基于微博爬虫python
一、实验题目
基于python的微博爬虫系统
二、实验目的
1.目的
- 要求学生能够熟练掌握python语言的基本知识和技能。
- 基本掌握模块和库的使用方法,能够使用模块和库解决问题。
- 能够利用所学的基本知识和技能,解决实际问题。
2.基本要求
- 要求利用python语言实现系统的基本功能。
- 熟练使用python第三方库,完成系统的实现。
- 程序具有一定的健壮性,不会因为用户的输入错误引起程序运行错误而中断执行。对输入值的类型、大小范围、字符串的长度等,进行正确性检查,对不合法的输入值给出出错信息,指出错误类型,等待重新输入。
3.创新要求
在基本要求达到后,可根据实际情况进行创新设计,如设计出比较友好的界面、提高程序的鲁棒性或者提高系统的性能等。
三、报告要求
1.系统功能
在这次实验中,实现了对郭麒麟的微博昵称,微博主页地址,微博头像地址,是否认证,微博说明,关注人数,粉丝数,性别以及微博等级的爬取,运行的时候,这些获取的信息将会在运行栏输出结果;设置一个对于爬取到的郭麒麟微博的图片的保存路径,会自动创建一个名为“郭麒麟picture”的文件夹,把获取到的郭麒麟的照片保存到里面。
2.相关技术(使用的关键技术等)
import urllib.request
import json
import requests
import os
3.总体设计(系统框架、流程图,解决思路等)
(1)系统框架:
网页版微博是纯正的HTML,而且调用的微博自家的API来获取图片。
网址:https://m.weibo.cn/api/container/即为微博api里面包含了个人的信息与微博文字与图片存储地址。
进入api页面我们可以很清晰的看到各种信息都用json存储起来了。我们再利用python中的json库提取出来即可。这比其它利用cookie模拟登陆要方便很多,我们只要输入被爬虫用户的微博ID然后运行便能自动爬取。
定义一个页面打开函数,使用代理服务器来爬取页面的函数;
定义一个获取containerid,然后可以爬取微博id;
定义一个微博用户的基本信息;
定义一个微博内容信息。
(2)流程图:
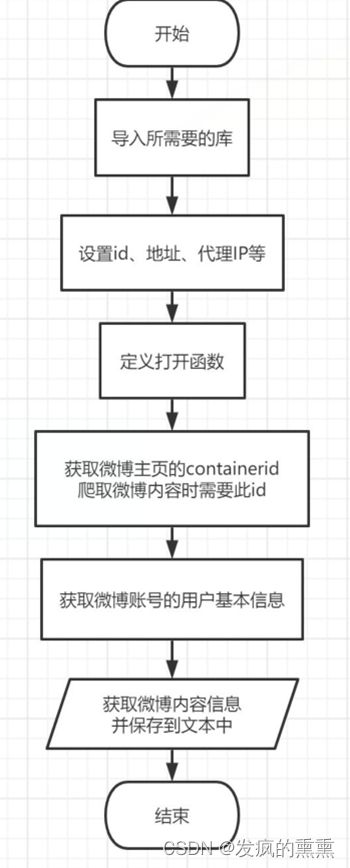
(3)解决思路:
根据网页上的一些结构,来写函数。
首先我们要实现用户的大规模爬取。 这里采用的爬取方式是,以微博的一个ID为起始点,定义要爬取的微博ID,设置代理IP,爬取他们各内的粉丝和关注列表,然后获取粉丝和关注列表的粉丝和关注列表。
定义get_containerid页面打开函数,获取微博主页的containerid,爬取微博内容时需要此ID。
定义get_userInfo函数,获取微博账号的用户基本信息,如:微博昵称、微博主页地址、微博头像地址、是否认证、微博说明、关注人数、粉丝数、性别、微博等级等。
定义get_weibo函数,获取微博内容信息,并保存到earthquake.txt文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等。
进行主函数调用来实现微博爬取。
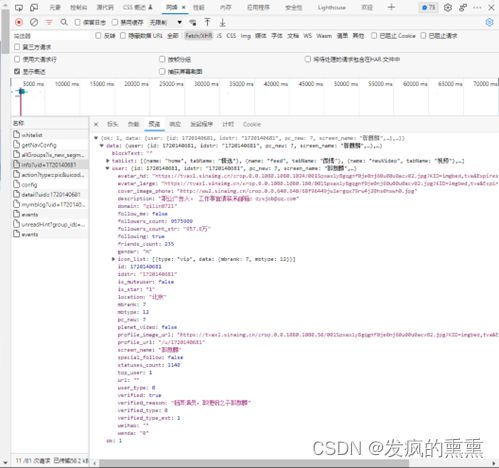
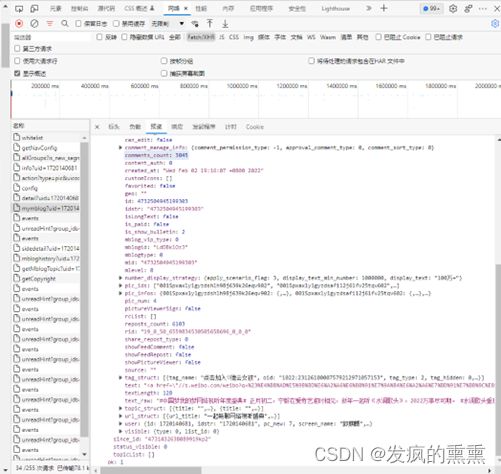
4.详细设计(算法/代码描述)
import urllib.request # 可以用来发送request和获取request的结果
import json # 用于存储和交换数据的语法
import requests # 该模块主要用来发 送 HTTP 请求
import os # 对文件以及文件夹或者其他的进行一系列的操作
path = 'D:\pycharm\pycharmproject\climb\weibo\\'
# 要爬取的明星的id
id = '1720140681'
# id = '5456865382'
# 代理服务器的地址
proxy_addr = "122.241.72.191:808"
pic_num = 0
weibo_name = "郭麒麟picture"
# 定义页面打开函数
# 使用代理服务器来爬取某个URL网页的功能
def use_proxy(url, proxy_addr):
req = urllib.request.Request(url) # 获取要请求的url
req.add_header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0") # 通过Request添加header
proxy = urllib.request.ProxyHandler({'http': proxy_addr}) # 使用代理服务器
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(req).read().decode('utf-8', 'ignore')
return data
# 获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data = use_proxy(url, proxy_addr)
content = json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if (data.get('tab_type') == 'weibo'):
containerid = data.get('containerid')
return containerid
# 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=' + id # 要爬取的微博的url
data = use_proxy(url, proxy_addr) # 使用代理服务器爬取整个url网页并且赋值给data
content = json.loads(data).get('data') # 将得到的数据转化为Python
profile_image_url = content.get('userInfo').get('profile_image_url')
description = content.get('userInfo').get('description')
profile_url = content.get('userInfo').get('profile_url')
verified = content.get('userInfo').get('verified')
guanzhu = content.get('userInfo').get('follow_count')
name = content.get('userInfo').get('screen_name')
fensi = content.get('userInfo').get('followers_count')
gender = content.get('userInfo').get('gender')
urank = content.get('userInfo').get('urank')
print("微博昵称:" + name + "\n" + "微博主页地址:" + profile_url + "\n" + "微博头像地址:" + profile_image_url + "\n" + "是否认证:" + str(
verified) + "\n" + "微博说明:" + description + "\n" + "关注人数:" + str(guanzhu) + "\n" + "粉丝数:" + str(
fensi) + "\n" + "性别:" + gender + "\n" + "微博等级:" + str(urank) + "\n") # 输出微博用户基本信息
#获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id, file):
global pic_num
i = 1
while True:
url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=' + id # 获取爬取的url
weibo_url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=' + id + '&containerid=' + get_containerid(
url) + '&page=' + str(i) # 获取要爬取的微博的url
try:
data = use_proxy(weibo_url, proxy_addr) # 使用代理服务器爬取整个url网页并且赋值给data
content = json.loads(data).get('data') # 将得到的数据转化为Python
cards = content.get('cards')
if (len(cards) > 0):
for j in range(len(cards)): # 从第一页开始爬取,直到爬取完
print("-----正在爬取第" + str(i) + "页,第" + str(j) + "条微博------")
card_type = cards[j].get('card_type') # 得到获得的文本的类型
if (card_type == 9): # 获取一页的十条微博
mblog = cards[j].get('mblog') # 得到那一条微博
attitudes_count = mblog.get('attitudes_count') # 得到点赞数
comments_count = mblog.get('comments_count')
created_at = mblog.get('created_at')
reposts_count = mblog.get('reposts_count')
scheme = cards[j].get('scheme')
text = mblog.get('text')
if mblog.get('pics') != None:
pic_archive = mblog.get('pics')
for _ in range(len(pic_archive)): # 遍历照片
pic_num += 1 # 照片数量加1
print(pic_archive[_]['large']['url']) # 输出照片的url
imgurl = pic_archive[_]['large']['url'] # 定义照片url为imgurl
img = requests.get(imgurl) # 获取照片的url
f = open(path + weibo_name + '\\' + str(pic_num) + str(imgurl[-4:]), 'ab') # 存储图片,多媒体文件需要参数b(二进制文件)
f.write(img.content) # 多媒体存储content
f.close()
with open(file, 'a', encoding='utf-8') as fh: # 输出到文件中
fh.write("----第" + str(i) + "页,第" + str(j) + "条微博----" + "\n")
fh.write("微博地址:" + str(scheme) + "\n" + "发布时间:" + str(
created_at) + "\n" + "微博内容:" + text + "\n" + "点赞数:" + str(
attitudes_count) + "\n" + "评论数:" + str(comments_count) + "\n" + "转发数:" + str(
reposts_count) + "\n")
i += 1 # 爬取一页加1
else:
break
except Exception as e:
print(e)
pass
# 储存位置设定
if __name__ == "__main__":
if os.path.isdir(path + weibo_name): # 如果有文件就什么不做
pass
else:
os.mkdir(path + weibo_name)
file = path + weibo_name + '\\' + weibo_name + ".txt"
get_userInfo(id) # 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
get_weibo(id, file) #获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
5.运行结果
(1)结果图1:
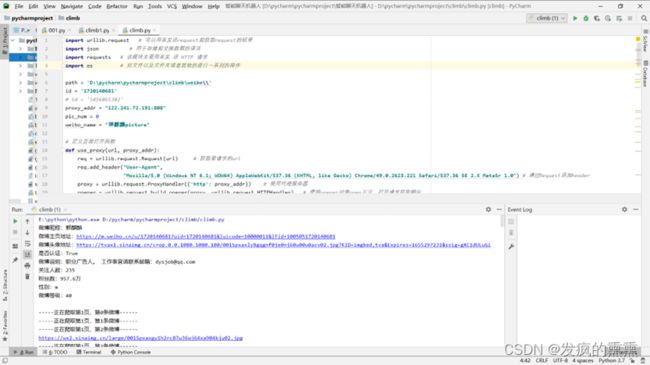
(2)结果图2:
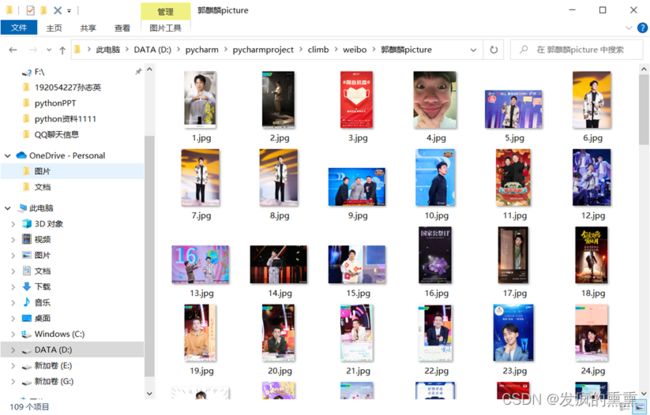
6.心得体会
在本次实验中,设计了基于微博爬虫的系统,主要对于明星郭麒麟的照片的爬取,通过这次Python实训,我收获了很多,一方面学习到了许多以前没学过的专业知识与知识的应用,另一方面还提高了自我动手做项目的潜力。本次实训是对我潜力的进一步锻炼,也是一种考验。从中获得的诸多收获,也是很可贵的,是十分有好处的。在本次实验中我学到了许多新的知识,是一个让我把书本上的理论知识运用于实践中的好机会,原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。在这次实训中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等。
7.参考书目、资料等。
(1)主要文章
陈娟,陈雯,石飞,王建英,胡英。 基于Python的信号与系统实验教学改革与实践[J]. 实验技术与管理,2021,(05):196-200.
张乐。 案例教学法在Python语言程序设计教学中的应用[J]. 计算机时代,2021,(04):72-75.
叶惠仙,游金水。 Python语言在大数据处理中的应用[J]. 网络安全技术与应用,2021,(05):51-54.
(2)主要书籍
《python程序设计》董付国 清华大学出版社
《Python网络爬虫实战》作者:胡松涛 清华大学出版社(2016-12)
《Python网络爬虫从入门到实践》作者:陈智铨 机械工业出版社(2017-09)
《Python爬虫开发与项目实践》作者:范传辉 机械工业出版社(2017-06)