《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》阅读笔记
论文标题
《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》
利用选择性状态空间的线性时间序列建模
作者
Albert Gu 和 Tri Dao
Albert Gu 来自卡内基梅隆大学机器学习系,Mamba 脱胎于 Albert Gu 的前作 S4 架构。
Tri Dao 来自普林斯顿大学计算机科学系,Mamba 的简化块设计结合了 Tri Dao 的 H3 块和 MLP 块。
初读
摘要
-
Transformer 架构及其核心注意力模块
-
地位:目前深度学习领域普遍的基础模型。
-
为了解决 Transformers 在长序列上的计算效率低下的问题,已经开发了许多次二次时间架构(subquadratic-time architectures),如:
-
线性注意力
-
门控卷积
-
递归模型
-
结构化状态空间模型(SSM)
-
-
仍存在的问题及原因:
-
它们在语言等重要模态上的表现不如注意力机制
-
一个关键弱点是它们无法执行基于内容的推理。
-
-
-
本文改进:
-
让 SSM 参数成为输入的函数
-
能解决离散模态的弱点,
-
使模型能够根据当前标记有选择地沿序列长度维度传播或遗忘信息。
-
-
设计了一种硬件感知的并行递归模式算法:
- 为了解决上述变化对高效卷积使用的阻碍,
- 将这些选择性 SSM 集成到一个简化的端到端神经网络架构中,该架构不含注意力,甚至不含 MLP 块(Mamba)。
-
-
Mamba 的特点:
- 快速推理(吞吐量比 Transformers 高 5 倍)
- 序列长度线性伸缩,其性能在实际数据中可提高到百万长度序列。
-
Mamba 的性能:
- 作为通用序列模型的骨干,Mamba 在语言、音频和基因组学等多种模式中都达到了最先进的性能。
- 在语言建模方面,无论是预训练还是下游评估,Mamba-3B 模型都优于同等规模的 Transformers,并能与两倍于其规模的 Transformers 相媲美。
结论
- 我们为结构化状态空间模型引入了一种选择机制,使其能够执行与上下文相关的推理,同时按序列长度线性扩展。
- 当把 Mamba 纳入一个简单的无注意力架构时,它在一系列不同的领域取得了最先进的结果,其性能达到或超过了强 Transformer 模型。
- 我们对选择性状态空间模型在不同领域建立基础模型的广泛应用感到兴奋,尤其是在基因组学、音频和视频等需要长语境的新兴模式中。我们的研究结果表明,Mamba 是通用序列模型骨干的有力候选者。
再读
Section 1 Introduction
-
第一段:基于 Transformer 及其核心注意力层的基础模型
-
现代机器学习的有效范式:
-
基础模型(Foundation models,FM),即在海量数据上进行预训练,然后针对下游任务进行调整的大型模型。
-
这些基础模型的骨干通常是序列模型,可在语言、图像、语音、音频、时间序列和基因组学等各种领域的任意输入序列上运行。
-
-
现代 FM 主要基于一种单一类型的序列模型:Transformer 及其核心注意力层。
- 优点:自注意力的功效归功于其在上下文窗口中密集路由信息的能力,使其能够对复杂数据进行建模。
- 缺陷:无法对有限窗口之外的任何事物进行建模,以及与窗口长度相关的二次缩放。
-
当前进展:
- 为了克服这些缺点,人们对注意力的更有效变体进行了大量研究,但这些研究往往以牺牲注意力的有效特性为代价。
- 到目前为止,这些变体还没有一个在跨领域的规模化应用中显示出经验上的有效性。
-
-
第二段:结构化状态空间序列模型(SSMs)
-
特点:
- 已成为序列建模领域的一类有前景的架构。
- 灵感来自经典状态空间模型。
- 这些模型可以被解释为循环神经网络(RNN)和卷积神经网络(CNN)的组合,
- 这类模型可以非常有效地进行递归或卷积计算,序列长度呈线性或近线性缩放。
-
优点:
在某些数据形式中具有建模长程依赖性的原理机制,并主导了诸如长程竞技场等基准测试。许多 SSMs 在涉及连续信号数据(如音频和视觉)的领域取得了成功。
-
缺陷:
在建模离散和信息密集数据(如文本)方面效果不佳。
-
-
本文提出了一类新的选择性状态空间模型,该模型在多个轴上改进了先前的工作,从而在序列长度线性缩放的同时实现了 Transformer 的建模能力。
-
选择机制
- 先前模型的一个关键局限:以依赖输入的方式有效选择数据的能力(即关注或忽略特定输入)。
- 基于选择性复制和感应头等重要合成任务的直觉,本文设计了一种简单的选择机制,根据输入对 SSM 参数进行参数化。这样,模型就能过滤掉无关信息,并无限期地记住相关信息。
-
硬件感知算法
- 上述简单的变化给模型的计算带来了技术挑战;事实上,所有先前的 SSM 模型都必须是时间和输入不变的,这样才能提高计算效率。
- 本文采用了一种硬件感知算法来克服这一难题,该算法通过扫描而不是卷积来计算模型,但不会将扩展状态具体化,以避免在 GPU 存储器层次结构的不同级别之间进行 I/O 访问。
- 由此产生的实现方法无论是在理论上(与所有基于卷积的 SSM 的伪线性相比,随序列长度线性扩展)还是在现代硬件上(在 A100 GPU 上可快达 3 倍)都比以前的方法更快。
-
体系结构
- 我们将先前的 SSM 架构设计与 Transformers 的 MLP 模块合并为一个模块,从而简化了先前的深度序列模型架构,形成了一种包含选择性状态空间的简单、同质的架构设计(Mamba)。
- 选择性 SSM 以及 Mamba 架构是完全递归模型,其关键特性使其适合作为在序列上运行的通用基础模型的骨干。
- 高质量:选择性为语言和基因组学等密集模式带来了强大的性能。
- 快速训练和推理:在训练过程中,计算和内存与序列长度成线性关系,而在推理过程中,由于不需要缓存以前的元素,因此自回归展开模型每一步只需要恒定的时间。
- 长上下文:质量和效率的共同作用使实际数据的性能提高到序列长度 100 万。
-
-
Mamba 的性能:
本文通过经验验证了 Mamba 作为通用序列 FM 骨干的潜力,无论是在预训练质量还是特定领域的任务性能方面,它都能在几种模式和环境中发挥作用:
-
合成:
在一些重要的合成任务上,如被认为是大型语言模型关键的复制和归纳头,Mamba 不仅能轻松解决,还能推导出无限长(>100 万个词组)的解决方案。
-
音频和基因组学:
在音频波形和 DNA 序列建模方面,Mamba 在预训练质量和下游指标(例如,在具有挑战性的语音生成数据集上,FID 降低了一半以上)方面都优于 SaShiMi、Hyena 和 Transformers 等先前的一流模型。在这两种情况下,它的性能都随着上下文长度的增加而提高,最高可达百万长度的序列。
-
语言建模:
Mamba 是第一个线性时间序列模型,无论是在预训练复杂度还是下游评估方面,都真正达到了 Transformer 质量的性能。通过多达 1B 个参数的缩放规律,我们发现 Mamba 的性能超过了大量基线模型,包括基于 LLaMa 的非常强大的现代变换器训练配方。我们的 Mamba 语言模型与类似规模的 Transformer 相比,具有 5 倍的生成吞吐量,而且 Mamba-3B 的质量与两倍于其规模的 Transformer 相当(例如,与 Pythia-3B 相比,常识推理的平均值高出 4 分,甚至超过 Pythia-7B)。
-
Section 2 State Space Models
状态空间模型
结构化状态空间序列模型(Structured state space sequence models,S4)是最近一类用于深度学习的序列模型,与 RNN、CNN 和经典状态空间模型广泛相关。它们受到一个特定连续系统 (1) 的启发,该系统通过一个隐含的潜在状态 h ( t ) ∈ R N h(t)\in\R^N h(t)∈RN 映射一个一维函数或序列 x ( t ) ∈ R → y ( t ) ∈ R x(t)\in\R\to y(t)\in\R x(t)∈R→y(t)∈R。
具体来说,S4 模型由四个参数 ( Δ , A , B , C ) (\Delta,A,B,C) (Δ,A,B,C) 定义,它们分两个阶段定义序列到序列的转换
h ′ ( t ) = A h ( t ) + B x ( t ) ( 1 a ) y ( t ) = C h ( t ) ( 1 b ) \begin{align} h'(t)&=Ah(t)+Bx(t)\qquad(1a)\\ y(t)&=Ch(t)\qquad\qquad\quad\ \ \ (1b) \end{align} h′(t)y(t)=Ah(t)+Bx(t)(1a)=Ch(t) (1b)
h t = A ‾ h t − 1 + B ‾ x t ( 2 a ) y t = C h t ( 2 b ) \begin{align} h_t&=\overline{A}h_{t-1}+\overline{B}x_t\qquad(2a)\\ y_t&=Ch_t\qquad\qquad\quad\ \ \ (2b) \end{align} htyt=Aht−1+Bxt(2a)=Cht (2b)
K ‾ = ( C B ‾ , C A B ‾ , … , C A k B ‾ , … ) ( 1 a ) y = x ∗ K ‾ ( 1 b ) \begin{align} \overline{K}&=(C\overline{B},C\overline{AB},\dots,C\overline{AkB},\dots)\qquad(1a)\\ y&=x*\overline{K}\qquad\qquad\qquad\qquad\qquad\quad\ (1b) \end{align} Ky=(CB,CAB,…,CAkB,…)(1a)=x∗K (1b)
-
离散化
第一阶段通过固定公式 A ‾ = f A ( Δ , A ) \overline{A}=f_A(\Delta,A) A=fA(Δ,A) 和 B ‾ = f B ( Δ , A , B ) \overline{B}=f_B(\Delta,A,B) B=fB(Δ,A,B) 将 “连续参数” ( Δ , A , B ) (\Delta,A,B) (Δ,A,B) 转换为 “离散参数” ( A ‾ , B ‾ ) (\overline{A},\overline{B}) (A,B) ,其中一对 ( f A , f B ) (f_A,f_B) (fA,fB) 称为离散化规则。可以使用各种规则,例如等式 (4) 中定义的零阶保持 (ZOH)。
A ‾ = exp ( Δ A ) B ‾ = ( Δ A ) − 1 ( exp ( Δ A ) − I ) ⋅ Δ B \overline{A}=\exp{(\Delta A)}\qquad\overline{B}=(\Delta A)^{-1}(\exp{(\Delta A)-I})\cdot\Delta B A=exp(ΔA)B=(ΔA)−1(exp(ΔA)−I)⋅ΔB
离散化与连续时间系统有很深的联系,可以赋予连续时间系统更多的特性,如分辨率不变性和自动确保模型正确归一化。它还与 RNN 的门控机制有关,我们将在第 3.5 节中再次讨论。不过,从机械的角度来看,离散化可以简单地看作是 SSM 前向传递中计算图的第一步。另一种 SSM 可以绕过离散化步骤,直接对 ( A ‾ , B ‾ ) (\overline{A},\overline{B}) (A,B) 进行参数化,这可能更容易推理。 -
计算
在参数从 ( Δ , A , B , C ) → ( A ‾ , B ‾ , C ) (\Delta,A,B,C)\to(\overline{A},\overline{B},C) (Δ,A,B,C)→(A,B,C) 转化之后,模型可以通过两种方式计算,一种是线性递推(2),另一种是全局卷积(3)。
通常,该模型使用卷积模式 (3) 进行高效的并行训练(提前看到整个输入序列),并切换到递归模式 (2) 进行高效的自回归推理(每次看到一个时间步的输入)。
-
线性时间不变性(LTI)
方程 (1) 至 (3) 的一个重要特性是,模型的动态在时间上是恒定的。换句话说, ( Δ , A , B , C ) (\Delta,A,B,C) (Δ,A,B,C) 以及 ( A ‾ , B ‾ ) (\overline{A},\overline{B}) (A,B) 在所有时间步中都是固定不变的。这一特性被称为线性时间不变性(LTI),它与递推和卷积有着深刻的联系。非正式地,我们认为 LTI SSM 等同于任何线性递推(2a)或卷积(3b),并用 LTI 作为这些模型类别的总称。
迄今为止,所有结构化 SSM 都是 LTI 模型(例如,以卷积方式计算),因为存在基本的效率限制,这将在第 3.3 节中讨论。然而,这项工作的一个核心观点是,LTI 模型在对某些类型的数据进行建模时具有根本性的局限性,我们的技术贡献在于消除 LTI 限制,同时克服效率瓶颈。
-
结构和尺寸
结构化 SSM 之所以被命名为结构化 SSM,是因为高效计算 SSM 还需要对 A 矩阵施加结构。最常用的结构形式是对角线结构,我们也使用这种结构。
在这种情况下, A ∈ R N × N A\in\R^{N\times N} A∈RN×N, B ∈ R N × 1 B\in\R^{N\times 1} B∈RN×1, C ∈ R 1 × N C\in\R^{1\times N} C∈R1×N 矩阵都可以用数字 N N N 来表示。要对批量大小为 B B B、长度为 L L L 、且具有 D D D 个通道的输入序列 x x x 进行操作,则 SSM 将独立应用于每个通道。请注意,在这种情况下,每个输入的总隐藏状态维度为 D N DN DN,在序列长度上计算它需要 O ( B L D N ) O(BLDN) O(BLDN) 时间和内存;这就是第 3.3 节中提到的基本效率瓶颈的根源。
-
一般状态空间模型
"状态空间模型 "一词的含义非常广泛,它简单地代表了任何具有潜在状态的循环过程的概念。它被用来指代不同学科中的许多不同概念,包括马尔可夫决策过程(MDP)(强化学习)、动态因果建模(DCM)(计算神经科学)、卡尔曼滤波器(控制)、隐马尔可夫模型(HMM)和线性动力系统(LDS)(机器学习),以及大量的递归(有时是卷积)模型(深度学习)。
本文使用 "SSM "一词专指结构化 SSM 或 S4 模型,这些术语可以互换使用。为方便起见,我们还可以包括这些模型的衍生模型,如那些侧重于线性递推或全局演化观点的模型,并在必要时澄清细微差别。
-
SSM 架构
SSM 是独立的序列变换,可被纳入端到端神经网络架构。(有时也称 SSM 架构为 SSNN,它与 SSM 层的关系就像 CNN 与线性卷积层的关系)。我们将讨论一些最著名的 SSM 架构,其中许多也将作为我们的主要基线。
- 线性注意是自我注意的一种近似方法,它涉及一种递归,可被视为一种退化的线性 SSM。
- H3 将这种递归概括为使用 S4;它可以被看作是一种由两个门控连接夹着一个 SSM 的架构(图 3)。H3 还在主 SSM 层之前插入了一个标准的局部卷积,并将其定格为移位 SSM。
- Hyena 使用与 H3 相同的架构,但用 MLP 参数化全局卷积取代了 S4 层。
- RetNet 在架构中增加了一个额外的门,并使用更简单的 SSM,允许另一种可并行计算的路径,使用多头注意力(MHA)的变体来代替卷积。
- RWKV 是最近基于另一种线性注意近似(无注意转换器)设计用于语言建模的 RNN。它的主要 "WKV "机制涉及 LTI 循环,可视为两个 SSM 的比率。
其他密切相关的 SSM 和架构将在扩展的相关工作(附录 B)中进一步讨论。我们特别强调 S5、QRNN 和 SRU,我们认为它们是与我们的核心选择性 SSM 关系最密切的方法。
Section 3 Selective State Space Models
选择性状态空间模型
- 第 3.1 节:利用合成任务的直觉来激发我们的选择机制,
- 第 3.2 节:解释如何将这一机制纳入状态空间模型。
- 第 3.3 节:由此产生的时变 SSM 不能使用卷积,这就提出了如何高效计算的技术难题。本文采用一种硬件感知算法,利用现代硬件的内存层次结构来克服这一难题。
- 第 3.4 节:描述了一个简单的 SSM 架构,它不需要注意力,甚至不需要 MLP 块。
- 第 3.5 节:讨论选择机制的一些其他特性。
3.1 Motivation: Selection as a Means of Compression
动机:选择作为一种压缩手段
-
序列建模的一个基本问题:将上下文压缩到更小的状态中。
-
从这个基本问题的角度看待流行的序列模型的取舍:
- 注意力既有效又低效,因为它根本没有明确压缩上下文。这一点可以从自回归推理需要明确存储整个上下文(即 KV 缓存)这一事实中看出,这直接导致了 Transformers 缓慢的线性时间推理和二次时间训练。
- 递归模型的效率很高,因为它们的状态是有限的,这意味着恒定时间推理和线性时间训练。然而,它们的效率受限于这种状态对上下文的压缩程度。
-
为了理解这一原理,重点讨论两个合成任务的运行示例:

- (左)复制任务的标准版本涉及输入和输出元素之间的恒定间距,可通过线性递归和全局卷积等时变模型轻松解决。
- (右上)选择性复制任务的输入间距是随机的,需要时变模型能够根据输入内容选择性地记住或忽略输入。
- (右下)"诱导头 "任务是联想记忆的一个例子,要求根据上下文检索答案,这是 LLM 的一项关键能力。
- 选择性复制任务修改了流行的复制任务,改变了要记忆的标记的位置。它要求内容感知推理能够记忆相关标记(彩色)并过滤掉不相关的标记(白色)。
- 诱导头任务是一种众所周知的机制,据推测,它可以解释大多数 LLMs 的情境学习能力。该任务要求进行情境感知推理,以了解何时在适当的情境中产生正确的输出(黑色)。
-
LTI 的缺点:
这些任务揭示了 LTI 模型的失败模式。从递归的角度来看,它们的恒定动态(例如(2)中的 ( A ‾ , B ‾ ) (\overline{A},\overline{B}) (A,B) 转换)无法让它们从上下文中选择正确的信息,也无法以依赖输入的方式影响沿序列传递的隐藏状态。从卷积的角度来看,众所周知,全局卷积可以解决初始复制任务( the vanilla Copying task),因为它只需要时间感知,但由于缺乏内容感知,全局卷积很难解决选择性复制任务(the Selective Copying task)(图 2)。更具体地说,输入到输出之间的间距是变化的,无法用静态卷积核建模。
-
总结:
序列模型的效率与效果权衡的特点在于它们如何很好地压缩其状态:**高效的模型必须有一个较小的状态,而有效的模型必须有一个包含上下文所有必要信息的状态。**反过来,我们提出建立序列模型的一个基本原则是选择性:或者说是将输入集中或过滤到序列状态中的上下文感知能力。特别是,选择机制可以控制信息如何沿着序列维度传播或交互(更多讨论见第 3.5 节)。
3.2 Improving SSMs with Selection
通过选择改进SSM
- 核心思想:让影响序列交互的参数(如 RNN 的递归动力学或 CNN 的卷积核)取决于输入,从而实现将选择机制纳入模型。

算法 1 和 2 展示了我们使用的主要选择机制。主要区别在于,我们只需将几个参数 Δ 、 B 、 C \Delta、B、C Δ、B、C 变为输入的函数,同时改变张量的形状。我们特别强调,这些参数现在都有一个长度维度 L L L,这意味着模型已经从时间不变变为时间可变。(请注意,形状注释已在第 2 节中进行了描述)。这就失去了与卷积(3)的等价性,对其效率产生了影响,将在下文讨论。
我们特别选择 s B ( x ) = L i n e a r N ( x ) s_B(x)=\mathrm{Linear}_N(x) sB(x)=LinearN(x)、 s C ( x ) = L i n e a r N ( x ) s_C(x)=\mathrm{Linear}_N(x) sC(x)=LinearN(x)、 s Δ ( x ) = B r o a d c a s t D ( L i n e a r 1 ( x ) ) s_\Delta(x)=\mathrm{Broadcast}_D(\mathrm{Linear}_1(x)) sΔ(x)=BroadcastD(Linear1(x)) 和 τ Δ ( x ) = s o f t p l u s \tau_\Delta(x)=\mathrm{softplus} τΔ(x)=softplus,其中 L i n e a r d \mathrm{Linear}_d Lineard 是维度 d d d 的参数化投影。选择 s Δ s_\Delta sΔ 和 τ Δ \tau_\Delta τΔ 是因为第 3.5 节中解释的 RNN 门控机制。
3.3 Ecient Implementation of Selective SSMs
高效实施选择性 SSM
诸如卷积和 Transformer 等硬件友好型架构得到了广泛应用。在这里,我们的目标是让选择性 SSM 在现代硬件(GPU)上也能高效运行。选择机制是非常自然的,早期的研究曾试图将选择的特殊情况纳入其中,例如让 Δ \Delta Δ 在循环 SSM 中随时间变化。然而,如前所述,使用 SSM 的一个核心限制是其计算效率,这也是 S4 及其所有衍生产品使用 LTI(非选择性)模型(最常见的形式是全局卷积)的原因。
3.3.1 Motivation of Prior Models
先行模型的动机
- 在高层次上,SSM 等循环模型总是在表现力和速度之间进行权衡:如第 3.1 节所述,隐藏状态维度越大的模型越有效,但速度越慢。因此 我们希望在不付出速度和内存代价的情况下最大化隐藏状态维度。
- 请注意,循环模式比卷积模式更灵活,因为后者(3)是由前者(2)扩展而来的。然而,这需要计算和物化形状为 ( B , L , D , N ) (B,L,D,N) (B,L,D,N) 的隐藏状态矩阵 h h h,该矩阵比输入 x x x 和形状为 ( B , L , D ) (B,L,D) (B,L,D) 的输出矩阵 y y y 要大得多(大 N N N 倍,即 SSM 状态维度)。因此,我们引入了更高效的卷积模式,该模式可以绕过状态计算,实现仅为 ( B , L , D ) (B,L,D) (B,L,D) 的卷积核 (3a)。
- 先前的 LTI SSM 利用双递归卷积形式,将有效状态维度提高了 N ( ≈ 10 − 100 ) N(\approx10-100) N(≈10−100),远大于传统的 RNN,而且不会降低效率。
3.3.2 Overview of Selective Scan: Hardware-Aware State Expansion
选择性扫描概述: 硬件感知状态扩展
选择机制旨在克服 LTI 模型的局限性,因此我们需要重新审视 SSM 的计算问题。我们用三种经典技术来解决这个问题:内核融合(kernel fusion)、并行扫描(parallel scan)和重新计算(recomputation)。我们提出了两个主要观点:
- 初级递归计算使用了 O ( B L D N ) O(BLDN) O(BLDN) FLOPs,而卷积计算使用了 O ( B L D log ( L ) ) O(BLD\ \log(L)) O(BLD log(L)) 而前者的常数因子更低。因此,对于长序列和不太大的状态维度 N N N,递归模式使用的 FLOP 实际上更少。
- 这两个挑战是递归的顺序性和大量的内存使用。为了解决后者,就像卷积模式一样,我们可以尝试不实际实现完整的状态 h h h。
其主要思路是利用现代加速器(GPU)的特性,仅在更高效的内存层次结构中实现状态 “ h h h”。特别是,大多数操作(矩阵乘法除外)都受到内存带宽的限制。这包括我们的扫描操作,我们使用内核融合来减少内存 I/O 的数量,从而比标准实现显著提速。
- 具体来说,我们不在 GPU HBM(高带宽存储器)中准备大小为 ( B , L , D , N ) (B,L,D,N) (B,L,D,N) 的扫描输入 ( A ‾ , B ‾ ) (\overline{A},\overline{B}) (A,B) ,而是直接从慢速 HBM 将 SSM 参数 ( Δ , A , B , C ) (\Delta,A,B,C) (Δ,A,B,C) 直接从慢速 HBM 加载到快速 SRAM,在 SRAM 中执行离散化和递归,然后将大小为 ( B , L , D ) (B,L,D) (B,L,D) 的最终输出写回 HBM。
- 为了避免顺序递归,我们注意到,尽管它不是线性的,但仍然可以用一种工作效率高的并行扫描算法将其并行化。
- 最后,我们还必须避免保存反向传播所必需的中间状态。我们谨慎地应用了经典的重新计算技术来降低内存需求:当输入从 HBM 加载到 SRAM 时,中间状态不会被存储,而是在后向传递中重新计算。因此,融合选择性扫描层的内存需求与使用 FlashAttention 的优化 transformer 实现相同。
有关融合内核和重新计算的详情见附录 D。图 1 展示了完整的选择性 SSM 层和算法。

图片概述:结构化 SSM 通过更高维的潜在状态 h h h(例如 N = 4 N=4 N=4),将输入 x x x 的每个通道(例如 D = 5 D=5 D=5)独立映射到输出 y y y。先前的 SSM 通过巧妙的交替计算路径避免了这一大型有效状态( D N DN DN,乘以批量大小 B B B 和序列长度 L L L)的具体化,这些路径需要时间不变性: ( Δ , A , B , C ) (\Delta,A,B,C) (Δ,A,B,C) 参数在整个时间内保持不变。我们的选择机制又增加了依赖于输入的动态,这也需要一种谨慎的硬件感知算法,以便只在 GPU 存储器层次结构中更高效的层级中实现扩展状态。
3.4 A Simplied SSM Architecture
简化的 SSM 架构
与结构化 SSM 一样,选择性 SSM 也是独立的序列变换,可以灵活地融入神经网络。H3 架构是最著名的 SSM 架构(第 2 节)的基础,一般由线性注意启发的区块和 MLP(多层感知器)区块交错组成。我们简化了这一架构,将这两个部分合二为一,均匀堆叠(图 3)。这是受门控注意力单元(GAU)的启发,该单元也对注意力做了类似的处理。
这种结构是通过一个可控的扩展因子 E E E 来扩展模型维度 D D D 。对于每个区块,大部分参数( 3 E D 2 3ED^2 3ED2)都在线性投影中(输入投影为 2 E D 2 2ED^2 2ED2,输出投影为 E D 2 ED^2 ED2),而内部 SSM 的贡献较小。相比之下,SSM 参数( Δ \Delta Δ、 B B B、 C C C 的投影和矩阵 A A A)的数量要少得多。我们重复这一模块,并交错使用标准归一化和残差连接,形成 Mamba 架构。在实验中,我们始终将 E = 2 E=2 E=2 固定下来,并使用该模块的两个堆栈来匹配 Transformer 交错 MHA(多头注意力)和 MLP 模块的 12 D 2 12D^2 12D2 参数。我们使用 SiLU/Swish 激活函数,从而使门控 MLP 成为流行的 "SwiGLU "变体。最后,我们还使用了一个可选的归一化层(我们选择了 LayerNorm),其动机是 RetNet 在类似位置使用了归一化层。

图片概述:我们的简化块设计结合了 H3 块(大多数 SSM 架构的基础)和现代神经网络中无处不在的 MLP 块。我们只是简单地重复 Mamba 模块,而不是交错使用这两个模块。与 H3 模块相比,Mamba 用激活函数取代了第一个乘法门。与 MLP 程序块相比,Mamba 在主分支上增加了一个 SSM。对于 σ \sigma σ,我们使用 SiLU / Swish 激活。
3.5 Properties of Selection Mechanisms
选择机制的特性
选择机制是一个更宽泛的概念,可以以不同的方式应用,例如应用于更传统的 RNN 或 CNN,应用于不同的参数(例如算法 2 中的 A A A),或使用不同的变换 s ( x ) s(x) s(x)。
3.5.1 Connection to Gating Mechanisms
与门控机制的联系
我们强调最重要的联系:RNN 的经典门控机制是我们 SSM 选择机制的一个实例。我们注意到,RNN 门控与连续时间系统离散化之间的联系已经得到证实。事实上,定理 1 是 Gu、Johnson、Goel 等人对 ZOH 离散化和输入依赖门的改进(证明见附录 C)。更广义地说,SSM 中的 Δ \Delta Δ 可以看作是 RNN 门控机制的一种广义作用。与之前的研究一致,我们认为 SSM 的离散化是启发式门控机制的原则基础。
定理 1. 当 N = 1 N=1 N=1, A = − 1 A=-1 A=−1, B = 1 B=1 B=1, s Δ = L i n e a r ( x ) s_\Delta=\mathrm{Linear}(x) sΔ=Linear(x) ,且 τ Δ = s o f t p l u s \tau_\Delta=\mathrm{softplus} τΔ=softplus 时,选择性 SSM 递推算法(算法 2)的形式为:
g t = σ ( L i n e a r ( x t ) ) h t = ( 1 − g t ) h t − 1 + g t x t \begin{align} g_t&=\sigma(\mathrm{Linear}(x_t))\\ h_t&=(1-g_t)h_{t-1}+g_tx_t \end{align} gtht=σ(Linear(xt))=(1−gt)ht−1+gtxt
如第 3.2 节所述,我们对 s Δ s_\Delta sΔ 和 τ Δ \tau_\Delta τΔ 的具体选择就是基于这种联系。特别要注意的是,如果给定的输入 x t x_t xt 应该被完全忽略(这在合成任务中是必要的),那么所有 D D D 通道都应该忽略它,因此我们在用 Δ \Delta Δ 重复/广播之前,会将输入投影到 1 维。
3.5.2 Interpretation of Selection Mechanisms
选择机制的解释
-
可变间距
选择性可以过滤掉相关输入之间可能出现的无关噪声标记。选择性复制任务(the Selective Copying task)就是一个例子,但在常见的数据模式中,尤其是离散数据中,例如存在 "嗯 "等语言填充物时,也会出现这种情况。这一特性的产生是因为模型可以机械地过滤掉任何特定的输入 x t x_t xt,例如在门控 RNN 的情况下(定理 1),当 g t → 0 g_t\to0 gt→0 时。
-
筛选上下文
根据经验观察,许多序列模型的性能并没有随着上下文时间的延长而提高,尽管从严格意义上讲,更多的上下文应该会带来更好的性能。一种解释是,许多序列模型在必要时无法有效忽略无关上下文;一个直观的例子是全局卷积(和一般的 LTI 模型)。另一方面,选择性模型可以在任何时候简单地重置它们的状态以去除无关的历史,因此它们的性能原则上随着上下文长度的增加而单调提高。
-
边界重置
在多个独立序列拼接在一起的情况下,Transformer 可以通过实例化特定的注意力掩码将它们分开,而 LTI 模型则会在序列之间渗入信息。选择性 SSM 还可以在边界重置状态(例如,当 Δ t → ∞ \Delta_t\to\infty Δt→∞ 或定理 1 g t → 1 g_t\to1 gt→1 时)。这些设置可能是人为的(例如将文档打包在一起以提高硬件利用率),也可能是自然的(例如强化学习中的情节边界)。
此外,我们还阐述了每个选择性参数的影响。
-
对 Δ \Delta Δ 的解释。
一般来说, Δ \Delta Δ 控制着对当前输入 x t x_t xt 的关注或忽略程度。它概括了 RNN 逻辑门(例如定理 1 中的 g t g_t gt),从机制上讲,大的 Δ \Delta Δ 会重置状态 h h h 并关注当前输入 x x x,而小的 Δ \Delta Δ 则会保持状态并忽略当前输入。SSM (1)-(2) 可以解释为一个被时间步长 Δ \Delta Δ 离散化的连续系统,直观地说,大 Δ → ∞ \Delta\to\infty Δ→∞ 表示系统更长时间地关注当前输入(从而 "选择 "当前输入并忘记当前状态),而小 Δ → 0 \Delta\to0 Δ→0 则表示忽略瞬时输入。
-
对 A A A 的解释
我们注意到,虽然 A A A 参数也可能是选择性的,但它最终只是通过 A ‾ = exp ( Δ A ) \overline{A}=\exp(\Delta A) A=exp(ΔA) (离散化 (4))与 Δ \Delta Δ 的相互作用来影响模型。因此, Δ \Delta Δ 的选择性足以确保 ( A ‾ , B ‾ ) (\overline{A},\overline{B}) (A,B) 的选择性,这也是改进的主要原因。我们假设,除了 Δ \Delta Δ 之外(或代替 Δ \Delta Δ),让 A A A 也具有选择性也会有类似的效果,为了简单起见,我们不考虑它。
-
对 B B B 和 C C C 的解释
如第 3.1 节所述,选择性最重要的特性是过滤掉无关信息,从而将序列模型的上下文压缩成一个有效的状态。在 SSM 中,修改 B B B 和 C C C 使其具有选择性,可以更精细地控制是让输入 x t x_t xt 进入状态 t t t,还是让状态进入输出 y t y_t yt。这可以解释为,模型可以分别根据内容(输入)和情境(隐藏状态)来调节循环动态。
3.6 Additional Model Details
其他模型细节
-
实数与复数
大多数先前的 SSM 在其状态迭代中使用复数,这在许多任务中都是提高性能的必要条件。然而,根据经验观察,完全实值的 SSM 似乎也能正常工作,在某些情况下甚至可能更好。我们将实值作为默认值,除一项任务外,其他任务都能很好地使用实值;我们假设,复数与实值的权衡与数据模态的连续-离散光谱有关,复数有助于连续模态(如音频、视频),但对离散模态(如文本、DNA)没有帮助。
-
初始化
大多数先前的 SSM 还建议进行特殊的初始化,尤其是在复值情况下,这在低数据量等多种情况下都有帮助。我们对复值情况的默认初始化是 S4D-Lin,对实值情况的默认初始化是 S4D-Real,它基于 HIPPO 理论。它们将 A A A 的 n n n-th 元素分别定义为 − 1 / 2 + n i -1/2+ni −1/2+ni 和 − ( n + 1 ) -(n+1) −(n+1)。不过,我们预计许多初始化都能顺利进行,尤其是在大数据和实值 SSM 环境中;第 4.6 节将考虑一些消融问题。
-
Δ \Delta Δ 的参数化
我们将 Δ \Delta Δ 的选择性调整定义为 s Δ ( x ) = B r o a d c a s t D ( L i n e a r 1 ( x ) ) s_\Delta(x)=\mathrm{Broadcast}_D(\mathrm{Linear}_1(x)) sΔ(x)=BroadcastD(Linear1(x)),这是由 Δ \Delta Δ 的力学原理(第 3.5 节)激发的。) 我们发现它可以从维度 1 推广到更大的维度 R R R。我们将其设定为 D D D 的一小部分,与区块中的主要线性投影相比,使用的参数数量可以忽略不计。我们还注意到,广播操作可以被看作是另一种线性投影,初始化为 1 和 0 的特定模式; 如果这个投影是可训练的,那么就会产生另一种 s Δ ( x ) = L i n e a r D ( L i n e a r 1 ( x ) ) s_\Delta(x)=\mathrm{Linear}_D(\mathrm{Linear}_1(x)) sΔ(x)=LinearD(Linear1(x)),这可以看作是一种低阶投影。
在我们的实验中,根据先前关于 SSM 的研究,将 Δ \Delta Δ 参数(可视为偏置项)初始化为 τ Δ − 1 ( U n i f o r m ( 0.001 , 0.1 ) ) \tau^{-1}_\Delta(\mathrm{Uniform}(0.001,0.1)) τΔ−1(Uniform(0.001,0.1))。
备注 3.1. 在我们的实验结果中,为了简洁起见,我们有时把选择性 SSM 简写为 S6 模型,因为它们是带有选择机制的 S4 模型,是用扫描计算的。
Section 4 Empirical Evaluation
经验评估
- 第 4.1 节中,我们测试了 Mamba 解决第 3.1 节中提出的两个合成任务的能力。然后,我们对三个领域进行了评估,每个领域都对自回归预训练和下游任务进行了评估。
- 第 4.2 节:语言模型预训练(缩放规律)和零点下游评估。
- 第 4.3 节:DNA 序列预训练 DNA 序列预训练和长序列分类任务的微调。
- 第 4.4 节:音频波形预训练和自回归生成语音片段的质量。
- 第 4.5 节展示了 Mamba 在训练和推理时的计算效率,第 4.6 节介绍了架构的各个组件和选择性 SSM。
4.1 Synthetic Tasks
合成任务
4.1.1 Selective Copying
选择性复制
复制任务是序列建模中研究最深入的合成任务之一,最初是为了测试递归模型的记忆能力而设计的。正如第 3.1 节所讨论的,LTI SSM(线性递归和全局卷积)只需跟踪时间而不是推理数据,就能轻松解决这个任务;例如,通过构建一个长度完全正确的卷积核(图 2)。这一点在早期的全局卷积研究中得到了明确验证。选择性复制任务通过随机化标记间的间距来防止这种捷径。请注意,这项任务之前已作为去噪任务引入。
需要注意的是,许多前人的研究认为,增加架构门控(乘法交互)可以赋予模型以 "数据依赖性 "并解决相关任务。然而,我们发现这种解释不够直观,因为这种门控并不沿着序列轴相互作用,也不能影响标记之间的间距。尤其是架构门控并不是选择机制的实例(附录 A)。
表 1 证实,H3 和 Mamba 等门控架构只能部分提高性能,而选择机制(将 S4 修改为 S6)可以轻松解决这一问题,尤其是在与这些功能更强大的架构相结合时。

4.1.2 Induction Heads
感应头
诱导头是机械可解释性视角中的一项简单任务,它对 LLM 的语境学习能力具有惊人的预测能力。它要求模型进行联想回忆和复制:例如,如果模型在序列中见过 "哈利-波特 "这样的大构词,那么下一次 "哈利 "出现在同一序列中时,模型应该能够通过复制历史来预测 “波特”。
-
数据集
我们在序列长度为 256、词汇量为 16 的诱导头任务中训练了一个双层模型,这与之前关于该任务的研究相当,但是序列更长。此外,我们还通过在测试时对从 2 6 = 64 2^6 = 64 26=64 到 2 20 = 1048576 2^{20} = 1048576 220=1048576 的一系列序列长度进行评估,研究了泛化和外推能力。
-
模型
根据有关诱导头的既有研究,我们使用 2 层模型,使注意力能够机械地解决诱导头任务。我们测试了多头注意力(8 个头,有不同的位置编码)和 SSM 变体。我们对 Mamba 使用的模型维度 D D D 为 64,对其他模型使用的模型维度 D D D 为 128。
-
结果
表 2 显示,Mamba–或者更准确地说,它的选择性 SSM 层–有能力完美地解决任务,因为它能够选择性地记住相关标记,而忽略中间的所有其他标记。它能完美地泛化到百万长度的序列,即比训练时看到的长度长 4000 倍,而其他方法都不能超过 2 倍。
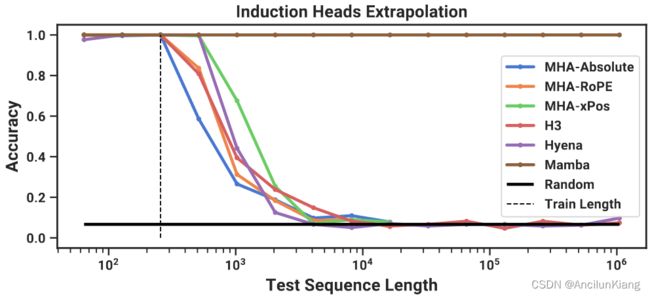
在注意力模型的位置编码变体中,xPos(专为长度外推法设计)略优于其他变体;还需注意的是,由于内存限制,所有注意力模型只测试到序列长度 2 14 = 16384 2^{14} = 16384 214=16384。在其他 SSM 中,H3 和 Hyena 相似,这与 Poli 等人(2023 年)的研究结果相反。
4.2 Language Modeling
语言建模
我们在标准自回归语言建模上评估了 Mamba 架构与其他架构的预训练指标(perplexity 困惑度)和零点评估(zero-shot evaluations)。我们将模型大小(深度和宽度)设置为 GPT3 规格。我们使用 Pile 数据集,并遵循 Brown 等人(2020 年)中描述的训练方法。所有训练细节见附录 E.2。
4.2.1 Scaling Laws
缩放定律
在基线方面,我们与标准 Transformer 架构(GPT3 架构)以及我们所知的最强 Transformer 配方(此处称为 Transformer++)进行了比较,后者基于 PaLM 和 LLaMa 架构(例如旋转嵌入、SwiGLU MLP、RMSNorm 而非 LayerNorm、无线性偏差和更高的学习率)。我们还与其他最新的亚二次方架构进行了比较(图 4)。所有模型细节见附录 E.2。
图 4 显示了在标准 Chinchilla 协议下,从 ≈ 125 M \approx125M ≈125M 到 ≈ 1.3 B \approx1.3B ≈1.3B 参数模型的缩放规律。Mamba 是第一个与非常强大的 Transformer 配方(Transformer++)性能相匹配的无注意力模型,后者现已成为标准配置,尤其是当序列长度增加时。我们注意到,RWKV 和 RetNet 基线在上下文长度为 8 k 8k 8k 的情况下,由于缺乏有效的实现,导致内存不足或不切实际的计算要求,因此缺少完整的结果。

4.2.2 Downstream Evaluations
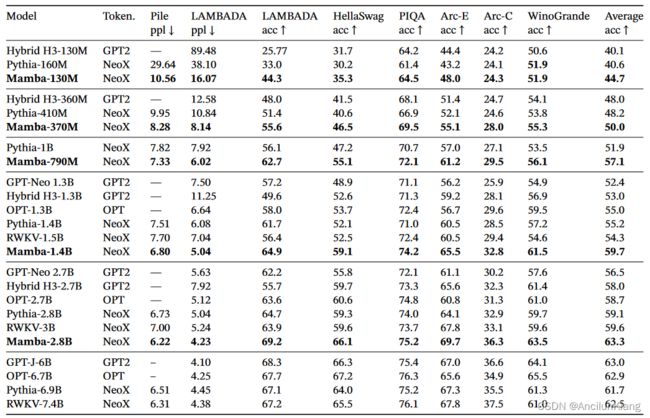
下游评估
表 3 显示了 Mamba 在一系列流行的下游零点评估任务中的表现。我们将这些模型与最著名的开源模型进行了比较,其中最重要的是 Pythia 和 RWKV,它们采用了与我们的模型相同的标记符、数据集和训练长度(300B 标记符)进行训练。(请注意,Mamba 和 Pythia 是在上下文长度为 2048 的情况下训练的,而 RWKV 是在上下文长度为 1024 的情况下训练的)。
4.3 DNA Modeling
DNA 建模
在大型语言模型取得成功的推动下,人们最近开始探索在基因组学中使用基础模型范例。DNA 被比作语言,因为它由具有有限词汇量的离散标记序列组成。众所周知,它还需要长程依赖关系来建模。我们将 Mamba 作为预训练和微调的调频骨干进行研究,其环境与最近关于 DNA 长序列模型的研究相同。特别是,我们重点探讨了模型大小和序列长度的缩放规律(图 5),以及需要长上下文的下游合成分类任务(图 6)。
在预训练方面,我们主要采用标准的因果语言建模(下一个标记预测)设置来进行训练和模型细节(另见附录 E.2)。在数据集方面,我们基本沿用了 HyenaDNA 的设置,它使用 HG38 数据集进行预训练,该数据集由单个人类基因组组成,在训练分割中包含约 45 亿个标记(DNA 碱基对)。
4.3.1 Scaling: Model Size
缩放: 模型尺寸
-
训练
为了使基线更具优势,我们在 1024 的短序列长度上进行训练;如第 4.3.2 节所示,我们预计在更长的序列长度上,结果会更有利于 Mamba。我们将全局批次大小固定为 1024,每批共有 2 20 ≈ 1 M 2^{20}\approx1M 220≈1M 个标记。对模型进行了 10 10 10 个梯度训练,共训练了 10 B 10 B 10B 个词块。
-
结果
图 5(左)显示,Mamba 的预训练复杂度随模型大小的变化而平滑提高,Mamba 的扩展能力优于 HyenaDNA 和 Transformer++。例如,在参数 ≈ 40 M \approx40M ≈40M 的最大模型规模下,曲线显示 Mamba 可以用大约少 3 倍到 4 倍的参数与 Transformer++ 和 HyenaDNA 模型相媲美。

4.3.2 Scaling: Context Length
缩放: 上下文长度
在下一个 DNA 实验中,我们研究了模型随序列长度的缩放特性。我们只对 HyenaDNA 和 Mamba 模型进行比较,因为在较长的序列长度上,二次注意的成本过高。我们在序列长度为 2 10 = 1024 2^{10} = 1024 210=1024、 2 12 = 4096 2^{12} = 4096 212=4096、 2 14 = 16384 2^{14} = 16384 214=16384、 2 16 = 65536 2^{16} = 65536 216=65536、 2 18 = 262144 2^{18} = 262144 218=262144、 2 20 = 1048576 2^{20} = 1048576 220=1048576 时对模型进行预训练。我们将模型大小固定为 6 层 128 宽(约 1.3 M − 1.4 M 1.3M-1.4M 1.3M−1.4M 个参数)。对模型进行了 20 20 20 个梯度的训练,共训练了 ≈ 330 B \approx330B ≈330B 标记。较长的序列长度使用了类似于的序列长度热身。
-
结果
图 5(右)显示,即使是长度为 100 万的超长序列,Mamba 也能利用较长的上下文。另一方面,HyenaDNA 模型随着序列长度的增加而变差。从第 3.5 节关于选择机制特性的讨论中可以直观地看出这一点。特别是,LTI 模型不能选择性地忽略信息;从卷积的角度来看,一个很长的卷积核是在一个很长的序列中汇总所有信息,而这个序列可能是非常嘈杂的。需要注意的是,虽然 HyenaDNA 声称在较长的上下文中会有所改进,但他们的结果并没有控制计算时间。

4.3.3 Synthetic Species Classication
合成物种分类
我们在一项下游任务中对模型进行了评估,该任务是通过随机取样 5 个不同物种的 DNA 连续片段来对其进行分类。这项任务改编自 HyenaDNA,后者使用的物种是 人类、狐猴、小鼠、猪、河马 {人类、狐猴、小鼠、猪、河马} 人类、狐猴、小鼠、猪、河马。我们对这项任务进行了修改,使其更具挑战性,即对已知共享 99% DNA 的五个类人猿物种 人类、黑猩猩、大猩猩、猩猩、倭黑猩猩 {人类、黑猩猩、大猩猩、猩猩、倭黑猩猩} 人类、黑猩猩、大猩猩、猩猩、倭黑猩猩 进行分类。

4.4 Audio Modeling and Generation
音频建模和生成
对于音频波形模式,我们主要与 SaShiMi 架构和训练协议进行比较。该模型包括:
- 一个 U-Net 主干网,两级池化系数使每级模型维度翻倍;
- 每级交替使用 S4 和 MLP 块。
我们考虑用 Mamba 模块取代 S4+MLP 模块。实验详情见附录 E.4。
4.4.1 Long-Context Autoregressive Pretraining
长语境自回归预训练
我们在 YouTubeMix(DeepSound 2017)上对预训练质量(自回归下一样本预测)进行了评估,YouTubeMix 是之前工作中使用的标准钢琴音乐数据集,由 4 小时的钢琴独奏音乐组成,采样率为 16000 Hz。 预训练细节基本遵循标准语言建模设置(第 4.2 节)。图 7 评估了在计算量保持不变的情况下,将训练序列长度从 2 13 = 8192 2^{13} = 8192 213=8192 增加到 2 20 ≈ 1 0 6 2^{20} ≈ 10^6 220≈106 的效果。(数据整理方式存在一些细微的边缘情况,可能会导致缩放曲线出现扭结。例如,只有分钟长的片段可用,因此最大序列长度实际上以 60 s ⋅ 16000 H z = 960000 60s ⋅ 16000Hz = 960000 60s⋅16000Hz=960000 为界)。

Mamba 和 SaShiMi(S4+MLP)基线都随着上下文长度的延长而不断改进;Mamba 在整个过程中都更胜一筹,而在更长的上下文长度下,差距就会拉大。主要指标是每字节比特数 (BPB),它是预训练其他模式时标准负对数似然 (NLL) 损失的一个常数因子 l o g ( 2 ) log(2) log(2)。
我们注意到一个重要细节:这是本文中唯一一次将实参数化转换为复参数化的实验(第 3.6 节)。我们在附录 E.4 中展示了其他消融情况。
4.4.2 Autoregressive Speech Generation
自回归语音生成
SC09 是一个基准语音生成数据集,由 1 秒钟的片段组成,采样频率为 16000 Hz,包含数字 "0 "到 “9”,具有高度可变的特征。我们基本沿用了 Goel 等人(2022 年)的自回归训练设置和生成协议。
表 4 显示了 Mamba-UNet 模型与 Goel 等人(2022 年)的各种基线相比的自动化指标: WaveNet、SampleRNN、WaveGAN、DiffWave 和 SaShiMi。小型 Mamba 模型的性能优于最先进的(大得多的)基于 GAN 和扩散的模型。与基线模型参数匹配的更大模型则进一步显著提高了保真度指标。

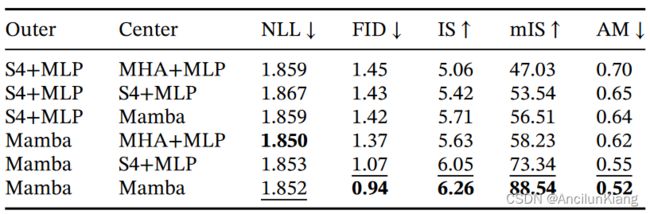
表 5 采用了小型 Mamba 模型,并研究了外层和中心阶段的不同架构组合。结果表明,在外围区块,Mamba 一直优于 S4+MLP,而在中心区块,Mamba > S4+MLP > MHA+MLP。
4.5 Speed and Memory Benchmarks
速度和内存基准测试
我们在图 8 中对 SSM 扫描操作(状态扩展 N = 16 N = 16 N=16)的速度以及 Mamba 的端到端推理吞吐量进行了基准测试。我们的高效 SSM 扫描比目前已知的最佳注意力实现(FlashAttention-2)更快,超过序列长度 2K,比 PyTorch 中的标准扫描实现快 20-40倍。Mamba 的推理吞吐量比类似规模的 Transformer 高出 4-5 倍,因为没有 KV 缓存,它可以使用更高的批处理规模。例如,Mamba-6.9B(未经训练)的推理吞吐量比 Transformer-1.3B 小 5 倍。详情见附录 E.5,其中还包括内存消耗基准。

4.6 Model Ablations
模型消融
4.6.1 Architecture
结构

表 6 调查了结构(块)及其内部 SSM 层(图 3)的影响。我们发现
- 在以前的非选择性(LTI)SSM(相当于全局卷积)中,性能非常相似。
- 用实值 SSM 取代之前工作中的复值 S4 变体对性能影响不大,这表明(至少对 LM 来说)在考虑硬件效率时,实值 SSM 可能是更好的选择。
- 用选择性 SSM(S6)取代其中任何一个都能显著提高性能,这也验证了第 3 节的动机。
- Mamba 架构的性能与 H3 架构类似(使用选择层时似乎略胜一筹)。
在附录 E.2.2 中,我们还研究了 Mamba 模块与其他模块的交错,如 MLP(传统架构)、MHA(混合注意力架构)。
4.6.2 Selective SSM
选择性 SSM
表 7 通过考虑选择性 Δ \Delta Δ、 B B B 和 C C C 参数的不同组合(算法 2),对选择性 SSM 层进行了分析,结果表明 Δ \Delta Δ 是最重要的参数,因为它与 RNN 门控有关(定理 1)。

表 8 考虑了 SSM 的不同初始化,这些初始化已被证明在某些数据模式和设置中会产生巨大差异。在语言建模方面,我们发现更简单的实值对角初始化(S4D-Real,第 3 行)比更标准的复值参数化(S4D-Lin,第 1 行)效果更好。随机初始化的效果也很好,这与之前的研究结果一致。

表 9 和表 10 分别考虑了改变 Δ \Delta Δ 和 ( B , C ) (B,C) (B,C) 投影的维度。将它们从静态变为选择性带来的好处最大,而进一步增加维度通常会在参数数少量增加的情况下适度提高性能。


特别值得注意的是,当状态大小 N N N 增加时,选择性 SSM 得到了显著改善,只需增加 1% 的参数,就能提高超过 1.0 的困惑度。这验证了我们在第 3.1 节和第 3.3 节中提出的核心动机。
Section 5 Discussion
讨论
-
相关工作
附录 Ad 讨论了选择机制与类似概念的关系。附录 B 是 SSM 和其他相关模型的扩展相关工作。
-
没有免费的午餐 连续-离散光谱
结构化 SSM 最初被定义为连续系统的离散化(1),对连续时间数据模态(如感知信号,如音频、视频)有很强的归纳倾向。正如第 3.1 节和第 3.5 节所讨论的,选择机制克服了它们在离散模式(如文本和 DNA)上的弱点;但反过来,这也会妨碍它们在 LTI SSM 擅长的数据上的表现。我们对音频波形的消融更详细地研究了这种权衡。
-
下游能力
基于转换器的基础模型(尤其是 LLM)具有丰富的生态系统特性和与预训练模型的交互模式,如微调、适应、提示、上下文学习、指令调整、RLHF、量化等。我们尤其感兴趣的是,变形器的替代品(如 SSM)是否也具有类似的特性和能力。
-
规模
我们的实证评估仅限于较小的模型规模,低于大多数强大的开源 LLM 以及其他循环模型和 RetNet 的阈值,这些模型已在 7B 参数规模及以上进行了评估。我们仍需评估 Mamba 在这些更大的规模下是否仍有优势。我们还注意到,扩展 SSM 可能涉及进一步的工程挑战和对模型的调整,本文对此未作讨论。
附录
A Discussion: Selection Mechanism
讨论: 选择机制
我们的选择机制受到门控、超网络和数据依赖等概念的启发,并与之相关。它也可以被视为与 "快速权重"相关,后者将经典 RNN 与线性注意机制联系起来。然而,我们认为这是一个值得澄清的独特概念。
-
门控
门控最初指的是 RNN 的门控机制,如 LSTM 和 GRU,或门控方程 (5)n 定理 1。这被解释为一种控制是否让输入进入 RNN 隐藏状态的特殊机制。特别是,这会影响信号在时间中的传播,并导致输入沿着序列长度维度进行交互。
不过,门控的概念在流行的用法中已被放宽,仅指任何乘法相互作用(通常与激活函数有关)。例如,神经网络架构中的元素相乘成分(不沿序列长度发生相互作用)现在通常被称为门控架构,尽管其含义与最初的 RNN 意义截然不同。因此,我们认为 RNN 门控的原始概念与乘法门控的流行用法实际上具有非常不同的语义。
-
超网络
超网络指的是其参数本身由更小的神经网络生成的神经网络。最初的想法从狭义上将其用于定义一个大型 RNN,其递归参数由一个较小的 RNN 生成。
-
数据依赖性
与超网络类似,数据依赖性可指模型的某些参数取决于数据的任何概念。
-
举例说明: GLU 激活
为了说明这些概念的问题,请考虑一个简单的对角线线性层 y = D x y=Dx y=Dx,其中 D D D 是一个对角线权重参数。现在假设 D D D 本身是由 x x x 的线性变换生成的,带有可选的非线性: D = σ ( W x ) D=\sigma(Wx) D=σ(Wx)。由于它是对角线,乘法就变成了元素乘积: y = σ ( W x ) ∘ x y=\sigma(Wx)\circ x y=σ(Wx)∘x 。
这是一个相当琐碎的变换,但它在技术上却满足了门控(因为它有一个乘法 “分支”)、超网络(因为参数 D D D 是由另一层产生的)和数据依赖(因为 D D D 取决于数据 x x x)的常见含义。然而,这实际上只是定义了一个 GLU 函数,它是如此简单,以至于经常被认为只是一个激活函数,而不是一个有意义的层。
-
选择
因此,虽然选择机制可以被视为结构门控、超网络或数据依赖等观点的特例,但其他大量的构造也可以被视为特例–基本上任何有乘法的构造都可以,包括标准的注意力机制。
相反,我们认为它与传统 RNN 的门控机制关系最为密切,后者是一个特例(定理 1),而且通过 Δ \Delta Δ 的变量(依赖于输入)离散化,与 SSM 也有着更深的联系。我们也摒弃了 “门控”(gating)一词,转而使用选择(selection),以澄清前者过多的使用。更狭义地说,我们使用选择来指代模型选择或忽略输入的机制作用,并促进序列长度上的数据交互(第 3.1 节)。除了选择性 SSM 和门控 RNN 之外,其他例子还包括依赖输入的卷积,甚至注意力。
B Related Work
B.1 S4 Variants and Derivatives
我们简要介绍了过去工作中的一些结构化 SSM,特别是那些与我们的方法有关的 SSM。
-
S4 引入了第一个结构化 SSM,描述了对角线结构和对角线加低阶(DPLR)。由于与连续时间在线记忆(HIPPO)有关,该研究重点关注 DPLR SSM 的高效卷积算法。
-
DSS 通过近似 HIPPO 初始化首次发现了对角结构 SSM 的经验有效性。这在 S4D 中得到了理论上的拓展。
-
S5 独立地发现了对角 SSM 近似,并且是第一个利用并行扫描反复计算的 S4 模型。然而,这需要降低有效状态维度,他们通过将 SSM 维度从 SISO(单输入单输出)公式转换为 MIMO(多输入多输出)公式实现了这一目标。我们提出的 S6 与扫描相同,但不同之处在于:
- 保留了 SISO 维度,从而提供了更大的有效循环状态;
- 使用硬件感知算法来克服计算问题;
- 增加了选择机制。
Lu 等人(2023 年)将 S5 应用于元 RL,以处理情节轨迹之间 SSM 状态的重置。他们的机制可以被看作是选择机制的一个特殊硬编码实例,其中 A 被手动设置为 0,而不是我们这种依赖于输入的可学习机制。如果能将选择性 SSM 通用地应用到这种设置中,并探究模型是否学会了在情节边界自动重置其状态,那将会非常有趣。
-
Mega 将 S4 简化为实值而非复值,并将其解释为指数移动平均(EMA)。此外,他们还将 SSM 的离散化步骤与 EMA 阻尼项进行了有趣的联系。与最初的 S4 论文中的发现相反,这是第一个模型显示实值 SSM 在某些情况下或与不同的架构组件相结合时是有效的。
-
Liquid S4 也是以依赖输入的状态转换来增强 S4。从这个角度看,它与选择机制有相似之处,尽管其形式有限,仍然是卷积计算,接近 LTI。
-
SGConv、Hyena、LongConv 、MultiresConv 和 Toeplitz Neural Network 都侧重于 S4 的卷积表示,并以不同的参数化创建全局或长卷积核。然而,这些方法无法直接进行快速自回归推断。
值得注意的是,所有这些方法以及我们所知的所有其他结构化 SSM 都是非选择性的,而且通常是严格的 LTI(线性时间不变)。
B.2 SSM Architectures
我们使用 SSM 架构或状态空间神经网络(SSNN)来指代将之前的 SSM 之一作为黑盒层的深度神经网络架构。
-
GSS 是第一个包含 SSM 的门控神经网络架构。它受到 Hua 等人(2022 年)的门控注意单元(GAU)的启发,看起来与我们的区块非常相似,只是多了一些投影。最重要的是,基于第 3.1 节中的动机,它的投影收缩了模型维度以减少 SSM 的状态大小,而我们的投影则扩大了模型维度以增加状态大小。
-
Mega 将上述 S4 的 EMA 简化与使用高效注意力近似的混合架构相结合。
-
H3 的动机是将 S4 与线性注意相结合。它首次将线性注意的这一表述推广到更一般的递归中,这也是后来架构的基础。
-
选择性 S4 将 S4 作为一个黑盒来生成二进制掩码,并与输入相乘。虽然与 "选择 "同名,但我们认为这是一种架构修改,更接近于架构门控而非选择机制(附录 A)。例如,我们假设它无法解决 "选择性复制 "任务,因为简单地屏蔽掉不相关的输入并不会影响相关输入之间的间距(事实上,如果噪声标记被嵌入为 0,"选择性复制 "任务甚至可以被视为预先屏蔽)。
-
RetNet 也是基于线性注意(Linear Attention),与 H3 非常相似,但将内部 S4 层简化为状态维度为 N = 1 N=1 N=1 的特殊情况。虽然其框架并非如此,但其递推可视为线性 SSM 的特例。
它的主要改进来源于使用大头部维度的线性注意,这可以看作是另一种进行输入依赖性状态扩展的方法。在线性注意变体中使用较大的头部维度是由 H3 首次实现的,但由于这需要相应的额外计算量,因此并未得到广泛应用。RetNet 采用标准多头注意力变体而不是卷积来并行计算,从而避免了这一问题。
-
RWKV 是另一种最近为语言建模而设计的 RNN。它基于 AFT(无注意力转换器),是线性注意力的另一种变体。它的主要 "WKV "机制涉及 LTI 循环,可以看作是两个 SSM 的比率。
我们还重点介绍了 Hua 等人(2022 年)的门控注意力单元(GAU),该单元的设计灵感来自于将 Transformer 的 MHA 和 MLP 模块组合在一起,也是我们将 H3 和 MLP 模块组合在一起的架构(第 3.4 节)的灵感来源。
B.3 Relationship to RNNs
RNN 和 SSM 有着广泛的联系,因为它们都涉及潜在状态的递归概念。
一些较早的 RNN,如强类型 RNN、准 RNN(QRNN)和简单递归单元(SRU)涉及无时间非线性的门控 RNN 形式。由于门控机制和选择机制的联系,这些机制可被视为选择性 SSM,因此在某种意义上比上述 LTI 结构 SSM 系列更为强大。其主要区别在于:
- 它们没有使用状态扩展( N = 1 N=1 N=1)或选择性 B B B、 C C C 参数,而这两个参数对性能都很重要(第 4.6 节)。
- 他们使用启发式门控机制,我们将其概括为选择机制+离散化的结果(定理 1)。与原则性 SSM 理论的联系提供了更好的参数化和初始化(第 3.6 节)。
此外,较早的 RNNs 还存在著名的效率问题和梯度消失问题,这两个问题都是由其顺序性引起的。对于上述一些 RNN,后者可以通过利用并行扫描来解决,但如果没有后来为 SSM 开发的理论,前者就很难解决。例如,现代结构化 SSM 与经典 SSM 理论启发下的递归动力学参数化(例如通过离散化)或直接分析有所不同。
我们还注意到,关于正交 RNN 的研究已有很长一段时间,其动机是约束 A 过渡矩阵为正交或单元矩阵,以控制其特征值并防止梯度消失问题。然而,这些研究还有其他局限性;我们认为,这些局限性源于正交/单元 RNN 也是 LTI 的这一事实。例如,它们几乎总是在 "复制 "任务中得到评估,并能完美地解决该任务,但在 "选择性复制 "任务中却显得力不从心。
B.4 Linear Attention
线性注意(LA)框架是普及核注意并展示其与递归自回归模型关系的重要成果。许多变体提出了替代核和其他修改。随机特征注意(RFA)利用高斯核的随机傅里叶特征近似,选择核特征图来近似软最大注意(即 exp 特征图)。Performer 则找到了指数核的近似值,该近似值只涉及正特征,同时也允许使用 softmax 归一化项。TransNormer 表明,LA 的分母项可能不稳定,因此建议用 LayerNorm 取而代之。cosFormer 用余弦重权机制增强了 RFA,该机制结合了位置信息以强调位置性。Linear Randomized Attention 从重要性采样的角度对 RFA 进行了概括,并将其推广到对整个 softmax 内核(而不仅仅是指数变换后的分子)提供更好的估计。
除了内核注意力,高效注意力还有许多其他变体;Tay、Dehghani、Bahri 等人(2022 年)的调查报告对其中许多变体进行了广泛分类。
B.5 Long Context Models
长语境已成为一个热门话题,最近有几个模型声称可以扩展到越来越长的序列。不过,这些模型通常都是从计算角度出发,尚未经过广泛验证。这些模型包括:
- Recurrent Memory Transformer 是 Transformer 骨干的轻量级封装。它显示了泛化多达 100 万个序列的能力,但仅限于合成记忆任务;他们的主要结果与我们的诱导头外推法实验类似(表 2)。
- LongNet 号称可扩展至 1B 长度,但在实际任务中只对长度 < 100 的情况进行了评估。
- Hyena 和 HyenaDNA,它们声称最多可利用 100 万上下文。然而,他们的实验在更长的上下文中对更多的数据进行了训练,因此很难断定在 100 万上下文中质量的提高是由于上下文长度还是由于更多的数据和计算。
- Sparse Transformer 展示了一个概念验证,即使用分步稀疏注意力变换器对长度为 2 20 = 1048576 2^{20} = 1048576 220=1048576 的音频波形进行建模,但并未讨论控制计算和模型大小时的性能权衡。
与此相反,我们认为,这项工作首次提出了一种方法,有意义地证明了随着语境时间的延长,性能也在不断提高。