Hadoop学习笔记(17)Hive的数据类型和文件编码
一、Hive的常用内部命令
- 1、有好几种方式可以与Hive进行交互。此处主要是命令行界面(CLI)。
- 2、$HIVE_HOME/bin目录下包含了可以执行各种各样Hive服务的可执行文件,包括hive命令行界面(CLI是使用Hive的最常用方式)。
[admin@master ~]$ cd apache-hive-1.2.2-bin/bin
[admin@master bin]$ ls
beeline ext hive hive-config.sh hiveserver2 metatool schematool
- 3、输入命令hive --help可以查看到hive命令的一个简明说明的选项列表。
[admin@master ~]$ hive --help
Usage ./hive --service serviceName
Service List: beeline cli help hiveburninclient hiveserver2 hiveserver hwi jar lineage metastore metatool orcfiledump rcfilecat schemaTool version
Parameters parsed:
--auxpath : Auxillary jars
--config : Hive configuration directory
--service : Starts specific service/component. cli is default
Parameters used:
HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory
HIVE_OPT : Hive options
For help on a particular service:
./hive --service serviceName --help
Debug help: ./hive --debug --help
[admin@master ~]$
(1)–auxpath选项允许用户指定一个以冒号分割的“附属的”Java包(JAR),这些文件中包含有用户可能需要的自定义扩展等。用户个性化的需求。
(2)–config文件目录这个命令允许用户覆盖$HIVE_HOME/conf中默认的属性配置,而指向一个新的配置文件目录。但一般不使用这个命令,而是在如下目录中新建hive-site.xml配置属性。
[admin@master ~]$ cd apache-hive-1.2.2-bin/conf
[admin@master conf]$ ls
beeline-log4j.properties.template hive-env.sh.template hive-log4j.properties.template ivysettings.xml
hive-default.xml.template hive-exec-log4j.properties.template hive-site.xml
- 4、执行shell命令
(1)用户不要退出hive CLI就可以执行简单的bash shell命令,需要在命令加上感叹号“!”,并且以“;”结尾。
hive> !pwd;
/home/admin
hive> !ls -ll;
总用量 315228
-rw-rw-r--. 1 admin admin 240 12月 7 06:46 _
drwxrwxr-x. 8 admin admin 159 3月 13 21:11 apache-hive-1.2.2-bin
-rw-rw-r--. 1 admin admin 90859180 3月 13 21:09 apache-hive-1.2.2-bin.tar.gz
-rw-rw-r--. 1 admin admin 14 2月 24 22:04 a.txt
drwxr-xr-x. 10 admin admin 161 2月 21 21:24 hadoop-2.5.2
-rw-rw-r--. 1 admin admin 147197492 2月 21 14:18 hadoop-2.5.2.tar.gz
drwxrwxr-x. 4 admin admin 56 3月 20 20:34 hadoopdata
-rw-rw-r--. 1 admin admin 19903532 3月 14 02:10 MySQL-client-5.6.22-1.el7.x86_64.rpm
-rw-rw-r--. 1 admin admin 875336 3月 17 22:19 mysql-connector-java-5.1.28.jar
-rw-rw-r--. 1 admin admin 3533816 3月 14 02:10 MySQL-devel-5.6.22-1.el7.x86_64.rpm
-rw-rw-r--. 1 admin admin 60406096 3月 14 02:10 MySQL-server-5.6.22-1.el7.x86_64.rpm
drwxrwxr-x. 2 admin admin 29 3月 2 23:28 sogou.500w
drwxrwxr-x. 3 admin admin 37 2月 21 23:20 test
drwxr-xr-x. 2 admin admin 6 12月 7 02:35 公共
drwxr-xr-x. 2 admin admin 6 12月 7 02:35 模板
drwxr-xr-x. 2 admin admin 6 12月 7 02:35 视频
drwxr-xr-x. 2 admin admin 6 12月 7 02:35 图片
drwxr-xr-x. 2 admin admin 6 12月 7 02:35 文档
drwxr-xr-x. 2 admin admin 6 12月 7 02:35 下载
drwxr-xr-x. 2 admin admin 6 12月 7 02:35 音乐
drwxr-xr-x. 2 admin admin 6 12月 7 02:35 桌面
(2)Hive CLI中不能使用需要用户进行输入的交互式命令,而且不支持shell的“管道”功能和文件名的自动补全功能。何为“shell的“管道”功能和文件名的自动补全功能”可从这篇好文章了解https://blog.csdn.net/weixin_45116657/article/details/94721926
- 5、在Hive内使用Hadoop的dfs命令
(1)用户可以在hive CLI中执行hadoop的dfs命令,只需将关键字hadoop去掉,然后以分号结尾。(如下两种方式)
[admin@master ~]$ hadoop fs -ls /user
Found 2 items
drwxr-xr-x - admin supergroup 0 2021-02-28 15:31 /user/admin
drwxr-xr-x - admin supergroup 0 2021-03-20 10:44 /user/hive
hive> dfs -ls /user;
Found 2 items
drwxr-xr-x - admin supergroup 0 2021-02-28 15:31 /user/admin
drwxr-xr-x - admin supergroup 0 2021-03-20 10:44 /user/hive
(2)这样使用hadoop命令的方式实际上比与其等价的在bash shell中执行的hadoop dfs -命令更加高效。因为后者每次都会启动一个新的JVM实例,而启动hive时就会JVM,且hive会在同一个进程中执行这些命令。
二、基本数据类型
HIVE有两大类数据类型:基本类数据类型、集合类数据类型。
- 1、Hive支持多种不同长度的整型和浮点型数据类型,支持布尔类型,也支持无长度限制的字符串类型。Hive v0.8.0版本增加了时间戳数据类型和二进制数组数据类型。
| 数据类型 | 长度 | 例子 |
|---|---|---|
| TINYINT | 1byte 有符号整数 | 20 |
| SMALINT | 2byte 有符号整数 | 20 |
| INT | 4byte 有符号整数 | 20 |
| BIGINT | 8byte 有符号整数 | 20 |
| BOOLEAN | 布尔类型,true或者false | TRUE |
| FLOAT | 单精度浮点数 | 3.14159 |
| DOUBLE | 双精度浮点数 | 3.14159 |
| STRING | 字符串列。可以指定字符集。可以使用单引号或者双引号 | ‘NOW IS THE TIME’,“就是现在” |
| TIMESTAMP(版本v0.8.0+) | 整数,浮点数或者字符串 | 1327882394(Unix新纪元秒),1327882394,123456789(Unix新纪元秒并跟随有纳秒数)和’2012-02-03 12:34:56.123456789’(JDBC所兼容的 java.sql.Timestamp时间格式) |
| BINARY(版本v0.8.0+) | 字节数组 |
- 2、需要注意所有的数据类型都是对java中的接口的实现,因此这些类型的具体行为细节和java中对应的类型是完全一致的。例如,string类型实现的是java的string,float实现的是java中的float等。
- 3、新增的数据类型TIMESTAMP的值可以是整数,也就是距离Unix新纪元时间(1970年1月1日,午夜12点)的秒数(即是时间戳);也可以是浮点数,也就是距离Unix新纪元时间(1970年1月1日,午夜12点)的秒数,精确到纳秒(小数点后保留9位数);还可以是字符串,即JDBC所约定的时间字符串格式,格式为YYYY-MM-DD hh:mm:ss.fffffffff。
- 4、TIMESTAMPS表示的是UTC时间。Hive本身提供了不同时区间互相转换的内置函数,也就是to_utc_timestamp函数和from_utc_timestamp函数。
- 5、BINARY数据类型和很多关系型数据库的VARBINARY数据类型是类似的,但其和BLOB数据类型并不相同。因为BINARY的列是存储在记录中的,而BLOB则不同。BINARY可以在记录中包含任意字节,这样可以防止Hive尝试将其作为数字,字符串等进行解析。
- 6、如果用户在查询中将一个float类型的列和一个double类型的列作对比或者将一种整型类型的值和另一种整型类型的值做对比,那么结果将会怎么样呢?Hive会隐式地将类型转换为两个整型类型中值较大的那个类型,也就是将float类型转换为double类型,而且如有必要,也会将任意的整型类型转换为double类型,因此事实上是同类型之间的比较。
三、基本数据类型案例
- 1、创建student表
hive> create database test_01;
OK
Time taken: 0.164 seconds
hive> show databases;
OK
default
sougou
test_01
Time taken: 0.024 seconds, Fetched: 3 row(s)
hive> use test_01;
OK
Time taken: 0.039 seconds
hive> create table student(id bigint,name string,score double,age int) row format delimited fields terminated by "\t";
OK
Time taken: 0.247 seconds
hive> show tables;
OK
student
Time taken: 0.036 seconds, Fetched: 1 row(s)
hive> describe student;
OK
id bigint
name string
score double
age int
Time taken: 0.273 seconds, Fetched: 4 row(s)
hive>
- 在linux本地创建一个简单的student表以及创造几条数据,然后写入到hive的student表
(1)在linux本地创建一个简单的student表以及创造几条数据
[admin@master ~]$ vim student.txt

(2)写入到hive的student表
hive> load data local inpath '/home/admin/student.txt' into table student;

(3)查看hive的test_01库和student表的相关信息
在创建student后,可以在mysql查看到test_01库和student的元信息。可以查看到所有hive的db信息都是放在mysql的DBS表中。所有hive的表信息放在mysql的TBLS表中。字段信息放在mysql的COLUMNS_V2表中。

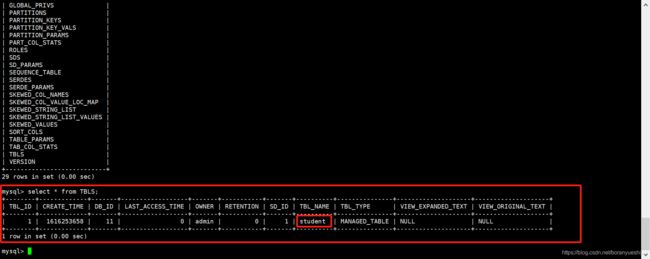
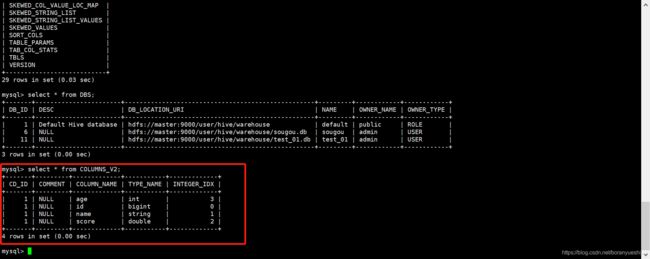
同时,在HDFS中,在如下目录可以查看到hive的表数据存放
hive> dfs -ls /user/hive/warehouse/test_01.db/student;
Found 2 items
-rwxr-xr-x 2 admin supergroup 67 2021-03-20 23:46 /user/hive/warehouse/test_01.db/student/student.txt
-rwxr-xr-x 2 admin supergroup 67 2021-03-20 23:52 /user/hive/warehouse/test_01.db/student/student_copy_1.txt
(4)故,验证了hive的概念
- Hive的元信息是存放在mysql数据库(默认是derby数据库,但替换成了mysql数据库)
- Hive的数据信息存放在目录hive> dfs -ls /user/hive/warehouse的对应database中
四、集合数据类型
- 1、Hive中的列支持使用struct、map和array集合数据类型。需要主要的是如下表中的语法示例实际上是调用的是内置函数。
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 和C语言中的struct或者“对象”类似,都可以通过“点”符合访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING,last STRING},那么第一个元素可以通过字段名first来引用 | struct(‘john’,‘doe’) |
| MAP | MAP是一组键-值对元组集合,使用数组表示法(例如[‘key’])可以访问元素。 | map(‘first’,‘john’,‘last’,‘doe’) |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。 | array(‘john’,‘doe’) |
- 2、和基本数据类型一样,这些类型同样是保留字。大多数的关系型数据库并不支持这些集合数据类型,因为使用它们会趋于破坏标准格式。例如,在传统数据模型中,structs可能需要由多个不同的表拼装而成,表间需要适当地使用外键来进行连接。
- 3、破坏标准格式所带来的一个实际问题是会增大数据冗余的风险,进而导致消耗不必要的磁盘空间,还有可能造成数据不一致,因为当数据发生改变时冗余的拷贝数据可能无法进行相应的同步。
- 4、然而,在大数据系统中,不遵守标准格式的一个好处就是可以提供更高吞吐量的数据。当处理的数据的数据量级是TB或者PB时,以最少的“头部寻址”来从磁盘上扫描数据是非常必要的。按数据集进行封装的话可以通过减少寻址次数来提供查询的速度。而如果根据外键关系关联的话则需要进行磁盘间的寻址操作,这样会非常高的性能消耗。
四、集合数据类型案例
1、STRUCT类型案例
在test_01库中创建表STRUCT结构的表
hive> create table struct_test(id int,info struct,age:int>) row format delimited fields terminated by ',' collection items terminated by ':';

在linux本地创建一个简单的struct_test表以及创造几条数据
[admin@master ~]$ vim struct_test.txt
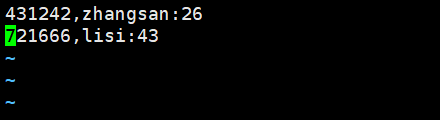
写入到hive的struct_test表并查询
hive> load data local inpath '/home/admin/struct_test.txt' into table struct_test;

2、ARRAY类型案例
在test_01库中创建表ARRAY结构的表
hive> create table array_test(class_name string,student_name_list array) row format delimited fields terminated by ',' collection items terminated by ':';

在linux本地创建一个简单的array_test表以及创造几条数据
[admin@master ~]$ vim array_test.txt
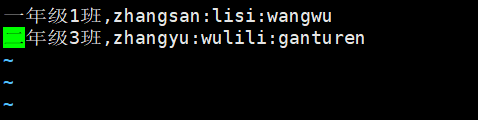
写入到hive的array_test表并查询
hive> load data local inpath '/home/admin/array_test.txt' into table array_test;

3、MAP类型案例
在test_01库中创建表MAP结构的表
hive> create table map_test(name string,score map,int>) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':';

在linux本地创建一个简单的map_test表以及创造几条数据
[admin@master ~]$ vim map_test.txt

写入到hive的map_test表并查询
hive> load data local inpath '/home/admin/map_test.txt' into table map_test;

五、基本数据类型与集合数据类型的综合应用案例
- 如下通过一个员工表来展示基本数据类型与集合数据类型的综合应用。
hive> create table employee(name string,salary float,subordinates array,deduction map,float>,address struct,city:string,state:string,zip:int>)row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':';

六、文本文件数据编码
- 1、Hive中默认的记录和字段分隔符,如下表


- JSON格式
