【AI】数学基础——数理统计(概念&参数估计)
概率论
文章目录
-
- 3.6 数理统计概念与定理
-
- 3.6.1 概率论与数理统计区别
- 3.6.2 基本定理
-
- 大数定理
- 马尔科夫不等式
- 切比雪夫不等式
- 中心极限定理
- 3.6.3 统计推断的基本问题
- 3.7 参数估计
-
- 3.7.1 频率派
-
- 点估计法
-
- 矩阵估计法
- 极大似然估计
- 点估计量的评估
- 区间估计
- 3.7.2 贝叶斯派
-
- 贝叶斯定理
-
- 条件概率
- 独立性
- 变式
- 贝叶斯公式
- 贝叶斯定理
- 贝叶斯定理计算概率
- 贝叶斯估计
- 贝叶斯预测
- 模型比较理论
- 实例:垃圾邮件过滤
数理统计(假设检验&数据处理)
数理统计的任务是根据可观察的样本反过来推断总体的性质
推断的工具是统计量,统计量是样本的函数,是个随机变量
参数估计通过随机抽取的样本来估计总体分布的未知参数,包括点估计和区间估计
假设检验通过随机抽取的样本来接收或拒绝关于总体的某个判断
3.6 数理统计概念与定理
3.6.1 概率论与数理统计区别
根据观察或实验得到的数据来研究随机现象,并对研究对象的客观规律做出合理的估计和判断。
-
概率论:研究对象是分布已知的随机变量,根据已知的分布来分析随机变量的特征和规律
概率论解决的是已知彩票的要将规律,判断一注号码中奖的可能性
-
数理统计:研究对象是分布未知的随机变量,研究方法是对随机变量进行独立重复的观察,根据得到的观察结果对原始分布做出推断
数理统计解决的是根据之前多次中奖/不中奖的号码记录以一定的精确性推测摇奖的规律
在数理统计中,可用的资源是有限的数据集——样本。观察对象所有的可能取值——总体。
- 样本通常由对总体进行多次独立的重复观测得到,并且与总体同分布
数理统计目标:根据样本推断总体数字特征
统计量 :在统计推断中,应用的往往不是样本本身,而是被称为统计量的样本的函数,本身也是一个随机变量
样本均值: X ‾ = 1 n ∑ i = 1 n X i \overline{X}=\frac{1}{n}\sum\limits_{i=1}^{n}X_i X=n1i=1∑nXi
样本方差: S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 S^2=\frac{1}{n-1}\sum\limits_{i=1}^n(X_i-\overline{X})^2 S2=n−11i=1∑n(Xi−X)2
3.6.2 基本定理
大数定理
在试验条件不变的条件下,重复多次实验,随机事件发生的频率 ≈ \approx ≈ 概率
马尔科夫不等式
P ( X ≥ a ) ≤ E X a , X ≥ 0 , a > 0 P(X\ge a)\le \frac{EX}{a},X\ge 0,a>0 P(X≥a)≤aEX,X≥0,a>0
证:
X ≥ a ⇒ X a ≥ 1 P ( X ≥ a ) = ∫ a + ∞ f ( x ) d x ≤ ∫ a + ∞ x a f ( x ) d x 由期望性质: E ( X a ) = ∫ − ∞ a x a f ( x ) d x + ∫ a + ∞ x a f ( x ) d x = x ≤ 0 ∫ 0 a x a f ( x ) d x + ∫ a + ∞ x a f ( x ) d x 由于 ∫ 0 a x a f ( x ) d x ≥ 0 ⇒ E ( X a ) ≥ ∫ a + ∞ x a f ( x ) d x P ( X ≥ a ) = ∫ a + ∞ f ( x ) d x ≤ ∫ a + ∞ x a f ( x ) d x ≤ E ( X a ) = E X a \begin{aligned} &X\ge a\Rightarrow \frac{X}{a}\ge 1\\ &P(X\ge a)=\int_{a}^{+\infty}f(x)dx\le \int_{a}^{+\infty}\frac{x}{a}f(x)dx\\ &由期望性质:E\left(\frac{X}{a}\right)=\int_{-\infty}^{a}\frac{x}{a}f(x)dx+\int_{a}^{+\infty}\frac{x}{a}f(x)dx\xlongequal{x\le 0}\int_{0}^{a}\frac{x}{a}f(x)dx+\int_{a}^{+\infty}\frac{x}{a}f(x)dx\\ &由于 \int_{0}^{a}\frac{x}{a}f(x)dx\ge 0\Rightarrow E\left(\frac{X}{a}\right)\ge \int_{a}^{+\infty}\frac{x}{a}f(x)dx\\ &P(X\ge a)=\int_{a}^{+\infty}f(x)dx\le\int_{a}^{+\infty}\frac{x}{a}f(x)dx\le E\left(\frac{X}{a}\right)=\frac{EX}{a} \end{aligned} X≥a⇒aX≥1P(X≥a)=∫a+∞f(x)dx≤∫a+∞axf(x)dx由期望性质:E(aX)=∫−∞aaxf(x)dx+∫a+∞axf(x)dxx≤0∫0aaxf(x)dx+∫a+∞axf(x)dx由于∫0aaxf(x)dx≥0⇒E(aX)≥∫a+∞axf(x)dxP(X≥a)=∫a+∞f(x)dx≤∫a+∞axf(x)dx≤E(aX)=aEX
切比雪夫不等式
二八定理:大部分围绕在均值附近
微笑公式: P = { ∣ X − E X ∣ ≥ ϵ } ≤ σ 2 ϵ 2 ⟺ P { ∣ X − E X ∣ < ϵ } > 1 − σ 2 ϵ 2 P=\{\vert X-EX\vert\ge \epsilon\}\le\frac{\sigma^2}{\epsilon^2}\iff P\{\vert X-EX\vert<\epsilon\}>1-\frac{\sigma^2}{\epsilon^2} P={∣X−EX∣≥ϵ}≤ϵ2σ2⟺P{∣X−EX∣<ϵ}>1−ϵ2σ2

- σ 2 \sigma^2 σ2 越小,小概率事件越少
- σ 2 \sigma^2 σ2 越大,在均值附近的围绕程度越低,越分散
证明:将马尔科夫不等式中的常数 a a a 代入为均值 ϵ \epsilon ϵ ,随机变量 X X X 代入为 ∣ X − E X ∣ \vert X-EX\vert ∣X−EX∣
eg:
n n n 重伯努利实验, P ( A ) = 0.75 P(A)=0.75 P(A)=0.75 ,确定实验次数 n n n ,使 A A A 出现的频率在 ( 0.74 , 0.76 ) (0.74,0.76) (0.74,0.76) 之间的概率不超过0.9
X ∼ B ( n , 0.75 ) X\sim B(n,0.75) X∼B(n,0.75) , E X = n p = 0.75 n EX=np=0.75n EX=np=0.75n , D X = n p q = 3 16 n DX=npq=\frac{3}{16}n DX=npq=163n
在 n n n 次实验中事件 A A A 出现的频率为 X n \frac{X}{n} nX , P { 0.74 < X n < 0.76 } = { 0.74 n < X < 0.76 n } = { ∣ X − 0.75 n ∣ < 0.01 n } ≥ 1 − 3 n \ 16 0.01 n 2 ≥ 0.9 P\{0.74<\frac{X}{n}<0.76\}=\{0.74n
n ≥ 18750 n\ge 18750 n≥18750
中心极限定理
任何一个总体的平均值都会围绕在总体的平均值附近
3.6.3 统计推断的基本问题
参数估计:对象是总体的某个参数
假设检验:对象是总体的某个论断,即关于总体的假设
3.7 参数估计
3.7.1 频率派
D : d a t a = ( X 1 , X 2 , ⋯ , X n ) T = ( x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x n 1 x n 2 ⋯ x n p ) ⏞ p 个维度 D:data=(X_1,X_2,\cdots,X_n)^T=\overbrace{\left(\begin{matrix}x_{11}&x_{12}&\cdots&x_{1p}\\x_{21}&x_{22}&\cdots&x_{2p}\\\vdots&\vdots&\ddots&\vdots\\x_{n1}&x_{n2}&\cdots&x_{np}\end{matrix}\right)}^{p个维度} D:data=(X1,X2,⋯,Xn)T= x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1px2p⋮xnp p个维度 n个数据
θ \theta θ 为参数, X ∼ P ( X ; θ ) X\sim P(X;\theta) X∼P(X;θ) ,假设 n n n 个样本 X i X_i Xi 整体服从一个分布
- 点估计
- 区间估计
点估计法
点估计:已知总体分布函数,但未知其中一个或多个参数时,借助总体的一个样本来估计未知参数的取值
- 核心在于构造合适的统计量 θ ^ \hat{\theta} θ^ ,并用这个统计量的观察值作为未知参数 θ \theta θ 的近似值
- 具体方法:矩估计法和最大似然估计法
矩阵估计法
矩表示随机变量的分布特征, k k k 阶矩定义为随机变量的 k k k 次方的期望,即 E ( X k ) E(X^k) E(Xk)
基本思想:用样本 k k k 阶矩估计总体的 k k k 阶矩
理论依据:样本矩的函数几乎处处收敛于总体矩的相应函数
- 大数定律——当样本容量足够大时,几乎每次都可以根据样本参数得到相应总体参数的近似值
极大似然估计
基本思想:认为抽样得到的这一组样本值概率较大,因而在参数估计时就需要让已有样本值出现的可能性最大
θ \theta θ :未知常量——常用极大似然估计MLE
θ M L E = a r g max θ L ( θ ∣ X ) = a r g max θ P ( X ∣ θ ) = a r g max θ l o g P ( X ∣ θ ) \theta_{MLE}=arg\max\limits_{\theta} L(\theta\vert X)=arg\max\limits_{\theta}P(X\vert \theta)=arg\max\limits_{\theta}logP(X\vert \theta) θMLE=argθmaxL(θ∣X)=argθmaxP(X∣θ)=argθmaxlogP(X∣θ)
X ∼ i i d P ( X ∣ θ ) = ∏ i = 1 n P ( x i ∣ θ ) X\overset{iid}{\sim}P(X\vert \theta)=\prod\limits_{i=1}^{n}P(x_i\vert \theta) X∼iidP(X∣θ)=i=1∏nP(xi∣θ)
似然函数
给定联合样本值X是关于 θ \theta θ 的函数 L ( θ ∣ X ) L(\theta\vert X) L(θ∣X)
- x:随机变量X的具体取值
- θ \theta θ:控制整体样本服从的分布
似然函数 L ( θ ∣ X ) L(\theta\vert X) L(θ∣X) :已知数据,求使数据出现的概率最大的分布的参数 θ \theta θ
似然概率 P ( X ∣ θ ) P(X\vert\theta) P(X∣θ) :已知样本服从的分布,即参数 θ \theta θ 已知,求当 X X X 取到样本 X X X 时的概率
在最大似然估计中,似然函数被定义为样本观测值出现的概率,确定未知参数的准则是让似然概率最大化
离散型
P ( x 1 ∣ θ ) > P ( x 2 ∣ θ ) P(x_1\vert\theta)>P(x_2\vert \theta) P(x1∣θ)>P(x2∣θ) : X X X 取 x 1 x_1 x1 的概率大
L ( θ 1 ∣ X ) = P ( X ∣ θ 1 ) > P ( X ∣ θ 2 ) = L ( θ 2 ∣ X ) L(\theta_1\vert X)=P(X\vert \theta_1)>P(X\vert \theta_2)=L(\theta_2\vert X) L(θ1∣X)=P(X∣θ1)>P(X∣θ2)=L(θ2∣X)
L:取到数据集 { X } \{X\} {X} 服从 θ 1 \theta_1 θ1 描述的分布的概率
P:在 θ 1 \theta_1 θ1 条件下,取到 { X } \{X\} {X} 的概率
连续型
X ∈ ( x − ϵ , x + ϵ ) X\in (x-\epsilon,x+\epsilon) X∈(x−ϵ,x+ϵ) 的概率
P ( x − ϵ < X < x + ϵ ) = ∫ x − ϵ x + ϵ f ( x ∣ θ ) d x = 积分中值定理 2 ϵ f ( x ∣ θ ξ ) = 2 ϵ L ( θ ξ ∣ X ) P(x-\epsilon
极大似然估计
X X X 独立同分布, x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn 选取 θ ^ ( x 1 , x 2 , ⋯ , x n ) \hat{\theta}(x_1,x_2,\cdots,x_n) θ^(x1,x2,⋯,xn) 作为 θ \theta θ 观测值,使 P θ ( X = x ) = L ( θ ∣ X ) P_{\theta}(X=x)=L(\theta\vert X) Pθ(X=x)=L(θ∣X) 的概率最大
L ( θ ∣ x 1 , x 2 , ⋯ , x n ) = a r g max θ P ( x 1 , x 2 , ⋯ , x n ∣ θ ) = ∏ i = 1 n P ( x i ∣ θ ) = ∫ x 1 x n f ( x ∣ θ ) d x \begin{aligned} L(\theta\vert x_1,x_2,\cdots,x_n)=arg\max\limits_{\theta}P(x_1,x_2,\cdots,x_n\vert \theta) =\prod\limits_{i=1}^nP(x_i\vert \theta)=\int_{x_1}^{x_n}f(x\vert\theta)dx \end{aligned} L(θ∣x1,x2,⋯,xn)=argθmaxP(x1,x2,⋯,xn∣θ)=i=1∏nP(xi∣θ)=∫x1xnf(x∣θ)dx
求解步骤:
- 构造似然函数 L ( θ ) L(\theta) L(θ)
- 取对 l n L ( θ ) lnL(\theta) lnL(θ)
- 求偏导,令 d l n L ( θ ) d θ = 0 \frac{dlnL(\theta)}{d\theta}=0 dθdlnL(θ)=0
- 求 θ ^ \hat{\theta} θ^
eg
X ∼ P ( λ ) X\sim P(\lambda) X∼P(λ) , x 1 , ⋯ , x n x_1,\cdots,x_n x1,⋯,xn 为样本值,求 λ \lambda λ 极大似然估计
P ( X = k ) = λ k k ! e − λ , ( k = 0 , 1 , ⋯ , n ) P(X=k)=\frac{\lambda^k}{k!}e^{-\lambda},(k=0,1,\cdots,n) P(X=k)=k!λke−λ,(k=0,1,⋯,n)
L ( λ ) = ∏ i = 1 n λ x i ( x i ) ! e − λ = e − n λ λ ∑ i = 1 n x i ∏ i = 1 n ( x i ) ! L(\lambda)=\prod\limits_{i=1}^{n}\frac{\lambda^{x_i}}{(x_i)!}e^{-\lambda}=e^{-n\lambda}\frac{\lambda^{\sum\limits_{i=1}^nx_i}}{\prod\limits_{i=1}^{n}(x_i)!} L(λ)=i=1∏n(xi)!λxie−λ=e−nλi=1∏n(xi)!λi=1∑nxi
l n L ( λ ) = − n λ + ( ∑ i = 1 n x i ) l n λ − ∑ i = 1 n l n [ ( x i ) ! ] lnL(\lambda)=-n\lambda+(\sum\limits_{i=1}^{n}x_i)ln\lambda-\sum\limits_{i=1}^nln[(x_i)!] lnL(λ)=−nλ+(i=1∑nxi)lnλ−i=1∑nln[(xi)!]
令 d l n L ( λ ) d λ = 0 ⇒ λ ^ = 1 n ∑ i = 1 n x i = x ‾ \frac{dlnL(\lambda)}{d\lambda}=0\Rightarrow \hat{\lambda}=\frac{1}{n}\sum\limits_{i=1}^{n}x_i=\overline{x} dλdlnL(λ)=0⇒λ^=n1i=1∑nxi=x
模型判别
SML——优化问题
- 设计模型:概率模型判别
- Loss function 求解
- 算法
总结:极大似然参数估计完全依赖本次抽样的样本值
点估计量的评估
无偏性:估计量的数学期望等于未知参数的真实值
- 如果估计量是无偏的,保持估计量的构造不变,而进行多次抽样,每次用新的样本计算估计值,那么这些估计值与未知参数真实值的偏差在平均意义上等于0
有效性:无偏估计量的方差尽量小
- 估计量与真实值之间的偏离程度
一致性:当样本容量趋近于无穷时,估计量依概率收敛于未知参数的真实值
区间估计
在估计未知参数 θ \theta θ 的过程中,除了求出估计量,还需估计出一个区间,并且确定这个区间包含 θ \theta θ 真实值的可信程度。
- 区间:置信区间
对总体反复抽样多次,每次得到容量相同的样本,根据每一组样本值可以确定一个置信区间 ( θ ‾ , θ ‾ ) (\underline{\theta},\overline{\theta}) (θ,θ)
每个置信区间有两种可能:包含 θ \theta θ 和不包含 θ \theta θ 。
如果对所有置信区间中包含 θ \theta θ 真实值的比例进行统计, 包含 θ 的置信区间 置信区间数总数 \frac{包含\theta的置信区间}{置信区间数总数} 置信区间数总数包含θ的置信区间 为置信水平
在点估计的基础上,增加取指范围(置信区间)、误差界限(置信水平)
3.7.2 贝叶斯派
贝叶斯定理
条件概率
引例
3张抽奖券,1个中奖券,最后一名与第一名抽中奖概率相同
Y Y Y :抽中, N N N :未抽中 , Ω = { Y N N , N Y N , N N Y } \Omega=\{YNN,NYN,NNY\} Ω={YNN,NYN,NNY} , A i A_i Ai 事件表示第 i i i 名抽中
P ( A 3 ) = ∣ A 3 ∣ ∣ Ω ∣ = 1 3 P(A_3)=\frac{\vert A_3\vert}{\vert \Omega\vert}=\frac{1}{3} P(A3)=∣Ω∣∣A3∣=31
P ( A 1 ) = ∣ A 1 ∣ ∣ Ω ∣ = 1 3 P(A_1)=\frac{\vert A_1\vert}{\vert \Omega\vert}=\frac{1}{3} P(A1)=∣Ω∣∣A1∣=31
上例中,若已知第一名未抽中,求第三名抽中概率,则:
第一名未抽中 B = { N Y N , N N Y } B=\{NYN,NNY\} B={NYN,NNY}
第二名抽中 A 2 = { N N Y } A_2=\{NNY\} A2={NNY}
P ( A 2 ∣ B ) = 1 2 P(A_2\vert B)=\frac{1}{2} P(A2∣B)=21

分析:样本空间变了,目标样本数量不变
事件B发生条件下,有事件A发生 ⟺ \iff ⟺ 事件AB同时发生,样本空间为B
求解:
P ( A ∣ B ) = P ( A B ) P ( B ) ⟺ n ( A B ) / n ( Ω ) n ( B ) / n ( Ω ) = P ( A B ) P ( B ) P(A\vert B)=\frac{P(AB)}{P(B)}\iff\frac{n(AB)/n(\Omega)}{n(B)/n(\Omega)}=\frac{P(AB)}{P(B)} P(A∣B)=P(B)P(AB)⟺n(B)/n(Ω)n(AB)/n(Ω)=P(B)P(AB)
eg
掷硬币,100个中有99个正常HT,一个HH。投出去是正面,该硬币是异常硬币的概率
A表示异常硬币的概率,B表示掷出正面的概率
-
P ( A ∣ B ) = 异常硬币正面 n ( 硬币正面 ) = 2 101 P(A\vert B)=\frac{异常硬币正面}{n(硬币正面)}=\frac{2}{101} P(A∣B)=n(硬币正面)异常硬币正面=1012
-
P ( A ∣ B ) = P ( A B ) P ( B ) = P ( A ∣ B ) P ( B ) P ( A ∣ B ) P ( B ) + P ( A ∣ B ‾ ) P ( B ‾ ) = 2 101 P(A\vert B)=\frac{P(AB)}{P(B)}=\frac{P(A\vert B)P(B)}{P(A\vert B)P(B)+P(A\vert \overline{B})P(\overline{B})}=\frac{2}{101} P(A∣B)=P(B)P(AB)=P(A∣B)P(B)+P(A∣B)P(B)P(A∣B)P(B)=1012
独立性
若 P ( B ∣ A ) = P ( B ) P(B\vert A)=P(B) P(B∣A)=P(B) ,则 A、B独立
- 若 P ( A 1 , A 2 , ⋯ , A n ) = ∏ i = 1 n P ( A i ) P(A_1,A_2,\cdots,A_n)=\prod\limits_{i=1}^nP(A_i) P(A1,A2,⋯,An)=i=1∏nP(Ai) ,则 A 1 A_1 A1 , A 2 A_2 A2 , ⋯ \cdots ⋯, A n A_n An 相互独立
相互独立(整体) ≠ \neq = 两两独立(两个)
P ( A B C ) = { 相互: P ( A B C ) = P ( A ) P ( B ) P ( C ) 两两: P ( A B ) = P ( A ) P ( B ) , P ( B C ) = P ( B ) P ( C ) , P ( A C ) = P ( A ) P ( C ) \begin{aligned} P(ABC)=\begin{cases} 相互:P(ABC)=P(A)P(B)P(C)\\ 两两:P(AB)=P(A)P(B),P(BC)=P(B)P(C),P(AC)=P(A)P(C) \end{cases} \end{aligned} P(ABC)={相互:P(ABC)=P(A)P(B)P(C)两两:P(AB)=P(A)P(B),P(BC)=P(B)P(C),P(AC)=P(A)P(C)
独立重复实验:相同条件下,实验E重复进行每次试验结果相互独立
n重伯努利实验:规定实验结果只有 A A A 和 A ‾ \overline{A} A 两种,相同条件下,将实验独立地重复n次
变式
乘法原理 : P ( A B ) = P ( A ) P ( B ) P(AB)=P(A)P(B) P(AB)=P(A)P(B)
全概率公式
S:实验E中的样本空间, A 1 , ⋯ , A 2 A_1,\cdots,A_2 A1,⋯,A2 为E中一组事件
满足:
- A i A j = ϕ A_iA_j=\phi AiAj=ϕ
- A 1 ⋃ A 2 ⋃ ⋯ ⋃ A n = S A_1\bigcup A_2\bigcup \cdots \bigcup A_n=S A1⋃A2⋃⋯⋃An=S
则称 A 1 , A 2 , ⋯ , A n A_1,A_2,\cdots,A_n A1,A2,⋯,An 为 S S S 的一个 划分
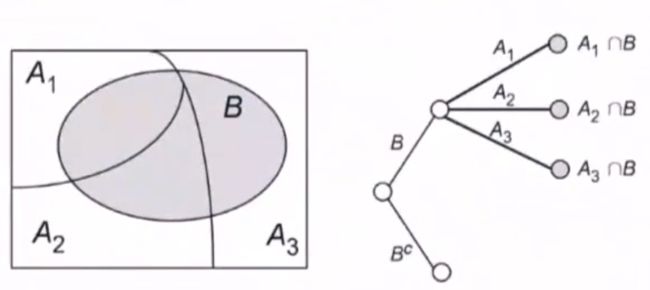
P ( B ) = P ( A 1 ⋂ B ) + ⋯ + P ( A n ⋂ B ) = P ( A 1 ) P ( B ∣ A 1 ) + ⋯ + P ( A n ) P ( B ∣ A n ) P(B)=P(A_1\bigcap B)+\cdots+P(A_n\bigcap B)=P(A_1)P(B\vert A_1)+\cdots+P(A_n)P(B\vert A_n) P(B)=P(A1⋂B)+⋯+P(An⋂B)=P(A1)P(B∣A1)+⋯+P(An)P(B∣An)
贝叶斯公式
先验概率 P ( A i ) P(A_i) P(Ai) 与后验概率 P ( A i ∣ B ) P(A_i\vert B) P(Ai∣B) 关系
P ( A i ∣ B ) = P ( B A i ) P ( B ) = P ( B ∣ A i ) P ( A i ) P ( B ) = P ( B ∣ A i ) P ( A i ) ∑ j = 1 n P ( B ∣ A j ) P ( A j ) P(A_i\vert B)=\frac{P(BA_i)}{P(B)}=\frac{P(B\vert A_i)P(A_i)}{P(B)}=\frac{P(B\vert A_i)P(A_i)}{\sum\limits_{j=1}^nP(B\vert A_j)P(A_j)} P(Ai∣B)=P(B)P(BAi)=P(B)P(B∣Ai)P(Ai)=j=1∑nP(B∣Aj)P(Aj)P(B∣Ai)P(Ai)
- 先验:假设(已知条件)的概率
- 后验:已知结果得到条件的概率
贝叶斯定理
P ( H ∣ D ) = P ( D ∣ H ) P ( H ) P ( D ) P(H\vert D)=\frac{P(D\vert H)P(H)}{P(D)} P(H∣D)=P(D)P(D∣H)P(H)
- P ( H ) P(H) P(H) :先验概率
- P ( D ∣ H ) P(D\vert H) P(D∣H) :似然概率
- P ( H ∣ D ) P(H\vert D) P(H∣D) :后验概率
贝叶斯定理计算概率

贝叶斯估计
后验( 数据 → 参数 数据\rightarrow 参数 数据→参数) → \rightarrow → 先验( 参数 → 数据 参数\rightarrow 数据 参数→数据)
在贝叶斯估计中,参数 θ \theta θ 为关注部分,以 θ \theta θ 作为前提的条件概率为先验概率
结合先验知识(统计,频数),若样本不合理可进行校正
θ M A P = a r g max θ P ( θ ∣ X ) = a r g max θ P ( X ∣ θ ) P ( θ ) P ( X ) = 同一样本不同模型,数据出现概率相等, P ( X ) 可看做常数,进而忽略 ∝ a r g max θ P ( X ∣ θ ) P ( θ ) \begin{aligned} \theta_{MAP}&=arg\max\limits_{\theta}P(\theta\vert X)=arg\max\limits_{\theta}\frac{P(X\vert \theta)P(\theta)}{P(X)}\\ &\xlongequal{同一样本不同模型,数据出现概率相等,P(X)可看做常数,进而忽略}\\ &\propto arg\max\limits_{\theta}P(X\vert \theta)P(\theta) \end{aligned} θMAP=argθmaxP(θ∣X)=argθmaxP(X)P(X∣θ)P(θ)同一样本不同模型,数据出现概率相等,P(X)可看做常数,进而忽略∝argθmaxP(X∣θ)P(θ)
样本离散:
a r g max θ P ( X ∣ θ ) P ( θ ) = a r g max θ P ( x 1 , x 2 , ⋯ , x n ∣ θ ) P ( θ ) = a r g max θ [ ∏ i = 1 n P ( x i ∣ θ ) ] P ( θ ) = a r g max θ l n { [ ∏ i = 1 n P ( x i ∣ θ ) ] P ( θ ) } = a r g max θ [ ∑ i = 1 n l n P ( x i ∣ θ ) + l n P ( θ ) ] \begin{aligned} arg\max\limits_{\theta}P(X\vert \theta)P(\theta)&=arg\max\limits_{\theta}P(x_1,x_2,\cdots,x_n\vert \theta)P(\theta)=arg\max\limits_{\theta}\left[\prod\limits_{i=1}^nP(x_i\vert \theta)\right]P(\theta)\\ &=arg\max\limits_{\theta}ln\left\{\left[\prod\limits_{i=1}^nP(x_i\vert \theta)\right]P(\theta)\right\}\\ &=arg\max\limits_{\theta}\left[\sum\limits_{i=1}^n lnP(x_i\vert \theta)+lnP(\theta)\right]\end{aligned} argθmaxP(X∣θ)P(θ)=argθmaxP(x1,x2,⋯,xn∣θ)P(θ)=argθmax[i=1∏nP(xi∣θ)]P(θ)=argθmaxln{[i=1∏nP(xi∣θ)]P(θ)}=argθmax[i=1∑nlnP(xi∣θ)+lnP(θ)]
样本连续:
a r g max θ P ( X ∣ θ ) P ( θ ) = a r g max θ P ( x 1 , x 2 , ⋯ , x n ∣ θ ) P ( θ ) = a r g max θ ∫ θ P ( X ∣ θ ) P ( θ ) arg\max\limits_{\theta}P(X\vert \theta)P(\theta)=arg\max\limits_{\theta}P(x_1,x_2,\cdots,x_n\vert\theta)P(\theta)=arg\max\limits_{\theta}\int_{\theta}P(X\vert \theta)P(\theta) argθmaxP(X∣θ)P(θ)=argθmaxP(x1,x2,⋯,xn∣θ)P(θ)=argθmax∫θP(X∣θ)P(θ)
eg
拼写检查 P ( 猜测词 ∣ 实际输入词 ) P(猜测词\vert 实际输入词) P(猜测词∣实际输入词)
猜测1: P ( w 1 ∣ D ) P(w_1\vert D) P(w1∣D) ,猜测2: P ( w 2 ∣ D ) P(w_2\vert D) P(w2∣D)
P ( w ∣ D ) = P ( w ) P ( D ∣ w ) P ( D ) P(w\vert D)=\frac{P(w)P(D\vert w)}{P(D)} P(w∣D)=P(D)P(w)P(D∣w) ,在已有输入的情况下,不管正确词是哪种情况,输入词出现的概率 P ( D ) P(D) P(D) 都相同
- 出于无法估计/估计困难,忽略同一影响 P ( D ) P(D) P(D)
故 P ( w ∣ D ) ∝ P ( D ∣ w ) P ( w ) P(w\vert D)\propto P(D\vert w)P(w) P(w∣D)∝P(D∣w)P(w)
此时, P ( w ) P(w) P(w) 为先验知识,可以通过统计,得出正确词出现的概率
若输入 tlp ,对于 t o p top top 或 t i p tip tip ,用极大似然无法估计,但由统计学,用户输入 t o p top top 词频高,则 top 概率大, P ( ′ t o p ′ ∣ ′ t l p ′ ) > P ( ′ t o p ′ ∣ ′ t l p ′ ) P('top'\vert 'tlp')>P('top'\vert 'tlp') P(′top′∣′tlp′)>P(′top′∣′tlp′)
贝叶斯预测
X X X:训练数据, X ~ \widetilde{X} X :测试数据
P ( X ~ ∣ X ) = ∫ θ P ( X ~ , θ ∣ X ) d θ = ∫ θ P ( X ~ ∣ θ ) P ( θ ∣ X ) d θ P(\widetilde{X}\vert X)=\int_\theta P(\widetilde{X},\theta\vert X)d\theta=\int_\theta P(\widetilde{X}\vert \theta)P(\theta\vert X)d\theta P(X ∣X)=∫θP(X ,θ∣X)dθ=∫θP(X ∣θ)P(θ∣X)dθ
- P ( θ ∣ X ) P(\theta\vert X) P(θ∣X) :由训练数据得到某一模型
- P ( X ~ ∣ θ ) P(\widetilde{X}\vert \theta) P(X ∣θ) :某一模式下,测试数据出现的概率
模型比较理论
极大似然:最符合观测数据的最有优势, P ( D ∣ θ ) P(D\vert \theta) P(D∣θ)
奥卡姆剃刀: P ( θ ) P(\theta) P(θ) 先验概率大的模型最有优势
eg :对于平面上点进行拟合,根据奥卡姆剃刀原理,越高阶多项式越不常见(过拟合线性)
P ( P o l ( X ) ) ≪ P ( P o l ( 2 ) ) ≪ P ( P o l ( 1 ) ) P(Pol(X))\ll P(Pol(2))\ll P(Pol(1)) P(Pol(X))≪P(Pol(2))≪P(Pol(1))
实例:垃圾邮件过滤
D D D :邮件, D D D 由 n n n 个单词组成, h + h^+ h+ :垃圾邮件, h − h^- h− :正常邮件
P ( h + ∣ D ) = P ( D ∣ h + ) P ( h + ) P ( D ) ∝ P ( h + ) P ( D ∣ h + ) P(h^+\vert D)=\frac{P(D\vert h^+)P(h^+)}{P(D)}\propto P(h^+)P(D\vert h^+) P(h+∣D)=P(D)P(D∣h+)P(h+)∝P(h+)P(D∣h+)
P ( h − ∣ D ) = P ( D ∣ h − ) P ( h − ) P ( D ) ∝ P ( h − ) P ( D ∣ h − ) P(h^-\vert D)=\frac{P(D\vert h^-)P(h^-)}{P(D)}\propto P(h^-)P(D\vert h^-) P(h−∣D)=P(D)P(D∣h−)P(h−)∝P(h−)P(D∣h−)
先验概率: P ( h + ) P(h^+) P(h+) 与 P ( h − ) P(h^-) P(h−) 都可以通过统计学得出,
D D D 中包含 n n n 个词, d 1 , d 2 , ⋯ , d n d_1,d_2,\cdots,d_n d1,d2,⋯,dn , P ( D ∣ h + ) = P ( d 1 , d 2 , ⋯ , d n ∣ h + ) P(D\vert h^+)=P(d_1,d_2,\cdots,d_n\vert h^+) P(D∣h+)=P(d1,d2,⋯,dn∣h+) 为垃圾邮件中出现这些词的概率
( 原始贝叶斯 ) P ( d 1 , d 2 , ⋯ , d n ∣ h + ) = P ( d 1 ∣ h + ) P ( d 2 , ⋯ , d n ∣ d 1 , h + ) = ⋯ = P ( d 1 ∣ h + ) P ( d 2 ∣ d 1 , h + ) P ( d 3 ∣ d 1 , d 2 , h + ) ⋯ ⇓ ( 朴素贝叶斯 ) = 假设特征间相互独立 P ( d 1 ∣ h + ) P ( d 2 ∣ h + ) ⋯ P ( d n ∣ h + ) \begin{aligned} (原始贝叶斯)&P(d_1,d_2,\cdots,d_n\vert h^+)=P(d_1\vert h^+)P(d_2,\cdots,d_n\vert d_1,h^+)=\cdots=P(d_1\vert h^+)P(d_2\vert d_1,h^+)P(d_3\vert d_1,d_2,h^+)\cdots\\ \Downarrow\\ (朴素贝叶斯)&\xlongequal{假设特征间相互独立}P(d_1\vert h^+)P(d_2\vert h^+)\cdots P(d_n\vert h^+) \end{aligned} (原始贝叶斯)⇓(朴素贝叶斯)P(d1,d2,⋯,dn∣h+)=P(d1∣h+)P(d2,⋯,dn∣d1,h+)=⋯=P(d1∣h+)P(d2∣d1,h+)P(d3∣d1,d2,h+)⋯假设特征间相互独立P(d1∣h+)P(d2∣h+)⋯P(dn∣h+)
可以用频率代替概率