【操作系统导论】内存篇——分段
引入
利用基址和界限寄存器,操作系统很容易将不同进程重定位到不同的物理内存区域。
但是,对于一整个地址空间,在栈和堆之间存在一块空闲空间,如果将整个地址空间分配给进程,无疑造成了大量的内存浪费。
为了解决这个问题,分段 (segmentation) 的概念应运而生。
在典型的地址空间里划分 3 个段:代码段、栈段、堆段;为每个段配置一对基址界限寄存器。
分段机制使得 OS 能够将不同的段放到不同的物理内存区域,从而避免地址空间中的未使用部分占用实际物理内存。
分段机制
标识不同段
硬件在地址转换时,如何知道段内的偏移量,以及地址引用了哪个段(基址)?
**显式 (explicit) 方式:**用虚拟地址的开头几位来标识不同的段。
举例,假设地址空间划分为 3 个段,则可以用 14 位虚拟地址的前两位来标识,如下所示:

用虚拟地址的后 12 位作为段内偏移,与基址寄存器相加,就得到了最终的物理地址。
并且,偏移量简化了对段边界的判断:检查偏移量是否小于界限,大于界限的为非法地址。
**隐式 (implicit) 方式:**硬件通过地址产生的方式来确定段。
举例,类似段寄存器CS、DS、SS:
-
对于数据段,将它的段地址放在 DS 中;
-
对于代码段,将它的段地址放在 CS 中;
-
对于栈段,则将它的段地址放在 SS 中;
栈反向增长
需要注意的是,在虚拟内存和物理内存中,栈都是反向增长的。

因此,在进行地址转换时,计算方式有所不同:
假设要访问虚拟地址 15KB,对应二进制 11 1100 0000 0000,前 2 位标识栈段,后 12 位为偏移量 3KB;并假设段的大小为 4KB。
-
反向偏移量 = 3KB - 4KB = −1KB。
-
物理地址 = 反向偏移量 + 基址 = -1KB + 28KB = 27KB
用户可以进行界限检查,确保反向偏移量的绝对值小于段的大小。
代码段共享
随着分段机制不断改进,系统设计人员意识到,在地址空间之间共享某些内存段(代码段), 可以节省内存空间,提升效率。
为了支持共享,需要一些额外的硬件支持,这就是 保护位(protection bit)。
-
为每个段增加了几个位,来标识程序对该段的访问权限,即:读、写、执行;
-
如果将代码段标记为「读-执行」,则代码可以被多个进程共享,而不用担心破坏隔离。
问题分析
第一个是老问题:操作系统在上下文切换时应该做什么?
各个段寄存器中的内容必须保存和恢复。
每个进程都有自己的虚拟地址空间,OS 必须在进程运行前,确保这些寄存器被正确地赋值。
第二个问题:操作系统如何管理物理内存中的空闲空间?
在动态内存分配和释放的过程中,分配和释放的内存段不总是处于连续的位置,导致内存中出现许多零散的空闲内存,这些零散的内存不足以满足某个特定大小的内存请求,从而导致内存空间的浪费,这类问题被称为 外部碎片 (external fragmentation) 问题。
一种解决方案是:紧凑 (compact) 物理内存,重新安排原有的段。
但是,内存紧凑成本很高,因为拷贝段是内存密集型的,一般会占用大量的处理器时间。
另一种解决方案:利用空闲列表管理算法,试图保留大的内存块用于分配。
相关算法有几百上千种,包括:最优匹配、最坏匹配、首次匹配、伙伴算法;
遗憾的是,无论算法多么精妙,都无法完全消除外部碎片,因此,好的算法只是试图减小它。
空闲列表
在堆上管理空闲空间 的数据结构通常称为 空闲列表(free list)。
该结构包含了管理内存区域中所有空闲块的引用;空闲列表不一定真的是列表,只是某种可以追踪空闲空间的数据结构。
分割与合并
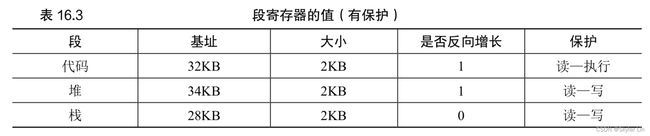
空闲列表包含一组元素,记录了堆中的哪些空间还没有分配。假设有下面的 30 字节的堆:

这个堆对应的空闲列表会有两个元素:

显然,大于 10 字节的分配请求会失败(返回 NULL);而恰好 10 字节的需求可以由两个空闲块中的任何一个满足。
但是,如果申请小于 10 字节空间,会发生什么?
假设申请了一个字节的内存,分配程序会执行 **分割(splitting)**操作:
找到一块可以满足请求的空闲空间,将其分割,第一块返回给用户,第二块留在空闲列表中。
可能得到以下结果:
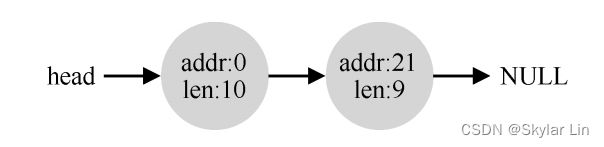
如果应用程序调用 free(10),归还堆中间的空间,会发生什么?
在释放一块内存时,分配程序会 **合并(coalescing)**可用空间:
如果待归还的内存块存在着相邻的空闲内存块,则将它们合并为一个较大的空闲内存块。
通过合并,空闲列表会回到其最初的样子:
释放内存块
free(void *ptr) 没有块大小的参数,它如何确定待释放空间的大小呢?
大多数分配程序会在 **头块(header)**中记录额外的信息,头块的定义如下:
typedef struct header_t
{
int size; // 分配空间的大小
int magic; // 幻数, 用于检验完整性
} header_t;
可想而知,用户在调用 free(void *ptr) 时,内存分配库会通过简单的指针运算得到头块的位置:
void free(void* ptr)
{
header_t* hptr = (void *)ptr - sizeof(header_t);
}
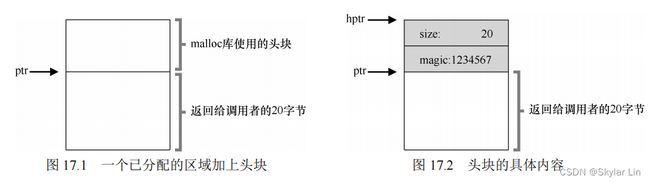
获得头块指针后,内存分配库通过幻数进行正常性检查 assert(hptr->magic == 1234567);;
并计算待释放空间的大小,即 头块大小 + 分配给用户的空间的大小 。
代码实现
现在,我们已经了解了空闲列表的概念,接着,我们用代码实现它!
typedef struct node_t
{
int size; // 空闲节点的大小
struct node_t *next; // 指向下一个节点
} node_t;
下面来初始化「堆」,假设「堆」的大小为 4096 字节,将空闲列表的第一个元素放在该空间中:
// mmap() returns a pointer to a chunk of free space
node_t* head = mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_ANON|MAP_PRIVATE, -1, 0);
head->size = 4096 - sizeof(node_t);
head->next = NULL;
如何,假设有一个 100 字节的内存请求,则空闲列表会有以下变化:

再来看下面的一个例子,应用程序调用 free(16500);,归还了中间的一块已分配空间:

基本策略
上面介绍了空闲列表的底层机制,现在来介绍一些 空闲分区算法 。
最佳适应
遍历空闲列表,选择最接近用户请求大小的空闲块,即 优先使用小空间,尽量避免空间浪费 。
可以将空闲分区按容量递增次序链接,每次分配内存时顺序查找空闲列表,找到大小能满足的第一个空闲分区。
最坏适应
遍历空闲列表,选择最大的空闲块,分割并满足用户需求后,将剩余的块加入空闲列表 。
可以将空闲分区按容量递减次序链接,每次分配内存时顺序查找空闲列表,找到大小能满足要求的第一个空闲分区。
首次适应
每次从 低地址 开始查找,找到第一个能满足用户请求大小的空闲分区。
可以将空闲分区按容量递增次序链接,每次分配内存时顺序查找空闲列表,找到大小能满足的第一个空闲分区。
邻近适应
额外维护一个指针,指向上一次查找结束的位置;
每次从上次查找结束的位置开始检索,找到第一个能满足用户请求大小的空闲分区。
简单总结:
-
最佳适应算法和最坏适应算法的开销较大。
-
首次适应算法和邻近适应算法的开销较小;