基于 YOLOv8 的疲劳状态检测 | 附源码
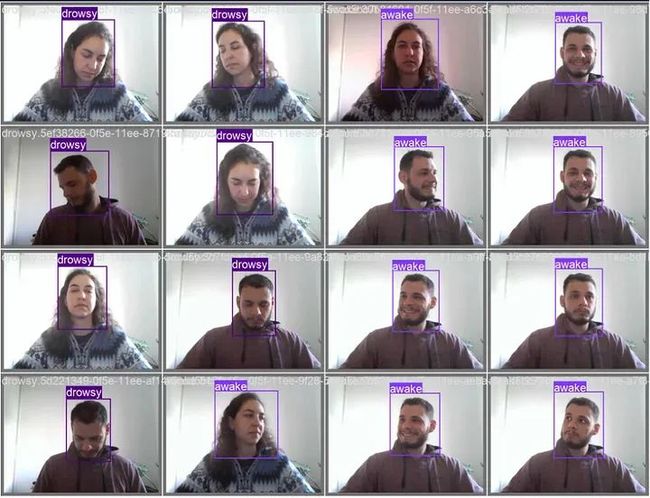
最终训练模型的推断结果
该项目旨在使用 YOLOv8,一种先进的目标检测模型,检测疲劳驾驶的迹象。目标是通过对从网络摄像头采集的图像进行训练,以检测疲劳迹象,如闭眼或头部下垂,从而创建一个自定义模型。一旦检测到疲劳,就会触发音频警报,以提醒个人并防止潜在事故。该项目专注于提高那些需要长时间驾驶或从事对警觉度至关重要的行业,如轮班工作的个人的安全性。
在我们深入了解运行该项目的详细信息之前,有一点需要注意,即您可以使用 YOLO 创建任何您想要的分类器(如果您能获得数据),尽管本例是一个疲劳检测器。
正如 ultralytics 的文档所说:
Yolov8 是备受赞誉的实时目标检测和图像分割模型的最新版本。
该模型将是我们项目的中心,它将允许我们快速轻松地创建图像检测模型。同样,根据文档:
训练模式用于在自定义数据集上训练 YOLOv8 模型。在此模式下,使用指定的数据集和超参数对模型进行训练。训练过程涉及优化模型的参数,以便它能够准确地预测图像中对象的类别和位置。
让我们专注于了解这两个基本步骤:数据收集和模型训练。对于技术读者,可以查看为整个项目从头到尾设计的这个架构模型。
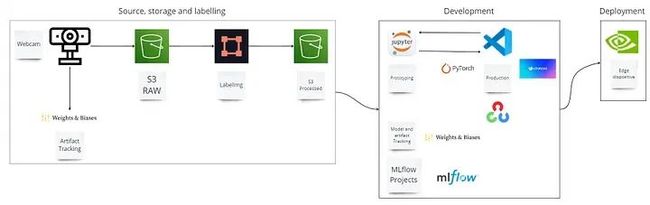
疲劳检测架构
那么让我们开始第一步:
1)数据收集
在这里,您需要一个基本的功能,即通过您自己的网络摄像头收集数据。
def collect_images_from_webcam(
labels: list, number_imgs: int, images_path: str) -> None:
'''
Collects images from the webcam and saves them to a folder.
Args:
labels (list): List of labels for the images.
number_imgs (int): Number of images to be collected for each label.
images_path (str): Path to the folder where the images will be saved.
Returns:
None
'''
cap = cv2.VideoCapture(0)
# Loop through labels
for label in labels:
print('Collecting images for {}'.format(label))
time.sleep(5)
# Loop through image range
for img_num in range(number_imgs):
logging.info(f'Collecting images for {label}, image number {img_num}')
# Webcam feed
ret, frame = cap.read()
# Naming our image path
imgname = os.path.join(images_path, label + '.' + str(uuid.uuid1()) + '.jpg')
# Write out image to file
cv2.imwrite(imgname, frame)
# Render to the screen
cv2.imshow('Image Collection', frame)
# 3-second delay between captures
time.sleep(3)
if cv2.waitKey(10) & 0xFF == ord('q'):
logging.info(f'You broke the sequence of collection for {label} images')
break
cap.release()
cv2.destroyAllWindows()通过填写参数,您可以收集尽可能多的数据,并将其存储到您选择的文件夹中。我做的一件非常有用的事情,是创建一个函数,它可以直接将收集的图像定向到正确的文件夹,您很快就会看到为什么这很有用。
def split_images(images_path: str, labels_path: str):
'''
Split the collected images into train, val, and test sets.
Args:
images_path (str): Path to the folder where the images are stored.
labels_path (str): Path to the folder where the labels are stored.
Returns:
None
'''
dest_folders = ['train', 'val', 'test']
for folder in dest_folders:
os.makedirs(os.path.join(images_path, folder), exist_ok=True)
os.makedirs(os.path.join(labels_path, folder), exist_ok=True)
file_list = os.listdir(images_path)
random.shuffle(file_list)
num_files = len(file_list)
train_count = int(TRAIN_RATIO * num_files)
val_count = int(VAL_RATIO * num_files)
for i, file_name in enumerate(file_list):
if file_name.endswith('.jpg'):
src_path = os.path.join(images_path, file_name)
if i < train_count:
dest_folder = 'train'
elif i < train_count + val_count:
dest_folder = 'val'
else:
dest_folder = 'test'
dest_path = os.path.join(images_path, dest_folder)
shutil.move(src_path, dest_path)
logging.info(f'Moved {file_name} to {dest_folder} folder.')2)模型训练
为了使用上一步收集的数据训练模型,我创建了一个自定义的 YOLO 模型函数,以便我们可以更改超参数。
def train_custom_yolo_model(
data: str,
epochs: int,
batch: int,
model_name: str,
lr0: float,
lrf: float,
weight_decay: float) -> tuple:
'''
Function to train a custom model using YOLO v8.
Args:
- data (str): Data configuration file path. Default is 'data.yaml'.
- epochs (int): Number of training epochs. Default is 20.
- batch (int): Batch size. Default is 8.
- augment (bool): Flag to enable data augmentation. Default is True.
- model_name (str): Output model name. Default is 'yolov8n_drowsiness'.
- lr0 (float): Initial learning rate for optimizer. Default is 0.01.
- lrf (float): Final learning rate for optimizer. Default is 0.01.
- weight_decay (float): Weight decay for optimizer. Default is 0.0005.
Returns:
- results (Tuple): A tuple containing the training results.
'''
# Load the pretrained model
model = YOLO('yolov8n.pt')
# Training settings
logging.info('Starting training...')
logging.info(f'Data configuration: {data}')
logging.info(f'Epochs: {epochs}')
logging.info(f'Batch size: {batch}')
logging.info(f'Model name: {model_name}')
logging.info(f'Initial learning rate: {lr0}')
logging.info(f'Final learning rate: {lrf}')
logging.info(f'Weight decay: {weight_decay}')
# Train the model
results = model.train(
data=data,
epochs=epochs,
batch=batch,
name=model_name,
lr0=lr0,
lrf=lrf,
weight_decay=weight_decay,
)
logging.info('Training completed.')
return results这就是您所需要的!相对容易,对吧?冷静下来,这并不那么容易,我们有一项至关重要的工作要做,它是一种更手动、更费力的工作。这是标记和创建 yaml 文件以供上面的模型训练函数使用的部分。看到上面的 "data" 参数,它由一个 yaml 文件提供,我们来详细了解一下。
3)yaml 文件
Ultralytics 框架使用 YAML 文件格式来定义训练检测模型的数据集和模型配置。以下是用于定义检测数据集的 YAML 格式示例:
path: /{your_local_path}/data
train: images/train
val: images/val
test: images/test您必须使用此文件为您的模型提供数据,它就像您收集并存储在这些相应文件夹(train、val、test)中的数据与您的 YOLO 模型之间的桥梁。我们还应该谈论标记数据,这是最难和最烦人的部分,但却是必要的。
4)标记您的数据
在这里,很难用文章的文字来解释这一步骤,所以我将重定向您到一篇非常好的内容,它在这方面帮助了我很多。我在这一步中使用的软件包是 labelImg。
要使用此软件包并标记您的数据,您可以访问此链接,从第 52:20 分钟开始观看,Nicholas Renotte 在那里轻松解释了如何使用它。我甚至建议您观看整个视频,这是一份令人惊叹的内容!
好吧,这就是这类项目的主要阶段,希望已经阐述清楚并让您的生活变得更轻松,如果您想使用 ultralytics 的这个令人难以置信的工具 Yolo 复制或进行类似的项目。
而在执行了所有这些步骤之后,您将能够在自己的网络摄像头上进行实时推断,甚至可以在检测到 "疲劳" 标签时触发警报!非常酷,对吧?
潜在应用:
驾驶员安全:疲劳检测模型可以集成到车辆中,以在驾驶员表现出疲劳迹象时发出警报,减少由疲劳引起的事故风险。
轮班工作:该模型可以部署在员工轮班工作的行业,如医疗保健或交通运输,以确保工人保持警觉并能够有效履行职责。
个人警报系统:个人可以将该模型用作个人安全设备,以防止在需要专注力的活动中发生与疲劳有关的事故,如学习或操作机械。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除