Mini Mybatis-Plus(上)
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学了这么多源码之后,总想自己造个轮子玩玩,这样不但可以加深对知识的理解,而且也对自己将来技术的提升有很大的帮助。
事不宜迟,一起来造第一个轮子:Mini MyBatis-Plus。
正如之前说的,我们造轮子是为了刻意练习,而不是为了用于生产环境。只要轮子能跑就行,不用过分关注无关紧要的细枝末节。大家阅读本文时,应该关注解决问题的过程,至于异常处理是否严谨、是否存在性能问题等等且先放一旁。
不论是MyBatis、通用Mapper还是MyBatis-Plus,底层都是对JDBC做的封装。所以理论上来说,要造一个Mini MyBatis-Plus,大致分两步:
- 先造一个JdbcTemplate,简化JDBC的操作(本篇完成)
- 再基于JdbcTemplate,封装得到Mini MyBatis-Plus(后两篇内容)
最后一篇有完整源码,不想敲的可以先去下载。
环境准备
理论上搭建一个Maven项目即可,因为本次造轮子是完全独立的项目,不需要用到SpringBoot。但我偷懒了,还是搭建了SpringBoot项目。
CREATE TABLE `t_user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` varchar(255) DEFAULT '' COMMENT '姓名',
`age` tinyint(3) unsigned DEFAULT '0' COMMENT '年龄',
`birthday` date DEFAULT NULL COMMENT '生日',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
org.springframework.boot
spring-boot-starter
mysql
mysql-connector-java
runtime
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
JDBC简介
什么是JDBC
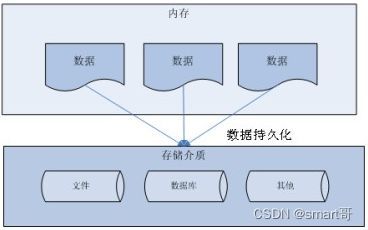
在说JDBC之前,必须先聊聊数据持久化。
持久化(把对象赶到磁盘中)
所谓持久化,就是把数据保存到可掉电式存储设备中以供之后使用。
大多数情况下,数据持久化意味着将内存中的数据保存到磁盘中加以“固化”。而持久化的实现过程大多通过各种关系数据库完成。当然,也可以存入磁盘文件或者XML数据文件。
JDBC
数据库是实现持久化的一种途径,而JDBC则是通向数据库的桥梁。

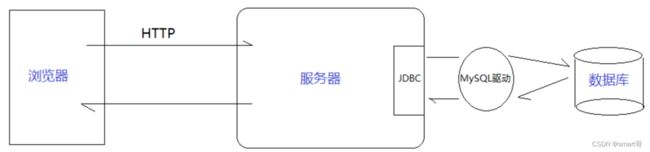
通俗地讲,JDBC就是一组API(包括少量类),为访问不同数据库提供了统一的途径,为开发者屏蔽了一些细节问题。比如,我们都知道浏览器发送HTTP请求访问服务器,但其实请求底层仍是TCP协议。同样的,访问数据库底层也通过TCP协议。你知道怎么与数据库建立TCP连接吗?一部分科班读者可能对计算机网络非常熟悉,但是大部分像我这样的野生程序员可能压根没想过这个问题。
所幸,这些具体的实现,各大数据库产商已经替我们做了,只不过这些实现类聚集在一块儿以后换了个名字:驱动。
驱动
浏览器通过HTTP访问服务器时,有Servlet为我们处理请求。javax.servlet虽然是接口,但是Java已经替我们准备了实现类:javax.servlet.http.HttpServlet,我们只要继承它,并覆盖doGet/doPost方法即可处理Get/Post请求。但JDBC是接口,只是定义了方法,却没有实现。要让我们自己去写一套类,难度颇大。首先,底层肯定是TCP连接,必须用到Socket编程连接数据库,然后进行各种参数校验,最终获取Connection返回。
各大数据库产商对于JDBC有不同的实现,但它们写的JDBC实现类都统称为“数据库驱动”,比如我们这次使用的mysql-connector-java。所以,当我们在一个工程中导入mysql-connector-java,其实本质是导入一系列JDBC的实现类。
JDBC简单示例
JDBC操作数据的步骤
- 通过DriverManager获得Connection
- 通过Connection获取PreparedStatement
- 通过PreparedStatement执行sql
- 获取结果集、处理结果集
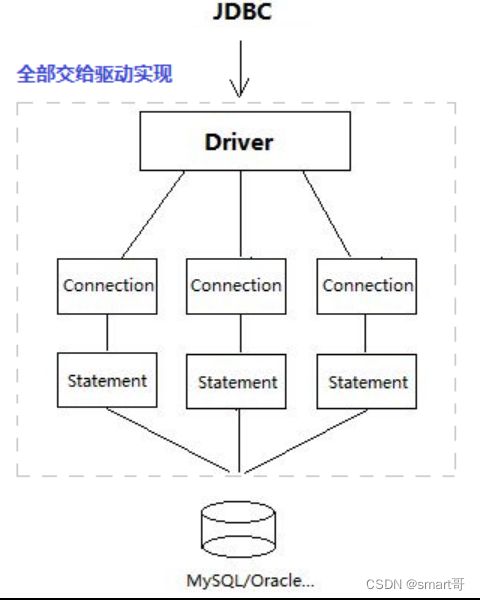
日常数据操作无非增删改查,而对于JDBC而言,查询为一类(executeQuery),增删改为一类(executeUpdate)。为什么这么分类呢?因为增删改操作只需返回int affectedRows,而查询操作还要额外处理结果集映射。
@SpringBootTest
class SimpleJDBC {
@Test
public void testQuery() throws SQLException {
// 1.注册驱动(已经过时,现在不必注册驱动,DriverManager被加载时会自动注册)
// Class.forName("com.mysql.jdbc.Driver");
// 2.建立连接
String url = "jdbc:mysql://localhost:3306/demo";
String user = "root";
String password = "123456";
Connection conn = DriverManager.getConnection(url, user, password);
// 3.创建sql模板
String sql = "select * from t_user where id = ?";
PreparedStatement preparedStatement = conn.prepareStatement(sql);
// 4.设置模板参数
preparedStatement.setInt(1, 1);
// 5.执行语句
ResultSet rs = preparedStatement.executeQuery();
// 6.处理结果
while (rs.next()) {
System.out.println(rs.getObject(1) + "\t" + rs.getObject(2) + "\t"
+ rs.getObject(3) + "\t" + rs.getObject(4));
}
// 7.释放资源
rs.close();
preparedStatement.close();
conn.close();
}
@Test
public void testUpdate() throws SQLException {
// 1.注册驱动(已经过时,现在不必注册驱动,DriverManager被加载时会自动注册)
// Class.forName("com.mysql.jdbc.Driver");
// 2.建立连接
String url = "jdbc:mysql://localhost:3306/demo";
String user = "root";
String password = "123456";
Connection conn = DriverManager.getConnection(url, user, password);
// 3.创建sql模板
String sql = "insert into t_user(name, age, birthday) values(?,?,?)";
PreparedStatement preparedStatement = conn.prepareStatement(sql);
// 4.设置模板参数
preparedStatement.setString(1, "bravo1988");
preparedStatement.setInt(2, 18);
preparedStatement.setDate(3, Date.valueOf(LocalDate.now()));
// 5.执行语句
preparedStatement.executeUpdate();
// 6.释放资源
preparedStatement.close();
conn.close();
}
}query要比update多一步,需要处理结果集(ResultSet)。
封装JdbcTemplate
简化Connection操作
/**
* 不论是query还是update,都有获取Connection和关闭Connection的操作
* 优化第一步:抽取getConnection()和closeConnection()
*/
@SpringBootTest
class SimpleJDBC {
@Test
public void testQuery() throws SQLException {
// 1.获取连接
Connection conn = this.getConnection();
// 2.创建sql模板
String sql = "select * from t_user where id = ?";
PreparedStatement preparedStatement = conn.prepareStatement(sql);
// 3.设置模板参数 id=1
preparedStatement.setInt(1, 1);
// 4.执行语句
ResultSet rs = preparedStatement.executeQuery();
// 5.处理结果
while (rs.next()) {
System.out.println(rs.getObject(1) + "\t" + rs.getObject(2) + "\t"
+ rs.getObject(3) + "\t" + rs.getObject(4));
}
// 6.释放资源
this.closeConnection(conn, preparedStatement, rs);
}
@Test
public void testUpdate() throws SQLException {
// 1.获取连接
Connection conn = this.getConnection();
// 2.创建sql模板
String sql = "insert into t_user(name, age, birthday) values(?,?,?)";
PreparedStatement preparedStatement = conn.prepareStatement(sql);
// 3.设置模板参数
preparedStatement.setString(1, "bravo1988");
preparedStatement.setInt(2, 18);
preparedStatement.setDate(3, Date.valueOf(LocalDate.now()));
// 4.执行语句
preparedStatement.executeUpdate();
// 5.释放资源
this.closeConnection(conn, preparedStatement, null);
}
private Connection getConnection() throws SQLException {
String url = "jdbc:mysql://localhost:3306/demo";
String user = "root";
String password = "123456";
return DriverManager.getConnection(url, user, password);
}
private void closeConnection(Connection conn, PreparedStatement preparedStatement, ResultSet rs) throws SQLException {
if (rs != null) {
rs.close();
}
if (preparedStatement != null) {
preparedStatement.close();
}
if (conn != null) {
conn.close();
}
}
}
抽取sql模板与sql参数
观察上面的截图,有以下几点发现:
- sql模板硬编码了,当前方法与t_user强关联,无法处理t_department等其他表数据
- 第三步操作很机械化,仅仅是给sql模板赋值,能否简化?
- 相比update操作,query多了一步:处理结果集
先来优化前两个问题:
- sql模板就是一个String字符串,可以抽取为参数传入
- PreparedStatement提供了setObject(index, value)方法,可以不用判断具体字段类型
所以update(增删改)可以暂时优化成这样:
public void update(String sql, Object[] params) throws SQLException {
// 1.获取连接
Connection conn = getConnection();
// 2.传入sql模板得到PreparedStatement
PreparedStatement preparedStatement = conn.prepareStatement(sql);
// 3.设置模板参数
for (int i = 0; i < params.length; i++) {
// 和数组不同,PreparedStatement参数设置从1开始
preparedStatement.setObject(i + 1, params[i]);
}
// 4.执行语句
preparedStatement.executeUpdate();
// 5.释放资源
closeConnection(conn, preparedStatement, null);
}设计模式中有个说法:越抽象越稳定,越具体越不稳定,所以提倡面向抽象编程。设计模式的目的不是消除变化,而是隔离变化。在软件工程中,变化的代码就像房间里一只活蹦乱跳的兔子,你并不能让它绝对安静(不要奢望需求永不变更),但可以准备一个笼子把它隔离起来,从而达到整体的稳定。
比如query方法:
public void query() throws SQLException {
// 1.建立连接
String url = "jdbc:mysql://localhost:3306/demo";
String user = "root";
String password = "123456";
Connection conn = DriverManager.getConnection(url, user, password);
// 省略其他代码
}获取Connection这步操作是必须的,是无法省略的,而且在可预见的未来,这段代码是不稳定的(不一定是换数据库地址,也可能是改密码)。较好的做法是,把获取Connection的代码封装到另一个方法中(甚至另一个类中):
public void query() throws SQLException {
// 1.获取连接(就一个方法调用,除非要改方法名,否则十分稳定)
Connection conn = ConnectionUtil.getConnection();
// 省略其他代码
}
public class ConnectionUtil {
public static Connection getConnection() {
String url = "jdbc:mysql://localhost:3306/demo";
String user = "root";
String password = "123456";
return DriverManager.getConnection(url, user, password);
}
}未来即使要更改数据库地址、用户名或密码,都无所谓,query()方法不用做任何改动。更好的做法是,把这些都抽取到配置文件中运行时读取,这也是通常意义上的“最佳优化”。之前有位同学问我,能不能配置文件都不用改就完成需求,我都不知道该说什么...
同理,上面优化的思路也是如此:分析代码中稳定的部分和不稳定的部分,尝试隔离不稳定的部分。最常用的处理方案有两个:
- 把不稳定的部分抽取成参数传入(变量/方法级别)
- 把不稳定的部分抽取成抽象方法,强制子类实现(方法/类级别)
不仅变量可以抽取成参数,方法也可以抽取成参数。在Java8引入Lambda表达式之前,要想抽取方法只能通过策略模式(传递对象引用,然后在方法内部调用对象的具体方法),而Java8之后可以直接传递Lambda表达式。当然,传递Lambda表达式作为参数的前提是,参数类型是函数式接口。
本次优化只是抽取变量而已。至此,update相关的操作已经比较通用,暂时看来似乎没有优化空间了,可以告一段落。接下来我们考虑query的结果集优化。
策略模式处理query结果集
和update一样,query方法也可以抽取sql和params:
public void query(String sql, Object[] params) throws SQLException {
// 1.获取连接
Connection conn = getConnection();
// 2.传入sql模板得到PreparedStatement
PreparedStatement preparedStatement = conn.prepareStatement(sql);
// 3.设置模板参数
for (int i = 0; i < params.length; i++) {
preparedStatement.setObject(i + 1, params[i]);
}
// 4.执行语句
ResultSet rs = preparedStatement.executeQuery();
// 5.处理结果
while (rs.next()) {
System.out.println(rs.getObject(1) + "\t" + rs.getObject(2) + "\t"
+ rs.getObject(3) + "\t" + rs.getObject(4));
}
// 6.释放资源
closeConnection(conn, preparedStatement, null);
}
但作为一个query操作,我们最关心的还是返回值,而上面方法的返回值是void,且第五步只是简单地循环打印结果集的每一行数据,而不是封装为List
很明显,query的优化方向就是:想办法把ResultSet里的结果集封装到指定的Bean中并返回。
如果我们多观察几个“样本”,

就会发现最大的难点在于:我们并不知道要把结果集封装成哪个Bean,也不知道要给Bean的哪些字段赋值!比如class字段是Student特有的,birthday字段是User特有的。这意味着,如果不靠入参提示,无法做到准确的封装。
实际上,如果要封装成指定的Bean,肯定是需要外界传参的,不然鬼知道要封装成什么?除非要求返回Map之类的
所以,问题又变成了:怎么通过传参提示封装的细节呢?最直接的办法是,针对每一个特定的Bean,都传入具体的封装规则。也就是采用策略模式,不同的Bean有不同的封装策略。
// 第一步:定义一个封装策略的接口
@FunctionalInterface
public interface RowMapper {
/**
* 将结果集转为指定的Bean
*
* @param resultSet
* @return
*/
T mapRow(ResultSet resultSet);
}
// 第二步:新增一个参数:RowMapper handler,传入具体的封装策略
public List query(String sql, Object[] params, RowMapper handler) throws SQLException {
// 1.获取连接
Connection conn = getConnection();
// 2.传入sql模板得到PreparedStatement
PreparedStatement preparedStatement = conn.prepareStatement(sql);
// 3.设置模板参数
for (int i = 0; i < params.length; i++) {
preparedStatement.setObject(i + 1, params[i]);
}
// 4.执行语句
ResultSet rs = preparedStatement.executeQuery();
// 5.处理结果
List result = new ArrayList<>();
while (rs.next()) {
System.out.println(rs);
T obj = handler.mapRow(rs);
result.add(obj);
}
// 6.释放资源
closeConnection(conn, preparedStatement, null);
return result;
}
// 第三步:使用query方法时,传入封装的规则(策略模式)
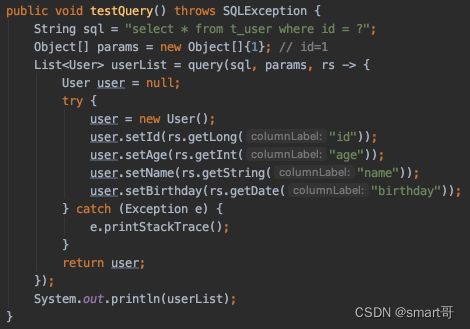
@Test
public void testQuery() throws SQLException {
String sql = "select * from t_user where id = ?";
Object[] params = new Object[]{1}; // id=1
// 直接传入匿名对象
List userList = query(sql, params, new RowMapper() {
@Override
public User mapRow(ResultSet rs) {
User user = null;
try {
user = new User();
user.setId(rs.getLong("id"));
user.setAge(rs.getInt("age"));
user.setName(rs.getString("name"));
user.setBirthday(rs.getDate("birthday"));
} catch (Exception e) {
e.printStackTrace();
}
return user;
}
});
System.out.println(userList);
} 由于RowMapper是函数式接口,所以testQuery()也可以传入Lambda表达式:
如果要用testQuery()查询Student,只需要替换sql、params并传入Student的具体封装规则即可,其他诸如getConnection()、excuteQuery()等通用步骤都已经封装在query()内部。
反射处理query结果集
正所谓“懒惰是第一生产力”,虽然采用策略模式后query()方法已经比较通用,但也仅仅是“通用”,并不“省力”。有多少种Bean就要写多少个转换规则,还是“太累了”!此时又轮到反射登场啦。
public List query(String sql, Object[] params, Class clazz) throws Exception {
// 1.获取连接
Connection conn = getConnection();
// 2.传入sql模板得到PreparedStatement
PreparedStatement preparedStatement = conn.prepareStatement(sql);
// 3.设置模板参数
for (int i = 0; i < params.length; i++) {
preparedStatement.setObject(i + 1, params[i]);
}
// 4.执行语句
ResultSet rs = preparedStatement.executeQuery();
// 5.利用反射封装Bean
List result = new ArrayList<>();
while (rs.next()) {
// 从ResultSet获取每一行结果集元数据(一行结果集就是一行表数据,对应一个Bean)
ResultSetMetaData metaData = rs.getMetaData();
// 创建bean
T bean = clazz.newInstance();
// 列数
int columnCount = metaData.getColumnCount();
// 循环封装
for (int i = 0; i < columnCount; i++) {
// 列名,不要写成getColumnName(i),因为列是从1开始的
String name = metaData.getColumnName(i + 1);
// 该列对应的值
Object value = rs.getObject(name);
// 反射出Bean中与列名对应的属性,将结果集的value设置进去 TODO column_name要与fieldName一致,目前不支持驼峰
Field field = clazz.getDeclaredField(name);
field.setAccessible(true);
field.set(bean, value);
}
// 加入到list
result.add(bean);
}
// 6.释放资源
closeConnection(conn, preparedStatement, null);
return result;
} Class参数的作用就是告诉query方法希望它把结果集封装成哪种类型的Bean。至此,我们的query()方法不仅“通用”,还很“省力”。需要说明的是,相比传入RowMapper,反射会带来一定的性能损耗。另外,由于是Demo,并没有做到驼峰和下划线的自动映射。好在一开始设计t_user表时,只定义了简单的字段名,比如name、age啥的。
JdbcTemplate完整代码
至此,JdbcTemplate的封装思路都介绍完了,来看看最终的代码吧:
/**
* 结果集映射器
*
* @author mx
*/
@FunctionalInterface
public interface RowMapper {
/**
* 将结果集转为指定的Bean
*
* @param resultSet
* @return
*/
T mapRow(ResultSet resultSet);
} /**
* JdbcTemplate,简化jdbc操作
*
* @author mx
*/
public class JdbcTemplate {
public List queryForList(String sql, List 我们自己的Mini-JdbcTemplate虽然没法和Spring-JdbcTemplate相比,但也算麻雀虽小五脏俱全了。我同时保留了RowMapper和Class两种写法,把选择的权利交给调用者。另外,一些待优化的细节我都在代码里标注了TODO,大家有兴趣可以自行实现。还有一个连接池相关的优化点,现在JdbcTemplate里的getConnection()和closeConnection()可以单独抽取成一个类,然后加上DataSource连接池就更好了(现在每次操作都会创建Connection、销毁Connection)。
最后,再来看看Spring封装的JdbcTemplate吧:
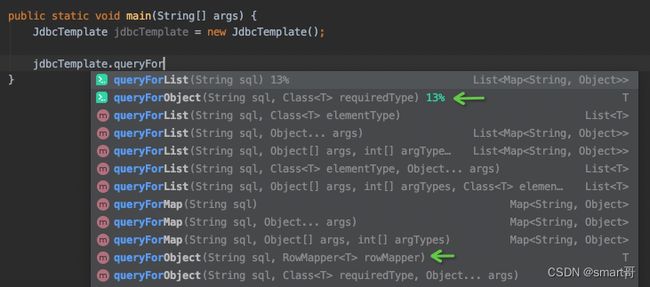
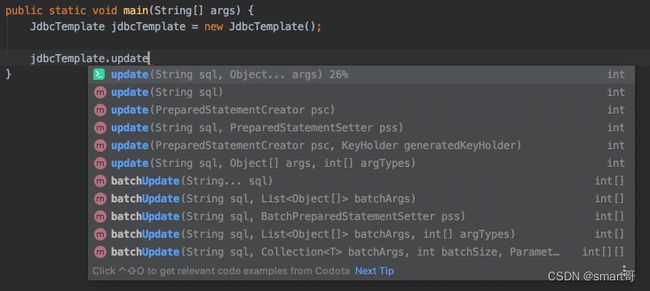
思考题
上面的JdbcTemplate还能优化吗?我在评论区给出了我的答案,也期待你有不同的思路。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬