MySQL高级应用-3
1 函数FUNCTION
概念
函数存储着一系列sql语句,调用函数就是一次性执行这些语句。所以函数可以降低语句重复。函数必须有返回值,有且只有一个返回值。
【但注意的是函数注重返回值,不注重执行过程,所以一些语句无法执行。所以函数并不是单纯的sql语句集合。】
1 创建
语法:
CREATE FUNCTION ``函数名(入参数列表)
RETURNS ``返回类型
BEGIN
函数体
RETURN 值;
END
注意:
参数列表包含: 参数名 参数类型
多个参数使用逗号隔开
函数体必须有 RETURN 语句
当函数体只有一句话时可以省略 BEGIN END
2 调用
SELECT ``函数名(参数列表);
3 自定义函数计算两个数的和
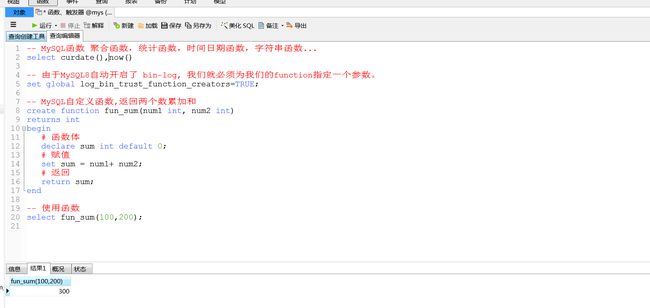
函数和存储过程的区别
①函数必须有返回值,有且仅有一个返回值,不允许返回一个结果集,适合做处理数据后返回一个结果
②存储过程没有返回值,但是可以有0或多个输出参数
③调用方式不同: call 存储过程 / select 函数
2 触发器TRIGGER
概念:
触发器是与表有关的数据库对象,指在 insert/update/delete 之前或之后,触发并执行触发器中定义的SQL语句集合。
触发器的这种特性可以协助应用在数据库端确保数据的完整性 , 日志记录 , 数据校验等操作 。
特殊两张表
使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。现在触发器还只支持行级触发,不支持语句级触发。
创建语法
CREATE TRIGGER``触发器名
BEFORE/AFTER INSERT/UPDATE/DELETE
ON``表名FOR EACH ROW
BEGIN
触发语句 ;
END;
删除语法
drop trigger [schema_name.]trigger_name;
如果没有指定 schema_name,默认为当前数据库 。
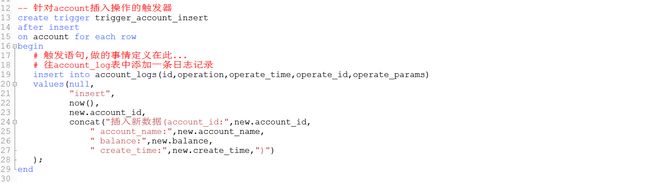
示例1:通过触发器记录 account 表的数据变更日志 , 包含增加, 修改 , 删除 ;
首先创建一张日志表 :
CREATE TABLE account_logs(
** id INT PRIMARY KEY AUTO_INCREMENT,
operation VARCHAR(20) COMMENT ‘操作类型, insert/update/delete’,
operate_time DATETIME COMMENT ‘操作时间’,
operate_id VARCHAR(36) COMMENT ‘操作行记录的ID’,
operate_params VARCHAR(500) COMMENT ‘操作参数’
);**
插入操作触发器
插入数据后,查看日志表: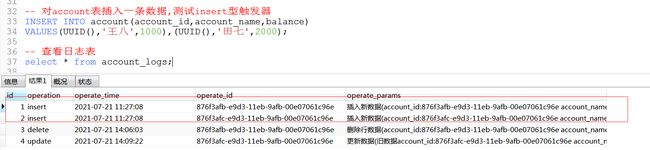
删除操作触发器

删除一条数据后,查看日志表: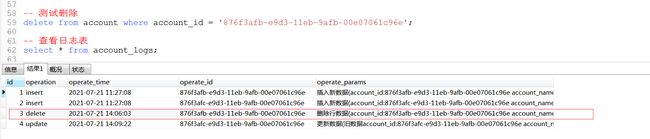
更新操作触发器
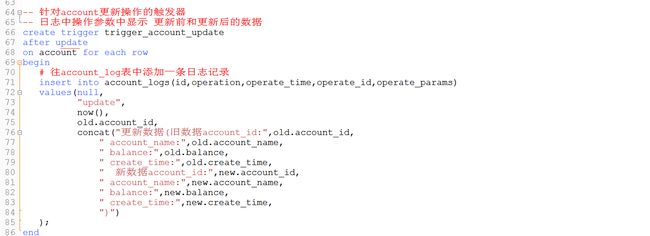
更新一条数据后,查看日志表: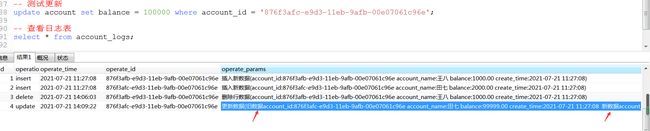
示例2:拓展更新触发器,多做一件事情
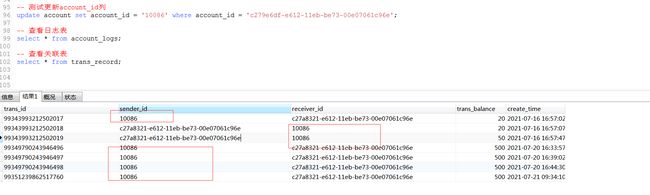
MySQL触发器指定表字段发生变化,更新关联表相关字段的值
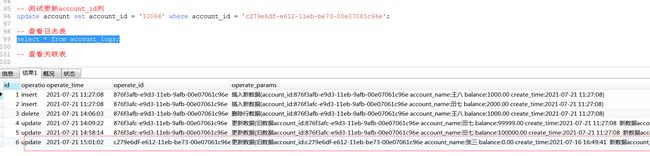
例如:当对account表进行修改,而修改的是编号account_id这个列,则关联的表中trans_record该字段也同时进行修改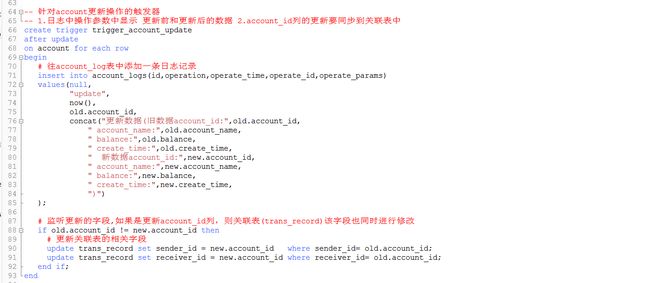
3 存储引擎(表类型)
存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式 。
存储引擎是基于表的,而不是基于库的。所以存储引擎也可被称为表类型。
可以通过show engines;, 来查询当前数据库支持的存储引擎 :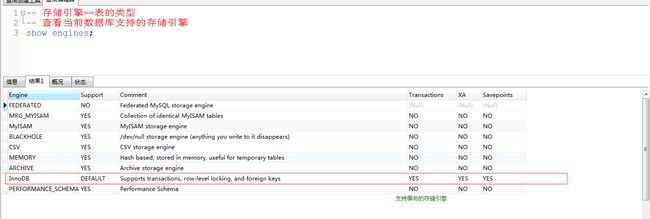
几种常用的存储引擎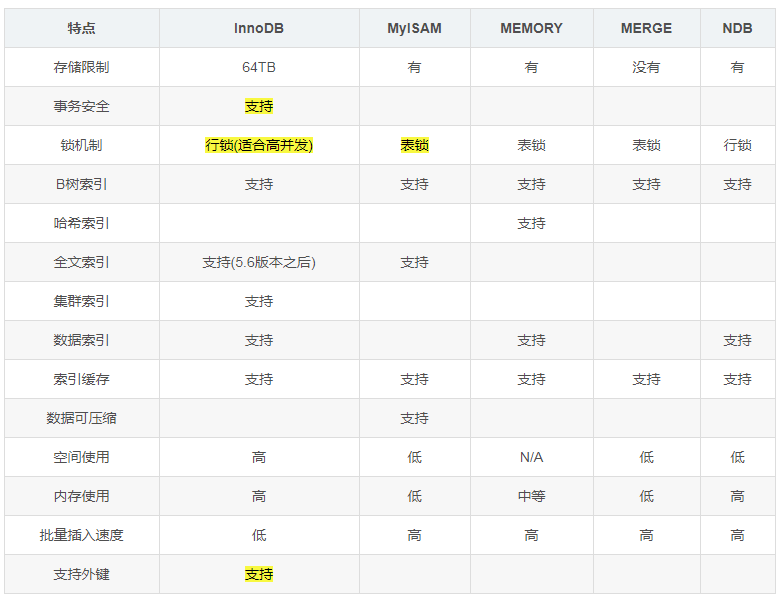
存储引擎的选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。
4 索引
4.1概念
索引是帮助MySQL高效获取数据的数据结构(有序)。
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。
因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
4.2索引类型
MySQL目前主要有以下几种索引类型:BTREE,HASH,RTREE,FULLTEXT,。
B树索引(BTREE): 最常见的索引类型,大部分存储引擎都支持 BTree索引,InnoDB默认使用的是BTree 索引模型。
哈希索引(HASH):只有Memory引擎支持 , 使用场景简单 。
R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少。
全文索引 (Full-text):全文索引也是MyISAM的一个特殊索引类型,InnoDB从MySQL5.6版本开始支持全文索引。
4.3索引分类
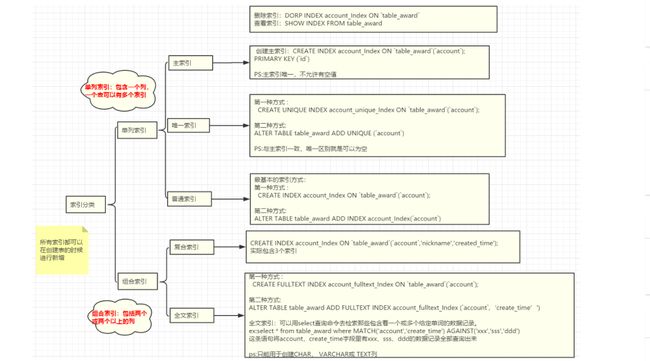
普通索引:仅加速查询
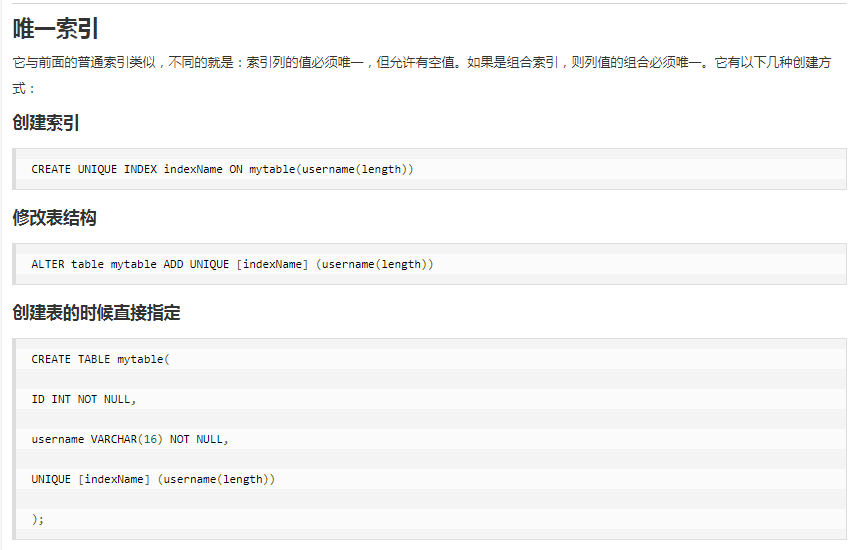
唯一索引:加速查询 + 列值唯一(可以有null)
主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,进行搜索
4.4什么时候建立索引?
1,主键自动建立唯一索引
2,经常用作查询条件的字段需要创建索引
3,查询中与其他表关联的字段,外键关系建立索引
4,经常需要排序、分组和统计的字段需要建立索引
4.5哪些情况不要建索引:
1,表的记录太少,百万级以下的数据不需要创建索引,
2,经常增删改的表不需要创建索引-因为更新表的同时,同步更新索引
3,数据重复且分布平均的字段不需要创建索引,如 true,false 之类。
4,频发更新的字段不适合创建索引
5,where条件里用不到的字段不需要创建索引
4.6什么时候索引失效?
1. 条件中有or,即使其中有条件带索引也不会生效
2. 对于多列索引,不是使用的第一部分,则索引不会生效
3. like查询以通配符开头(以%开头),mysql索引失效会变成全表扫描的操作
4. 字符串不加单引号,则索引不会生效
5. mysql在使用不等于的时候,则索引不会生效
6. 查询的数量是大表的大部分,则索引不会生效
4.7查看索引
SHOW INDEX FROM ``表名;
4.8删除索引
DROP INDEX``索引名ON ``表名
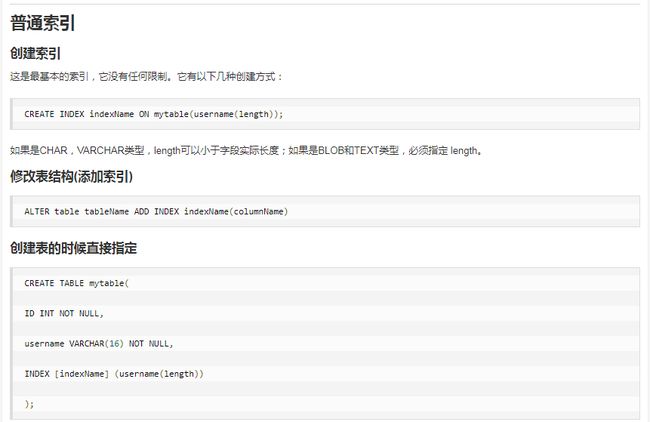
4.8创建索引
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
语法:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX``索引名
[USING ``索引类型]#如果不指定则为B+Tree
ON ``表名(列名,…)
例:给city表的city_name列创建索引
CREATE INDEXindex_city_citynameON city(city_name);

4.10使用ALTER 命令为表添加索引
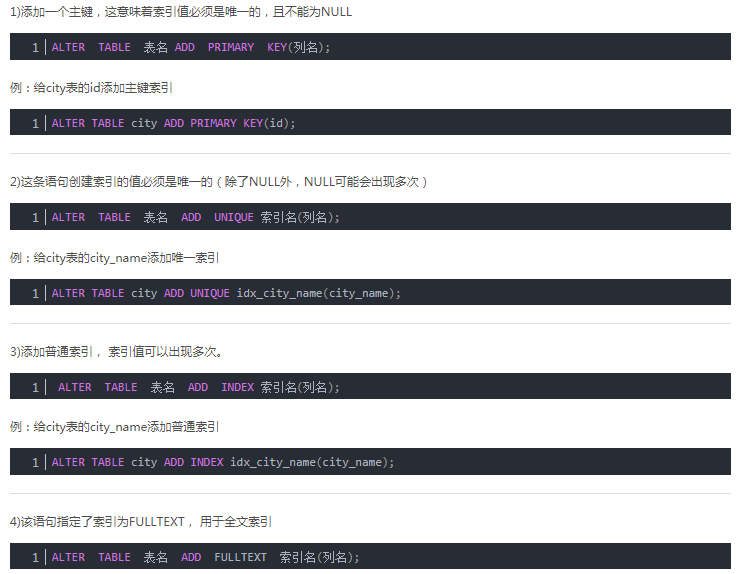
4.11使用explain分析执行计划
查询SQL语句的执行计划 : EXPLAIN SELECT * FROM employees;
查看SQL查询的类型和使用的实际索引等信息
4.12使用show profile分析SQL执行时间
通过show profiles,我们能够更清楚地了解SQL执行的过程。
通过show profile for query query_id查看具体某一条sql语句的执行各个阶段耗时:
分析计划具体知识查看该博文:
https://blog.csdn.net/qq_41112238/article/details/104004400?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-13.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-13.nonecase
示例:
创建表tab_test表,使用存储过程插入5万条数据
create table tab_test(
id int,
name varchar(20) not null,
status char(1) not null,
primary key(id)
)
插入数据
id:1-50000
name=”name+id”
status 根据 id是奇数状态0 偶数状态1
查看表索引情况:

演示1:查询所有–>无索引

演示2:根据主键查询->唯一索引
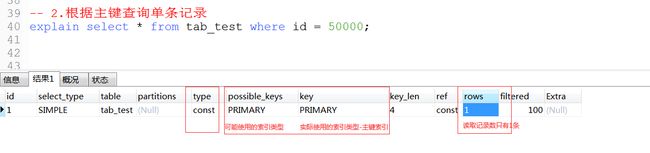
演示3:根据name查询->无索引
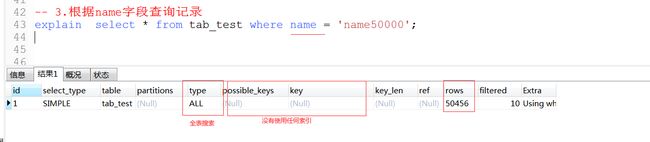
演示4::为name添加普通索引,再查询
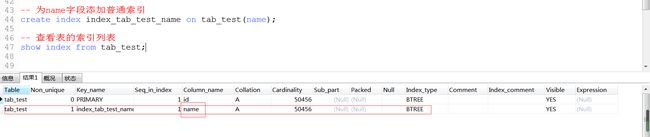
再查一次
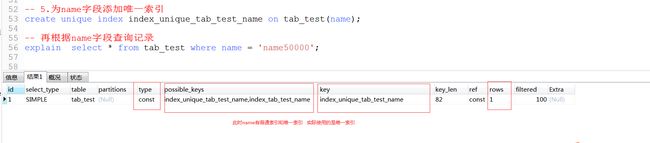
演示5:为name添加唯一索引,再查询
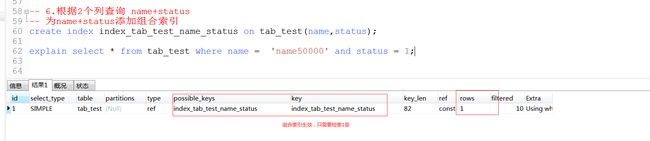
演示6:先删除上面的唯一索引和普通索引,为name和status列添加组合索引

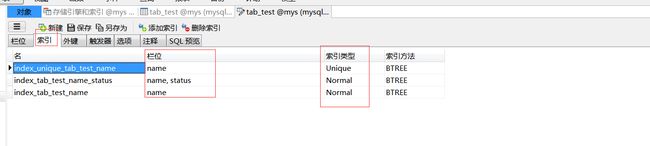
演示7:索引失效情况…

like查询以通配符开头(以%开头),索引失效会变成全表扫描的操作

5 SQL语法优化方法
1对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 涉及的查询频繁的列上建立索引
2杜绝直接 SELECT * 读取全部字段
3 能确定返回结果只有一条时,使用 limit 1:在保证数据不会有误的前提下,能确定结果集数量时,多使用 limit,尽快的返回结果
4 少用子查询,改用 join
5考虑使用 union all,少使用 union,注意考虑去重,union all 不去重,而少了排序操作,速度相对比 union 要快,如果没有去重的需求,优先使用 union all
6 避免使用 is null, is not null 这样的比较
7 减少与数据库交互的次数
8 杜绝危险 SQL,例如where 1=1 会遭到SQL注入式攻击
9 可以使用分库分区…
10 …