大数据高级开发工程师——Hadoop学习笔记(1)
文章目录
- Hadoop基础篇
-
- Hadoop集群安装
-
- 环境准备
-
- 服务器准备
- 设置时钟同步
- 三台虚拟机添加普通用户
- 三台虚拟机定义统一目录
- 三台虚拟机hadoop用户设置免密登录
- 三台虚拟机安装jdk
- hadoop集群安装
-
- 环境部署规划
- 安装包下载
- 查看hadoop支持的压缩方式以及本地库
- 修改配置文件
-
- 修改 hadoop-env.sh
- 修改 core-site.xml
- 修改 hdfs-site.xml
- 修改 mapred-site.xml
- 修改 yarn-site.xml
- 修改 workers文件
- 创建文件存放目录
- 安装包分发scp与rsync
-
- 通过 scp 直接拷贝
- 通过rsync来实现增量拷贝
- 通过rsync来封装分发脚本
- 配置 hadoop 环境变量
- 格式化集群
- 启动集群
-
- 启动HDFS、YARN、Historyserver
- 单个进程逐个启动
- 一键启动hadoop集群的脚本
- 验证集群是否搭建成功
-
- 访问web ui界面
- 所有机器查看进程脚本
- 运行一个mr例子
- Zookeeper集群环境搭建
- 开发环境搭建
-
- windows 开发环境准备
-
- 1. 修改 hosts 文件
- 2. 安装 jdk
- 3. 配置hadoop环境变量
- 4. 安装maven
- 5. 安装IDEA
- MAC 开发环境准备
- Hadoop简介
-
- hadoop的起源
- hadoop的发展版本介绍
- hadoop生产环境版本选择
- hadoop的运行模式
-
- 1. 本地运行模式
- 2. 伪分布式运行模式
- 3. 完全分布式运行模式(开发重点)
- hadoop的架构介绍
Hadoop基础篇
Hadoop集群安装
环境准备
服务器准备
- 准备 3 台 linux 服务器,如果只有一台电脑,可以借助 Vmware 安装,请参考利用VMware安装Linux服务器环境
- 关闭防火墙
# root用户下执行
systemctl stop firewalld
systemctl disable firewalld
# 关闭selinux
vi /etc/sysconfig/selinux
SELINUX=disabled
- 更改主机名
vi /etc/hostname
- 修改 IP 域名映射
vi /etc/hosts
192.168.254.128 node01
192.168.254.130 node02
192.168.254.132 node03
设置时钟同步
- 通过网络进行时钟同步
# 通过网络连接外网进行时钟同步,安装ntpdate
yum -y install ntpdate
# 阿里云时钟同步服务器
ntpdate ntp4.aliyun.com
# 设置定时任务
crontab -e
# 添加如下内容
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
- 内网某机器作为时钟同步服务器
# 确认是否安装ntpdate时钟同步工具
rpm -qa | grep ntpdate
# 安装ntp
yum -y install ntp
# 执行以下命令,设置时区为中国上海时区
timedatectl set-timezone Asia/Shanghai
# 启动node01的ntpd服务
systemctl start ntpd
# 设置ntpd服务开机启动
systemctl enable ntpd
# 修改node01这台服务器的时钟同步配置,允许对外提供服务
vim /etc/ntp.conf
# 同意192.168.254.0网段(修改成自己的网段)的所有机器与node01同步时间
restrict 192.168.254.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
# 注释掉以下这四行内容
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
# 修改完成之后,重启node01的ntpd服务
systemctl restart ntpd
# 至此,ntpd的服务端已经安装配置完成,接下来配置客户端与服务端进行同步
# 客户端node02与node03设置时区与node01保持一致Asia/Shanghai
# node02与node03修改配置文件,保证每次时间写入硬件时钟
vim /etc/sysconfig/ntpdate
SYNC_HWCLOCK=yes
# node02与node03修改定时任务,定时与node01同步时间
crontab -e
*/1 * * * * /usr/sbin/ntpdate node01

三台虚拟机添加普通用户
- 三台linux服务器统一添加普通用户hadoop,并给以sudo权限,用于以后所有的大数据软件的安装,并统一设置普通用户的密码为 123456
useradd hadoop
passwd hadoop

- 三台机器为普通用户添加sudo权限
visudo
# 增加如下内容
hadoop ALL=(ALL) ALL

三台虚拟机定义统一目录
- 定义三台linux服务器软件压缩包存放目录,以及解压后安装目录,三台机器执行以下命令,创建两个文件夹,一个用于存放软件压缩包目录,一个用于存放解压后目录。
# 软件压缩包存放目录
mkdir -p /bigdata/soft
# 软件解压后存放目录
mkdir -p /bigdata/install
# 将文件夹权限更改为hadoop用户
chown -R hadoop:hadoop /bigdata
- 创建hadoop用户之后,我们三台机器都通过hadoop用户来进行操作,以后再也不需要使用root用户来操作了
- 三台机器通过 su hadoop命令来切换到hadoop用户
su hadoop

三台虚拟机hadoop用户设置免密登录
- 三台机器分别在hadoop用户下执行以下命令生成公钥与私钥
ssh-keygen -t rsa
# 按三次Enter键即可生成了

- 三台机器在hadoop用户下,执行命令拷贝公钥到node01服务器
ssh-copy-id node01

- node01 服务器将公钥拷贝给 node02 与 node03
# node01在hadoop用户下,执行以下命令,将authorized_keys拷贝到node02与node03服务器
cd /home/hadoop/.ssh/
scp authorized_keys node02:$PWD
scp authorized_keys node03:$PWD

- 验证:从任意节点是否能免秘钥登陆其他节点;如node01免密登陆node02
ssh node02

- 三台机器在hadoop用户下执行以下命令,实现关机重启
sudo reboot -h now
三台虚拟机安装jdk
- 如果已经安装过 jdk 环境,这一步可以忽略
hadoop集群安装
环境部署规划
| 服务器IP | node01 | node02 | Node03 |
|---|---|---|---|
| HDFS | NameNode | ||
| HDFS | SecondaryNameNode | ||
| HDFS | DataNode | DataNode | DataNode |
| YARN | ResourceManager | ||
| YARN | NodeManager | NodeManager | NodeManager |
| 历史日志服务器 | JobHistoryServer |
安装包下载
- 官网下载地址:https://hadoop.apache.org/releases.html
- 历史归档版本下载地址:https://archive.apache.org/dist/hadoop/core/
- 接下来下载并解压安装包到指定目录:
[hadoop@centos128 soft]$ pwd
/bigdata/soft
[hadoop@centos128 soft]$ wget http://archive.apache.org/dist/hadoop/core/hadoop-3.1.4/hadoop-3.1.4.tar.gz
[hadoop@centos128 soft]$ tar -zxvf hadoop-3.1.4.tar.gz -C /bigdata/install/
# 删掉没用的文档
[hadoop@centos128 share]$ rm -rf doc/
查看hadoop支持的压缩方式以及本地库
[hadoop@centos128 soft]$ cd /bigdata/install/hadoop-3.1.4/
[hadoop@centos128 hadoop-3.1.4]$ bin/hadoop checknative

- 如果出现openssl为false,那么所有机器在线安装openssl即可,执行以下命令,虚拟机联网之后就可以在线进行安装了
sudo yum -y install openssl-devel
修改配置文件
修改 hadoop-env.sh
[hadoop@centos128 hadoop]$ pwd
/bigdata/install/hadoop-3.1.4/etc/hadoop
[hadoop@centos128 hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/usr/apps/jdk1.8.0_241

修改 core-site.xml
[hadoop@centos128 hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://node01:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/bigdata/install/hadoop-3.1.4/hadoopDatas/tempDatasvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>4096value>
property>
<property>
<name>fs.trash.intervalname>
<value>10080value>
property>
configuration>
修改 hdfs-site.xml
[hadoop@centos128 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node01:9868value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>node01:9870value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///bigdata/install/hadoop-3.1.4/hadoopDatas/namenodeDatasvalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///bigdata/install/hadoop-3.1.4/hadoopDatas/datanodeDatasvalue>
property>
<property>
<name>dfs.namenode.edits.dirname>
<value>file:///bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/nn/editsvalue>
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
<value>file:///bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/snn/namevalue>
property>
<property>
<name>dfs.namenode.checkpoint.edits.dirname>
<value>file:///bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/editsvalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
configuration>
修改 mapred-site.xml
[hadoop@centos128 hadoop]$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.job.ubertask.enablename>
<value>truevalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node01:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node01:19888value>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
configuration>
修改 yarn-site.xml
[hadoop@centos128 hadoop]$ vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.pmem-check-enabledname>
<value>falsevalue>
property>
configuration>
修改 workers文件
[hadoop@centos128 hadoop]$ vim workers
- 原内容替换为:
node01
node02
node03
创建文件存放目录
# node01 上执行
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/tempDatas
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/namenodeDatas
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/datanodeDatas
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name
mkdir -p /bigdata/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits
安装包分发scp与rsync
- 在linux当中,用于向远程服务器拷贝文件或者文件夹可以使用scp或者rsync,这两个命令功能类似都是向远程服务器进行拷贝,只不过scp是全量拷贝,rsync可以做到增量拷贝,rsync的效率比scp更高一些。
通过 scp 直接拷贝
- scp(secure copy)安全拷贝:可以通过scp进行不同服务器之间的文件或者文件夹的复制,用法:
scp -r sourceFile username@host:destpath
- node01节点执行以下命令进行拷贝
[hadoop@centos128 hadoop]$ cd /bigdata/install/
[hadoop@centos128 install]$ scp -r hadoop-3.1.4/ node02:$PWD
[hadoop@centos128 install]$ scp -r hadoop-3.1.4/ node03:$PWD
通过rsync来实现增量拷贝
- rsync 远程同步工具:rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
- rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
- 安装命令:
sudo yum -y install rsync
- 基本用法:
# 命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
rsync -av /bigdata/soft/apache-zookeeper-3.6.2-bin.tar.gz node02:/bigdata/soft/
- 选项参数说明
| 选项 | 功能 |
|---|---|
| -a | 归档拷贝 |
| -v | 显示复制过程 |
通过rsync来封装分发脚本
- 我们可以通过rsync这个命令工具来实现脚本的分发,可以增量的将文件分发到我们所有其他的机器上面去
- 需求:循环复制文件到所有节点的相同目录下
- rsync命令原始拷贝:
rsync -av /bigdata/soft hadoop@node02:/bigdata/soft
- 期望脚本使用方式:xsync要同步的文件名称
说明:在/home/hadoop/bin这个目录下存放的脚本,hadoop用户可以在系统任何地方直接执行。
- 脚本实现:在/home/hadoop目录下创建bin目录,并在bin目录下xsync创建文件,文件内容如下
cd /home/hadoop/bin
touch xsync
vim xsync
- 在该文件中编写如下代码
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo $fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo $pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=1; host<4; host++)); do
echo ------------------- node0$host --------------
rsync -av $pdir/$fname $user@node0$host:$pdir
done
- 修改脚本 xsync 具有执行权限
cd ~/bin/
chmod 777 xsync
- 调用脚本形式:xsync 文件名称
xsync /home/hadoop/bin/
注意:如果将xsync放到/home/hadoop/bin目录下仍然不能实现全局使用,可以将xsync移动到/usr/local/bin目录下
配置 hadoop 环境变量
- 三台机器都要进行配置hadoop的环境变量
sudo vim /etc/profile
- 添加配置内容
# 配置Hadoop环境变量
export HADOOP_HOME=/bigdata/install/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 配置完成后生效
source /etc/profile
格式化集群
- 要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
- 注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。格式化操作只有在首次启动的时候需要,以后再也不需要了。
- node01执行一遍即可
hdfs namenode -format
# 或者
hadoop namenode –format
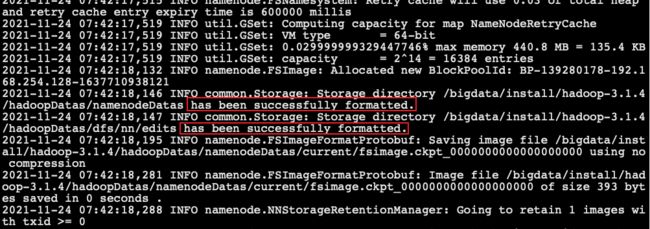
- 下图打印
has been successfully formatted表示格式化成功
启动集群
- 启动集群有两种方式:
- 脚本一键启动
- 单个进程逐个启动
启动HDFS、YARN、Historyserver
- 如果配置了 etc/hadoop/workers 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
- 启动集群:主节点node01节点上执行以下命令
start-dfs.sh
start-yarn.sh
# 已过时mr-jobhistory-daemon.sh start historyserver
mapred --daemon start historyserver

- 查看进程:

- 停止集群(主节点node01节点上执行):
stop-dfs.sh
stop-yarn.sh
# 已过时 mr-jobhistory-daemon.sh stop historyserver
mapred --daemon stop historyserver
单个进程逐个启动
# 在主节点上使用以下命令启动 HDFS NameNode:
# 已过时 hadoop-daemon.sh start namenode
hdfs --daemon start namenode
# 在主节点上使用以下命令启动 HDFS SecondaryNamenode:
# 已过时 hadoop-daemon.sh start secondarynamenode
hdfs --daemon start secondarynamenode
# 在每个从节点上使用以下命令启动 HDFS DataNode:
# 已过时 hadoop-daemon.sh start datanode
hdfs --daemon start datanode
# 在主节点上使用以下命令启动 YARN ResourceManager:
# 已过时 yarn-daemon.sh start resourcemanager
yarn --daemon start resourcemanager
# 在每个从节点上使用以下命令启动 YARN nodemanager:
# 已过时 yarn-daemon.sh start nodemanager
yarn --daemon start nodemanager
- 以上脚本位于$HADOOP_HOME/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的start 改为stop 即可。
一键启动hadoop集群的脚本
- 为了便于一键启动hadoop集群,我们可以编写shell脚本,在node01服务器的/home/hadoop/bin目录下创建脚本
cd /home/hadoop/bin/
vim hadoop.sh
- 脚本内容如下:
#!/bin/bash
case $1 in
"start" ){
source /etc/profile;
/bigdata/install/hadoop-3.1.4/sbin/start-dfs.sh
/bigdata/install/hadoop-3.1.4/sbin/start-yarn.sh
#/bigdata/install/hadoop-3.1.4/sbin/mr-jobhistory-daemon.sh start historyserver
/bigdata/install/hadoop-3.1.4/bin/mapred --daemon start historyserver
};;
"stop"){
/bigdata/install/hadoop-3.1.4/sbin/stop-dfs.sh
/bigdata/install/hadoop-3.1.4/sbin/stop-yarn.sh
#/bigdata/install/hadoop-3.1.4/sbin/mr-jobhistory-daemon.sh stop historyserver
/bigdata/install/hadoop-3.1.4/bin/mapred --daemon stop historyserver
};;
esac
- 修改脚本权限
chmod 777 hadoop.sh
./hadoop.sh start # 启动hadoop集群
./hadoop.sh stop # 停止hadoop集群
验证集群是否搭建成功
访问web ui界面
- hdfs集群访问地址:http://192.168.254.128:9870/

- yarn集群访问地址:http://192.168.254.128:8088/

- jobhistory访问地址:http://192.168.254.128:19888/

- 修改本机的 hosts
- windows的hosts文件路径是
C:\Windows\System32\drivers\etc\hosts - mac的hosts文件是
/etc/hosts
- windows的hosts文件路径是
# Hadoop
192.168.254.128 hadoop01
192.168.254.130 hadoop02
192.168.254.132 hadoop03
- 上边的web ui界面访问地址可以是:
http://hadoop01:9870
http://hadoop01:8088
http://hadoop01:19888
所有机器查看进程脚本
-
我们也可以通过jps在每台机器上面查看进程名称,为了方便我们以后查看进程,我们可以通过脚本一键查看所有机器的进程
-
在node01服务器的/home/hadoop/bin目录下创建文件xcall
cd ~/bin/
vim xcall
- 添加以下内容
#!/bin/bash
params=$@
for (( i=1 ; i <= 3 ; i = $i + 1 )) ; do
echo ============= node0$i $params =============
ssh node0$i "source /etc/profile;$params"
done
- 然后一键查看进程并分发该脚本
chmod 777 /home/hadoop/bin/xcall
xsync /home/hadoop/bin/
- 各节点应该启动的hadoop进程如下图
xcall jps

运行一个mr例子
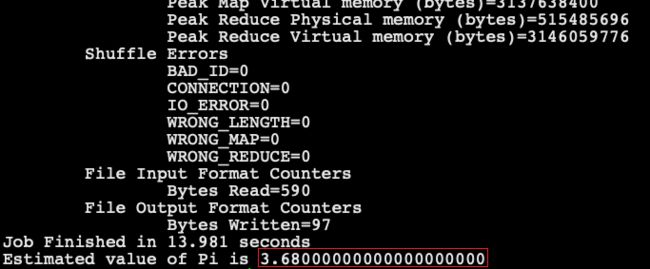
- 任意节点运行 pi 用例:
hadoop jar /bigdata/install/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 5 5
- 最后计算出pi的近似值:
提醒:如果要关闭电脑时,清一定要按照以下顺序操作,否则集群可能会出问题
关闭hadoop集群
关闭虚拟机
关闭电脑
Zookeeper集群环境搭建
- 请参考:JavaEE 企业级分布式高级架构师(八)Zookeeper学习笔记(1)
开发环境搭建
windows 开发环境准备
1. 修改 hosts 文件
- 修改hosts文件:所在位置
C:\Windows\System32\drivers\etc\hosts - 将虚拟机中/etc/hosts文件以下内容,添加到windows的hosts文件末尾(根据自己的实际情况,修改ip地址)
2. 安装 jdk
- jdk下载链接
- 注意:jdk不要安装到有空格、有中文的目录
- 配置环境变量:右键我的电脑 ==>> 选择属性 ==>> 高级系统设置 ==>> 高级 ==>> 环境变量
- 在“系统变量”中“新建”变量JAVA_HOME,值为自己的jdk具体路径,如C:\Java\jdk1.8.0_172(无中文、无空格)
- PATH中添加值
%JAVA_HOME%\bin - CLASSPATH值为
.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar;%JAVA_HOME%\lib\dt.jar
jdk和jre
- JRE顾名思义是java运行时环境,包含了java虚拟机,java基础类库。是使用java语言编写的程序运行所需要的软件环境,是提供给想运行java程序的用户使用的。
- JDK顾名思义是java开发工具包,是程序员使用java语言编写java程序所需的开发工具包,是提供给程序员使用的。JDK包含了JRE,同时还包含了编译java源码的编译器javac,还包含了很多java程序调试和分析的工具:jconsole,jvisualvm等工具软件,还包含了java程序编写所需的文档和demo例子程序。
3. 配置hadoop环境变量
- 找到我们在linux中安装hadoop集群所用的tar.gz包
hadoop-3.1.4.tar.gz将它解压到一个没有中文、没有空格的目录下 - 然后在windows当中配置hadoop的环境变量,bin、sbin目录添加到path中
- 然后将 hadoop.dll 文件拷贝到C:\Windows\System32
- 将hadoop集群的一下5个配置文件
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers,拷贝到windows下hadoop的C:\hadoop-3.1.4\etc\hadoop目录下 - cmd中运行
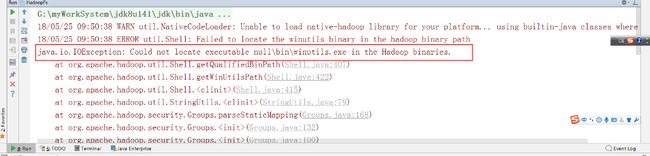
hadoop,如果出现下图报错,那么,将C:\hadoop-3.1.4\bin目录中的所有cmd文件用notepad++打开,进行文档格式转换

- 注意:如果没有配置好windows的hadoop的环境变量,在windows下用IDEA编程时,会报以下错误
- windows中,各版本的hadoop的winutils下载地址
4. 安装maven
- 官网:http://maven.apache.org/
- 下载解压安装包
apache-maven-3.6.1-bin.zip到某安装目录即可(也可以去官网下载maven) - 配置环境变量,增加MAVEN_HOME环境变量
- 仓库:
- 本地仓库:MAVEN_HOME/conf/settings.xml文件中,localRepository用于配置本地仓库目录,默认是用户目录下的.m2/repository目录
- 中央仓库:是官方或者第三方提供的仓库
- https://mvnrepository.com/
- cdh的 https://repository.cloudera.com/artifactory/cloudera-repos/
- maven的配置文件settings.xml在maven的conf目录中本地仓库路径
/path/to/local/repo - Maven是否需要和用户交互以获得输入。如果Maven需要和用户交互以获得输入,则设置成true,反之则应为false,默认为true 。
true - 为了加快jar包依赖的下载速度,可以在settings.xml的mirrors中添加如下内容
<mirror>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
5. 安装IDEA
- idea官网:https://www.jetbrains.com/,根据自己的操作系统,选择合适的idea版本。
- idea下载地址https://www.jetbrains.com/idea/download/#section=windows
MAC 开发环境准备
- mac下做hadoop编程,只需如下几步即可
- mac下安装jdk1.8
- 安装maven
- 安装idea
- 使用虚拟化软件,创建3节点的hadoop集群
- 若想在mac下操作hadoop集群,比如运行hadoop命令,那么将某虚拟机上如node01上的的hadoop文件夹
/bigdata/install/hadoop-3.1.4拷贝到mac,比如我的目录下/Volumes/D/hadoop/hadoop-3.1.4 - 修改hadoop-env.sh的JAVA_HOME的值为mac的jdk路径,根据自己的实际情况进行修改
- 修改mac用户主目录下的 ~/.bash_profile 文件,添加JAVA_HOME、HADOOP_HOME环境变量
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Home
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/Volumes/D/hadoop/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 然后
source ~/.bash_profile,运行mapreduce的pi例子
$ hadoop jar /Volumes/D/hadoop/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 3 3
- 若报错:
org.apache.hadoop.security.AccessControlException: Permission denied: user=yangwei, access=EXECUTE, inode="/tmp":hadoop:supergroup:drwxrwx---
- 权限问题引起的问题,在虚拟机中使用hadoop用户,修改hdfs的/tmp目录的权限
hadoop@centos128 install]$ hdfs dfs -chmod -R 777 /tmp/
- 然后,可以在 mac 中运行pi例子就可以了
Hadoop简介
hadoop的起源
- Hadoop 最早起源于 Nutch,而 Apache Nutch 是 Apache Lucene(一个文本搜索系统库) 的一部分。
- Nutch的设计目标是构建一个大型的全网搜索引擎,主要包括web爬虫抓取网页、全文检索、查询;
- 但随着抓取网页数量的增加,遇到了严重的可扩展性问题:如何解决数十亿网页的存储和索引问题。

-
2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案:
- 分布式文件系统(GFS):可用于处理海量网页的存储
- 分布式计算框架MAPREDUCE:可用于处理海量网页的索引计算问题
-
Nutch的开发人员完成了相应的开源实现 HDFS(04年)和MAPREDUCE(05年),并从Nutch中剥离成为独立项目HADOOP。
-
到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
-
Hadoop作者Doug Cutting

- 狭义上来说,hadoop就是单独指代hadoop这个软件。
- 广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件。

hadoop的发展版本介绍
- 0.x系列版本:hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本。
- 1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等。
- 2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,也是现在生产环境当中使用最多的版本。
- 3.x版本系列:在2.x版本的基础上,引入了一些hdfs的新特性等,且已经发行了稳定版本,未来公司的使用趋势。

hadoop生产环境版本选择
-
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
- Apache版本最原始(最基础)的版本,对于入门学习最好。
- Cloudera在大型互联网企业中用的较多。
- Hortonworks文档较好。
-
mapr
-
Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
-
Cloudera Hadoop
官网地址:https://www.cloudera.com
下载地址:http://archive.cloudera.com/cdh5/cdh/5/
- 2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
- 2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
- CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
- Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
- Cloudera的标价为每年每个节点4000美元。
- Cloudera开发并贡献了可实时处理大数据的==Impala项目==。
-
Hortonworks Hadoop
官网地址:https://www.cloudera.com
- 现cloudera与hortonworks已合并。
- 2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
- 公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
- 雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
- Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了==Ambari==,一款开源的安装和管理系统。
- HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
- Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
注意:Hortonworks已经与Cloudera公司合并
hadoop的运行模式
1. 本地运行模式
- 无需任何守护进程,所有的程序都运行在同一个JVM上执行。在独立模式下调试MR程序非常高效方便。所以一般该模式主要是在学习或者开发阶段调试使用
2. 伪分布式运行模式
- Hadoop守护进程运行在本地机器上,模拟一个小规模的集群,换句话说,可以配置一台机器的Hadoop集群
- 伪分布式是完全分布式的一个特例。
3. 完全分布式运行模式(开发重点)
- Hadoop守护进程运行在一个集群上,需要使用多台机器来实现完全分布式服务的安装
hadoop的架构介绍
- Hadoop 由三个模块组成:
- 分布式存储 HDFS
- 分布式计算 MapReduce
- 资源调度引擎 YARN

-
关键词:
- 分布式
- 主从架构
-
HDFS 模块主从架构:
- NameNode:主节点,主要负责集群的管理以及元数据信息管理
- DataNode:从节点,主要负责存储用户数据
- Secondary NameNode:辅助 NameNode 管理元数据信息,以及元数据信息的冷备份
-
YARN 模块:
- ResourceManager:主节点,主要负责资源分配
- NodeManager:从节点,主要负责执行任务