tensorflow模型量化篇(1)量化方法及动态范围量化
文章目录
- 1 量化方法
-
- 1.1 优缺点比较
- 2 训练后量化
-
- 2.1 方法
- 2.2 选择策略
- 2.3 数据类型
- 2.4 动态范围量化(dynamic range quantization)
-
- 2.4.1 数据类型变化
- 2.4.2 使用方法
- 章节导航
-
- 下一篇:[tensorflow模型量化篇(2)全整形量化](https://blog.csdn.net/weixin_43490422/article/details/114988717)
1 量化方法
在tensorflow官网中有两种类型的量化方法:
- 量化感知训练(Quantization aware training)
- 训练后量化(Post-training quantization)
这两种方法一种是在训练中量化,一种是训练后量化。
1.1 优缺点比较
- 训练后(指训练后量化):集成到tensorflow lite转换器中,迭代快、容易使用,但是模型精度损失较大。
- 训练过程中(指量化感知训练):基于Keras搭建。相对难以使用,需要更长的时间来重新训练模型,但对模型精度的保持比较好。
2 训练后量化
因为训练后量化的易用性,所以先从此方法学起。
2.1 方法
训练后量化有三种方式可供选择:
| 技术 | 优点 | 硬件支持 |
|---|---|---|
| 动态范围量化(dynamic range quantization) | 小了4x , 2x-3x 加速 | CPU |
| 全整形量化(Full integer quantization) | 小了4x, 3x+ 加速 | CPU, Edge TPU, Microcontrollers |
| 半浮点数量化(Float16 quantization) | 小了两倍,可GPU加速 | CPU, GPU |
这里的小了多少倍,是根据数据的精度来算的,举例来说,浮点数float32类型量化为int8类型,从32位降低到了8位,所以是小了4倍。
2.2 选择策略
下图是tensorflow官方给出的这三种方法的选择策略图:
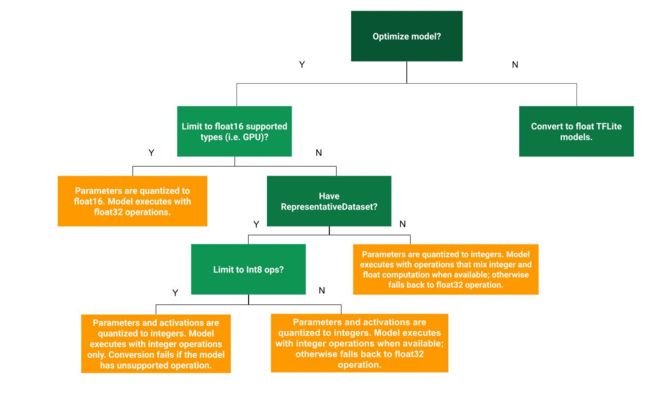
英语水平有限,暂时翻译如下:
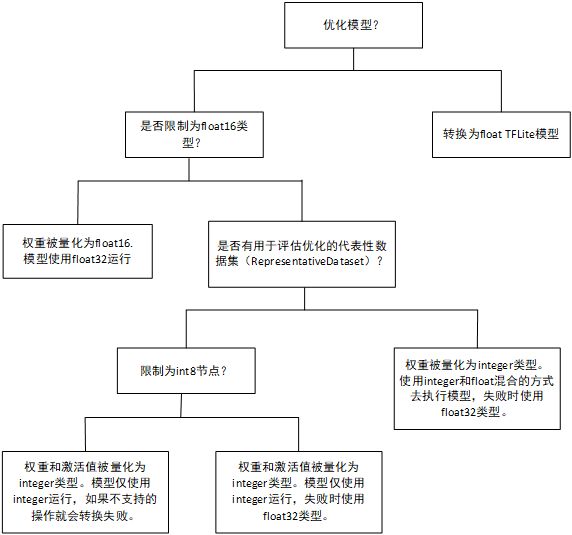
2.3 数据类型

2.4 动态范围量化(dynamic range quantization)
注:在官网上以前这个位置的名称叫做混合量化(post training “hybrid”),也有tensorflow官方工作人员的证明,确实有混合量化:(https://v.qq.com/x/page/h0927f3qzvg.html)

现在这个位置被改为动态范围量化,推测两者应该是一种东西。

2.4.1 数据类型变化
①在模型转换时量化权重张量,量化为8bit整数,此时非常量的激活张量还用浮点数来表示
②在推理时动态的量化激活张量,对于支持量化内核的ops,激活在处理之前被动态量化到8位的精度,在处理之后被反量化到浮点精度。
2.4.2 使用方法
读取保存的model模型,使用tensorflow lite转换器,配置它默认的优化方式。
官方示方法:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()
官方示例代码参考:https://www.tensorflow.org/lite/performance/post_training_quant
下面从一个使用minist数据集的代码加深了解
import tensorflow as tf
from tensorflow import keras
#加载minist数据集
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
#数据预处理
train_images = train_images / 255.0
test_images = test_images / 255.0
#构建模型
model = keras.Sequential([
keras.layers.InputLayer(input_shape=(28, 28)),
keras.layers.Reshape(target_shape=(28, 28, 1)),
keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation=tf.nn.relu),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
# 编译并训练
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(
train_images, train_labels,
epochs=1, validation_split=0.1,
)
1688/1688 [==============================] - 12s 7ms/step - loss: 0.5289 - accuracy: 0.8666 - val_loss: 0.1034 - val_accuracy: 0.9710
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
tflite_name = "tflite_model"
open(tflite_name, "wb").write(tflite_model)
84760
#动态范围量化,之前被称作为混合量化
converter_quant = tf.lite.TFLiteConverter.from_keras_model(model)
converter_quant.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model_quant = converter_quant.convert()
#保存tf lite 模型
DRQ_name = "quantify_DRQ.tflite"
open(DRQ_name, "wb").write(tflite_model_quant)
24176
从上边的代码结果可以看出来模型大小从84760b降到了24176b,约为原来的1/4。
print(input_details)
print(output_details)
[{'name': 'input_1', 'index': 0, 'shape': array([ 1, 28, 28], dtype=int32), 'shape_signature': array([-1, 28, 28], dtype=int32), 'dtype': , 'quantization': (0.0, 0), 'quantization_parameters': {'scales': array([], dtype=float32), 'zero_points': array([], dtype=int32), 'quantized_dimension': 0}, 'sparsity_parameters': {}}]
[{'name': 'Identity', 'index': 18, 'shape': array([ 1, 10], dtype=int32), 'shape_signature': array([-1, 10], dtype=int32), 'dtype': , 'quantization': (0.0, 0), 'quantization_parameters': {'scales': array([], dtype=float32), 'zero_points': array([], dtype=int32), 'quantized_dimension': 0}, 'sparsity_parameters': {}}]
#在PC python中测试tf lite 模型的准确率
def evaluate(interpreter_path):
#加载模型并分配张量
interpreter = tf.lite.Interpreter(model_path=interpreter_path)
interpreter.allocate_tensors()
#获得输入输出张量.
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
import numpy as np
index = input_details[0]['index']
shape = input_details[0]['shape']
acc_count = 0
image_count = test_images.shape[0]
for i in range(image_count):
interpreter.set_tensor(index, test_images[i].reshape(shape).astype("float32"))
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
label = np.argmax(output_data)
if label == test_labels[i]:
acc_count += 1
print("test_images accuracy is {:.2%}".format(acc_count/(image_count)))
evaluate(DRQ_name)
evaluate(tflite_name)
test_images accuracy is 97.03%
test_images accuracy is 97.02%
通过以上对比,动态范围量化使得模型大小缩小为原来的1/4,模型准确率降低了0.01%