数据分析初学者的热门项目推荐(附数据集链接)
文章目录
- 初学者练习项目
-
-
- 1. 薪资数据
- 2 . 市场营销分析探索性数据分析
- 3 . UFO目击数据分析
- 4 . 数据清理练习
-
- Python热门数据分析项目
-
-
- 5. Uber行程分析
- 6. 推特情感分析
- 7. 房价预测
-
- 租赁和住房数据分析项目
-
-
- 8. Zillow住房价格
- 9. Airbnb房源数据分析项目
- 10. 纽约市房地产销售数据
-
- 娱乐音乐行业数据分析项目
-
-
- 11. 影视行业数据集
- 12. 流行音乐数据分析
-
- 经济和公共数据分析项目
-
-
- 13. 新冠数据分析
- 14. 新闻媒体数据集
- 15. 巨无霸指数分析
-
- 高级数据分析项目(使用API)
-
-
- 16. 谷歌趋势数据分析
- 17.《纽约时报》电影评论情绪分析
-
初学者练习项目
初学者项目的提供了实际的、有趣的数据分析练习,旨在帮助新手巩固基础技能、学习数据处理和分析的实际应用。通过探索不同领域的数据集,初学者可以培养对数据的理解、处理和分析的能力。通过下面项目可以逐步学习,从简单的描述性分析到更复杂的数据清理和挖掘任务。
1. 薪资数据
链接: Salary_Data
介绍:
这个薪资数据集,相对容易阅读和清洗,
适合对该数据集进行描述性分析,我们可以确定哪些人口统计学特征与薪资减少或增加有关。例如,我们可以探索按性别、年龄、行业甚至前工作年限等因素对薪资影响。
2 . 市场营销分析探索性数据分析
链接: Marketing Analytics | Kaggle
介绍: 这个市场营销分析数据集包括客户档案、活动成功与失败、渠道表现和产品偏好。可以通过这个数据集研究市场营销分析,你可以通过数据回答许多问题,比如:
- 哪些因素与商店购买数量显著相关?
- 在运行活动的地区和该活动的成功之间是否存在显著关系?
- 美国在总购买方面与世界其他地方相比如何?
还可以参考Top的笔记本Marketing Analytics EDA task [Final] | Kaggle,里面包括许多可视化和分析。
3 . UFO目击数据分析
链接:UFO Sightings | Kaggle
介绍: 这是一个有趣的数据集,包含了过去100年来的80,000多次目击数据。可以通过它可以了解目击报告最频繁的地点,美国与世界其他地方的目击情况等等。此外,这个数据集也有许多笔记本可以查看,其中包含有用的代码片段。
4 . 数据清理练习
链接: Data Cleaning Challenge: Handling missing values | Kaggle
介绍: 这个挑战要求清理数据以及执行各种数据清理任务,包括处理缺失值、缩放和规范化以及解析日期等技术。
Python热门数据分析项目
这三个热门项目展现了在真实的商业环境中,如何使用Python进行商业数据分析:Uber行程分析项目通过Kaggle数据集深入挖掘Uber商业运作模式,推特情感分析项目借助Twitter数据集展示了情感趋势的变化,而房价预测项目则利用加利福尼亚人口普查数据集进行房价研究。在分析过程中,可以运用时间序列分析、自然语言处理和地理数据可视化等方面的技能。
5. Uber行程分析
链接: Uber Pickups in New York City | Kaggle
介绍: 这是来自Aman Kharwal的一个分析项目:Uber Trips Analysis using Python | Aman Kharwal。该项目使用了FiveThirtyEight提供的Kaggle数据集,其中包含近2000万次Uber接载。有许多角度可以分析这个数据集,比如热门的接载时间或每周最繁忙的日子。
下面是一个按小时分析接载时间的数据可视化:
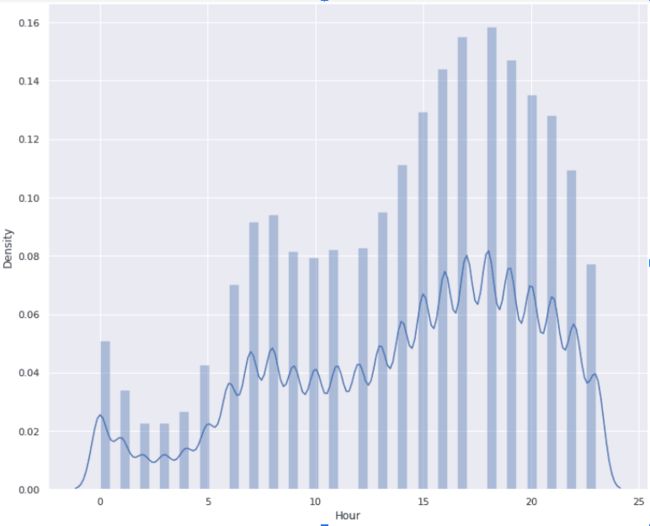
6. 推特情感分析
介绍: 推特(现在是X公司)是进行分析项目的完美数据源,你可以根据Twitter数据集执行各种分析。情感分析项目非常适合练习初学者的自然语言处理(NLP)技巧。
一种选项是测量数据集中随时间变化的情感,如下所示:
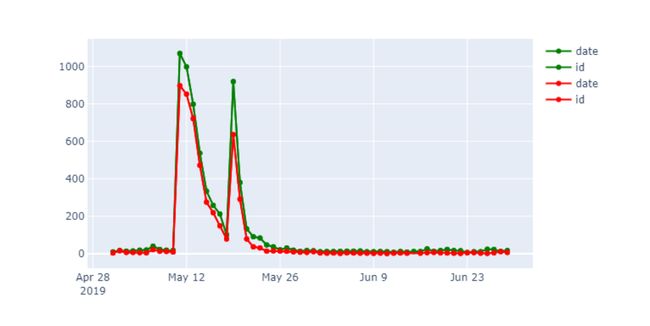
Natassha Selvaraj的这个教程提供了分析的逐步说明:Twitter Sentiment Analysis with Python
或者参考Twitter开发者论坛上的这个教程
How to analyze the sentiment of your own Tweets | Docs | Twitter Developer Platform
7. 房价预测
链接: California Housing Data (1990) | Kaggle
介绍: 这是加利福尼亚人口普查数据集,我们可以用它来预测区域、邮政编码或房屋详细信息的房价。
可以通过Python来制作这个价格热力图:

租赁和住房数据分析项目
这一系列租赁和住房数据分析项目提供了深入挖掘房地产市场的机会。Zillow住房价格数据集通过Zillow的ZHVI指数呈现了房屋市场价值的平均值,涵盖了地区、住房类型、租赁、库存和价格预测等多方面信息。Inside Airbnb项目以分析、清理和聚合的方式呈现全球数十个城市的Airbnb数据,包括房源数量、日历和评论。纽约市房地产销售数据集则展示了2016年9月至2017年9月在纽约市出售的每个房地产,为进行EDA、价格预测、回归分析和数据清理等多个项目提供了基础。
8. Zillow住房价格
链接:Zillow’s free datasets.
介绍:查看Zillow的免费数据集。 Zillow住宅价值指数(ZHVI)是按地区和住房类型平滑、季节性调整的住房市场价值的平均值。还有关于出租、住房库存和价格预测的数据集。
可以查看不同地区的房源、探索单个房源的挂牌价与售价,或查看各个城市的平均售价与平均挂牌价。
9. Airbnb房源数据分析项目
链接: Inside Airbnb
纽约房源数据链接:New York City Airbnb Open Data
介绍: 在Inside Airbnb上,您将找到经过分析、清理和聚合的Airbnb数据。有来自世界各地几十个城市的数据,包括房源数量、房源日历和房源评论。
Agratama Arfiano在这个报告已经对新加坡的Airbnb数据进行了广泛的分析。您可以进行各种不同的分析,包括按主机或按街区查找房源数量。Arfiano为该项目制作了一些非常引人注目的可视化,包括以下内容:

10. 纽约市房地产销售数据
链接: real estate dataset
介绍: 这个房地产数据集显示了2016年9月至2017年9月之间在纽约市出售的每个房地产。可以使用这些数据(或您自己创建的类似数据集)进行多个项目,包括EDA、价格预测、回归分析和数据清理。
娱乐音乐行业数据分析项目
电影、电视剧和音乐也可以通过数据分析技巧,去探索历史上娱乐行业变化。
11. 影视行业数据集
链接:
- The Movie Database 5000
- Netflix Movies and TV Shows
- Box Office Mojo data
介绍: 以Kaggle电影数据集为例,创建一个显示以下内容之一的可视化:总收入与IMDB平均评级、Netflix按评级播放的节目,或工作室对顶级电影的可视化。

12. 流行音乐数据分析
链接:Spotify前10000首歌曲
介绍: 这个数据集汇集了20世纪60年代的流行音乐排行榜,跨足各种音乐流派,呈现了多年来音乐趋势的变迁,包含了各种经典热门歌曲。
数据分析师可以使用该数据集,分析音乐流行趋势、研究特定艺术家或专辑的影响,或者探索流派演变,甚至构建基于历史音乐偏好的推荐系统。还可以分析特征随时间的变化,例如歌曲是否在演进中变得更加醇厚、生动或响亮,或者深入探讨艺术家在不同时间段的兴衰变化。
经济和公共数据分析项目
下面几个案例, 展现了数据分析技巧在经济和公共领域的应用。比如
在疫情期间,全球数据分析师通过新冠肺炎数据进行深入探索,并提供了丰富的可视化和时序分析案例。另外,新闻媒体数据集可用于观众偏好和新闻消费趋势的分析。而巨无霸指数项目为我们提供一种有趣的购买力评估方法,同时也可以通过该项目练习数据清理和多维度分析。
13. 新冠数据分析
链接:
- 欧盟新冠肺炎数据集 欧洲疾病预防和控制中心的数据集,包含欧盟地区的新冠肺炎数据。
- 美国新冠肺炎数据集《纽约时报》提供的美国新冠肺炎数据。然而,数据可能已经过时。
- 墨西哥新冠肺炎数据集墨西哥政府提供的新冠肺炎数据集。
介绍: 在疫情期间,全球的数据分析师都针对新冠数据做出了各种分析和可视化项目,同时也给初学者提供了许多非常好的可视化以及时序分析案例
最有价值的分析项目之一是那些深入研究经济和当前趋势的项目。这些项目利用了金融市场趋势、公共人口统计数据和社交媒体行为的数据,不仅对企业和政策制定者,而且对那些旨在更好地了解周围世界的个人来说,都是强有力的工具。
14. 新闻媒体数据集
链接: 数据集
新闻媒体数据集提供了有关YouTube上排名前43位的英语媒体频道的宝贵信息,包括其排名前50位的每一个视频。这个数据集虽然范围有限,但可以为观众的偏好和新闻消费趋势提供有趣的见解。
可以使用基本的情绪分析工具来确定表现最好的头条新闻是正面的还是负面的。
对于情绪分析,可以使用TextBlob 模块进行情绪分析。
from textblob import TextBlob
sentiment = ""
print(TextBlob(sentiment).sentiment)
#结果1为正,-1为负。
15. 巨无霸指数分析
链接:Big Mac Index Data
介绍: Big Mac Index 提供了一种有趣的方法来比较不同国家之间的购买力平价。该指数通过一种标准化、相同的产品麦当劳巨无霸显示了美元与其他货币的比较情况。该数据集由Andrii Samoshyn提供,包含许多缺失的数据,为数据清理提供了现实世界中的练习。数据可以追溯到2000年4月至2020年1月。
处理缺失数据的一种常见策略是使用均值或中位数等中心趋势指标来填补空白。根据缺失数据的性质,回归插补等更先进的技术也可能适用。
使用这个已清理的数据集,您可以比较一段时间内或区域之间的值。引入“地理邻近度”一栏可以提供更多的分析层次,允许在邻国之间进行比较。聚类或分类等机器学习技术可以揭示数据中的新分组或模式,为全球经济趋势提供更丰富的解释。
在进行这些分析时,重要的是要记住评估工作有效性的方法。这可能涉及显著性的统计测试、预测模型的准确性测量,甚至对绘制的数据进行视觉检查,以确保准确捕捉趋势和模式。请记住,如果没有稳健的评估方法,任何分析项目都是不完整的。
高级数据分析项目(使用API)
借助API、云服务等,将数据处理和分析流程自动化。
16. 谷歌趋势数据分析
PS:google_trends 本地挂梯子还是会失败报错,但是在colab上可以运行。
谷歌趋势是谷歌提供的一项免费服务,可以作为数据分析师的宝库,为全球流行趋势提供见解。但有一个问题。谷歌趋势不支持任何官方的API,这使得直接数据获取有点挑战。然而,有一个变通方法——使用一个google_trends模块来帮助我们抓取数据:
# 运行下面代码进行安装
# pip install -U google_trends
from google_trends import daily_trends, realtime_trends
print(realtime_trends(country='US', language='en-US', timezone='-180'))
此代码应按以下格式打印数据:
[{'title':'title of the trend',
'entity_names':['title', 'of', 'the', 'trend'],
'article_urls':['url.com', 'article.com']}, {'title':'rank two article'}]
接下来,可以创建一个自动化程序至少每小时抓取一次,并且将结果存储在CSV文件中,以便以后查询。有很多分析点,比如关键词排名、文章网站排名等等。
17.《纽约时报》电影评论情绪分析
情绪分析是衡量公众舆论和对各种主题的情绪反应的关键工具,在这种情况下,也包括电影。随着大量影评每天在《纽约时报》等广为流传的出版物上发表,适当的情绪分析可以为电影的感知质量及其在评论家中的受欢迎程度提供有价值的见解。
数据源查询:作为数据源,NYT有一个API服务,允许您查询他们的数据库。在此链接 中创建帐户并启用“电影评论”服务。然后,使用API键,可以使用以下脚本开始查询:
import requests
def query_movie(query='XXXXX', api_key='XXXX'):
return requests.get("https://api.nytimes.com/svc/movies/v2/reviews/search.json?query="+query+"&api-key=" + api_key).json()