爬虫:报错418
目录
- 1.问题描述:
- 2.解决方法:
-
- 2.1修改
- 2.2结果
- 小结:
1.问题描述:
代码:
#导入爬虫所需要的库
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
url = requests.get('https://movie.douban.com/nowplaying/shanghai/') #请求网页
url.encoding="utf-8"
html_data=url.text
soup = bs(html_data, 'html.parser')#解析网页
nowplaying_movie = soup.find_all('div', id='nowplaying')
nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item')#定位元素位置
items=['title','score','release','director','actors']
nowplaying_list_summary=pd.DataFrame()#创建数据框,用来记录爬取内容
for item in items:
nowplaying_list_item='data-'+item
nowplaying_list_detail=[]#创建列表,记录每一部影片的具体信息
for movie in nowplaying_movie_list:
movie_item=movie[nowplaying_list_item].rjust(10)
nowplaying_list_detail.append(movie_item)
nowplaying_list_summary[item]=nowplaying_list_detail#将获取的内容合并入已有的数据框中
pd.set_option('colheader_justify', 'right')
pd.set_option('display.width', 200)
print(nowplaying_list_summary.head())
报错:
Traceback (most recent call last):
File “D:/Program Files (x86)/TransT-main/Projects/play/test9.py”, line 12, in
nowplaying_movie_list = nowplaying_movie[0].find_all(‘li’, class_=‘list-item’)#定位元素位置
IndexError: list index out of range
图片:

2.解决方法:
输出get到的内容会发现是418代码
2.1修改
添加内容
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
url = requests.get('https://movie.douban.com/nowplaying/shanghai/', headers=header) #请求网页
状态码418表示"我是个茶壶",通常是作为一个玩笑或特殊用途的响应返回。它不是一个正常的成功或错误状态码。
当你在进行网络爬虫时,有些网站会根据请求的User-Agent头部信息来判断是否是一个合法的请求。一些网站可能会禁止非常规的User-Agent或将其视为爬虫行为,并返回错误状态码。
通过设置User-Agent头部信息为一个常见的浏览器User-Agent,如上述的Mozilla/5.0,你让请求看起来像是来自一个普通的浏览器,而不是爬虫。这样做可以绕过某些网站的防爬机制,从而成功获取数据。
修改后代码:
#导入爬虫所需要的库
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
url = requests.get('https://movie.douban.com/nowplaying/shanghai/', headers=header) #请求网页
url.encoding="utf-8"
html_data=url.text
soup = bs(html_data, 'html.parser')#解析网页
nowplaying_movie = soup.find_all('div', id='nowplaying')
nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item')#定位元素位置
items=['title','score','release','director','actors']
nowplaying_list_summary=pd.DataFrame()#创建数据框,用来记录爬取内容
for item in items:
nowplaying_list_item='data-'+item
nowplaying_list_detail=[]#创建列表,记录每一部影片的具体信息
for movie in nowplaying_movie_list:
movie_item=movie[nowplaying_list_item].rjust(10)
nowplaying_list_detail.append(movie_item)
nowplaying_list_summary[item]=nowplaying_list_detail#将获取的内容合并入已有的数据框中
pd.set_option('colheader_justify', 'right')
pd.set_option('display.width', 200)
print(nowplaying_list_summary.head())
2.2结果
图片:
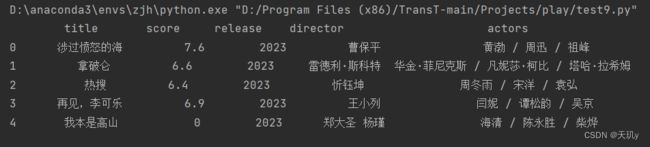
小结:
以下是常见的HTTP错误码及其对应的含义:
1xx 信息性响应:
100 Continue:服务器已接收到请求的初始部分,并且客户端应继续发送其余部分。
101 Switching Protocols:服务器正在切换协议。
2xx 成功:
200 OK:请求已成功。
201 Created:请求已经被实现,并且在服务器上创建了一个新的资源。
204 No Content:服务器成功处理了请求,但没有返回任何内容。
3xx 重定向:
301 Moved Permanently:请求的资源已被永久移动到新位置。
302 Found:请求的资源暂时被移动到新位置。
304 Not Modified:客户端使用缓存数据,请求的资源未被修改。
4xx 客户端错误:
400 Bad Request:服务器无法理解客户端的请求,可能是语法错误等。
401 Unauthorized:请求需要身份验证或认证失败。
403 Forbidden:服务器拒绝请求访问资源。
404 Not Found:请求的资源不存在。
5xx 服务器错误:
500 Internal Server Error:服务器遇到了意外错误,无法完成请求。
502 Bad Gateway:服务器作为网关或代理,从上游服务器收到无效响应。
503 Service Unavailable:服务器当前无法处理请求,通常由于过载或停机维护。
关注我给大家分享更多有趣的知识,以下是个人公众号,提供 ||代码兼职|| ||代码问题求解||
由于本号流量还不足以发表推广,搜我的公众号即可:
