【创新实训】问答系统-Question Generation模块-【博客4:模型架构的搭建与训练过程】
前面三篇博客主要探究了QG(Question Generation)任务的基本策略、评价指标;描述了我的初步探索;以及给出了数据处理的方法:
- 博客1:基本策略
- 博客2:评价指标、初步探索
- 博客3:训练数据和预测数据预处理的部分
- 博客4:模型的构建
- 博客5:生成“问答对”
- 博客6:问答对有效性过滤(基于文本分类任务)
- 博客7:用问题库检索服务
一、模型构建
1.1 模型架构
正如前文所提到,我在“‘万创杯’中医药天池大数据竞赛”问题生成赛题的第一名的解决方案的基础上进行适当扩展。
包的导入和相关参数的设置,具体参数尤其是BatchSize部分我结合模型的训练的实际情况做了一定的调整。
import keras.backend.tensorflow_backend as KTF
import numpy as np
import tensorflow as tf
from bert4keras.backend import keras, K, search_layer
from bert4keras.models import build_transformer_model
from bert4keras.optimizers import Adam
from bert4keras.snippets import DataGenerator, AutoRegressiveDecoder
from bert4keras.snippets import sequence_padding
from bert4keras.tokenizers import Tokenizer, load_vocab
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras.layers import Input
from keras.models import Model
from rouge import Rouge # pip install rouge
from sklearn.model_selection import KFold
from tqdm import tqdm
from utils import json2df, preprocess
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 指定GPU
# 11895
# 基本参数
n = 5 # 交叉验证
max_p_len = 194 # 篇章最大长度
max_q_len = 131 # 问题最大长度
max_a_len = 65 # 答案最大长度
head = 64 # 篇章截取中,取答案id前head个字符
batch_size = 1 # 批大小
epochs = 1 # 迭代次数
SEED = 2020 # 随机种子
# nezha配置
config_path = '../user_data/model_data/NEZHA-Large-WWM/bert_config.json'
checkpoint_path = '../user_data/model_data/NEZHA-Large-WWM/model.ckpt-346400'
dict_path = '../user_data/model_data/NEZHA-Large-WWM/vocab.txt'
# 加载并精简词表,建立分词器
token_dict, keep_tokens = load_vocab(
dict_path=dict_path,
simplified=True,
startswith=['[PAD]', '[UNK]', '[CLS]', '[SEP]'],
)
tokenizer = Tokenizer(token_dict, do_lower_case=True)
- 端到端地实现“篇章 + 答案 → 问题”,使用“NEZHA + UniLM”的方式来构建一个Seq2Seq模型。
- 其中UniLM可以完成单向、序列到序列和双向预测任务,在抽象摘要、生成式问题回答和语言生成数据集的抽样领域取得了最优秀的成绩。
- 而Nezha-large-wwm预训练模型是测试后效果是最好的模型,单个的Nezha-large-wwm加上一定的Trick就能达到0.64+。
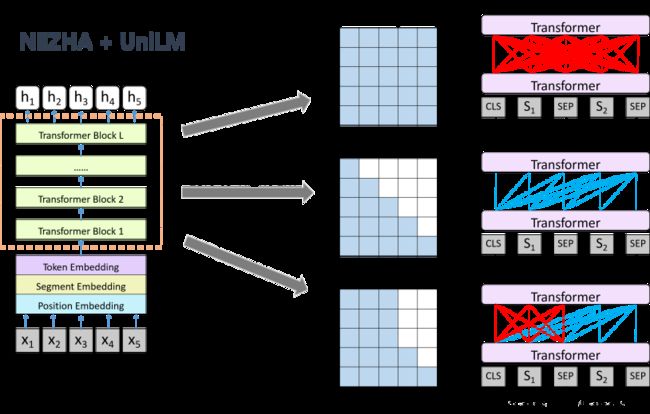
关键模型的构建
def build_model():
"""构建模型。"""
# 的Bert模型就已经搭建完毕,剩下的就是Keras的使⽤
model = build_transformer_model(
config_path,
checkpoint_path,
model='nezha',
application='unilm',
keep_tokens=keep_tokens, # 只保留keep_tokens中的字,精简原字表
)
# 实例化输入、输出的张量
o_in = Input(shape=(None, ))
train_model = Model(model.inputs + [o_in], model.outputs + [o_in])
# 交叉熵作为loss,并mask掉输入部分的预测
y_true = train_model.input[2][:, 1:] # 目标tokens
y_mask = train_model.input[1][:, 1:]
y_pred = train_model.output[0][:, :-1] # 预测tokens,预测与目标错开一位
cross_entropy = K.sparse_categorical_crossentropy(y_true, y_pred)
cross_entropy = K.sum(cross_entropy * y_mask) / K.sum(y_mask)
train_model.add_loss(cross_entropy)
train_model.compile(optimizer=Adam(1e-5))
return model, train_model
def adversarial_training(model, embedding_name, epsilon=1.):
"""给模型添加对抗训练
其中model是需要添加对抗训练的keras模型,embedding_name
则是model里边Embedding层的名字。要在模型compile之后使用。
"""
if model.train_function is None: # 如果还没有训练函数
model._make_train_function() # 手动make
old_train_function = model.train_function # 备份旧的训练函数
# 查找Embedding层
for output in model.outputs:
embedding_layer = search_layer(output, embedding_name)
if embedding_layer is not None:
break
if embedding_layer is None:
raise Exception('Embedding layer not found')
# 求Embedding梯度
embeddings = embedding_layer.embeddings # Embedding矩阵
gradients = K.gradients(model.total_loss, [embeddings]) # Embedding梯度
gradients = K.zeros_like(embeddings) + gradients[0] # 转为dense tensor
# 封装为函数
inputs = (
model._feed_inputs + model._feed_targets + model._feed_sample_weights
) # 所有输入层
embedding_gradients = K.function(
inputs=inputs,
outputs=[gradients],
name='embedding_gradients',
) # 封装为函数
def train_function(inputs): # 重新定义训练函数
grads = embedding_gradients(inputs)[0] # Embedding梯度
delta = epsilon * grads / (np.sqrt((grads ** 2).sum()) + 1e-8) # 计算扰动
K.set_value(embeddings, K.eval(embeddings) + delta) # 注入扰动
outputs = old_train_function(inputs) # 梯度下降
K.set_value(embeddings, K.eval(embeddings) - delta) # 删除扰动
return outputs
model.train_function = train_function # 覆盖原训练函数
class QuestionGeneration(AutoRegressiveDecoder):
"""通过beam search来生成问题。"""
def __init__(self, model, *args, **kwargs):
super().__init__(*args, **kwargs)
self.model = model
@AutoRegressiveDecoder.wraps(default_rtype='probas')
def predict(self, inputs, output_ids, states):
token_ids, segment_ids = inputs
token_ids = np.concatenate([token_ids, output_ids], 1)
segment_ids = np.concatenate([segment_ids, np.ones_like(output_ids)], 1)
return self.model.predict([token_ids, segment_ids])[:, -1]
def generate(self, passage, answer, topk=5):
p_token_ids, _ = tokenizer.encode(passage, maxlen=max_p_len)
a_token_ids, _ = tokenizer.encode(answer, maxlen=max_a_len)
token_ids = p_token_ids + a_token_ids[1:]
segment_ids = [0] * (len(p_token_ids) + len(a_token_ids[1:]))
q_ids = self.beam_search([token_ids, segment_ids], topk) # 基于beam search
return tokenizer.decode(q_ids)
class Evaluator(keras.callbacks.Callback):
"""计算验证集rouge_l。"""
def __init__(self, valid_data, qg):
super().__init__()
self.rouge = Rouge()
self.best_rouge_l = 0.
self.valid_data = valid_data
self.qg = qg
def on_epoch_end(self, epoch, logs=None):
rouge_l = self.evaluate(self.valid_data) # 评测模型
if rouge_l > self.best_rouge_l:
self.best_rouge_l = rouge_l
logs['val_rouge_l'] = rouge_l
print(
f'val_rouge_l: {rouge_l:.5f}, '
f'best_val_rouge_l: {self.best_rouge_l:.5f}',
end=''
)
def evaluate(self, data, topk=1):
total, rouge_l = 0, 0
for p, q, a in tqdm(data):
total += 1
q = ' '.join(q)
pred_q = ' '.join(self.qg.generate(p, a, topk))
if pred_q.strip():
scores = self.rouge.get_scores(hyps=pred_q, refs=q)
rouge_l += scores[0]['rouge-l']['f']
rouge_l /= total
return rouge_l
1.2输入与输出
训练模型的输入:
- [CLS]篇章[SEP]答案[SEP]问题[SEP]
预测时的输入:
- [CLS]篇章[SEP]答案[SEP]
输出:
- 答案[SEP]

数据加载模块:
def load_data(filename):
"""加载数据。"""
df = json2df(filename) # json转DataFrame
df = preprocess(df) # 数据预处理
# 文本截断
D = list()
for _, row in df.iterrows():
passage = row['passage']
question = row['question']
answer = row['answer']
if len(passage) < max_p_len - 2 and len(answer) < max_a_len - 1:
D.append((passage, question, answer))
else:
a = answer[:max_a_len-1] if len(answer) > max_a_len - 1 else answer
try:
idx = passage.index(a)
if len(passage[idx:]) < (max_p_len - 2 - head):
p = passage[-(max_p_len - 2):]
else:
p = passage[max(0, idx - head):]
p = p[:max_p_len - 2]
except ValueError:
p = passage[:max_p_len - 2]
D.append((p, question, a))
return D
数据生成器的构建
class data_generator(DataGenerator):
"""数据生成器。"""
def __init__(self, data, batch_size=32, buffer_size=None, random=False):
super().__init__(data, batch_size, buffer_size)
self.random = random
def __iter__(self, random=False):
"""单条样本格式:[CLS]篇章[SEP]答案[SEP]问题[SEP]。"""
batch_token_ids, batch_segment_ids, batch_o_token_ids = [], [], []
for is_end, (p, q, a) in self.sample(random):
p_token_ids, _ = tokenizer.encode(p, maxlen=max_p_len)
a_token_ids, _ = tokenizer.encode(a, maxlen=max_a_len)
q_token_ids, _ = tokenizer.encode(q, maxlen=max_q_len)
token_ids = p_token_ids + a_token_ids[1:] + q_token_ids[1:]
segment_ids = [0] * (len(p_token_ids) + len(a_token_ids[1:]))
segment_ids += [1] * (len(token_ids) - len(p_token_ids) - len(a_token_ids[1:]))
o_token_ids = token_ids
if np.random.random() > 0.5:
token_ids = [
t if s == 0 or (s == 1 and np.random.random() > 0.3)
else np.random.choice(token_ids)
for t, s in zip(token_ids, segment_ids)
]
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_o_token_ids.append(o_token_ids)
if len(batch_token_ids) == self.batch_size or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_o_token_ids = sequence_padding(batch_o_token_ids)
yield [batch_token_ids, batch_segment_ids, batch_o_token_ids], None
batch_token_ids, batch_segment_ids, batch_o_token_ids = [], [], []
def forfit(self):
while True:
for d in self.__iter__(self.random):
yield d
1.3其他策略
1)解码算法:Beam search算法。
2)交叉验证:在单模型(NEZHA-Large-WWM)上使用5折交叉验证。
3)增强泛化能力:早停法(EarlyStopping)。
4)采用半监督学习思想:伪标签(有细微的提升,大约万分之二左右)。
5)缓解Exposure Bias问题:
- 通过随机替换Decoder的输入词来构造“有代表性”的负样本;
- 采用了“对抗训练”来生成扰动样本。
(大约有百分之二提升)
6)解决显存不足的方法:梯度累积优化器(可以使用小的batch size实现大batch size的效果)
7)简化多分类的类别:精简词表(总tokens约2万个,然而近一半Token不会出现)。
main方法中所需要的调用:
if __name__ == '__main__':
do_train()
do_train()中包含了模型真正训练的完整流程,调用了上面构建的模型以及数据的加载部分:
def do_train():
# 加载数据[(p, a, q)...]
data = load_data('../data/train.json') # 加载数据
# 交叉验证
kf = KFold(n_splits=n, shuffle=True, random_state=SEED)
for fold, (trn_idx, val_idx) in enumerate(kf.split(data), 0):
if fold != 0:
break # 只训练一次
print(f'Fold {fold}')
# 配置Tensorflow Session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # 不全部占满显存, 按需分配
sess = tf.Session(config=config)
KTF.set_session(sess)
# 划分训练集和验证集
train_data = [data[i] for i in trn_idx]
valid_data = [data[i] for i in val_idx]
# 训练数据生成器
train_generator = data_generator(train_data, batch_size, random=True)
# model用于生成问题,train_model 源于 model 用于进行训练
model, train_model = build_model() # 构建模型
# 进行对抗训练
adversarial_training(train_model, 'Embedding-Token', 0.5) # 对抗训练
# 问题生成器
qg = QuestionGeneration(
model, start_id=None, end_id=tokenizer._token_dict['?'],
maxlen=max_q_len
)
# 设置回调函数
# callbacks用于指定在每个epoch开始和结束的时候进行哪种特定操作
callbacks = [
# 评估器:评估 rough 的值
Evaluator(valid_data, qg),
# 提前停止
# patience:能够容忍多少个epoch内都没有improvement
# monitor:需要监视的值,通常为:val_acc 或 val_loss 或 acc 或 loss
# mode:根据监视值
EarlyStopping(
monitor='val_rouge_l',
patience=1,
verbose=1,
mode='max'),
# 在每个epoch后保存模型到filepath
ModelCheckpoint(
f'../user_data/model_data/fold-{fold}.h5',
monitor='val_rouge_l',
save_weights_only=True,
save_best_only=True,
verbose=1,
mode='max'),
]
# 模型训练
train_model.fit_generator(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=epochs,
callbacks=callbacks,
)
KTF.clear_session()
sess.close()
二、模型训练
2.1仅用中医文献阅读理解数据集训练
尽管前文叙述中,我采取了多数据集融合的训练方式,但在最初的尝试中,我仍然只用到了中医文献阅读理解数据集。
我的模型运行在学校的云服务器上,CUDA版本为1.2,GPU为Nvidia的2080Ti。此外,我也尝试了在自己电脑上运行以及网络租用3080Ti服务器训练模型,但是由于时间关系,没有配置得很成功。
下面是仅用中医文献阅读理解数据集训练的主要操作:

将数据放入/data目录中,运行train.py文件,设置好空闲的GPU,开始训练模型。过程中主要注意了下面问题:
- 1) 由于GPU的显存有一定的限度,即使设置为不占满GPU仍然可能中途发生内存不足的中断错误,经过多次测试,我最终设置BatchSize = 1。
- 2) 我选取的5折交叉验证中单个Epoch的训练时间比较长,我epoch_num先设置为1作为测试。
- 3) 根据GPU的显存,调节合适的文本截取长度,在这里
max_p_len = 194 # 篇章最大长度
max_q_len = 131 # 问题最大长度
max_a_len = 65 # 答案最大长度
head = 64 # 篇章截取中,取答案id前head个字符
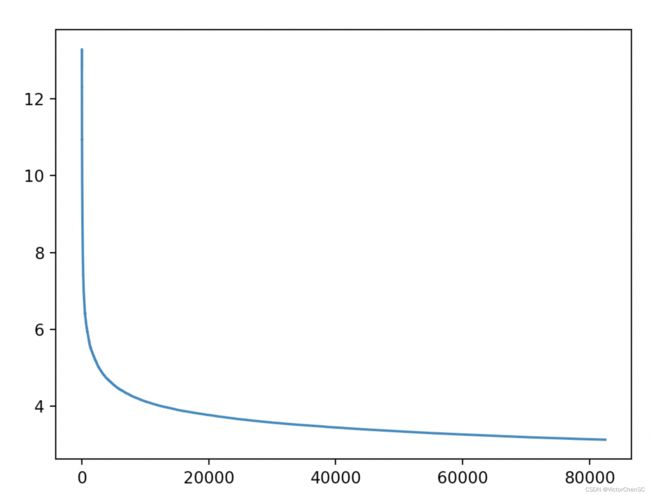
最初,模型的初始loss为13.4199。
经过了9个小时训练,大概完成了30%的训练进度,loss降低到了3.6870。
训练了20小时后,完成了5折交叉验证,
将数据用python的matplotlib作图可以发现,在大约8000个batch之后,模型训练的结果在验证集上的loss没有特别明显地下降了。最终模型在一个epoch之后,loss从13降低到了3.09左右(图a)。
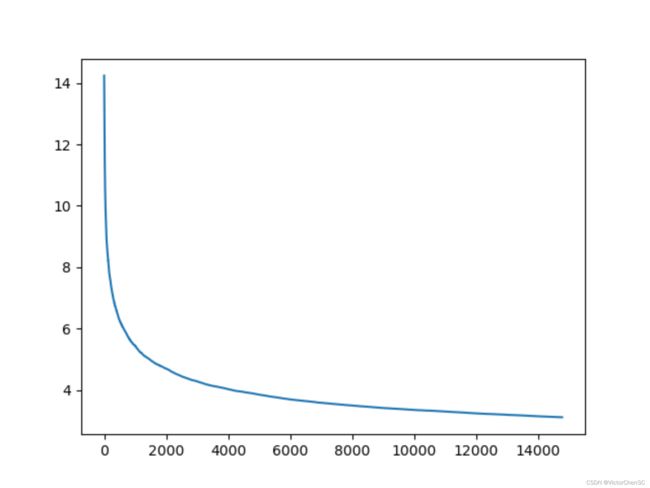
2.2中医文献+CJRC+Squad+DuReader多数据集结合训练
考虑到由于中医文献具有领域的局限性,上述训练过程在“经济法教辅语料”的数据集上表现并不优秀。快速提升模型在多种领域问题上的表现性能的一个方法,是将多领域的数据融合,打乱顺序同时放入模型训练。
经过12小时的训练(图b),模型的loss从13.0降低到3.1。
在后面的问题生成任务中可以发现,多领域数据集融合版本训练的模型在“经济法教辅语料”上表现更加优秀。
最优val_rouge_l: 0.59066