R语言处理缺失值之naniar包
获取更多R语言和生信知识,请欢迎关注公众号:医学和生信笔记
医学和生信笔记 公众号主要分享:1.医学小知识、肛肠科小知识;2.R语言和Python相关的数据分析、可视化、机器学习等;3.生物信息学学习资料和自己的学习笔记!
文章目录
-
- 简介
- 如何开始探索缺失值
-
- `vis_dat()`
- `vis_miss()`
- 探索缺失值的关系
- 可视化变量中的缺失值
- 使用`NA`替换缺失值
- 整洁的缺失数据:shadow matrix
- 可视化插补后的缺失值
- 缺失值的汇总函数
- 模型化缺失值
简介
缺失值在数据中无处不在,需要在分析的初始阶段仔细探索和处理。在本次示例中,会详细介绍naniar包探索缺失值的数据结构,它和ggplot2和tidy系列使用方法非常相似!
有时,研究人员或分析人员会介绍或描述一种缺失机制。例如,他们可能会解释说,当出现极端天气事件时,气象站的数据可能会出现故障,当阵风速度很高时,他们不会记录温度数据。这似乎是一个很好的简单的,合乎逻辑的解释。然而,就像所有好的解释一样,这一解释很简单,但实现这一解释的过程可能并不简单,而且可能需要比开发探索性数据分析和模型所需的更多时间。
本次示例主要探讨3个问题:
- 开始探索缺失值
- 探索缺失值的机制
- 模型化缺失值
如何开始探索缺失值
当你面对新的数据时,可能首先会使用各种汇总函数查看数据的基本情况,比如:
summary()str()skimr::skimdplyr::glimpse()- …
但是当数据有缺失值时,就会影响接下来的分析。所以首先还要查看数据的缺失情况。
R包visdat可以展示缺失值数据,主要有4个函数:
vis_dat()vis_miss()gg_miss_upset()
vis_dat()
library(visdat)
vis_dat(airquality)

此函数可以可视化整体数据,还会给出数据类型等信息,当然也包括缺失值。
vis_miss()
vis_miss(airquality)

vis_miss则主要专注于缺失值的可视化。
探索缺失值的关系
通过vis_miss可以知道哪些变量有缺失值,但是我们还想知道这些缺失值之间有什么关系,这时候就用到naniar包了。
例如:
library(ggplot2)
ggplot(airquality,
aes(x = Solar.R,
y = Ozone)) +
geom_point()
## Warning: Removed 42 rows containing missing values (geom_point).

这幅图会直接把缺失值删掉,并不能知道缺失值的情况。
通过使用naniar包,可以达到以下效果:
library(naniar)
ggplot(airquality,
aes(x = Solar.R,
y = Ozone)) +
geom_miss_point()
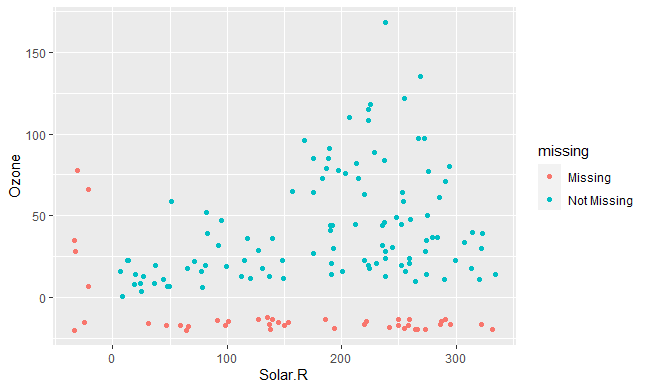
缺失值和非缺失值一目了然!
既然是ggplot2一样的tidy系列,那也肯定是支持其他特性的,比如分面:
ggplot(airquality,
aes(x = Solar.R,
y = Ozone)) +
geom_miss_point() +
facet_wrap(~Month)

支持主题:
ggplot(airquality,
aes(x = Solar.R,
y = Ozone)) +
geom_miss_point() +
facet_wrap(~Month) +
theme_dark()

可视化变量中的缺失值
gg_miss_var(airquality)

可以看到每一列有多少缺失值。
当然也是支持更换主题:
gg_miss_var(airquality) + theme_bw()

支持ggplot2的各种特性,比如labs:
gg_miss_var(airquality) + labs(y = "Look at all the missing ones")
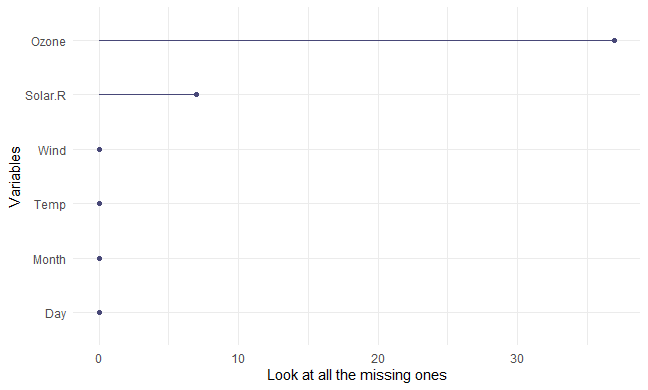
支持分面的语法和上面稍有不同:
gg_miss_var(airquality, facet = Month)

还有很多其他可视化方法:
gg_miss_upset(airquality)
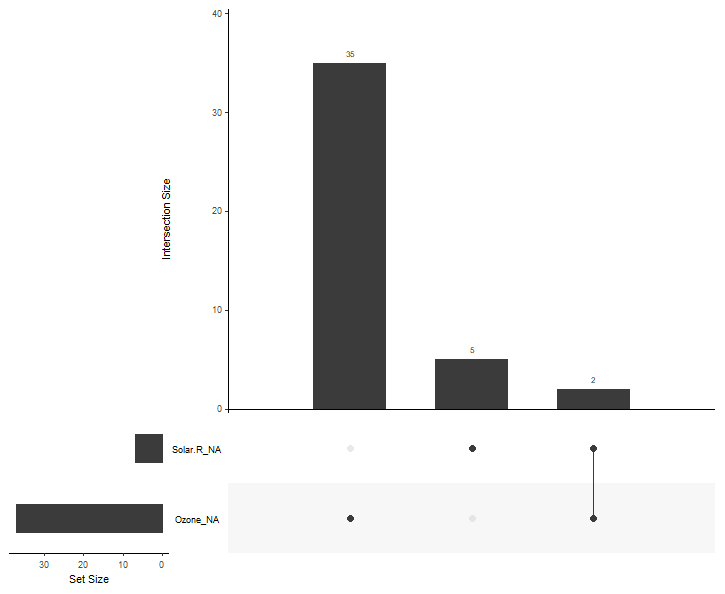
一个更加复杂的数据:
gg_miss_upset(riskfactors)

使用NA替换缺失值
在一个数据中有很多缺失值用NA来表示可能会更加方便,比如N/A、N A,Not Available,-999等。
naniar中提供了replace_with_na函数把这些缺失值替换为NA。主要有:
replace_with_nareplace_with_na_allreplace_with_na_atreplace_with_na_if
和dplyr中的replace_na()用法完全一样,不过一个是把NA替换成其他值,一个是把其他值替换成NA。
整洁的缺失数据:shadow matrix
as_shadow()函数直接以数据框的性质返回是否是缺失值,输入什么样子输出就是什么样子!
as_shadow(airquality)
## # A tibble: 153 x 6
## Ozone_NA Solar.R_NA Wind_NA Temp_NA Month_NA Day_NA
##
## 1 !NA !NA !NA !NA !NA !NA
## 2 !NA !NA !NA !NA !NA !NA
## 3 !NA !NA !NA !NA !NA !NA
## 4 !NA !NA !NA !NA !NA !NA
## 5 NA NA !NA !NA !NA !NA
## 6 !NA NA !NA !NA !NA !NA
## 7 !NA !NA !NA !NA !NA !NA
## 8 !NA !NA !NA !NA !NA !NA
## 9 !NA !NA !NA !NA !NA !NA
## 10 NA !NA !NA !NA !NA !NA
## # … with 143 more rows
把数据框形式的缺失值数据和原数据整合到一起:bind_shadow():
aq_shadow <- bind_shadow(airquality)
library(dplyr)
glimpse(aq_shadow)
## Rows: 153
## Columns: 12
## $ Ozone 41, 36, 12, 18, NA, 28, 23, 19, 8, NA, 7, 16, 11, 14, 18, 1…
## $ Solar.R 190, 118, 149, 313, NA, NA, 299, 99, 19, 194, NA, 256, 290,…
## $ Wind 7.4, 8.0, 12.6, 11.5, 14.3, 14.9, 8.6, 13.8, 20.1, 8.6, 6.9…
## $ Temp 67, 72, 74, 62, 56, 66, 65, 59, 61, 69, 74, 69, 66, 68, 58,…
## $ Month 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,…
## $ Day 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, …
## $ Ozone_NA !NA, !NA, !NA, !NA, NA, !NA, !NA, !NA, !NA, NA, !NA, !NA, !…
## $ Solar.R_NA !NA, !NA, !NA, !NA, NA, NA, !NA, !NA, !NA, !NA, NA, !NA, !N…
## $ Wind_NA !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA,…
## $ Temp_NA !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA,…
## $ Month_NA !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA,…
## $ Day_NA !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA,…
也可以使用nabular()函数达到同样的效果:
aq_nab <- nabular(airquality)
glimpse(aq_nab)
## Rows: 153
## Columns: 12
## $ Ozone 41, 36, 12, 18, NA, 28, 23, 19, 8, NA, 7, 16, 11, 14, 18, 1…
## $ Solar.R 190, 118, 149, 313, NA, NA, 299, 99, 19, 194, NA, 256, 290,…
## $ Wind 7.4, 8.0, 12.6, 11.5, 14.3, 14.9, 8.6, 13.8, 20.1, 8.6, 6.9…
## $ Temp 67, 72, 74, 62, 56, 66, 65, 59, 61, 69, 74, 69, 66, 68, 58,…
## $ Month 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,…
## $ Day 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, …
## $ Ozone_NA !NA, !NA, !NA, !NA, NA, !NA, !NA, !NA, !NA, NA, !NA, !NA, !…
## $ Solar.R_NA !NA, !NA, !NA, !NA, NA, NA, !NA, !NA, !NA, !NA, NA, !NA, !N…
## $ Wind_NA !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA,…
## $ Temp_NA !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA,…
## $ Month_NA !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA,…
## $ Day_NA !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA, !NA,…
这两种方法得到的东西是一样的:
all.equal(aq_shadow, aq_nab)
## [1] TRUE
通过这2个函数,就可以对缺失值做一些简单的统计了:
airquality %>%
bind_shadow() %>%
group_by(Ozone_NA) %>%
summarise_at(.vars = "Solar.R",
.funs = c("mean", "sd", "var", "min", "max"),
na.rm = TRUE)
## # A tibble: 2 x 6
## Ozone_NA mean sd var min max
##
## 1 !NA 185. 91.2 8309. 7 334
## 2 NA 190. 87.7 7690. 31 332
还可以通过画图展示缺失值和非缺失值的数据分布:
ggplot(aq_shadow,
aes(x = Temp,
colour = Ozone_NA)) +
geom_density()

可视化插补后的缺失值
使用simpltation包进行缺失值插补,并可视化插补后的数据:
library(simputation)
library(dplyr)
airquality %>%
impute_lm(Ozone ~ Temp + Wind) %>%
ggplot(aes(x = Temp,
y = Ozone)) +
geom_point()
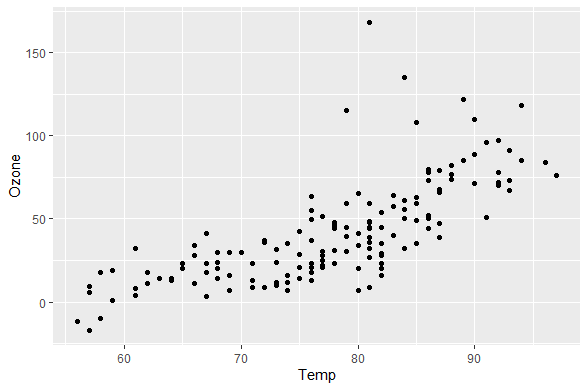
这样就不知道哪些是插补的哪些不是了,可以通过以下方法解决:
aq_shadow %>%
as.data.frame() %>%
impute_lm(Ozone ~ Temp + Wind) %>%
ggplot(aes(x = Temp,
y = Ozone,
colour = Ozone_NA)) +
geom_point()
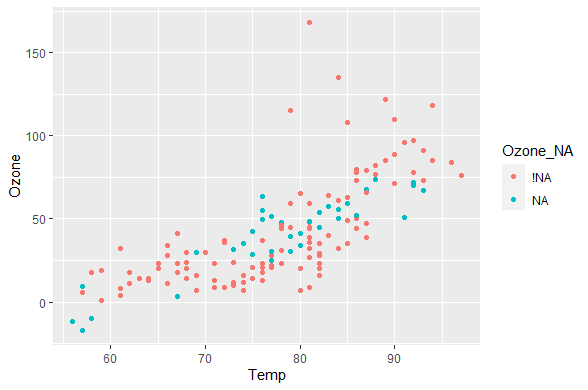
缺失值的汇总函数
主要通过n_miss()和n_complete()统计缺失值和非缺失值:
n_miss(airquality)
## [1] 44
n_complete(airquality)
## [1] 874
n_complete(airquality$Ozone)
## [1] 116
当然还提供其他格式的函数,比如百分比形式,小数形式,表格形式,针对某一列的缺失值汇总等:
prop_miss_case(airquality)
## [1] 0.2745098
pct_miss_case(airquality)
## [1] 27.45098
miss_case_summary(airquality) # 每行的缺失值
## # A tibble: 153 x 3
## case n_miss pct_miss
##
## 1 5 2 33.3
## 2 27 2 33.3
## 3 6 1 16.7
## 4 10 1 16.7
## 5 11 1 16.7
## 6 25 1 16.7
## 7 26 1 16.7
## 8 32 1 16.7
## 9 33 1 16.7
## 10 34 1 16.7
## # … with 143 more rows
汇总表格形式的,以下结果说明:有111行没有缺失值,占数据的72%,有40行只有1个缺失值,占数据的26%,有2行含2个缺失值,只占1%。
miss_case_table(airquality)
## # A tibble: 3 x 3
## n_miss_in_case n_cases pct_cases
##
## 1 0 111 72.5
## 2 1 40 26.1
## 3 2 2 1.31
还有针对列的:
prop_miss_var(airquality) # 含有缺失值的列占比
## [1] 0.3333333
pct_miss_var(airquality)
## [1] 33.33333
同样的针对列的缺失值汇总:
miss_var_summary(airquality)
## # A tibble: 6 x 3
## variable n_miss pct_miss
##
## 1 Ozone 37 24.2
## 2 Solar.R 7 4.58
## 3 Wind 0 0
## 4 Temp 0 0
## 5 Month 0 0
## 6 Day 0 0
miss_var_table(airquality)
## # A tibble: 3 x 3
## n_miss_in_var n_vars pct_vars
##
## 1 0 4 66.7
## 2 7 1 16.7
## 3 37 1 16.7
除此之外,还提供miss_var_run和miss_var_span函数,还可以和group_by连用探索缺失值!
模型化缺失值
对缺失值简历模型!如果不学习这个R包,我是真的想不到还可以这样搞缺失值!
首先看下缺失值占比:
airquality %>%
add_prop_miss() %>%
head()
## Ozone Solar.R Wind Temp Month Day prop_miss_all
## 1 41 190 7.4 67 5 1 0.0000000
## 2 36 118 8.0 72 5 2 0.0000000
## 3 12 149 12.6 74 5 3 0.0000000
## 4 18 313 11.5 62 5 4 0.0000000
## 5 NA NA 14.3 56 5 5 0.3333333
## 6 28 NA 14.9 66 5 6 0.1666667
然后我们可以使用决策树之类的模型来预测哪些变量及其值对于预测缺失比例是重要的:
library(rpart)
library(rpart.plot)
airquality %>%
add_prop_miss() %>%
rpart(prop_miss_all ~ ., data = .) %>%
prp(type = 4, extra = 101, prefix = "Prop. Miss = ")
## Warning: Cannot retrieve the data used to build the model (so cannot determine roundint and is.binary for the variables).
## To silence this warning:
## Call prp with roundint=FALSE,
## or rebuild the rpart model with model=TRUE.
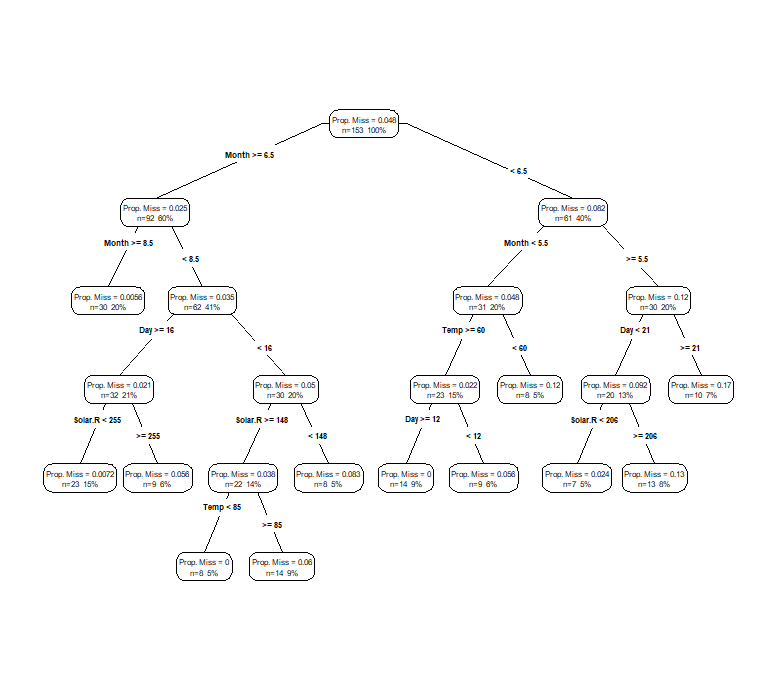
!!!震惊啊!
这个包还有很多其他的用法,本次教程只是浅尝辄止,不得不说,包的作者真是太有才了,缺失值也能玩出花来!
获取更多R语言和生信知识,请欢迎关注公众号:医学和生信笔记
医学和生信笔记 公众号主要分享:1.医学小知识、肛肠科小知识;2.R语言和Python相关的数据分析、可视化、机器学习等;3.生物信息学学习资料和自己的学习笔记!