【Hive】——函数案例
1 Hive 多字节分隔符处理
1.1 默认规则
Hive默认序列化类是LazySimpleSerDe,其只支持使用单字节分隔符(char)来加载文本数据,例如逗号、制表符、空格等等,默认的分隔符为”\001”。根据不同文件的不同分隔符,我们可以通过在创建表时使用 row format delimited 来指定文件中的分割符,确保正确将表中的每一列与文件中的每一列实现一一对应的关系。
1.2 问题
- 每一行数据的分隔符是多字节分隔符,例如:”||”、“–”等
- 数据的字段中包含了分隔符
1.3 方案一:替换分隔符(不推荐)
直接解决数据问题,而不是解决了单字节分隔符问题,不推荐

1.4 方案二:RegexSerDe正则加载(推荐)
• 除了使用最多的LazySimpleSerDe,Hive该内置了很多SerDe类;
• 官网地址:https://cwiki.apache.org/confluence/display/Hive/SerDe
• 多种SerDe用于解析和加载不同类型的数据文件,常用的有ORCSerDe 、RegexSerDe、JsonSerDe等。
• RegexSerDe用来加载特殊数据的问题,使用正则匹配来加载数据。
• 根据正则表达式匹配每一列数据。
• https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-ApacheWeblogData

create table singer(id string,--歌手id
name string,--歌手名称
country string,--国家
province string,--省份
gender string,--性别
works string)--作品
--指定使用RegexSerde加载数据
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES ("input.regex" = "([0-9]*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)");
create table apachelog(
ip string, --IP地址
stime string, --时间
mothed string, --请求方式
url string, --请求地址
policy string, --请求协议
stat string, --请求状态
body string --字节大小
)
--指定使用RegexSerde加载数据
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
--指定正则表达式
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^}]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([^ ]*)"
) stored as textfile ;
2 URL解析函数
2.1 URL基本组成
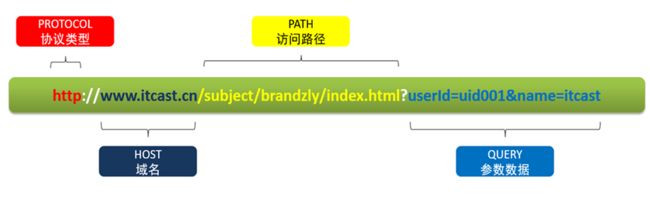
2.2 parse_url函数
2.2.1 功能
parse_url函数是Hive中提供的最基本的url解析函数,可以根据指定的参数,从URL解析出对应的参数值进行返回,函数为普通的一对一函数类型。
2.2.2语法
parse_url(url, partToExtract[, key]) - extracts a part from a URL
Parts: HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO key
2.2.3 案例
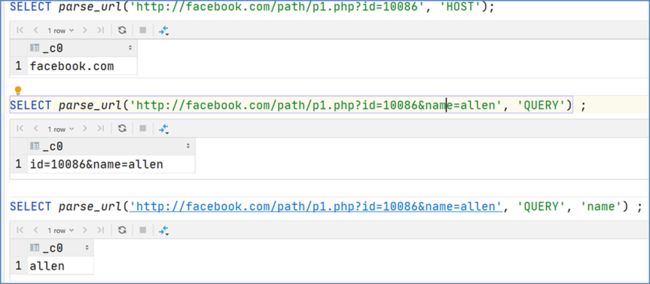
SELECT parse_url('http://facebook.com/path/p1.php?id=10086', 'HOST');
SELECT parse_url('http://facebook.com/path/p1.php?id=10086&name=allen', 'QUERY') ;
SELECT parse_url('http://facebook.com/path/p1.php?id=10086&name=allen', 'QUERY', 'name') ;
select
id,
parse_url(url,"HOST") as host,
parse_url(url,"PATH") as path,
parse_url(url,"QUERY") as query
from
tb_url;

2.3 parse_url_tuple
2.3.1 功能
parse_url_tuple函数是Hive中提供的基于parse_url的url解析函数,可以通过一次指定多个参数,从URL解析出多个参数的值进行返回多列,函数为特殊的一对多函数类型,即通常所说的UDTF函数类型。
2.3.2语法
parse_url_tuple(url, partname1, partname2, ..., partnameN) - extracts N (N>=1) parts from a URL.
It takes a URL and one or multiple partnames, and returns a tuple.
2.3.3 案例
--建表
create table tb_url(
id int,
url string
)row format delimited
fields terminated by '\t';
--加载数据
load data local inpath '/root/hivedata/url.txt' into table tb_url;
select * from tb_url;
select parse_url_tuple(url,"HOST","PATH") as (host,path) from tb_url;
select parse_url_tuple(url,"PROTOCOL","HOST","PATH") as (protocol,host,path) from tb_url;
select parse_url_tuple(url,"HOST","PATH","QUERY") as (host,path,query) from tb_url;

3 UDTF函数问题
Hive中的一对多的UDTF函数可以实现高效的数据转换,但是也存在着一些使用中的问题,UDTF函数对于很多场景下有使用限制,例如:select时不能包含其他字段、不能嵌套调用、不能与group by等放在一起调用等等。
UDTF函数的调用方式,主要有以下两种方式:
3.1 直接在select后单独使用
--parse_url_tuple
select
id,
parse_url_tuple(url,"HOST","PATH","QUERY") as (host,path,query)
from tb_url;
3.2 与Lateral View放在一起使用
--单个lateral view使用
select
a.id as id,
b.host as host,
b.path as path,
b.query as query
from tb_url a lateral view parse_url_tuple(url,"HOST","PATH","QUERY") b as host,path,query;
--多个lateral view
select
a.id as id,
b.host as host,
b.path as path,
c.protocol as protocol,
c.query as query
from tb_url a
lateral view parse_url_tuple(url,"HOST","PATH") b as host,path
lateral view parse_url_tuple(url,"PROTOCOL","QUERY") c as protocol,query;
4 Lateral View
如果UDTF不产生数据时,这时侧视图与原表关联的结果将为空
---Outer Lateral View
--如果UDTF不产生数据时,这时侧视图与原表关联的结果将为空
select
id,
url,
col1
from tb_url
lateral view explode(array()) et as col1;
如果加上outer关键字以后,就会保留原表数据,类似于outer join
--如果加上outer关键字以后,就会保留原表数据,类似于outer join
select
id,
url,
col1
from tb_url
lateral view outer explode(array()) et as col1;

5 行列转换
5.1 多行转多列(case when)
case when 函数:用于实现对数据的判断,根据条件,不同的情况返回不同的结果,类似于Java中的switch case 功能
CASE
WHEN 条件1 THEN VALUE1
……
WHEN 条件N THEN VALUEN
ELSE 默认值 END
CASE 列
WHEN V1 THEN VALUE1
……
WHEN VN THEN VALUEN
ELSE 默认值 END
5.2 多行转单列(concat_ws、collect_list、collect_set)
- concat_ws 函数: 用于实现字符串拼接,可以指定分隔符
特点:任意一个元素不为null,结果就不为null
concat_ws(SplitChar,element1,element2……)
select concat_ws("-","itcast","And","heima");
+-------------------+
| itcast-And-heima |
+-------------------+
select concat_ws("-","itcast","And",null);
±------------+
| itcast-And |
±------------+
2. collect_list 函数: 用于将一列中的多行合并为一行,不进行去重
collect_list(colName)
select collect_list(col1) from row2col1;
±---------------------------+
| [“a”,“a”,“a”,“b”,“b”,“b”] |
±---------------------------+
2. collect_set 函数: 用于将一列中的多行合并为一行,并进行去重
collect_set(colName)
select collect_set(col1) from row2col1;
±-----------+
| [“b”,“a”] |
±-----------+
5.3 多列转多行(union、union all)
5.4 单列转多行(explode)
6 json处理
6.1 概述
JSON数据格式是数据存储及数据处理中最常见的结构化数据格式之一,很多场景下公司都会将数据以JSON格式存储在HDFS中,当构建数据仓库时,需要对JSON格式的数据进行处理和分析,那么就需要在Hive中对JSON格式的数据进行解析读取。
6.2 JSON 函数处理
适用于将数据作为一个JSON字符串加载到表中,再通过JSON解析函数对JSON字符串进行解析
6.2.1 get_json_object
- 功能: 用于解析JSON字符串,可以从JSON字符串中返回指定的某个对象列的值
- 语法: get_json_object(json_txt, path) - Extract a json object from path
- json_txt:指定要解析的JSON字符串,path:指定要返回的字段,通过$.columnName的方式来指定path
- 特点:每次只能返回JSON对象中一列的值

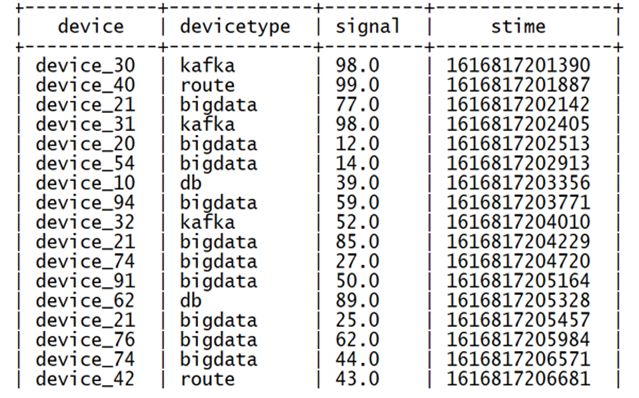
select
--获取设备名称
get_json_object(json,"$.device") as device,
--获取设备类型
get_json_object(json,"$.deviceType") as deviceType,
--获取设备信号强度
get_json_object(json,"$.signal") as signal,
--获取时间
get_json_object(json,"$.time") as stime
from tb_json_test1;
6.2.2 json_tuple
- 功能:用于实现JSON字符串的解析,可以通过指定多个参数来解析JSON返回多列的值
- 语法:json_tuple(jsonStr, p1, p2, …, pn) like get_json_object, but it takes multiple names and return a tuple
- 参数:jsonStr:指定要解析的JSON字符串;p1:指定要返回的第1个字段;pn:指定要返回的第n个字段
- 特点:功能类似于get_json_object,但是可以调用一次返回多列的值,属于UDTF类型函数,一般搭配lateral view使用,返回的每一列都是字符串类型
--json_tuple
--单独使用
select
--解析所有字段
json_tuple(json,"device","deviceType","signal","time") as (device,deviceType,signal,stime)
from tb_json_test1;
--搭配侧视图使用
select
json,device,deviceType,signal,stime
from tb_json_test1
lateral view json_tuple(json,"device","deviceType","signal","time") b
as device,deviceType,signal,stime;
6.3 JSONSerde
Hive中为了简化对于JSON文件的处理,内置了一种专门用于解析JSON文件的Serde解析器,在创建表时,只要指定使用JSONSerde解析表的文件,就会自动将JSON文件中的每一列进行解析。

--JsonSerDe
--创建表
create table tb_json_test2 (
device string,
deviceType string,
signal double,
`time` string
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
load data local inpath '/root/hivedata/device.json' into table tb_json_test2;