数据库mysql详细教学
目录
mysql的第一组基本操作:数据库操作
1、查看当前数据库
2、创建数据库
3、选中数据库
4、删除数据库
5、表操作
5.1查看数据库中的表
编辑
5.2创建表
5.2.1数据类型
5.3 查看指定表的表结构
5.4删除表
5.5 MySQL表的增删改查
5.5.1新增 / 插入数据
5.5.2 查找操作
eg1:全列查找
eg 2:原来基础上+条件
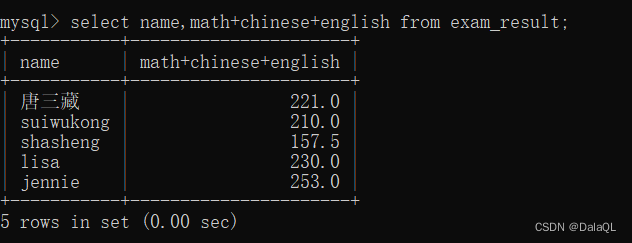
eg 3:查询每个同学的总成绩
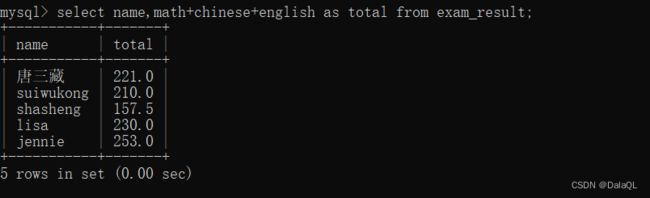
eg 4:查询的时候指定别名(相当于起了个小名,更方便理解含义)
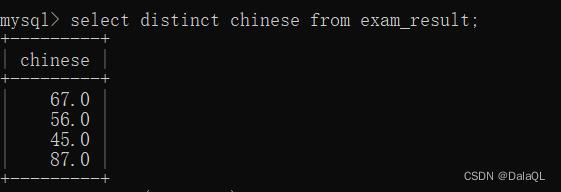
eg 5:去重查询
eg 6:条件查询
eg7:between and 约定一个前闭后闭 区间(包括两侧边界)
eg8:查询数学成绩是 87 或 98 或 56的同学
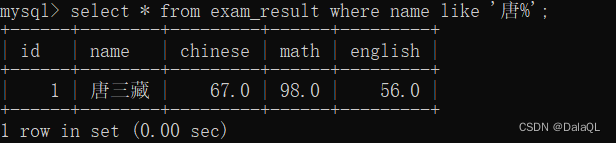
eg9:模糊查询 like
eg10:NULL / null 表示表格这一项为空
eg11:分页查询 limit
5.5.3修改操作
5.5.4 删除操作
数据库约束
1、not null
2、unique
3、default
4、primary key
5、foreign key 外键
表的设计
把查询和新增联合起来
更复杂的查询
01聚合查询
02联合查询
03内连接
04外连接
05自连接
06子查询
07合并查询
索引
索引的数据结构
事务
事务四个特性:
并发事务可能产生的问题
四种隔离级别
1024 byte 构成 1 kb
1024 KB => 1MB
1024 MB => 1GB
1024 GB => 1TB
1024 TB => 1PB
内存的数据,断电后会丢失。外存的数据,断电后数据还在~
“持久化” 这样的次,意思就是把数据写到硬盘上。
mysql的第一组基本操作:数据库操作
1、查看当前数据库
show databases:1)show 和 databases 之间有一个或者多个空格
2)注意是databases,不是database。
3)使用 英文分号 结尾。(客户端里的任何一个sql都需要使用 分号 来结尾)
2、创建数据库
可以指定字符集。
补充:
计算机里,不同的字符集下,表示一个汉字所需要的字节不同。
平时常用的:
1、gbk windows 简体中文版,默认字符集。 2个字节表示一个汉字
2、utf8 更通用的字符集。不仅仅能表示中文 通常是3个字节白哦是一个汉字的
create database 数据库名 charset utf8(字符集)

3、选中数据库
use 数据库名;选中数据库,选中之后,会有个提示~
4、删除数据库
drop database 数据库名5、表操作
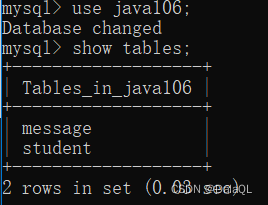
5.1查看数据库中的表

一定要先选中数据库再操作!
5.2创建表
5.2.1数据类型
- 字符:char varchar(可变长度字符串)
- 时间:data datatime
- 整数:tinyint(相当于Byte) smallint(相当于Short) int(相当于Integer) bigint(相当于Long)
- 浮点:float double
- BLOB:存储的是2进制串,和bit[]不一样,只能存最多 64 bit。blob可以存更长,比如要存一个小的图片,存一个小的音频文件。
- datetime / timestamp:都能表示年月日,时分秒。timestamp:4个字节的时间戳,不太够用了。
double 和 float 有一个很严重的问题!
表示有些数据的时候,不能精确表示!(存在误差)
0.1 + 0.2 = 0.3 => false
主要市和内存存储结构相关。
这个表示方式带来的好处,存储空间小,计算速度块,但是可能存在误差。
使用decimal,是使用了类似于字符串的方式来保存的~ 更精确存储
但是存储空间更大,计算速度更慢了
上述类型都是有符号(带有正负的)无符号的不建议使用
create table 表名(列名 类型, 列名 类型……); 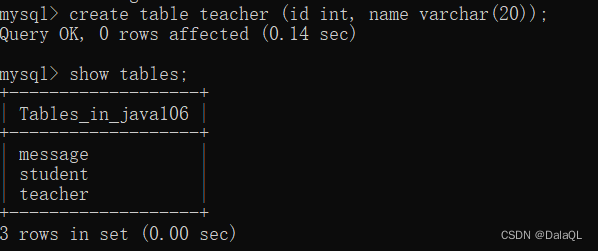
5.3 查看指定表的表结构
desc 表名;
desc -> describe 的缩写。(描述一个表是啥样的)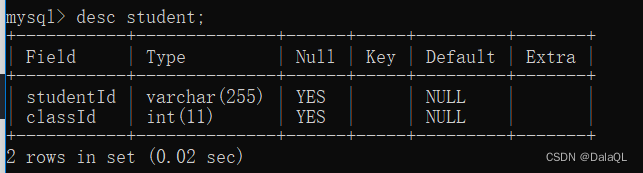
5.4删除表
drop table 表名;创建数据库也有一个 IF [NOT] EXISTS
eg:单价使用什么类型?
double (3,1) 不精确!!
decimal 是更好的选择!!(更精确)
此处更好的选择是使用
![]() 性别不止 男 和 女~
性别不止 男 和 女~
有些字段,看起来是数字,实际上是字符串~
像身份证,虽然是由数字构成的,但是这个数字不能够参与 +-*/ 算数运算
5.5 MySQL表的增删改查
CRUD 即增加(create), 查询(Retrieve), 更新(update),删除(Delete)四个单词的首字母缩写。
5.5.1新增 / 插入数据
insert into 表名 values(值,值……);![]()
values 后这里的个数,类型,顺序要和表头结构匹配~~
SQL没有字符类型,‘ 和 ‘’ 都可以表示字符串。
此处还有一种错误数据库字符集没有正确配置引起的~~
数据库不做任何修改,默认情况下创建的数据库字符集是“拉丁文”字符集,不能表示中文。
在插入的时候,指定某个 / 某些列来插入![]() 此时 values 后面的内容。就是和values前面的 () 的内容匹配的~
此时 values 后面的内容。就是和values前面的 () 的内容匹配的~
一次插入 N 个记录,比一次插入一个记录,分N次插入,效率要高一些~~ 
插入时间的时候,是通过特定格式的字符串来表示时间日期的。形如:‘2023-11-14 02:41:00’
如果想把时间设置为当前时刻,sql 提供了一个特殊的函数,now()

5.5.2 查找操作
eg1:全列查找
查找整个表,所有行的所有列。
select * from 表名;如果数据量几亿,几十亿执行 select * 操作,肯定会非常危险!!
降低危险程度,一个简单有效的办法——当你需要操作生产环境的数据库的时候,一定要拉上一个人一起操作。
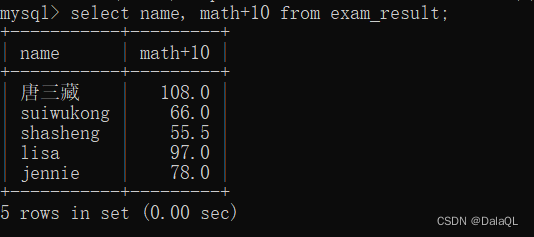
eg 2:原来基础上+条件
查询的时候,针对分数进行变换。比如让查询的math成绩都在原来基础上+10‘
select name, math+10 from 表名;
上述查询,数据库服务器硬盘的数据没有发生改变,再次查询,还是+10之前。
eg 3:查询每个同学的总成绩
表达式查询,是让列和列之间进行运算。
eg 4:查询的时候指定别名(相当于起了个小名,更方便理解含义)
使用 as 关键字
eg 5:去重查询
distinct 针对指定列进行去重(把重复行去掉)
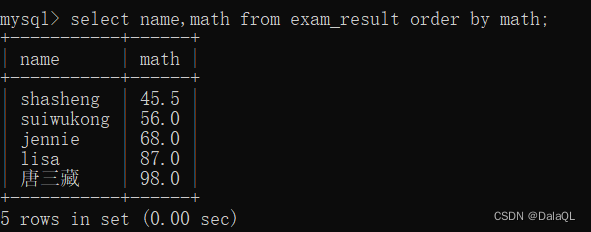
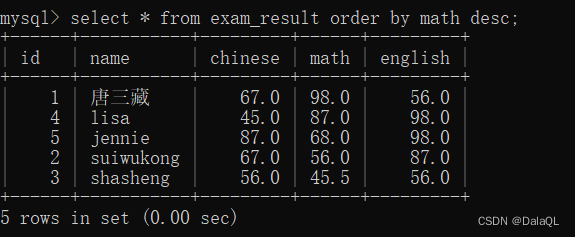
eg 6:按照查询结果排序
order by 子句,指定某些列进行排序~
排序可能是升序,也可能是降序
对于mysql来说,如果sql没有指定order by,此时查询结果集的数据顺序,是不可预期的。
order by 可以根据多个列来排序
desc 降序(descend)
asc 表示升序,但如果省略不写,默认就是升序。
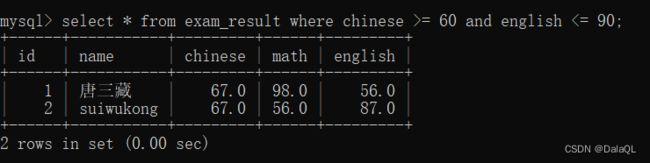
eg 6:条件查询
在查询的时候,指定筛选条件 符号条件的数据留下,不符合的直接 pass
需要先描述条件。
通过 where 子句,搭配上条件表达式,就可以完成条件查询~
可以直接拿两个列比较~
条件查询使用表达式作为条件
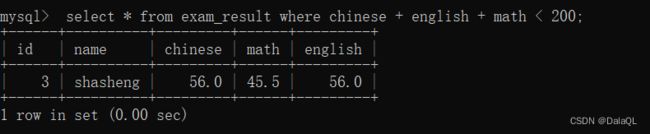
查询总分在200分以下的同学
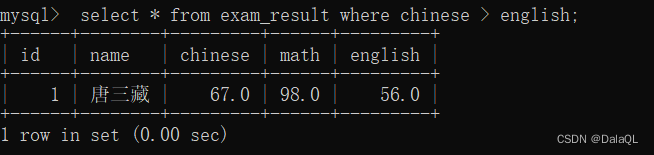
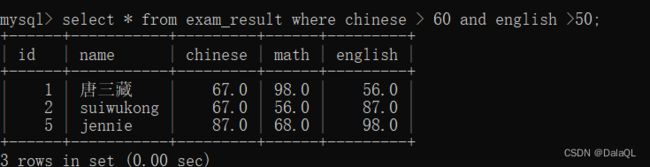
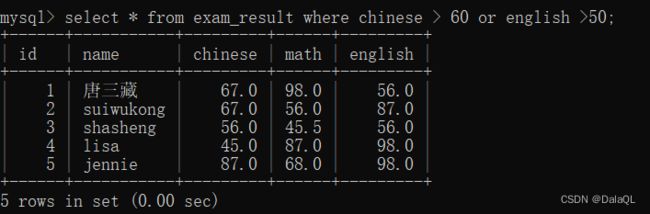
查询语文成绩大于60分,且英语成绩大于50分的同学。 and
查询语文成绩大于60,或英语成绩大于50的同学。 or
and 和 or 的优先级
一个where 中即存在 and 又存在 or,先执行 and 后执行 or。后边写代码,记得多加()。
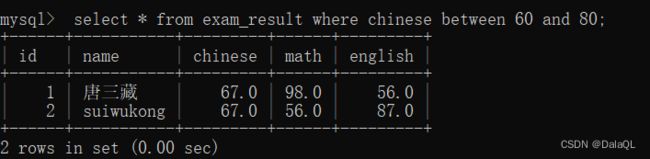
eg7:between and 约定一个前闭后闭 区间(包括两侧边界)
String 这里的有些方法,就是按照区间来指定的 substr……
List 这里的有些方法也是按照区间 subList……
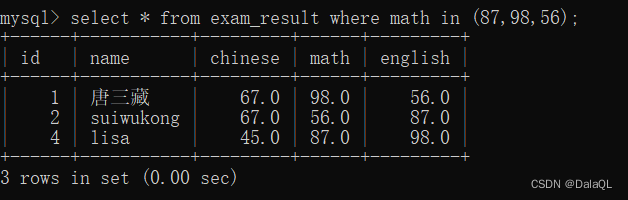
eg8:查询数学成绩是 87 或 98 或 56的同学
in
以上写法效率比较低。
eg9:模糊查询 like
模糊匹配,不要求元素完全相同,只要满足一定的规则,就可以了~
like支持两个用法:
1、使用%代表任意 0 个字符或者N个字符~
2、使用_代表任意1个字符~
like ’%藏‘ 查询藏结尾的
like ’%孙%‘ 查询包含孙的
mysql 效率比较低~
很容易成为性能瓶颈,模糊匹配更是比较低效的写法,如果这里支持的功能更复杂,反而更拖慢数据库的效率。
eg10:NULL / null 表示表格这一项为空
sql不区分大小写的
null 和其他数值进行运算,结果还是null
null结果在条件中,相当于false 了
<=> 使用这个比较相对运算,就可以处理 null 的比较!
null <=> null =》 true
或者
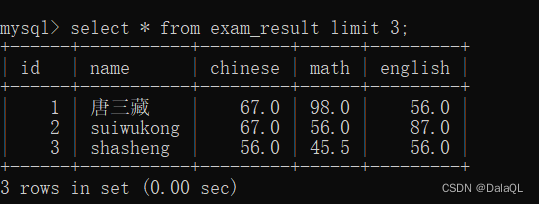
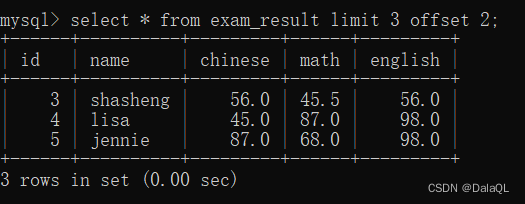
eg11:分页查询 limit
比如一共5000页,一共这么多数据,全都显示出来,一方面,用户看不过来;一方面对于系统的压力也比较大~~
一页显示10个数据~~
limit 还可以搭配 offset,声明从哪一条开始查询(从0开始计数)
limit 3 offset 6; 等价于 limit 6,3;(不太推荐这么写)
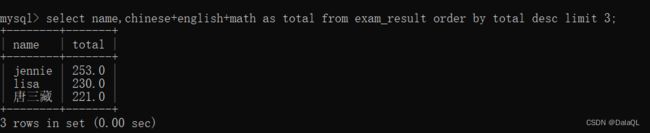
查询总分前三名的同学信息~~
1、计算每个同学的总成绩
2、按照成绩排序(降序)
3、取前三条记录~
order by 这里可以使用别名,where不能使用





5.5.3修改操作
update关键字进行
update 表名 set 列名 = 值,列名 = 值……where条件;
 order by / limit 等也是可以使用的~
order by / limit 等也是可以使用的~

超过范围了,此时修改不会生效

修改所有人的成绩为0.5倍。

update操作非常危险!
5.5.4 删除操作
delete 删除记录(行)
delete from 表名 where 条件;
delete from exam_result where name like '孙%';
不写 where 也没有 limit 就是全部了!这个操作基本相当于删表了(drop table)
delete from 表还在,里面的数据没了。 l.clear();
drop table 表和数据都没了。 l=null;
数据库约束
约束,就是数据库针对里面的数据能写啥,给出的一组“检验规则”。
- NOT NULL 必填项
- UNIQUE 让列的值是唯一的(不和别的行重复,eg:学号,手机号,身份号)
- DEFAULT 默认值
- PRIMARY KEY 主键
- FOREIGN KEY 外键
- CHECK 在mysql 5 版本中,不支持
1、not null
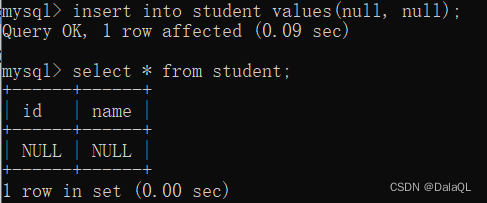
此时表中可以随意插入空值!
给一个现有的表加约束,也可以,比较麻烦,使用 alter table
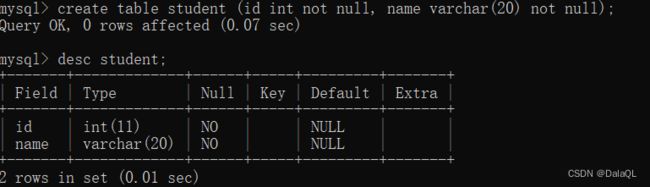
2、unique
插入/修改数据的时候,先会查询,先看看数据是否已经存在,如果不存在,就能够插入/修改成功。如果存在,则插入/修改失败。
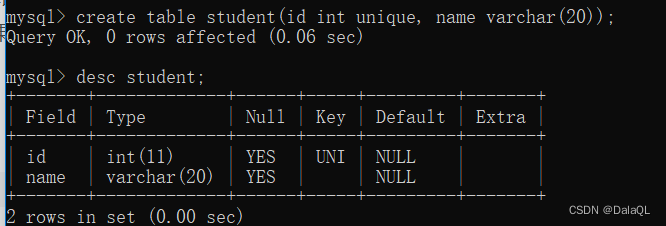
此时再插入同样的数据报错。
entry:入口,条目
补充:数据库在插入前先查询了一下~(只不过查询操作,咱们感知不到)
因此,这里是多了个查找数据的成本。
本质上,程序运行 vs 程序员开发效率。
3、default
默认值是insert指定列插入的时候,其他未被指定到列就是按照默认值来填充~~
create table 表名(id int, name varchar(20) default '无名氏');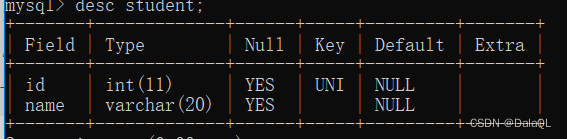
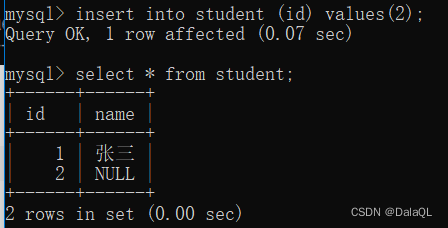
4、primary key
主键,一条记录 在表中的“身份标识” 手机号码,身份证号码,学号……
也是要求唯一,并且不能为空~~
主键 = unique + not null
mysql 要求一个表里,只能有一个主键!!
创建主键的时候,可以使用一个列作为主键,也可以使用多个列作为主键(复合主键)
create table 表名(id int primary key, name varchar(20));

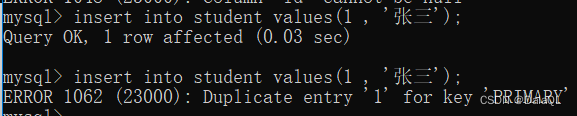
一个重要的问题:
如何给这个记录安排一个主键呢?
mysql自身只是能够检查是否重复,设置的时候还是靠程序员来设置。
此处,由很多办法,mysql提供了一个简单粗暴的做法,自增主键~~
auto_increment
create table student (id int primary key auto_increment, name varchar(20));
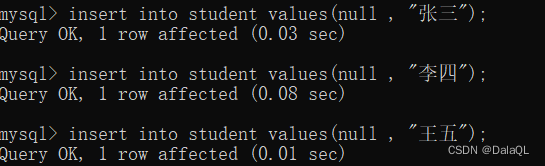
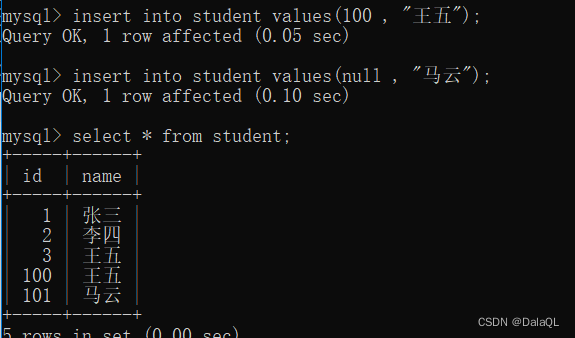
给自增主键插入数据的时候,可以手动指定一个值,也可以让mysql 自己分配。
如果让他自己分配,就在insert语句的时候,把 id 设为空即可
此时可以手动分配,也可以让mysql自己指定~
但是再次插入的时候,就从序号最大值+1开始了~
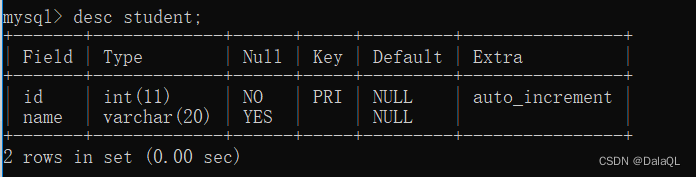

5、foreign key 外键
create table student (studentId int primary key auto_increment, name varchar(20),classId int,foreign key(classId) references class(classId));![]()
此时就要求 student 表中的每个记录的 classId 得在 class 表的 classId 中存在! ![]()
student受到class的约束,就把class叫做student的父表(parent),
student就是class的子表(child) ![]()
子类对父类也有约束,被孩子依赖的数据不能删除掉
![]()
eg:电商类网站
商品表(id, name, price……)
订单表(orderId, userId, goodsId, time ……)
订单表中的goodsId得在 商品表中存在外键约束~
有一种情况,商品要下架,如何实现?
给商品表加一列,表示是否下架,此时实现下架并非是delete记录,而是update把是否下架字段进行修改~~ 逻辑删除
表的设计
设计表,分两步走
1、梳理清楚需求中的“实体”
2、梳理清楚实体之间的关系
实体之间的关系,主要由三种(严格的说是四种)
1、一对一
一个学生,只能有一个账号。
一个账号,只能供一个学生所有
如何设计表
1)搞一个大表,包含学生信息 + 账号信息
account-student(accountId, username, password, studentName……)
2)搞两个表,相互关联
account(accountId, username, password);
student(studentId, name……);
3)搞两个表
account(accountId, username, password);
student(studentId, studentName, accountId);
后续可以搞一些教师表等,也能和account关联
2、一对多
一个班级 可以包含多个学生
一个学生只能处于一个班级
两种典型表示方式:
1)student(studnetId, name); mysql没有数组类型,不能这么搞,但是redis,是由数组类型的,此时就可以考虑这样的设计
class(classId, className, studentIdList)
2)class(classId, className);
1 2001
2 2002
student(studentId, name, classId);
1 张三 1
2 李四 2
3、多对多
一个学生可以选择多个课程,
一个课程也可以提供给多个学生。
方式:
1)student(studentId, name)
1 张三
2 李四
course(courseId,name)
1 语文
2 数学
需要搞一个 关联表
student_course(studentId, courseId)
1 1
1 2 张三选了 语文 和 数学
2 1 语文这个课程就提供给了张三和李四~
把查询和新增联合起来
把查询结果作为新增的数据~ 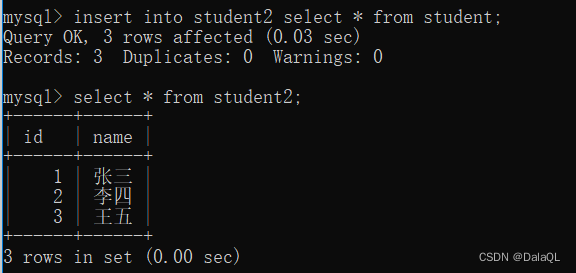
要求:查询结果得到的列数、类型需要和插入的表的列数、类型匹配。列名不一样没事。
更复杂的查询
01聚合查询
把查询过程中,表的行和行之间进行一定的运算~
select 指定的列,要么是带有聚合函数的,要么就是得指定的group by的列……
不能指定一个 非聚合 非 group by 的列
依赖聚合函数。这些是SQL提供的库函数
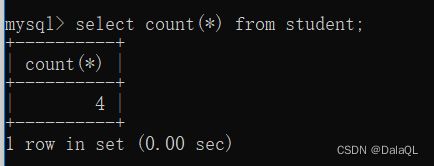
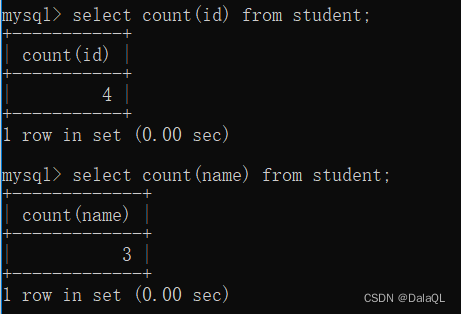
- COUNT 计数
这个操作,可以理解成,先执行select *
然后去计算select* 查询结果有多少行~
有一行名字是空
- SUM 求和
sum操作会自动跳过结果为null的行。
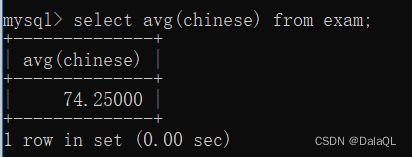
- AVG 平均数
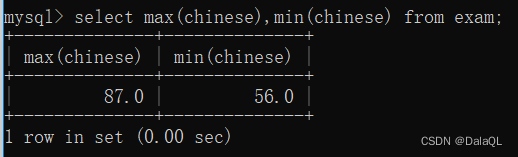
- MAX
- MIN

聚合函数还能搭配表达式使用。求总分的平均分。 
以上聚合函数默认都是针对这个表的所有类进行聚合~
有时候,还需要分组聚合(按照制定的字段,把记录分成若干组,每一组分别使用聚合函数)
员工表
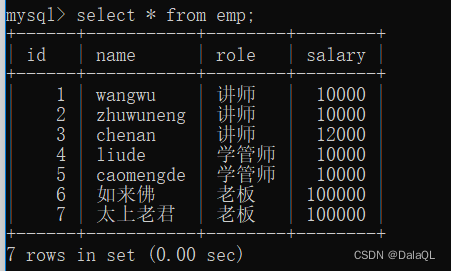
求每个岗位的平均薪资~就需要使用分组查询 group by 指定一个列,就会把列里的值,相同的分到同一个组
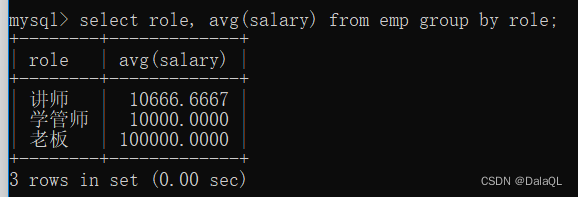
分组的时候,可以指定条件筛选~~
先搞清楚,筛选条件是分组前,还是分组后~~
1、分组前,筛选,使用where条件,求每个岗位的平均薪资,但是抛出 wangwu 同学。
group by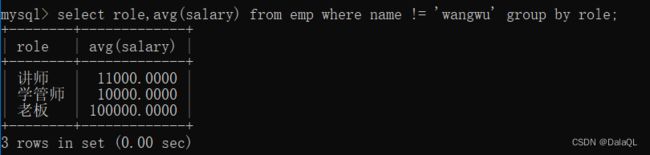
2、分组后,筛选,使用having条件~求出每个岗位的平均薪资,刨除老板~~
having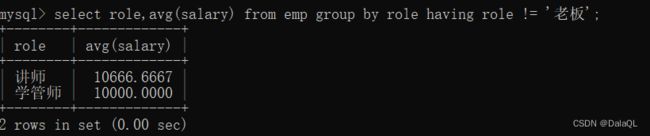
3、既抛出wangwu,有抛出老板
02联合查询
把多个表联合到一起进行查询~
笛卡尔积(一种运算),联合查询就是基于这个运算。
笛卡尔积,其实就是一种排列组合,把两张表的记录 尽可能的排列出N种情况~
班级表(classId,className)
1 2001
2 2002
学生表(studentId,name,classId)
1 张三 1
2 李四 1
3 王五 2
4 赵六 2
学生表和班级表的笛卡尔积结果
(studentId,name,classId) (classId,className)
√ 1 张三 1 1 2001
1 张三 1 2 2002
√ 2 李四 1 1 2001
2 李四 1 2 2002
3 王五 2 1 2001
√ 3 王五 2 2 2002
4 赵六 2 1 2001
√ 4 赵六 2 2 2002
有效数据:classId 相同,两个class对的上,就可以使用 where 子句的条件来描述。
去掉无效数据之后,笛卡尔积里剩余的数据,就是每个同学在哪个班级里这样的信息了。
基于 笛卡尔积 + 条件 进行查询,此时就是 联合查询 / 多表查询
select * from student,score where student.id = score.student_id;
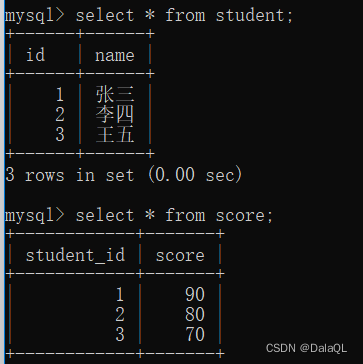
03内连接
语法:
inner join……on……
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件; select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;多表查询一般实现步骤:
1、分析清除需求种,涉及到的信息都在哪些表里~
2、针对这多个表进行笛卡尔积
3、筛选出其中有效数据(此处使用学生id作为关联条件)
4、结合需求中的条件,进一步加强条件
5、针对列进行精简
四张表 student, classes, course, score
三个实体:学生, 班级, 课程
学生和班级, 一对多关系
学生和课程, 多对多关系 score表相当于是关联表
班级和课程,没关系
1) 查询“许仙”同学的成绩
学生表和成绩表进行联合查询。
select sco.score from student stu inner join score sco on stu.id=sco.student_id and stu.name='许仙'; -- 或者 select sco.score from student stu, score sco where stu.id=sco.student_id and stu.name='许仙';2)查询所有同学的总成绩,及同学的个人信息
-- 成绩表对学生表是多对1关系,查询总成绩是根据成绩表的同学id来进行分组的 SELECT stu.sn, stu.NAME, stu.qq_mail, sum( sco.score ) FROM student stu JOIN score sco ON stu.id = sco.student_id GROUP BY sco.student_id;3)查询所有同学的成绩,及同学的个人信息
-- 查询出来的都是有成绩的同学,“老外学中文”同学 没有显示 select * from student stu join score sco on stu.id=sco.student_id; -- 学生表、成绩表、课程表3张表关联查询 SELECT stu.id, stu.sn, stu.NAME, stu.qq_mail, sco.score, sco.course_id, cou.NAME FROM student stu JOIN score sco ON stu.id = sco.student_id JOIN course cou ON sco.course_id = cou.id ORDER BY stu.id;
04外连接
内连接和外连接都是进行笛卡尔积。但是细节上有所差别~
内连接:
外连接:加 left / right 关键字
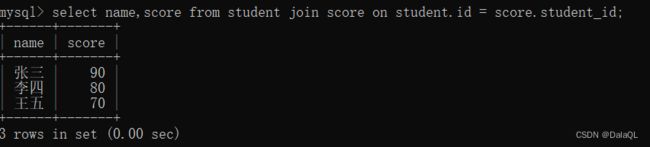
select name,score from student left join score on student.id = score.student_id;
当前情况下,这两个表的数据是一一对应的~
第一个表的每个记录,在第二个表里都有体现。第二个表里的每个记录,在第一个表里也都有体现
此时内连接和外连接,查询结果相同!
左外连接:就是以左侧的表为准,左侧表中的所有数据都能体现出来
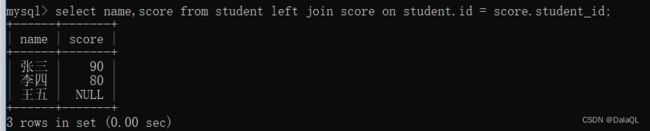
右外链接,就是以右侧表为准。右侧表中的所有数据都体现出来。

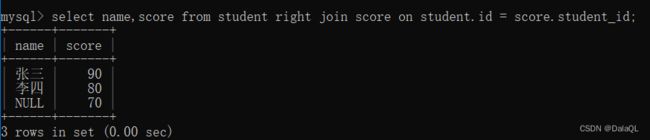
05自连接
这个操作本质上是把“行”转成“列”
SQL中进行条件查询,都是指定 某一列 / 多个列 之间进行关系运算~
无法行和行之间关系运算~
有点时候为了实现这种行之间的比较,就需要把行关系转成列关系~
子连接需要指定表的别名。
SQL的逻辑表达能力是有限。很多时候不是做了,而是代码大。
相比之下,使用Java这样的语言来描述复杂逻辑是更好的选择 !!
06子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询(套娃~~把多个查询语句合并一个)
子查询一旦嵌套的层次多了,对于代码的可读性是毁灭性的打击!
- 单行子查询:返回一行记录的子查询
查询与“不想毕业” 同学的同班同学:
select * from student where classes_id=(select classes_id from student where name='不想毕业');
- 多行子查询:返回多行记录的子查询
案例:查询“语文”或“英文”课程的成绩信息
1、[NOT] IN关键字
-- 使用IN select * from score where course_id in (select id from course where name = '语文' or name = '英文'); --使用 NOT IN select * from score where course_id not in (select id from course where name != '语文' and name != '英文');可以使用多列包含:
-- 插入重复的分数:score, student_id, course_id列重复 insert into score(score, student_id, course_id) values -- 黑旋风李逵 (70.5, 1, 1), (98.5, 1 3), --菩提老祖 (60, 2, 1); --查询重复的分数 select * from score where (score, student_id, course_id) in (select score, student_id, course_id from score group by score, atudent_id, course_id having count(0) > 1);2、[NOT]EXISTS关键字
-- 使用EXISTS select * from score sco where exists (select sco.id from course cou where(name = '语文' or name='英文') and cou.id = sco.course_id); --使用 NOT EXISTS select * from score sco where not exists (select sco.id from course cou where(name != '语文' and name != '英语') and (cou.id = sco.course_id));
- 在from子句中使用子查询:子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
查询所有比“中文系2019级3班”的平均分高的成绩信息:
-- 获取“中文系2019级3班”的平均分,将其看作临时表 select avg(sco.score) score from score sco join student stu on sco.student_id = stu.id join classes cls on stu.classes_id = cls.id where cls.name = "中文系2019级3班";查询成绩表中,比以上临时表平均分高的成绩:
select * from score sco, (select avg(sco.score) score from score sco join student stu on sco.student_id = stu.id join classes cls on stu.classes_id = cls.id where cls.name = '中文系2019班3级' ) tmp where sco.score > tmp.score;查询成绩表中,比以上临时表平均分高的成绩:
select * from score sco, ( select avg(sco.score) score from score sco join student stu on sco.student_id = stu.id join classes cls on stu.classes_id = cls.id where cls.name = '中文系2019级3班' ) tmp where sco.score > tmp.score;
07合并查询
在实际应用中,为了合并多个select的执行结构,可以使用集合操作符union,union all。使用union 和 union all时,前后查询的结果集中,字段需要一致。
- union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
案例:查询id小于3,或者名字为‘英文’的课程:
select * from course where id < 3 union select * from course where name = '英文'; --或者使用or 来实现 select * from course where id<3 or name='英文';or 只能针对一个表,union可以把多个表的查询结果合并。(要求多个结果列得对应)
- union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
案例:查询id小于3,或者名字为‘Java’的课程
-- 可以看到结果集中出现重复数据Java select * from course where id < 3 union all select * from course where name = '英文';
索引
索引 index = 》 目录
索引存在的意义就是为了加速查找速度!(省略了遍历的过程)
但是付出了一定的代价 :
- 需要付出额外的空间代价来保存索引数据
- 索引可能会拖慢新增、删除、修改的速度
主键 会自带索引~ unique也会自带~
整体来说,还是认为索引是利大于弊的~
实际开发中,查询场景一般要比增删改频率高很多~
查看索引
show index from 表名;创建索引
create index 索引名 on 表名(列名);
把表中的内容,根据name搞了一份目录出来~
创建索引操作,可能很危险!
如果表里的数据很大,这个建立索引的开销也会很大!!
好的做法:是创建表之初,就把索引设定好~
如果表里已经有很多数据,索引就别动了~
删除索引
drop index 索引名 on 表名;

索引的数据结构
B+树:为了数据库索引,量身定做的数据结构
- 二叉搜索树 : 如果元素高了,树的的高度就会比较高,树的高度 相当于 比较的次数。对于数据库来说。则是IO访问次数。数据库里的数据在硬盘上。
- 哈希表:虽然查询的快,但是不能支持范围查询,不能支持模糊匹配~
- B+树:
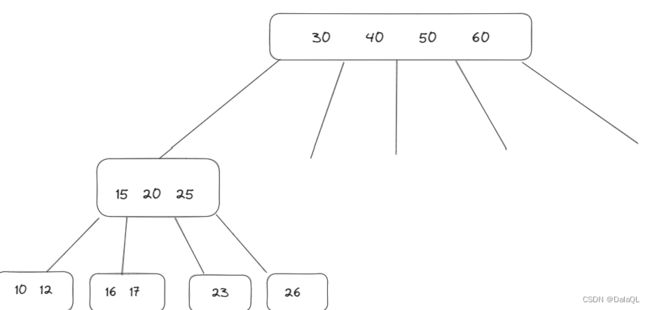
- 当前一个节点保存更多的key,最终树的高度是相对更矮的。查询的时候减少了 IO 访问次数(和 B树 一样的)
- 所有的查询都会落到叶子节点上(查询任何一个数据,经过IO的访问次数是一样的)这个稳定是很关键的~稳定能够让程序员对于程序的执行效率有一个更准确的评估~
- B+树的所有叶子节点,构成链表,此时比较方便查询~~(比如查询学号>5并且<11的同学~~只需要先找到5所在的位置,再找到11所在位置,从5沿着链表访问到11,中间结果即为所求)
- 由于数据都在叶子节点上,非叶子节点,只存储key,导致非叶子节点,占用空间是比较小的~~这些非叶子节点就可能在内存中缓存(或者是缓存的一部分)
补充:
B树(B-树)‘-’是连接符,不是减号,不能念成B-树
B 树可以认为是一个N叉搜索树
树的度:所有节点的度的最大值~
节点的度是有几个孩子~
当节点的子树多了,节点上保存的 key 多了,意味着在同样 key 的个数的前提下,B树的高度就要比 二叉搜索树 低很多!!
B+树,在B树的基础上有做出了改进
整个树的所有数据都是包含在 叶子节点中 的!!
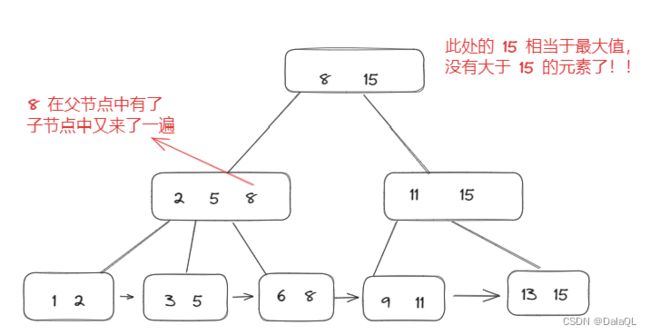
上述这个结构是默认id是表的主键了。如果这个表里有多个索引呢?
针对 id 有主键索引
针对 name 又有一个索引~
- 表的数据还是按照 id 为主键,构建出B+树,通过叶子节点组织所有的数据行~
- 其次,针对name这一列会构建另一个B+树,但是这个B+树的叶子节点就不再存储这一行的完整数据,而是存主键 id 是啥~
- 此时,如果你根据name来查询,查到叶子节点得到的只是 主键 id,还需要再通过主键 id 去主键的 B+ 树里在查一次~~(查两次B+树)
上述过程称为“回表”,这个过程,都是mysql自动完成的,用户感知不到
特点:
- 一个节点,可以存储N个key,N个key划分出了N个区间(而不是N+1个区间)
- 每个节点中key的值,都会在子节点中也存在(同时该key是子节点的最大值)
- B+树的叶子节点,是首尾相连,类似一个链表~
- 由于叶子节点,是完整的数据集合,只在叶子节点这里存储数据表的每一行的数据~~而非叶子节点,只存key值本身即可~
事务
比如经典场景:转账~ 淘宝买东西,下单
account(id, balance)
1 1000
2 0
1给2转账 500
1)update account set balance = balance-500 where id =1;
2)update account set balance = balance+500 where id = 2;
假设,在执行转账过程中,执行完 1 之后,数据库崩溃了/主机宕机
此时这个转账就僵硬了!
1 的钱扣了,但是2 的钱没到账!
事务就是为了解决上述问题~~
事务的本质就是把多个 sql 语句给打包成一个整体(原子性atom),要么全部执行成功,要么就一个都不执行~~而不会出现“执行一半”这样的中间状态!
(不是真的没执行,而是看起来好像没执行一样,执行了,执行一般出错了,出错之后,选择恢复现场,把数据还原成未执行之前的状态了~) 这个恢复数据的操作,称为“回滚”(rollback)
此处是需要额外的部分来记录事务中的操作步骤。(数据库里专门有个用来记录事务的日志)
正因为如此,使用事务的时候,执行sql的开销是更大的,效率是更低的~
start transaction;
-- 阿里巴巴账号减少2000
update account set money = money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
uodate account set money = money+2000 where name = '四十大盗'
commit;事务四个特性:
- 原子性:(最核心的特性)初心~
- 一致性:事务执行前后,数据得是靠谱的~
- 持久性 :事务修改的内容是写在硬盘上的,持久存在的,重启也不丢失
- 隔离性:这个隔离性是为了解决“并发”执行事务,引起的问题~
并发事务:一个餐馆(服务器),同一时刻要给多个顾客(客户端)提供服务
此时,服务器同时处理多个客户端的请求,就称为“并发”。
引起问题:如果并发的这些事务,是修改不同的表/不同的数据,没啥事~~
如果修改的是同一个表/同一个数据~~可能会带来一系列问题!
比如多个客户端一起尝试对同一个账户进行转账操作,此时就可能会把这个数据给搞乱了~
事务的隔离性,存在的意义就是为了 在数据库并发处理事务的时候不会有问题(即使有问题,问题也不大)
并发事务可能产生的问题
- 脏读问题
eg:我写代码的时候,同学路过,看了眼我的代码,他走后,我可能把代码修改了。
考试的时候,有的同学瞄旁边同学的卷子~~有的人就故意使坏,故意写个错误答案,让别人抄走,然后自己再偷偷改过来。
一个事务A正在对数据进行修改的过程,还没提交之前,另外一个事务B,也对同一个数据进行了读取。此时B的读数据就成为“脏读”,读到的数据也就成为“脏数据”。因为A数据很可能把数据给改了。
解决:引入了“写操作加锁”这样的机制。
就比如和别人商量好,我写代码的过程中,你别来看,等我改完,提交到码云上,你再通过我的码云来看。
当我写到时候,同学没法读,意味着我的“写操作”和同学的“读操作”不能并发了~
这个给写加锁操作,就降低了并发程度(降低了效率),提高了隔离性(提高了数据的准确性)
- 不可重复读
eg:还是写代码,同学想看。约定好,我写的时候,不许看,等我提交了,再通过码云来看(约定好写加锁了)
我写代码,提交了版本1,此时就有同学开始都这个代码了~于是我又打开代码,继续修改代码~~然后又提交版本2.
这个同学开始读的过程中,读到的是版本1 的代码,读着读着,我提交了版本2,此时这个同学读的代码,刷的一下变样了!
这个问题,叫做“不可重复读”
事务1 已经提交了数据,此时事务2 开始去读取数据。在读取过程中,事务 3又提交了新的数据。此时意味着同一个事务2 之内,多次读数据,读出来的结果是不相同的~(预期是一个事务中,多次读取结果的一样)
解决:引入了“读操作加锁”这样的机制
同学发现这个问题,就知道是在他读到过程中,我又改代码了,于是来找我,和我约定~他读代码的时候,我也不能修改!
通过这个读加锁,又进一步的降低了事务的并发处理能力(处理效率也降低),提高了事务的隔离性(数据的准确性)
- 幻读
eg:由于约定了读加锁,同学读的时候,我不能该代码~我干等有点无聊,所以我想办法,同学读student.java我就创建一个teacher.java。这样的情况,大多数情况下都没事,少数情况下,个别同学发现了,读代码读着读着突然冒出个Teacher.java,有点同学就巨大接受不了了~~
在读解锁和写加锁的前提下,一个事务两次读取同一个数据,发现读取的数据值是一样的,但是结果集不一样~(Student.java 代码内容不变,但是第一次看到是只有student.java这个文件,第二次看到的是student.java和teacher.java了)这就叫做幻读
解决:数据库使用“串行化”这样的方式来解决幻读。彻底放弃并发处理事务,一个接一个的串行的处理事务。这样做,并发程度是最低的(效率最低的),隔离性是最高的(准确性也是最高的)
相当于同学要求我在她们读我的代码的时候,我不要摸电脑,必须强制摸鱼~
四种隔离级别
对应上述问题,Mysql提供了4种隔离级别,就对应上面的几个情况~
- read uncommitted 没有进行任何锁限制,并发最高(效率最高),隔离性最低(准确性最低)
- read committed 给写加锁,并发程度降低,隔离性提高了
- repeatable read 给写和读都加锁,并发程度又降低,隔离性又提高了
- serializable 串行化,并发程度最低,隔离性最高
以上四种隔离级别可以通过修改mysql的配置文件,来设置当前mysql工作在哪种状态下~
隔离级别的选择:
eg:转账的时候,一分钱都不能差,哪怕慢点,也得转对!!
准确性要拉满,效率不关键~~
抖音,点赞,一个视频有多少赞,要求快,赞的数量差个十个八个,都没事~追求效率,准确性都不关键~