【域适应十三】2023-CVPR Patch-Mix Transformer for Unsupervised Domain Adaptation: A GamePerspective
1.motivation
最近,很多工作致力于利用视觉转换器(ViT)来完成具有挑战性的无监督域适应(UDA)任务。它们通常采用ViT中的Cross Attention进行直接的域对齐(CDTrans)。然而,由于Cross Attention的性能高度依赖于目标样本的伪标签质量,当域间隙较大时,域对齐的效果就会降低。
为了解决这一问题,本文从博弈的角度,提出了一个被称为PMTrans的模型,用一个中间域(使用源域patches和目标域patches通过线性插值组成)连接了源域和目标域,并且通过一个新提出的PatchMix模块和特征提取器(ViT)、分类器进行Min-Max博弈来对齐中间域和源域/目标域。
2.Method:PatchMix

PMTrans将UDA的过程解释为具有三个参与者的Min-Max CE(交叉熵)博弈,包括特征提取器,分类器和PatchMix。PatchMix模块通过学习使用基于博弈论模型的可学习beta分布生成的权重对两个域的patch进行采样,来有效地建立中间域,即概率分布。
PatchMix试图最大化中间域和源/目标域之间的CE,而特征提取器和分类器试图最小化CE来对齐域,一直达到参数稳定的均衡状态。如果混合来自两个域的混合patch表示等同于混合相应的标签,那么源域和目标域是对齐的。因此,最小化混合patch和混合标签之间的CE可以有效地促进域对齐。
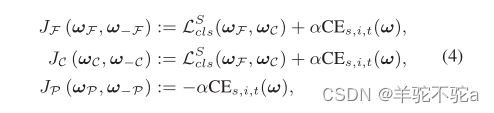
2.1 PatchMix
PatchMix模块通过线性插值将源域和目标域的patches组合形成中间域的patches:

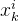 表示由源域第k个patch和目标域第k个patch线性组成的中间域的第k个patch。其中
表示由源域第k个patch和目标域第k个patch线性组成的中间域的第k个patch。其中 ∈[0,1] 随机采样自
∈[0,1] 随机采样自 ![]() 分布,这是一个可学习的分布,可学习参数为
分布,这是一个可学习的分布,可学习参数为![]() 。
。
中间域标签![]() 则是根据插值权重之和来决定源域标签
则是根据插值权重之和来决定源域标签![]() 和目标域标签
和目标域标签![]() 的权重。
的权重。
然而这种中间域标签忽略了不同patch对分类的贡献不同,为此,引入了ViT编码器中的类token与第k个image patch的归一化的注意力得分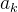 ,上式变为:
,上式变为:

在后续的训练中并未用到中间域标签,但源域标签权重和目标域标签权重分别用于衡量中间域源域CE损失和中间域目标域CE损失的重要性。
2.2 Semi-supervised mixup loss

PMTrans的损失函数由源域上的交叉熵损失 ,标签空间的中间域与源域/目标域的半监督损失
,标签空间的中间域与源域/目标域的半监督损失![]() 、
、 ![]() ,特征空间的中间域与源域/目标域的半监督损失
,特征空间的中间域与源域/目标域的半监督损失![]() 、
、 ![]() 组成。
组成。
源域上的交叉熵损失:
![]()
其中F表示特征提取器(Transformer编码器),C表示分类器,L为交叉熵损失函数。
PatchMix试图最大化中间域和源域/目标域的CE损失,特征提取器和分类器则在训练中最小化中间域和源域/目标域的CE损失,即标签空间的![]() 、
、 ![]() 和特征空间的
和特征空间的![]() 、
、 ![]() 。
。
lable space:
将中间域的logits与源域标签和目标域伪标签计算交叉熵损失,如下所示:
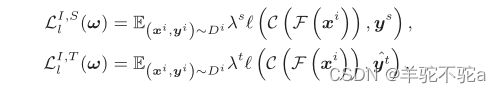
其中![]() 和
和![]() 为源域标签权重和目标域标签权重。L为交叉熵损失。
为源域标签权重和目标域标签权重。L为交叉熵损失。![]() 为源域标签,
为源域标签,![]() 通过k-means聚类所得的目标域伪标签。
通过k-means聚类所得的目标域伪标签。
feature space:
由于目标数据的伪标签不太可靠,标签空间中的监督损失不足以减少域发散。因此,进一步提出在不需要目标域的监督信息的情况下,最小化特征空间中特征相似度与标签相似度之间的差异的特征空间损失。 首先,特征相似度通过计算中间域特征和源域/目标域特征之间的余弦相似度得到:
![]()
这是一个B×B的矩阵,B为Batch Size,表示每个中间域样本的特征与每个源域样本的特征的相似度。
中间域和源域的标签相似度![]() ,也是一个B×B的矩阵,第j个中间域样本对应第j个源域样本,所以
,也是一个B×B的矩阵,第j个中间域样本对应第j个源域样本,所以![]() 设为1,然后对于
设为1,然后对于![]() ,若第k个源域样本的标签和第j个源域样本的标签一致则为1,否则为0。
,若第k个源域样本的标签和第j个源域样本的标签一致则为1,否则为0。 ![]() 可由下式计算:
可由下式计算:

对于中间域和目标域的标签相似度![]() ,使用B×B的单位矩阵。这表示只能确定第j个中间域样本和第j个目标域样本相似,无法确定与其它目标域样本是否相似。 如图(b)所示,由源域闹钟样本构成的中间域样本与其它源域闹钟样本的相似度为1;而对于目标域样本,只能确定中间域样本与构成成分的目标样本的相似度为1。
,使用B×B的单位矩阵。这表示只能确定第j个中间域样本和第j个目标域样本相似,无法确定与其它目标域样本是否相似。 如图(b)所示,由源域闹钟样本构成的中间域样本与其它源域闹钟样本的相似度为1;而对于目标域样本,只能确定中间域样本与构成成分的目标样本的相似度为1。
特征空间中中间域和源域/目标域之间的差异如下所示:

![]()
最后,将特征空间和标签空间中的两个半监督混合损失表示为:
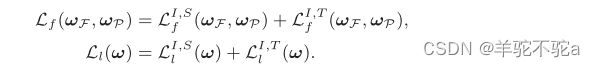
Min-Max CE博弈的目标是在特征和标签空间中对齐分布。中间域与源/目标域之间的总CE损失为:
![]()
加上源域的交叉熵损失即为PMTrans的总目标:
![]()
其中α是权衡参数。优化目标后,具有理想Beta分布的PatchMix模块将不再最大化CE。同时,特征提取器和分类器也就没有动力改变它们的参数来最小化CE,这时达到平衡,中间域与源域/目标域对齐良好。
3.实验
本文在四个流行的UDA基准数据集上进行了实验,包括Office-Home、Office-31、VisDA-2017和DomainNet。


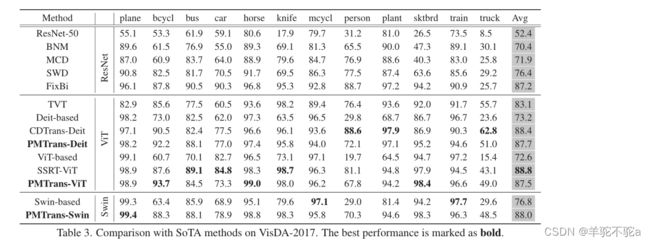
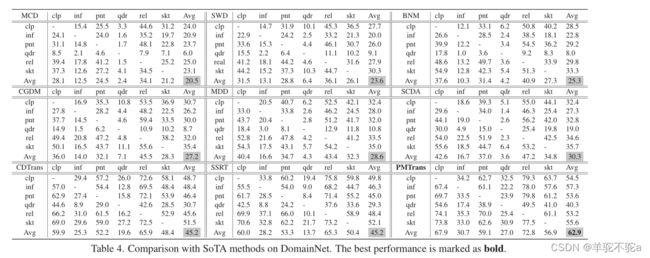
下面是对标签空间和特征空间的半监督损失函数的消融实验,结果表明,半监督混合损失在减小域差异方面是有效的

Beta分布的可学习超参数![]() 对Office-Home影响的消融结果。
对Office-Home影响的消融结果。

PMTrans与全局混合Mixup和局部混合CutMix的比较如表7所示。
