SpringCloud——微服务相关组件入门
前言
本篇博客为SpringCloud的一个简单入门,包含了SpringCloud全家桶的一些常用组件,供大家学习和参考,在每个组件介绍中均有官方文档的地址,推荐大家在学习过程中根据官方的文档中进行学习,毕竟技术更新迭代是很快的,同时还收集了相关的技术博客供大家参考。
想要学习SpringCloud其他组件的可以前往官网学习Spring Cloud
传统架构演进到分布式架构
高可用 LVS+keepalive
- 单体应用=》分布式架构=》微服务
- 单体应用
- 开发速度慢
- 启动时间长
- 依赖庞大
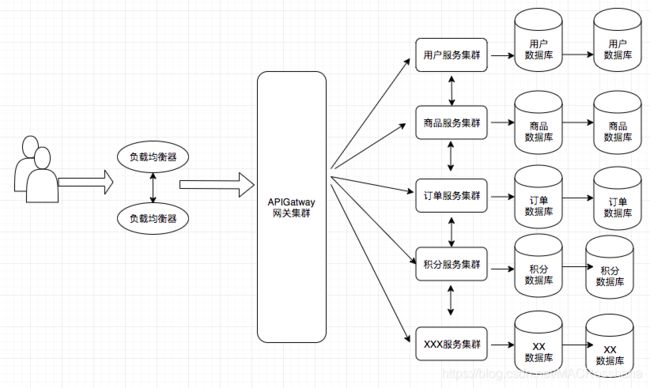
- 微服务
- 易开发、理解和维护
- 独立的部署和启动
- 不足
- 分布式系统-》分布式事务问题
- 需要管理多个服务-》服务治理
微服务核心基础
网关、服务发现注册、配置中心、链路追踪、负载均衡器、熔断
1、网关:路由转发 + 过滤器
2、服务注册发现:调用和被调用方的信息维护
3、配置中心:管理配置,动态更新 eg: SpringBoot的application.properties
4、链路追踪:分析调用链路耗时 eg:下单-》查询商品服务获取商品价格-》查询用户信息-》保存数据库
5、负载均衡器:分发负载
6、熔断:保护自己和被调用方
常见的微服务框架
consumer: 调用方
provider: 被调用方
一个接口一般都会充当两个角色(不是同时充当)
1、dubbo: zookeeper + dubbo + springmvc/springboot
官方地址:http://dubbo.apache.org/#!/?lang=zh-cn
配套
通信方式:rpc
注册中心:zookeper/redis
配置中心:diamond
2、springcloud: 全家桶+轻松嵌入第三方组件(Netflix 奈飞)
官网:http://projects.spring.io/spring-cloud/
配套
通信方式:http restful
注册中心:eruka/consul
配置中心:config
断路器:hystrix
网关:zuul
分布式追踪系统:sleuth+zipkin
[Dubbo和Spring Cloud微服务架构对比] https://blog.csdn.net/zhangweiwei2020/article/details/78646252
SpringCloud—注册中心
作用:服务管理,核心是有个服务注册表,心跳机制动态维护,SpringCloud的核心组件
- 服务提供者provider: 启动的时候向注册中心上报自己的网络信息
- 服务消费者consumer: 启动的时候向注册中心上报自己的网络信息,拉取provider的相关网络信息
好处
微服务应用和机器越来越多,调用方需要知道接口的网络地址,如果靠配置文件的方式去控制网络地址,对于动态新增机器,维护带来很大问题——总结:分布式系统中机器集群部署,维护较为困难,需要进行统一管理
主流的注册中心:zookeeper、Eureka、consul、etcd 等
| Feature | Consul | zookeeper | etcd | euerka |
|---|---|---|---|---|
| 服务健康检查 | 服务状态,内存,硬盘等 | (弱)长连接,keepalive | 连接心跳 | 可配支持 |
| 多数据中心 | 支持 | — | — | — |
| kv存储服务 | 支持 | 支持 | 支持 | — |
| 一致性 | raft | paxos | raft | — |
| cap | ca | cp | cp | ap |
| 使用接口(多语言能力) | 支持http和dns | 客户端 | http/grpc | http(sidecar) |
| watch支持 | 全量/支持long polling | 支持 | 支持 long polling | 支持 long polling/大部分增量 |
| 自身监控 | metrics | — | metrics | metrics |
| 安全 | acl /https | acl | https支持(弱) | — |
| spring cloud集成 | 已支持 | 已支持 | 已支持 | 已支持 |
SpringCloud—Eureka
- Eureka—英[juˈriːkə]
官方地址:https://cloud.spring.io/spring-cloud-netflix/reference/html/
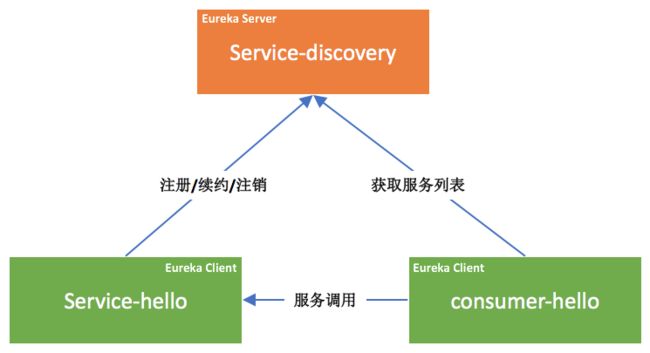
参考
https://www.jianshu.com/p/d32ae141f680
https://blog.csdn.net/zjcjava/article/details/78608892
SpringCloud—ribbon、feign
服务之间的调用方式
RPC:远程过程调用,像调用本地服务(方法)一样调用服务器的服务
支持同步、异步调用
客户端和服务器之间建立TCP连接,可以一次建立一个,也可以多个调用复用一次链接
优点:PRC数据包小
缺点:相比Rest较为复杂,涉及编解码,序列化,链接,丢包,协议
相关技术:protobuf、thrift
Rest:http请求,支持多种协议和功能
优点:开发方便成本低
缺点:http数据包大
java开发:HttpClient,URLConnection
ribbon
文档:https://docs.spring.io/spring-cloud-netflix/docs/2.2.4.RELEASE/reference/html/#spring-cloud-ribbon
method 1:
@Bean
@LoadBalanced
public RestTemplate restTemplate(){ return new RestTemplate();}
restTemplate.getForObject(url, Object.class);
method 2:
Using the Ribbon API Directly:
public class MyClass {
@Autowired
private LoadBalancerClient loadBalancer;
public void doStuff() {
ServiceInstance instance = loadBalancer.choose("stores");
URI storesUri = URI.create(String.format("https://%s:%s", instance.getHost(), instance.getPort()));
// ... do something with the URI
}
}
Customizing the Ribbon Client by Setting Properties: users=>Srping.application.name
users:
ribbon:
NIWSServerListClassName: com.netflix.loadbalancer.ConfigurationBasedServerList
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.WeightedResponseTimeRule
feign
文档:https://docs.spring.io/spring-cloud-openfeign/docs/2.2.4.RELEASE/reference/html/
Demo:
1)@EnableFeignClients
2)
@FeignClient(name = "Shopping-Mall")
public interface ShoppingMallClient {
@GetMapping("api/v1/pub/list/home_Commodity")
JsonData homeBanner();
}
3)
#Default optons readtimeout is 60s,but hystrix is 1s.
feign:
client:
config:
default:
connectTimeout: 2000
readTimeout: 2000
PS
1)、路径
2)、Http方法必须对应
3)、使用requestBody,应该使用@PostMapping
4)、多个参数的时候,通过@RequestParam(“id”) int id)方式调用
ribbon与feign选择
- 推荐使用
feign:- 默认集成了ribbon
- 写起来更加思路清晰和方便
- 采用注解方式进行配置,配置熔断等方式方便
SpringCloud—熔断、降级
熔断
熔断这一概念来源于电子工程中的断路器(Circuit Breaker)。在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。
降级
服务降级是从整个系统的负荷情况出发和考虑的,对某些负荷会比较高的情况,为了预防某些功能(业务场景)出现负荷过载或者响应慢的情况,在其内部暂时舍弃对一些非核心的接口和数据的请求,而直接返回一个提前准备好的fallback(退路)错误处理信息。这样,虽然提供的是一个有损的服务,但却保证了整个系统的稳定性和可用性。
二者的异同
-
相同点
- 目标一致 都是从可用性和可靠性出发,为了防止系统崩溃;
- 用户体验类似 最终都让用户体验到的是某些功能暂时不可用;
-
不同点
- 触发原因不同
- 服务熔断一般是某个服务(下游服务)故障引起
- 而服务降级一般是从整体负荷考虑
- 触发原因不同
Netflix—Hystrix
文档
https://github.com/Netflix/Hystrix
https://github.com/Netflix/Hystrix/wik
https://docs.spring.io/spring-cloud-netflix/docs/2.2.4.RELEASE/reference/html/#circuit-breaker-hystrix-clients
What Is Hystrix For?
Hystrix is designed to do the following:
- Give protection from and control over latency and failure from dependencies accessed (typically over the network) via third-party client libraries.
- Stop cascading failures in a complex distributed system.
- Fail fast and rapidly recover.
- Fallback and gracefully degrade when possible.
- Enable near real-time monitoring, alerting, and operational control.
查看默认策略—— HystrixCommandProperties.java
文档:https://github.com/Netflix/Hystrix/wiki/Configuration#execution.isolation.strategy
1)execution.isolation.strategy
THREAD— it executes on a separate thread and concurrent requests are limited by the number of threads in the thread-poolSEMAPHORE— it executes on the calling thread and concurrent requests are limited by the semaphore count
SEMAPHORE适用于接口并发量高的情况,如每秒数千次调用的情况,导致的线程开销过高,通常只适用于非网络调用,执行速度快
2)execution.isolation.thread.timeoutInMilliseconds 超时时间 默认 1000毫秒
3)execution.timeout.enabled 是否开启超时限制 (一定不要禁用)
4)execution.isolation.semaphore.maxConcurrentRequests 隔离策略为 信号量的时候,如果达到最大并发数时,后续请求会被拒绝,默认为10
HystrixDashboard(了解——不常用,实际项目做好监控报警)
Demo:
/**
* 监控报警
* @return
*/
private JsonData testRibbonFallback(HttpServletRequest request){
Runnable r = ()->{
String result = "系统负载过大,服务器已熔断降级";
System.out.println(result);
//TODO
};
Thread thread1 = new Thread(r);
thread1.start();
String result = "系统负载过大,服务器已熔断降级";
return JsonData.buildError(-1,result);
}
SpringCloud—网关
概念
API Gateway,是系统的唯一对外开放的入口,介于客户端和服务端之间的中间层,处理非业务功能,如提供路由请求、鉴权、监控、缓存、限流等功能
主要功能
1)统一接入
智能路由
AB测试、灰度测试
负载均衡、容灾处理
日志埋点(类似Nignx日志)
2)流量监控
限流处理
服务降级
3)安全防护
鉴权处理
监控
机器网络隔离
互联网主流的网关
- zuul:是Netflix开源的微服务网关,和Eureka,Ribbon,Hystrix等组件配合使用,Zuul 2.0比1.0的性能提高很多
- kong: 由Mashape公司开源的,基于Nginx的API gateway
- nginx+lua:是一个高性能的HTTP和反向代理服务器,lua是脚本语言,让Nginx执行Lua脚本,并且高并发、非阻塞的处理各种请求
Netflix——Zuul
Zuul中默认就已经集成了Ribbon负载均衡和Hystix熔断机制
文档:
https://docs.spring.io/spring-cloud-netflix/docs/2.2.4.RELEASE/reference/html/#router-and-filter-zuul
Netflix uses Zuul for the following:
- Authentication
- Insights
- Stress Testing
- Canary Testing
- Dynamic Routing
- Service Migration
- Load Shedding
- Security
- Static Response handling
- Active traffic management
Properties Demo
@EnableZuulProxy =>include @EnableCircuitBreaker
#ZuulProperties.java
server:
port: 9000
spring:
application:
name: api-gateway
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka
management:
endpoints:
web:
exposure:
include: "*"
#http://localhost:9000/actuator/routes 查看路由表需要配置
#自定义路由规则
zuul:
routes:
shopping-mall-service:
path: /apigateway/shopping-mall-service/**
serviceId: shopping-mall-service
test-service:
path: /apigateway/test-service/**
serviceId: test-service
ignored-patterns: /*-service/**
sensitive-headers: Set-Cookie,Authorization
ZuulFilter
Demo
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import com.netflix.zuul.exception.ZuulException;
import org.apache.commons.lang.StringUtils;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
import static org.springframework.cloud.netflix.zuul.filters.support.FilterConstants.PRE_TYPE;
/**
* 登录过滤器
*/
@Component
public class LoginFilter extends ZuulFilter {
/**
* 过滤器类型,前置过滤器
* @return
*/
@Override
public String filterType() {
return PRE_TYPE;
}
/**
* 过滤器顺序,越小越先执行
* @return
*/
@Override
public int filterOrder() {
return 4;
}
/**
* 过滤器是否生效
* @return
*/
@Override
public boolean shouldFilter() {
RequestContext requestContext = RequestContext.getCurrentContext();
HttpServletRequest request = requestContext.getRequest();
//项目规模大可以采用ACL
if ("XXX".equalsIgnoreCase(request.getRequestURI())){
return true;}
return false;
}
/**
* 业务逻辑
* @return
* @throws ZuulException
*/
@Override
public Object run() throws ZuulException {
//JWT
RequestContext requestContext = RequestContext.getCurrentContext();
HttpServletRequest request = requestContext.getRequest();
//token对象
String token = request.getHeader("token");
if(StringUtils.isBlank((token))){
token = request.getParameter("token");
}
//登录校验逻辑 根据公司情况自定义 JWT
if (StringUtils.isBlank(token)) {
requestContext.setSendZuulResponse(false);
requestContext.setResponseStatusCode(HttpStatus.UNAUTHORIZED.value());
}
requestContext.addZuulRequestHeader("XXX","X");
return null;
}
}
RateLimitFilter
Guava RateLimit
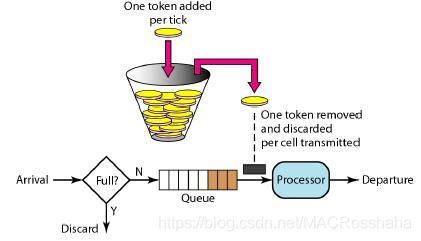
Demo
package org.macross.apigateway.filter;
import com.google.common.util.concurrent.RateLimiter;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import com.netflix.zuul.exception.ZuulException;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
import static org.springframework.cloud.netflix.zuul.filters.support.FilterConstants.PRE_TYPE;
@Component
public class RateLimitFilter extends ZuulFilter {
private static final RateLimiter RATE_LIMITER = RateLimiter.create(1000);
@Override
public String filterType() {
return PRE_TYPE;
}
@Override
public int filterOrder() {
return -4;
}
@Override
public boolean shouldFilter() {
RequestContext requestContext = RequestContext.getCurrentContext();
HttpServletRequest request = requestContext.getRequest();
return "XXX".equalsIgnoreCase(request.getRequestURI());
}
@Override
public Object run() throws ZuulException {
RequestContext requestContext = RequestContext.getCurrentContext();
if (!RATE_LIMITER.tryAcquire()){
requestContext.setSendZuulResponse(false);
requestContext.setResponseStatusCode(HttpStatus.TOO_MANY_REQUESTS.value());
}
return null;
}
}
网关Zuul集群搭建

zuul+nginx+lvs+keepalive 方案:https://www.cnblogs.com/liuyisai/p/5990645.html
SpringCloud—Sleuth、ZipKin
Sleuth
文档:https://docs.spring.io/spring-cloud-sleuth/docs/2.2.4.RELEASE/reference/html/
微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。——跟踪用户请求过程,追踪链路,
| 特点 | 说明 |
|---|---|
| 提供链路追踪 | 通过sleuth可以很清楚的看出一个请求经过了哪些服务, 可以方便的理清服务局的调用关系 |
| 性能分析 | 通过sleuth可以很方便的看出每个采集请求的耗时, 分析出哪些服务调用比较耗时,当服务调用的耗时 随着请求量的增大而增大时,也可以对服务的扩容提 供一定的提醒作用 |
| 数据分析 优化链路 | 对于频繁地调用一个服务,或者并行地调用等, 可以针对业务做一些优化措施 |
| 可视化 | 对于程序未捕获的异常,可以在zipkpin界面上看到 |
Demo:
![]()
1、spring.application.name的值
2、sleuth生成的一个ID,叫Trace ID,用来标识一条请求链路,一条请求链路中包含一个Trace ID,多个Span ID
3、Span ID 基本的工作单元,获取元数据,如发送一个http
4、是否要将该信息输出到zipkin服务中来收集和展示。
ZipKin
官网:https://zipkin.io/
Zipkin is a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems in service architectures. Features include both the collection and lookup of this data.
大规模分布式系统的APM工具(Application Performance Management),基于Google Dapper的基础实现,和sleuth结合可以提供可视化web界面分析调用链路耗时情况
zipkin组成:Collector、Storage、Restful API、Web UI组成
-
相关技术
- 鹰眼(EagleEye)
- CAT
- twitter开源zipkin,结合sleuth
- Pinpoint,运用JavaAgent字节码增强技术
- StackDriver Trace (Google)
-
知识拓展:OpenTracing
OpenTracing 已进入 CNCF,正在为全球的分布式追踪,提供统一的概念和数据标准。
通过提供平台无关、厂商无关的 API,使得开发人员能够方便的添加(或更换)追踪系统的实现。
Zipkin+Sleuth
收集跟踪信息通过http请求发送给zipkin server,zipkinserver进行跟踪信息的存储以及提供Rest API即可,Zipkin UI调用其API接口进行数据展示默认存储是内存,可也用mysql、或者elasticsearch等存储
文档:https://docs.spring.io/spring-cloud-sleuth/docs/2.2.4.RELEASE/reference/html/#sleuth-with-zipkin-via-http
Demo
spring:
zipkin:
base-url: http://112.124.18.163:9411/
sleuth:
sampler:
probability: 1
SpringCloud——config-server
-
配置中心的作用
- 统一管理环境,快速切换各个环境的配置
-
相关技术
- 百度的disconf 地址:https://github.com/knightliao/disconf
- 阿里的diamand 地址:https://github.com/takeseem/diamond
- springcloud的configs-server 地址:http://cloud.spring.io/spring-cloud-config/
configs-server
- git配置中心
- 相关技术:gitlab、github、开源中国git、阿里云git
Demo
1)@EnableConfigServer
2)application.yml
spring:
application:
name: config-server
#git配置
cloud:
config:
server:
git:
uri: XXX
username: XXX
password: XXX
#超时时间
timeout: 5
#分支
default-label: master
- 访问方式
- 多种访问路径,可以通过启动日志去查看
- 例子 http://localhost:9100/product-service.yml
/{name}-{profiles}.properties
/{name}-{profiles}.yml
/{name}-{profiles}.json
/{label}/{name}-{profiles}.yml
name 服务器名称
profile 环境名称,开发、测试、生产
lable 仓库分支、默认master分支
config-client
文档:https://cloud.spring.io/spring-cloud-config/reference/html/#_spring_cloud_config_client
Discovery First Bootstrap
If you use a DiscoveryClient implementation, such as Spring Cloud Netflix and Eureka Service Discovery or Spring Cloud Consul, you can have the Config Server register with the Discovery Service. However, in the default “Config First” mode, clients cannot take advantage of the registration.
If you prefer to use DiscoveryClient to locate the Config Server, you can do so by setting spring.cloud.config.discovery.enabled=true (the default is false). The net result of doing so is that client applications all need a bootstrap.yml (or an environment variable) with the appropriate discovery configuration. For example, with Spring Cloud Netflix, you need to define the Eureka server address (for example, in eureka.client.serviceUrl.defaultZone). The price for using this option is an extra network round trip on startup, to locate the service registration. The benefit is that, as long as the Discovery Service is a fixed point, the Config Server can change its coordinates. The default service ID is configserver, but you can change that on the client by setting spring.cloud.config.discovery.serviceId (and on the server, in the usual way for a service, such as by setting spring.application.name).
1)pom.xml
>
>org.springframework.cloud >
>spring-cloud-config-client >
>
2)bootstrap.yml
#指定注册中心地址
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
#服务的名称
spring:
application:
name: product-service
#指定从哪个配置中心读取
cloud:
config:
discovery:
service-id: CONFIG-SERVER
enabled: true
profile: test
#建议用lable去区分环境,默认是lable是master分支
#label: test