力扣刷题常用数据结构和方法(java版本)
1、基本数据结构:
数组(特别是二维数组,刚开始搞不清楚如何获取行和列,以及初始化):
//静态初始化
int[] intArr = new int[]{1,2,3,4,5,6};
//简化版
int[] intArr = {1,2,3,4,5,6};
//动态初始化
int[] intArr = new int[6];
//初始化二维数组
int[][] intMatrix = {{1,2},{3,4},{5,6}};
int[][] intMatrix = new int[3][2];
//获取数组长度
int rowLength = intMatrix.length;//行数
int colLength = intMatrix[0].length;//第0行列数
判断最大值最小值
//Float Double Byte Character Short Integer Long
Imax = Integer.MAX_VALUE;
Imin = Integer.MIN_VALUE;
java.lang.Math.max(参数1,参数2)是一个静态的工具方法Character
判断一个字符是否是数字字符
Character.isDigit(char c) 是则返回true,不是则返回false;
判断一个字符时候是字母
Character.isLowerCase(char c) || Character.isUpperCase(char c) LowerCase是小写,UpperCase是大写;
判断一个字符是字母或数字
Character.isLetterOrDigit(char c)
将字母转换为大写
Character.toUpperCase(char c);
将字母转换为小写
Character.toLowerCase(char c);String
String s = "asdefgasdefg";
for(int i = 0; i < s.length(); i++>){
char c = s.charAt(i);
}
s.indexOf('s') //retrun 1
s.indexof('s',2) //return 7
s.lastIndexOf('s') //return 7
s.lastIndexOf('s',6)//return 1
string[] ss = s.split("regex");
//参数:beginIndex - 开始处的索引(包括)
// endindex 结尾处索引(不包括)。
String s = s.substring((int)start,(int)end)//[start,end)
char[] cs = s.toCharArray();
String s = s.toLowerCase();
String s = s.toUpperCase();
String s = s.trim();
String s = String.valueOf(object);
StringBuilder & StringBuffer
StringBuilder sb = new StringBuilder("String");
sb.append("");
sb.reverse();
sb.delete((int)start,(int)end); //[start,end)
sb.deleteCharAt(int index);
sb.insert((int)offset,"String");
sb.toString();
sb.setCharAt((int)index,(char)c);
数组排序
Arrays.sort()是经过调优排序算法,性能能达到n*log(n)
Arrays.sort()重载了四类方法
sort(T[] a):对指定T型数组按数字升序排序。
sort(T[] a,int formIndex, int toIndex):对指定T型数组的指定范围按数字升序排序。
sort(T[] a, Comparator c): 根据指定比较器产生的顺序对指定对象数组进行排序。
sort(T[] a, int formIndex, int toIndex, Comparator c): 根据指定比较器产生的顺序对指定对象数组的指定对象数组进行排序。字典序:
字典排序是一种对于随机变量形成序列的排序方法,其方法是按照字母排列顺序,或数字顺序由小到大形成的的序列。
//简单给字符数组排序
/**
* 给字符串进行字典序排序
* @param str
* @return
*/
public static String dictSort(String str){
char[] chars = str.toCharArray();
Arrays.sort(chars); //可以转化成字符数组
return new String(chars);
}
/**
* 给字符串数组进行字典序排序
* @param strArr
* @return
*/
public static List dictSort(String[] strArr){
List list = Arrays.asList(strArr);//或者是利用list的sort方法
Collections.sort(list);
return list;
}
//如果是给不同的字符串呢
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.*;
public class 字典排序1 {
public static void sort(){
ArrayList arr = new ArrayList<>();
arr.add("red");
arr.add("8");
arr.add("pink");
arr.add("5");
arr.add("black");
arr.add("晨");
arr.add("write");
arr.add("张");
arr.add("7");
arr.add("purple");
arr.add("哗哗");
Collections.sort(arr, new Comparator() {
@Override
public int compare(String o1, String o2) {
try {
String str1 = new String(o1.toString().getBytes("GB2312"),"ISO-8859-1");
String str2 = new String(o2.toString().getBytes("GB2312"),"ISO-8859-1");
return str1.compareTo(str2);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return 0;
}
});
for(int i = 0;i < arr.size();i++){
System.out.println(arr.get(i));
}
}
public static void main(String[] args) {
sort();
}
}
JDK1.8集合框架
Collection接口
Collection接口是Set,List,Queue接口的父接口
//Collection
add(Object o);
addAll(Collection c);
clear();
contains(Object o);
remove(Object o);
size();
toArray();
Collections.sort(Collection c);
Collections.reverse(Collection c);
//List 有序集合,具有和索引有关的操作
ListMap 接口
HashTable,此类实现一个哈希表,该哈希表将键映射到相应的值。任何非 null 对象都可以用作键或值。
HashMap,基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)
LinkedHashMap,Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序,为插入顺序。
TreeMap,基于红黑树,该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
//HashMap
Map map = new HashMap<>();
map.put("key","value");
map.getOrDefault("key","default");//if(map.containsKey("key")) return "value" else return "default"
map.get("key"); //return "value";
map.containsKey("key");
方法1:使用For-Each迭代entries
这是最常见的方法,并在大多数情况下更可取的。当你在循环中需要使用Map的键和值时,就可以使用这个方法
for(Map.Entry entry : map.entrySet()){
entry.getKey();
entry.getValue();
}
2、map的遍历:如果你只需要用到map的keys或values时,你可以遍历KeySet或者values代替entrySet
Map map = new HashMap();
//iterating over keys only
for (Integer key : map.keySet()) {
System.out.println("Key = " + key);
}
//iterating over values only
for (Integer value : map.values()) {
System.out.println("Value = " + value);
}
栈、双端队列
Deque是一个线性表接口,可以两端进行元素的插入和删除。Deque是“Double ended Queue”的缩写,Deque读音[dɛk] 。使用Deque接口提供的方法就可以完成队列“先进先出”和堆栈“后进先出”的功能:
Deque有三种用途:
- 普通队列(一端进另一端出):
Queue queue = new LinkedList()或Deque deque = new LinkedList() - 双端队列(两端都可进出)
Deque deque = new LinkedList() - 堆栈
Deque deque = new LinkedList()
注意:Java堆栈Stack类已经过时,Java官方推荐使用Deque替代Stack使用。Deque堆栈操作方法:push()、pop()、peek()。
Deque是个接口,其实现类有:
- ArrayDeque,使用“数组”存储数据
- LinkedList,使用“链表”存储数据
- ConcurrentLinkedDeque,线程安全的LinkedList
下表总结了其12 种方法:
| 第一个元素 (头部) | 最后一个元素 (尾部) | |||
| 抛出异常 | 特殊值 | 抛出异常 | 特殊值 | |
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 删除(返回并删除) | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 检查(值返回不删除) | getFirst() | peekFirst() | getLast() | peekLast() |
add():Inserts the specified element at the tail of this queue. As the queue is unbounded, this method will never throw IllegalStateException or return false.
offer():Inserts the specified element at the tail of this queue. As the queue is unbounded, this method will never return false.
区别:两者都是往队列尾部插入元素,不同的时候,当超出队列界限的时候,add()方法是抛出异常让你处理,而offer()方法是直接返回false
Deque接口扩展(继承)了 Queue 接口。在将双端队列用作队列时,将得到 FIFO(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。从 Queue 接口继承的方法完全等效于 Deque 方法,如下表所示:
| Queue方法 | 等效Deque方法 |
| add add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
双端队列也可用作 LIFO(后进先出)堆栈。应优先使用此接口而不是遗留 Stack 类。在将双端队列用作堆栈时,元素被推入双端队列的开头并从双端队列开头弹出。堆栈方法完全等效于 Deque 方法,如下表所示:
| 堆栈方法 | 等效Deque方法 |
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
小顶堆PriorityQueue
PriorityQueue类在Java1.5中引入并作为 Java Collections Framework 的一部分。PriorityQueue是基于优先堆的一个无界队列,这个优先队列中的元素可以默认自然排序或者通过提供的Comparator(比较器)在队列实例化的时排序。
优先队列不允许空值,而且不支持non-comparable(不可比较)的对象,比如用户自定义的类。优先队列要求使用Java Comparable和Comparator接口给对象排序,并且在排序时会按照优先级处理其中的元素。
优先队列的头是基于自然排序或者Comparator排序的最小元素。如果有多个对象拥有同样的排序,那么就可能随机地取其中任意一个。当我们获取队列时,返回队列的头对象。
优先队列的大小是不受限制的,但在创建时可以指定初始大小。当我们向优先队列增加元素的时候,队列大小会自动增加。
PriorityQueue是非线程安全的,所以Java提供了PriorityBlockingQueue(实现BlockingQueue接口)用于Java多线程环境。
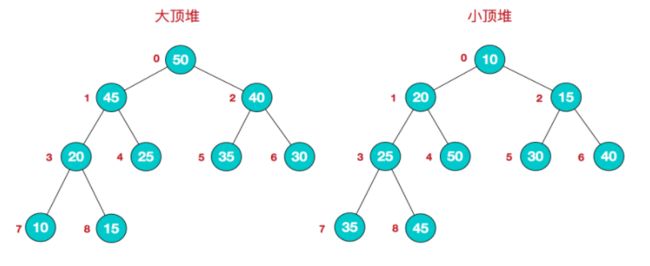
堆是一种非线性结构,(本篇随笔主要分析堆的数组实现)可以把堆看作一个数组,也可以被看作一个完全二叉树,通俗来讲堆其实就是利用完全二叉树的结构来维护的一维数组
按照堆的特点可以把堆分为大顶堆和小顶堆
大顶堆:每个结点的值都大于或等于其左右孩子结点的值
小顶堆:每个结点的值都小于或等于其左右孩子结点的值
参考文献:堆排序(大顶堆、小顶堆)----C语言 - 蓝海人 - 博客园
PriorityQueue天生是小顶堆,那么如果我要大顶堆怎么办?
// 默认实现了一个最小堆。
Queue priorityQueue = new PriorityQueue<>();
// 实现最大堆
Queue priorityQueue = new PriorityQueue(
lists.size(),
new Comparator(){
@Override
public int compare(ListNode o1, ListNode o2) { return o2.val-o1.val; }
}
);
一句话总结:默认最小堆,最大堆后面减前面
import java.util.PriorityQueue;
public class Test9 {
public static void main(String[] args) {
int[] a = {45,36,18,53,72,30,48,93,15,35};
//1,默认实现的是最小堆,元素按照natural ordering排序(自然排序,例如,数字的从小到大)
PriorityQueue minHeap = new PriorityQueue();
for(int i=0;i import java.util.Comparator;
import java.util.PriorityQueue;
public class Test9 {
public static void main(String[] args) {
int[] a = {45,36,18,53,72,30,48,93,15,35};
//2,通过比较器排序,实现最大堆
PriorityQueue maxHeap = new PriorityQueue(new Comparator() {
@Override
public int compare(Integer o1, Integer o2) {
/**以下是对比较器升序、降序的理解.
*(1) 写成return o1.compareTo(o2) 或者 return o1-o2表示升序
*(2) 写成return o2.compareTo(o1) 或者return o2-o1表示降序
*/
return o2.compareTo(o1);
}
}) ;
for(int i=0;i 常用ASCII码
数字0-9 :48~57.
26个大写字母:65~90.
26个小写字母:97~122.