运维大模型探索之 Text2PromQL 问答机器人
作者:陈昆仪(图杨)
大家下午好,我是来自阿里云可观测团队的算法工程师陈昆仪。今天分享的主题是“和我交谈并获得您想要的PromQL”。今天我跟大家分享在将AIGC技术运用到可观测领域的探索。

今天分享主要包括5个部分:
- 为什么我们需要一个自然语言翻译PromQL的机器人;
- 我们证实有效的算法及踩过的坑;
- Demo及相关数据成果的展示;
- 关于未来展望;
- Q&A。

为什么我们需要一个自然语言翻译 PromQL 的机器人?
先说说PromQL是什么,PromQL就是Prometheus的时序数据库的专属查询语句。Prometheus是云原生领域数据存储和查询的“事实标准”(De facto standard,我也是第一次看到这个词,“De facto ”居然还是拉丁文)。“事实标准”的意思就是“几乎所有”。从K8s应用中采集上来的指标数据都会被存在Prometheus这种时序数据库里,所有查询、分析工作也是在Prometheus上执行的。简而言之,PromQL几乎是所有K8s应用的运维工程师最经常使用的查询语句,没有之一。
现在我们知道什么是PromQL了,所以为什么我们需要一个自然查询语句转PromQL的机器人。我们把这个答案概括成3个"C":
1. 第一个“C”是“Complex”,“Complex syntax”。
PromQL的语法其实是比较复杂的,其实让它难学的根本在于它和我们熟悉的SQL语句有着本质不同:
SQL是适用于【关系数据库】的查询语句,SQL里我们关注的是Tabel和Tabel不断地做join,结合多个表的信息来得到我们最终想要的东西。但在PromQL里,我们处理的是【时序数据库】里的数据向量。这里我们没有Tabel了,全都是存在一些Label和指标的Vector。Join也很少用了。
我们可以看一个例子,当我们想查过去1 min 中响应时间最高的前十个应用,PromQL是这么写的:
topk(10,sum by (service)(sum_over_time(arms_http_requests_seconds{}[1m]))/sum by (service)(sum_over_time(arms_http_requests_count{}[1m])))
对熟悉SQL的同学开始,tokk 和 sum by 还算直观,sum_over_time 是啥,中间那个"/" 是什么意思?“arms_http_requests_seconds” 和 “arms_http_requests_count”是表名么?确实有一些学习成本。
2. 第二个"C"是"Confusing",“Confusing metric name”。
PromQL是由指标名、算子和Label组成的,指标名有时候会非常难懂。这主要是因为K8s里面这些指标,是不同公司的Agent采集上来的,这种提供Agent的公司包括:Google、AWS、Datadog、Dynatrace、阿里云等等,每个公司都有自己的命名方式,甚至有一些指标是用户自定义的。加上监控领域关注的指标又多又杂,有时候看文档都看不明白那些指标到底什么意思,该怎么用。
3. 第三个"C"是“Commenly”,“Commenly used query”。
PromQL其实是一个非常常用的查询语句,因为它不仅能提供运维相关的指标,CPU、rt、QPS、Error、404什么的,它也可以统计点击率、转换率、SLO、SLA、PV、UV,所以不仅仅是运维工程师可以用它,开发工程师、产品经理都可以用它。但现状是大家都用SRE给我们配的盘,想要指标选择找人帮配,我们也经常收到客户的工单要帮写PromQL。
综上, PromQL的语法不好学、指标名又复杂、日常工作中用得又多,为了减轻SRE的工作、降低工单,也为了Prometheus和K8s的推广,我们需要一款自然语言转PromQL的机器人。

我们证实有效的算法及踩过的坑
现在我们来到本次分享的第二部分,我们做自然语言转PromQL机器人走过的路(这里都是干货)。

1. ChatGPT是不是就可以完成自然语言到PromQL的翻译?
老板说我们要一个Text2PromQL的机器人,现在第一件事是要做什么呢?有的同学可能会说“买点GPU?”、“买个带GPU的FC实例?”、“收集点语料?”,这几件事都很重要,但不是我们第一步要做的事情。我们第一步要做的事情是先看看ChatGPT自己,是不是就可以完成自然语言到PromQL的翻译了。 如果大模型本身就可以很好地完成这个任务,那我们不用开发了。就等着通义千问做大做强,我们直接调用他们的API就行。我们做了一些实验,发现ChatGPT和通义千问都不能很好地完成这个工作。以ChatGPT为例,我问他“给我写个PromQL,帮我查一下过去5min,平均响应时间最长的10个应用是啥”。它给我的回答是topk(10,avg_over_time(application_response_time_seconds[5m]))
我们看下它哪里错了,首先是指标名的事情,在我们的系统中,根本没有一个叫"application_response_time_seconds"的指标,且avg_over_time(application_response_time_seconds[5m]))的意思是,对指标5min内。
先算"application_response_time_seconds"指标头和尾的差值,比如它在10:05min的值-它在10:00的值,再除以5。这个在可观测领域是没有物理含义的。
我们说过去5min内,应用平均响应时间,是需要用过去5min内,应用被调用的总耗时,除以它被调用的总次数,是每次调用的平均响应时间,分母是调用次数,不是5min。可以看看正确的例子:
topk(10,sum by (service)(sum_over_time(arms_http_requests_seconds{}[5m]))/sum by (service)(sum_over_time(arms_http_requests_count{}[5m])))
总结来看,如ChatGPT的通用LLM表现:
- 提供PromQL语法是正确的。
- 但它对我们的系统一无所知,不知道我们的指标名,对别的公司提供的监控系统也不知道,它没法知道我们的指标名。
- 它其实不大了解用户问这个问题真正的意图,因为它在这里的背景知识太少了。
也就是说,LLM需要更多知识…
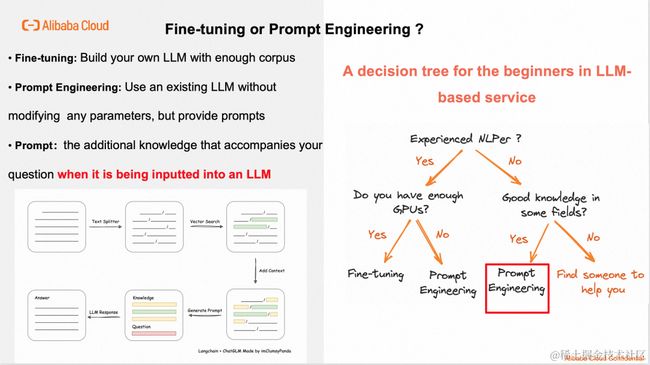
为了给LLM灌知识,我们也进行了大量调研,总的来说有2种方案:
-
Fine-tuning
用足够的语料对大模型进行微调,这里的微调指的是修改模型本身的一些参数,或者在大模型外接一个小模型,总之就是系统除了LLM本身自带的参数之外,已经有了任务相关的神经网络和参数了。
-
Prompt Engineering(提示词工程) 就是在不增加或修改大模型本身任意一个参数的前提下,只是在用户提问时,带一点上下文作为额外的知识,来提升回答的准确性。
这两种方案本身没有优劣之分,虽然Prompt Engineering听起来会更简单一些,但已在很多领域表现出比Fine turning更优的性能。我们画了一颗决策树,希望能给想要做LLM-based 应用的同行们一些经验:
- 如果你老板让我们做一个LLM-based的应用,我们要先问问自己:“我是不是一个经验丰富的NLPer”,如果您不知道NLPer是啥?-- 诚挚推荐“Prompt Engineering”。
- 如果您是一位经验丰富的NLPer,手握十几篇A。好,第二个问题,“贵团队有没有足够的GPU?”如果贵团队有十几张A100,那不用犹豫了,直接 Fine-tuining。可以搞一个大新闻,说不定能做一个比ChatGPT更强的领域专属大模型!
- 如果您不是经验丰富的NLPer,那么第二个问题是“您或您的团队中,有没有某个领域的专家”比如K8s领域,或者可观测领域。如果您对这个问题的回答是“Yes”,那么Prompt Engineering是最优的选择。
在我们ARMS团队目前还没有招揽垂直的NLP人才,但我们在可观测领域有十余年实践经验,所以我们选择了Prompt Engineering。
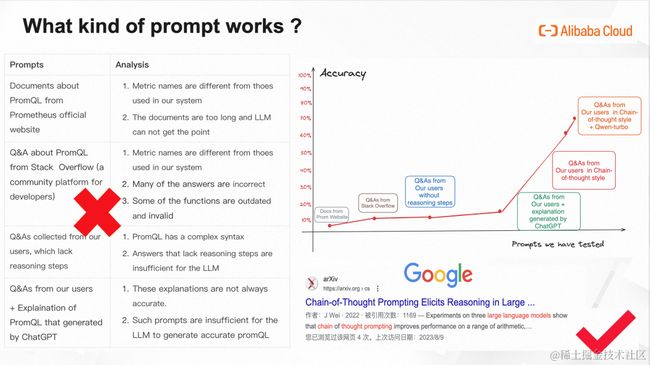
2. 什么样的提示词有用?
这一页PPT至少对我来说,是今天最有价值的一页。我希望几个月前有人能够把它分享给我,这样我可以节约很多时间和精力。
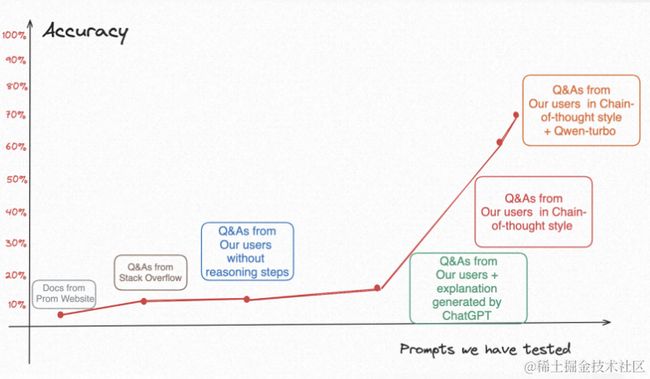
我们花了好几个月时间尝试了5种提示词,终于把text2PromQL的准确率从百分之5以下,提升到百分之70-80%,简单复盘一下探索历程:
➥PromQL官方文档
项目刚开始时候,第一个想到的可能有用的提示词是Prometheus官网所提供关于PromQL的文档,这个其实很直觉。然后试了一下,就用户提问一个PromQL问题,系统自动地把整个PromQL的文档当做提示词灌进去。测试了几十个Case,结果就是基本没有对的。
我们分析:大模型写出来的PromQL里面指标名和我们系统的不一样,也可以理解;意图识别也不对,因为LLM其实没那么聪明,它没法从那么抽象、那么长的文档里面找出比如“查前十个平均响应时间最长的应用”要有那些算子,怎么对指标加减乘除得到“平均响应时间”。
➥社区问答示例
那既然文档太长了,大模型学不会。我们做了一些调研发现说给大模型喂examples是有用的,就是常说的 “Few-shot”方式。然后就从Stack Overflow问答平台上找了几十个关于PromQL的问答。用户提问时就给他匹配语料里最相似的Case。结果准确率好了一点点,但是还是10%以下。
我们分析:首先,还是指标名问题,Q&A里的指标名不是我们系统里用的那些;其次,这种社区的回答质量其实参差不齐,他们给的答案也未必是对的。最后,一些回答里提到的函数和算子已被废弃,现在执行这种算子是无效的。
➥ARMS内部收集的PromQL问答示例
经过前两步尝试,我们发现指标名是绕不开的问题。所以我们的第三个PromQL方案是用ARMS系统自己收集的Q&A,这里的答案就包含了我们自己系统指标名的信息。我们做了实验之后发现,效果确实好了一点,但不多。因为前面说的PromQL确实比较复杂,有很多算子、很多指标名。对大模型来说,还是太难了。
➥ARMS内部收集的PromQL问答示例+ChatGPT生产的对回复中的PromQL的解释
那既然直接给PromQL不够,我们就加一些对PromQL的说明,这里的说明我们是直接用ChatGPT生产的。做了实验,发现这样准确率可以到20%左右,其实也没啥用。
➥Chain-of-Thought格式的PromQL问答示例
经过一个非常长的探索,我们终于找到一种Prompt Engineering的算法,实验之后,即使基于ChatGLM-6B,准确率也能到60-70%,终于迎来了第一个拐点。
➥Chain-of-Thought格式的PromQL问答示例+通义千问
当我们把大模型换成通义千问,其它配置一点没改,准确率原地涨了10%,到了80%左右。即使不完全正确的场景,也给了指标名、该用的算子等非常有用的信息且语法基本不会错。通义千问确实很厉害!
Chain-of-Thought 是Google Brain实验室提出来算法,本来用来增强LLM推理能力的,本来也不是用来做Text2PromQL,而是用来教LLM解小学应用题的。这篇论文甚至都没有正式发表,只是挂在了arxiv上,一年的时间,引用量就1000+了,可能也有熟悉LLM的小伙伴听说过它。

3. 什么是COT?
下面我们来介绍CoT是什么, 刚刚我们说了PromPT是给到大模型的知识,那么Chain-of-Thought PromPT就是给到大模型的带推理步骤的知识。
举个例子,现在我们希望LLM回答一个应用题Q:餐厅有23个苹果,如果他们用20个做午餐,然后又买了6个,那它现在有几个?由于GPT是个自然语言模型,它不大会算数。为了提升准确率,我们给他一些提示PromPT提示词给LLM一个例子。
➥普通提示词:
Q:Roger有5个羽毛球,他又买了2桶,每桶有3个,那他现在有几个。
A:答案是11。理论上,LLM应该能照葫芦画瓢回答出来,但他的答案是错误的。
➥Google 给的Chain-of-Thought提示词:
Q:Roger有5个羽毛球,他又买了2桶,每桶有3个,那他现在有几个。
A:Roger本来有5个球,买了2桶,每桶3个的球,也就是6个球。5+6=11。所以答案是11。这里就是给了例子中的推导过程。然后奇迹发生了,GPT居然就会了并给出正确答案。

下面我们来介绍CoT算法,在Text2PromQL场景下是怎么使用的。如果您比较熟悉PromQL,您应该可以感觉到写PromQL很像我们小学做的应用题。
下面我们回答一开始题的例子:
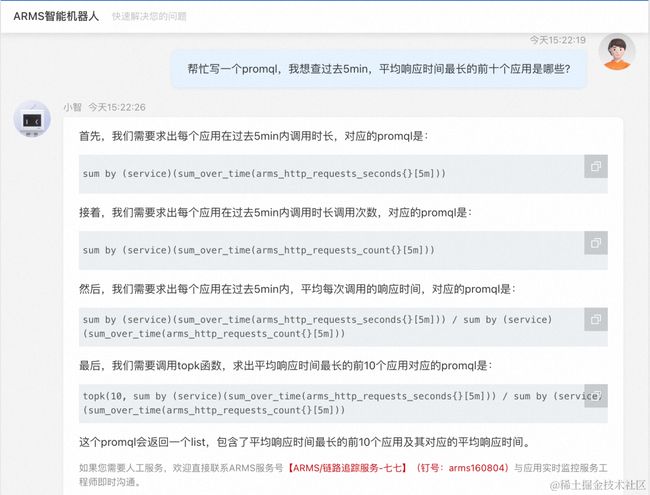
Q:“帮忙写一个PromQL,我想查过去5min,平均响应时间最长的前十个应用是哪些?”
CoT要带推理过程,我们从头说起。
A:首先,我们算过去5min,每个应用被调用的总时长,可以用下面的PromQL
![]()
然后,我们算过去5min,每个应用一共被调用了多少次,可以用下面的PromQL
![]()
可以看到这俩PromQL只是指标名不同,第一个是“arms_http_requests_seconds”记录的是latency,第二个的指标名是“arms_http_requests_count”记录的是调用量
再然后,算平均响应时间,那平均响应时间=调用总时长/调用总次数。这个PromQL就是用第一步的PromQL除以第二步的PromQL,得到

最后,因为问的是平均响应时间最高的前10个应用,所以还需要调用一下Topk函数,得到最终的PromQL

这就是CoT在Text2PromQL场景下的提示词。下面介绍ARMS小机器人的系统架构图

我们拥有一个离线系统和一个在线系统。在离线系统中,我们将ARMS多年沉淀的大量用户关于Text2Promql的问答示例,通过Chain-of-Chain Prompting算法转换成Chain-of-thought格式的Q&A示例,然后进行文本切割,得到一个Q&A示例,再通过embedding将文字转换为数字组成的向量,再把这些向量存到数据库中。
下面来看在线系统,当一个用户提问,比如写一个PromQL,查平均响应时间最长的10个应用,类似地,我们也会把这些文字,通过embedding,转换成数字组成的向量。现在我们拥有了用户问题转换出来的向量,以及离线系统中,数据库中一系列向量。那么,我们就可以在数据库中检索和当前用户问题最相似的topk个向量,把这个k+1个数字组成的向量还原为文字,然后把用户的问题,以及k个最相似的历史Q&A作为提示词输入到大模型中,就可以得到最终的PromQL。
可以看到,我们这个系统初始的输入是用户的PromQLl问答示例,所以当用户问得越多,我们能覆盖的场景也越多,准确率也会越高,总的来说,我们的机器人会越问越聪明。
Demo 演示
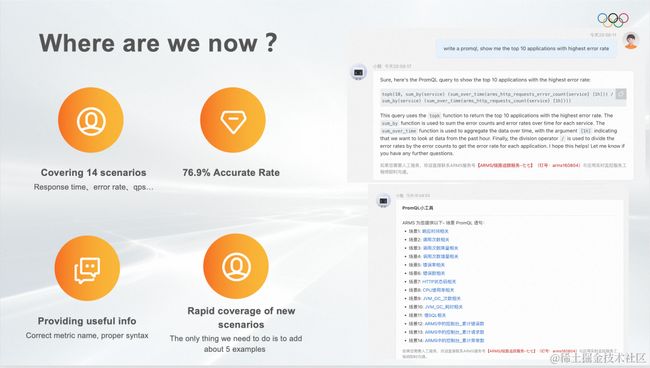
目前覆盖了:
- ARMS应用性能监控的14个场景,目前覆盖的都是ARMS的指标,如果不是ARMS的用户,可能需要根据指标名进行修改。
- K8s相关:(Container、Pod、Node维度)的CPU使用率、内存使用率、磁盘使用率等
- 灵骏默认大盘相关:(节点和集群维度)的CPU使用率、GPU使用率和内存使用率
- Kafka相关:(消息Topic、Group、instance维度)消息发送、消费、堆积量、磁盘使用率等
- Nacos相关:Full GC、服务读\写接口rt等
- MSE相关:网络流量、CPU、内存、磁盘指标。
在我们覆盖的场景中,我们用100+个Case测试过,准确率76.9%。即使在没有覆盖的场景下也能给出非常多有用信息。更重要的是基于PromPT Engineering,通过给提示词增加模型的准确率,所以覆盖新场景非常快,只要给它生成CoT格式的提示词就好。
产品体验入口:
- 如果您对容器指标相关的PromQL感兴趣,请点击容器数据源免登录Grafana入口 [ 1]
- 如果您对应用监控指标相关的PromQL感兴趣,请点击APM数据源免登录Grafana入口 [ 2]
- 如果目前PromQL只能助手的回答不满意,可以点击回答下方的反馈按钮哦

我们还做了一个对比实验:问没有提示词的ChatGPT 3.5还是刚刚那个“帮忙写一个PromQL,我想查过去5min,平均响应时间最长的前十个应用是哪些?” ,记过ChatGPT能写对语法,但是指标名和用户意图识别都是错的。然后问一下原生通义千问,发现它写的是类SQL?

但问通义千问的 Qwen-turbo + 我们的CoT提示词,结果语法、指标名和用户意图识别都是对的,无可挑剔。
未来展望
最后就是展望啦,自然语言转查询语句在数据库和可观测领域目前都是比较火热的话题。可观测领域的巨头们,比如Google、DataDog、New Relic 都提供类似服务。其中Google和我们思路相似,也是自然语言转PromQL,毕竟PromQL是云原生方向查询语句的事实标准。
但即使Google背后的模型是ChatGPT4,也做不到100%的准确率。因为他们不敢让大模型直接出图,或者说出大盘,还需要人工来点确认。BTW,可观测领域的新星HoneyComb倒是敢直接出图,这里可以体验:https://www.honeycomb.io/sandbox
To the best of my knowledge,基于我个人浅薄的认知,这个方向后面还有很长很长的路要走。
1. 第一个里程碑可能是一个自然语言到图表的机器人。
我们现在的topic是“Chat with me and get the PromQL you want”,那个时候的topic可能是“Chat with me and get the charts you want”,就直接出图了,查询语句接近100%准确。到时候想要图表、要数据就不用麻烦SRE大佬们了,直接和机器人说。
2. 第二个里程碑可能是一个可观测领域更智能的机器人。
不仅能出图,还能告诉你怎么配告警、怎么查问题,就像个经验丰富的运维工程师。但我们还是需要一个人类来点确定按钮,来决定是否采纳建议。那时候的topic是“Chat with me and get monitoring suggestions you want”。
3. 最后一个里程碑就是畅想已久的ChatOps。
真的可以通过对话来运维,那时候机器人就像一个非常专业的、经验丰富的、extremely hard-working的运维工程师,这里我放的是祖师爷–图灵。我们畅想的topic是“Chat with me and I will take care of your systems and applications”。这个岗位估计就不怎么需要人类了。
当然第三个里程碑可能有点远,我感觉前两个应该在不远的将来。

非常感谢大佬您看到了这里,这篇文章很长,但重点就两句话:“CoT提示词真的靠谱” “在text2PromQL场景下,实例Q&A + 一步一步的PromQL生成过程是我们实验过的最靠谱的PromPT。”
因为我们今年已经没有holiday了。
Have a nice day : )

Q&A
Q1: Prometheus 版本不断再升级,同一家公司、不同团队用的版本可能也不大一样,会对这个Text2PromQL准确性有影响吗?
A1: 首先,虽然 Prometheus自己确实在不断地升级,但对PromQL算子本身,其实这么久也没有太多变化。那些常用的、基础算子已经很完备了。所以其实Prometheus版本更新对我们来说影响不大;其次,即使出现了新的常用算子,我们也只需要再对它进行语料覆盖就好。因为我们做的是提示词工程嘛,所以只需要加一些语料,不用去调模型,训练它,几天就能新覆盖一个场景。
Q2: 刚刚提到用ChatGPT3.5进行了实验,但在Text2PromQL场景下效果不好。那现在ChatGPT-4出来了,它比ChatGPT3.5强很多,有没有在它上面做实验呢?
A2: 这是一个非常好的问题。ChatGPT-4确实很厉害,我们也试了一下,但它依然不能很好地解决Text2PromQL的场景。首先,PromQL是算子+Label+指标名。那指标名是我们系统产生的,比如ARMS 应用性能监控的用户,他指标名是ARMS自定义的,也不是公开的数据,ChatGPT-4就很难获取到这部分的信息。然后,就是更聪明的模型,我们理解它只是泛化能力更强,可能要覆盖一个新场景,比如容器监控,告诉它一点信息,给几个例子他就能表现得很好啦。
Q3: 想问一下系统中有用开源的向量数据库和开源大模型像ChatGLM什么的吗?
A3: 我们一开始探索时,通义千问和阿里云的向量数据库还没有公布。当时我们用的确实是开源向量数据库和开源大模型ChatGLM-6B。后来上线时,就换了阿里云的向量数据库和通义千问。可以看这个图,当我们把大模型换成通义千问后,其它配置一点没改,准确率原地涨了10%,到了80%左右,即使不完全对的场景,也给了指标名、该用的算子等非常有用的信息且语法基本不会错。通义千问确实很厉害!
Q4: embedding 用的是什么模型,有什么取舍?
A4: 在Text2PromQL这块儿,其实我找了一个可用的embedding模型就很靠谱了。因为embedding这里就是决定了你一个用户的问题会匹配到哪些相关语料嘛。我发现我们那个PromQL的语料,写成Chain-of-Thought的格式后,就很长发现它基本都能匹配到和用户问题相关的,后面这也是我们调优方向.
Q5: 问一下example的代表性,会不会对效果产生影响?
A5: 会,所以我们先写清楚了我们支持的场景。而且其实PromQL你匹配到它指标名和算子,对用户来说,他自己就能get到足够的信息了。CoT足够长,然后匹配到的概率已经很高了。
Q6: 这个项目中最难得部分是什么?因为我们自己尝试的过程中发现如果背后大模型不够好,简直是事倍功半,但你大模型比较聪明时候就很简单。
A6: 对,是这样的。我觉得这个项目最难得部分有两个:都在这张图上了。
- 第一个难的就是找合适的提示词。CoT这种提示词,给我们准确率直接来了一个拐点,从20%涨到60%-70%。
- 第二个是大模型本身,我们找到CoT这个算法之后,想把准确率从60%-70%往上涨,也试了不少方法,但是收获甚微。我们发现这个项目的瓶颈,就是当时用的那个开源大模型。我们就想着,那也不是我能解决的问题,所以这个项目就pending了得有1个多月。后来到9月13日,通义千问对外开放了,给我们调了它的API,又给我涨了10%,其实这个10%是比较保守的,在很多场景下,example给够,准确率是非常非常高的。

Q7 : 所以您这个项目本身没有对通义千问做任何的fine-turn对吧?
A7: 对,我们调用的就是那个商用的通义千问接口,一点都没有改。
对Text2PromQL或AIOps感兴趣的朋友可以加一下我们的钉钉群(群号:25125004458):
相关链接:
[1] 容器数据源免登录Grafana入口
https://demo.grafana.aliyuncs.com/explore?orgId=1&left=%7B%22datasource%22:%22arms-unify-demo-ack_1277589232893727_805acb%22,%22queries%22:%5B%7B%22refId%22:%22A%22,%22hide%22:false,%22expr%22:%22%22%7D%5D,%22range%22:%7B%22from%22:%22now-1h%22,%22to%22:%22now%22%7D%7D
[2] APM数据源免登录Grafana入口
https://demo.grafana.aliyuncs.com/explore?orgId=1&left=%7B%22datasource%22:%22arms_metrics_cn-hangzhou_cloud_hangzhou_1277589232893727_86cb47%22,%22queries%22:%5B%7B%22refId%22:%22A%22,%22hide%22:false%7D%5D,%22range%22:%7B%22from%22:%22now-1h%22,%22to%22:%22now%22%7D%7D