pytorch中池化函数详解
1 池化概述
1.1 什么是池化
池化层是卷积神经网络中常用的一个组件,池化层经常用在卷积层后边,通过池化来降低卷积层输出的特征向量,避免出现过拟合的情况。池化的基本思想就是对不同位置的特征进行聚合统计。池化层主要是模仿人的视觉系统对数据进行降维,用更高层次的特征表示图像。池化层一般没有参数,所以反向传播的时候,只需对输入参数求导,不需要进行权值更新。
池化操作的基本思想是将特征图划分为若干个子区域(一般为矩形),并对每个子区域进行统计汇总。池化操作的方式可以有很多种,比如最大池化(Max Pooling)、平均池化(Average Pooling)等。其中,最大池化操作会选取每个子区域内的最大值作为输出,而平均池化操作则会计算每个子区域内的平均值作为输出。
1.2 池化的作用
理论上来说,网络可以在不对原始输入图像执行降采样的操作,通过堆叠多个的卷积层来构建深度神经网络,如此一来便可以在保留更多空间细节信息的同时提取到更具有判别力的抽象特征。然而,考虑到计算机的算力瓶颈,通常都会引入池化层,来进一步地降低网络整体的计算代价,这是引入池化层最根本的目的。
池化层大大降低了网络模型参数和计算成本,也在一定程度上降低了网络过拟合的风险。概括来说,池化层主要有以下五点作用:
-
增大网络感受野
-
抑制噪声,降低信息冗余
-
降低模型计算量,降低网络优化难度,防止网络过拟合
-
使模型对输入图像中的特征位置变化更加鲁棒
1.3 池化核大小
池化窗口的大小,在PyTorch里池化核大小可以是一个整数或者一个元组,例如 kernel_size=2 或者 kernel_size=(2, 3)。
- 如果是一个整数,则表示高和宽方向上的池化窗口大小相同;
- 如果是一个元组,则第一个元素表示高方向上的池化窗口大小,第二个元素表示宽方向上的池化窗口大小。
1.4 步幅大小
用于指定池化窗口在高和宽方向上的步幅大小,可以是一个整数或者一个元组,例如 stride=2 或者 stride=(2, 3)。
- 如果是一个整数,则表示高和宽方向上的步幅大小相同;
- 如果是一个元组,则第一个元素表示高方向上的步幅大小,第二个元素表示宽方向上的步幅大小。
1.5 填充
池化层的填充(padding)可以控制池化操作在特征图边缘的行为,使得池化后的输出特征图与输入特征图大小相同或相近。
在池化操作时,如果输入特征图的尺寸不能被池化窗口的大小整除,那么最后一列或者最后一行的部分像素就无法被包含在池化窗口中进行池化,因此池化后的输出特征图尺寸会减小。
通过在输入特征图的边缘添加填充,可以使得池化操作在边缘像素处进行池化,避免了信息的丢失,并且保持了输出特征图的大小与输入特征图相同或相近。同时,填充也可以增加模型的稳定性,减少过拟合的风险。
需要注意的是,池化层的填充和卷积层的填充有所不同:
- 池化层的填充通常是指在输入特征图的边缘添加0值像素;
- 卷积层的填充是指在输入特征图的边缘添加0值像素或者复制边缘像素。
PyTorch里的填充大小可以是一个整数或者一个元组,例如 padding=1 或者 padding=(1, 2)。
- 如果是一个整数,则表示在高和宽方向上的填充大小相同;
- 如果是一个元组,则第一个元素表示高方向上的填充大小,第二个元素表示宽方向上的填充大小。默认为 0,表示不进行填充。
2 pytorch中的池化函数
PyTorch 提供了多种池化函数,用于对输入数据进行不同类型的池化操作。
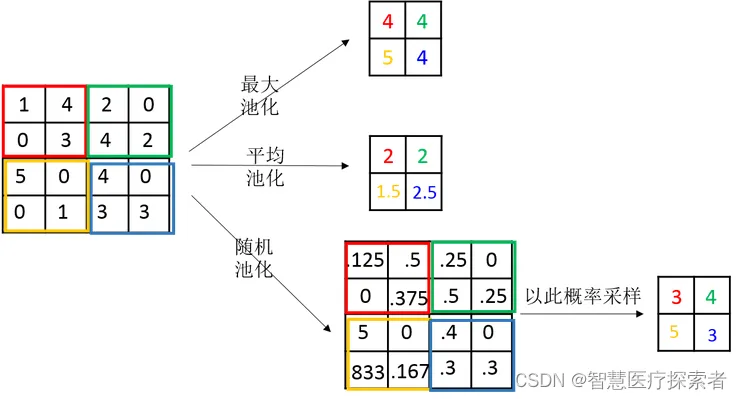
以下是一些常用的 PyTorch 池化函数:
2.1 平均池化(Average Pooling):
-
nn.AvgPool1d: 一维平均池化。
-
nn.AvgPool2d: 二维平均池化。
-
nn.AvgPool3d: 三维平均池化。
2.2 最大池化(Max Pooling):
-
nn.MaxPool1d: 一维最大池化。
-
nn.MaxPool2d: 二维最大池化。
-
nn.MaxPool3d: 三维最大池化。
2.3 全局池化(Global Pooling):
-
nn.AdaptiveAvgPool1d: 自适应一维平均池化,用于将整个输入降维为指定大小。
-
nn.AdaptiveAvgPool2d: 自适应二维平均池化,用于将整个输入降维为指定大小。
-
nn.AdaptiveAvgPool3d: 自适应三维平均池化,用于将整个输入降维为指定大小。
-
nn.AdaptiveMaxPool1d: 自适应一维最大池化,用于将整个输入降维为指定大小。
-
nn.AdaptiveMaxPool2d: 自适应二维最大池化,用于将整个输入降维为指定大小。
-
nn.AdaptiveMaxPool3d: 自适应三维最大池化,用于将整个输入降维为指定大小。
这些池化函数允许你对不同维度的输入数据进行平均池化或最大池化,并且有自适应版本,可以自动调整输入大小以满足指定的输出大小。选择适当的池化函数取决于你的应用和输入数据的维度。
3 池化层的pytorch实现
3.1 平均池化
3.1.1 一维平均池化(nn.AvgPool1d)
不同池化函数的构造方式在 PyTorch 中基本相似,它们都是基于 nn.Module 类的子类,并具有一些特定的参数。这些池化函数的构造函数通常需要指定池化核的大小 (kernel_size),步幅 (stride) 和填充 (padding),以控制池化操作的行为。对于自适应池化,你需要指定目标输出大小 (output_size),而不需要手动设置核大小和步幅。
函数构成:
avg_pool = nn.AvgPool1d(kernel_size, stride, padding)示例:
import torch
import torch.nn as nn
# 创建一个一维输入张量
x = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0])
# 创建一个一维平均池化层,指定池化核大小为2
avg_pool = nn.AvgPool1d(kernel_size=2)
# 对输入进行一维平均池化
output = avg_pool(x.unsqueeze(0).unsqueeze(0))
# 输出平均池化后的结果
print(output) 3.1.2 二维平均池化(nn.AvgPool2d)
函数构成:
avg_pool = nn.AvgPool2d(kernel_size, stride, padding)示例:
import torch
import torch.nn as nn
# 创建一个二维输入张量(4x4的图像)
x = torch.tensor([[1.0, 2.0, 3.0, 4.0],
[5.0, 6.0, 7.0, 8.0],
[9.0, 10.0, 11.0, 12.0],
[13.0, 14.0, 15.0, 16.0]], dtype=torch.float32)
# 创建一个二维平均池化层,指定池化核大小为2x2
avg_pool = nn.AvgPool2d(kernel_size=2)
# 对输入进行二维平均池化
output = avg_pool(x.unsqueeze(0).unsqueeze(0))
# 输出平均池化后的结果
print(output) 在上面的示例中,我们使用了一个4x4的二维输入张量,并创建了一个2x2的池化核进行平均池化。
3.1.3 三维平均池化(nn.AvgPool3d)
函数构成:
avg_pool = nn.AvgPool3d(kernel_size, stride, padding)示例:
import torch
import torch.nn as nn
# 创建一个三维输入张量(4x4x4的数据)
x = torch.randn(1, 1, 4, 4, 4) # 随机生成一个大小为4x4x4的三维张量
# 创建一个三维平均池化层,指定池化核大小为2x2x2
avg_pool = nn.AvgPool3d(kernel_size=2)
# 对输入进行三维平均池化
output = avg_pool(x)
print(output) # 输出平均池化后的结果在上面的示例中,我们使用了一个随机生成的4x4x4的三维输入张量,并创建了一个2x2x2的池化核进行平均池化。
这些示例演示了如何使用PyTorch的nn.AvgPool2d和nn.AvgPool3d函数对二维和三维数据进行平均池化操作。你可以根据你的需求自定义输入数据和池化核的大小。
3.2 最大池化
3.2.1 一维最大池化(nn.MaxPool1d)
函数构成:
max_pool = nn.MaxPool1d(kernel_size, stride, padding)示例:
import torch
import torch.nn as nn
# 创建一个一维输入张量
x = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0])
# 创建一个一维最大池化层,指定池化核大小为2
max_pool = nn.MaxPool1d(kernel_size=2)
# 对输入进行一维最大池化
output = max_pool(x.unsqueeze(0).unsqueeze(0))
print(output) # 输出最大池化后的结果3.2.2 二维最大池化(nn.MaxPool2d)
函数构成:
max_pool = nn.MaxPool2d(kernel_size, stride, padding)示例:
import torch
import torch.nn as nn
# 创建一个二维输入张量(3x3的图像)
x = torch.tensor([[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0]])
# 创建一个二维最大池化层,指定池化核大小为2x2
max_pool = nn.MaxPool2d(kernel_size=2)
# 对输入进行二维最大池化
output = max_pool(x.unsqueeze(0).unsqueeze(0))
print(output) # 输出最大池化后的结果3.2.3 三维最大池化(nn.MaxPool3d)
函数构成:
max_pool = nn.MaxPool3d(kernel_size, stride, padding)示例:
import torch
import torch.nn as nn
# 创建一个随机的三维输入张量(2x2x2x2的数据)
x = torch.randn(1, 1, 2, 2, 2) # 随机生成一个大小为2x2x2x2的三维张量
# 创建一个三维最大池化层,指定池化核大小为2x2x2
max_pool = nn.MaxPool3d(kernel_size=2)
# 对输入进行三维最大池化
output = max_pool(x)
print(output) # 输出最大池化后的结果在这个示例中,我们创建了一个大小为 2x2x2x2 的随机三维输入张量 x,然后使用 nn.MaxPool3d 创建了一个三维最大池化层,指定了池化核大小为 2x2x2。最后,我们对输入张量进行了三维最大池化操作,并打印了池化后的结果。
这个示例演示了如何使用 PyTorch 进行三维最大池化操作,你可以根据你的需求自定义输入数据和池化核的大小。
以上示例展示了各种池化函数的用法,你可以根据需要选择适合你的任务和输入数据维度的池化函数,并调整参数以满足具体要求。
3.3 全局池化
以下是自适应一维、二维和三维平均池化的示例:
3.3.1 自适应一维平均池化(nn.AdaptiveAvgPool1d)
函数构成:
adaptive_avg_pool = nn.AdaptiveAvgPool1d(output_size)示例:
import torch
import torch.nn as nn
# 创建一个一维输入张量
x = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0])
# 创建一个自适应一维平均池化层,指定目标输出大小为3
adaptive_avg_pool = nn.AdaptiveAvgPool1d(output_size=3)
# 对输入进行自适应一维平均池化
output = adaptive_avg_pool(x.unsqueeze(0).unsqueeze(0))
print(output) # 输出自适应平均池化后的结果在上面的示例中,我们使用了一个自适应一维平均池化层,指定了目标输出大小为 3。
3.3.2 自适应二维平均池化(nn.AdaptiveAvgPool2d)
函数构成:
adaptive_avg_pool = nn.AdaptiveAvgPool2d(output_size)示例:
import torch
import torch.nn as nn
# 创建一个二维输入张量(4x4的图像)
x = torch.tensor([[1.0, 2.0, 3.0, 4.0],
[5.0, 6.0, 7.0, 8.0],
[9.0, 10.0, 11.0, 12.0],
[13.0, 14.0, 15.0, 16.0]])
# 创建一个自适应二维平均池化层,指定目标输出大小为 (2, 2)
adaptive_avg_pool = nn.AdaptiveAvgPool2d(output_size=(2, 2))
# 对输入进行自适应二维平均池化
output = adaptive_avg_pool(x.unsqueeze(0).unsqueeze(0))
print(output) # 输出自适应平均池化后的结果在上面的示例中,我们使用了一个自适应二维平均池化层,指定了目标输出大小为 (2, 2)。
3.3.3 自适应三维平均池化(nn.AdaptiveAvgPool3d)
函数构成:
adaptive_avg_pool = nn.AdaptiveAvgPool3d(output_size)示例:
import torch
import torch.nn as nn
# 创建一个三维输入张量(4x4x4的数据)
x = torch.randn(1, 1, 4, 4, 4) # 随机生成一个大小为4x4x4的三维张量
# 创建一个自适应三维平均池化层,指定目标输出大小为 (2, 2, 2)
adaptive_avg_pool = nn.AdaptiveAvgPool3d(output_size=(2, 2, 2))
# 对输入进行自适应三维平均池化
output = adaptive_avg_pool(x)
print(output) # 输出自适应平均池化后的结果在上面的示例中,我们使用了一个自适应三维平均池化层,指定了目标输出大小为 (2, 2, 2)。
这些示例演示了如何使用 PyTorch 的 nn.AdaptiveAvgPool1d、nn.AdaptiveAvgPool2d 和 nn.AdaptiveAvgPool3d 函数对一维、二维和三维数据进行自适应平均池化操作,我们可以根据需求自定义输入数据和目标输出大小。
以下是分别使用自适应一维、二维和三维最大池化的示例:
3.3.4 自适应一维最大池化(AdaptiveMaxPool1d)
函数构成:
adaptive_max_pool = nn.AdaptiveMaxPool1d(output_size)这些函数构成中,output_size 是一个元组,用于指定目标输出的大小,这将决定池化窗口的大小。自适应池化会根据输出大小自动调整池化窗口,以使输出尺寸与指定的 output_size 匹配。这使得池化操作能够适应不同输入数据的尺寸,而不需要显式指定池化窗口的大小。
示例:
import torch
import torch.nn as nn
# 创建一个一维输入张量(长度为 8)
x = torch.randn(1, 1, 8) # 随机生成一个长度为 8 的一维张量
# 创建一个自适应一维最大池化层,指定目标输出大小为 4
adaptive_max_pool = nn.AdaptiveMaxPool1d(output_size=4)
# 对输入进行自适应一维最大池化
output = adaptive_max_pool(x)
print(output) # 输出自适应最大池化后的结果3.3.5 自适应二维最大池化(AdaptiveMaxPool2d)
函数构成:
adaptive_max_pool = nn.AdaptiveMaxPool2d(output_size)示例:
import torch
import torch.nn as nn
# 创建一个二维输入张量(4x4的数据)
x = torch.randn(1, 1, 4, 4) # 随机生成一个大小为 4x4 的二维张量
# 创建一个自适应二维最大池化层,指定目标输出大小为 (2, 2)
adaptive_max_pool = nn.AdaptiveMaxPool2d(output_size=(2, 2))
# 对输入进行自适应二维最大池化
output = adaptive_max_pool(x)
print(output) # 输出自适应最大池化后的结果3.3.6 自适应三维最大池化(AdaptiveMaxPool3d)
函数构成:
adaptive_max_pool = nn.AdaptiveMaxPool3d(output_size)示例:
import torch
import torch.nn as nn
# 创建一个三维输入张量(4x4x4的数据)
x = torch.randn(1, 1, 4, 4, 4) # 随机生成一个大小为 4x4x4 的三维张量
# 创建一个自适应三维最大池化层,指定目标输出大小为 (2, 2, 2)
adaptive_max_pool = nn.AdaptiveMaxPool3d(output_size=(2, 2, 2))
# 对输入进行自适应三维最大池化
output = adaptive_max_pool(x)
print(output) # 输出自适应最大池化后的结果