re模块(正则)
【 一 】 re模块概述
在线测试工具 正则表达式在线测试 - 站长工具
随着正则表达式越来越普遍,Python 内置库 re 模块也支持对正则表达式使用
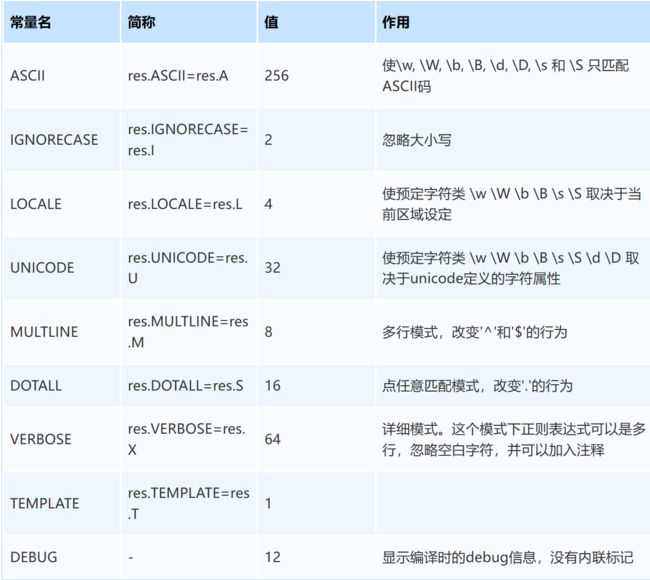
Python 提供了re模块可以支持正则表示表达式使用,re模块提供了9个常量、12个函数
 使用方法:
使用方法:
re模块是Pytohon内置库,我们只需要import re就可以直接导入进去正常使用了
re 模块对象组成:
1.正则对象:用于执行正则表达式相关操作的实体
2.匹配对象: 用于存放正在表达式匹配的结果并提供用于获取相关匹配结果的方法
【 二 】re模块的常量
【 三 】 字符组
[abc]:匹配字符集合中的任意一个字符,即匹配'a'、'b'或'c'。[^abc]:匹配除字符集合中的任意一个字符以外的字符。[a-z]:匹配指定范围内的任意小写字母。[A-Z]:匹配指定范围内的任意大写字母。[0-9]:匹配指定范围内的任意数字。[a-zA-Z]:匹配指定范围内的任意字母。[a-zA-Z0-9]:匹配指定范围内的任意字母或数字。
元字符:
元字符是正则表达式中具有特殊意义的字符。它们用于匹配模式中的特定字符或字符集合。以下是一些常见的元字符及其含义:
-
.(点号):匹配除换行符之外的任意字符。 -
^(脱字符):匹配输入字符串的开头。 -
$(美元符号):匹配输入字符串的结尾。 -
*(星号):匹配前面的字符零次或多次。 -
+(加号):匹配前面的字符一次或多次。 -
?(问号):匹配前面的字符零次或一次。 -
{n}:匹配前面的字符恰好 n 次。 -
{n,}:匹配前面的字符至少 n 次。 -
{n,m}:匹配前面的字符至少 n 次,但不超过 m 次。 -
[](方括号):用于定义字符集合,可以匹配其中的任意一个字符。 -
()(圆括号):用于分组字符,可以应用其他元字符,如|或*。 -
\(反斜杠):用于转义特殊字符,使其失去特殊意义。
import re
# 匹配包含数字和字母的字符串
pattern = r'(?=.*\d)(?=.*[a-zA-Z]).+'
text = "a1b2c3"
result = re.match(pattern, text)
if result:
print("字符串符合要求")
else:
print("字符串不符合要求")转义符:
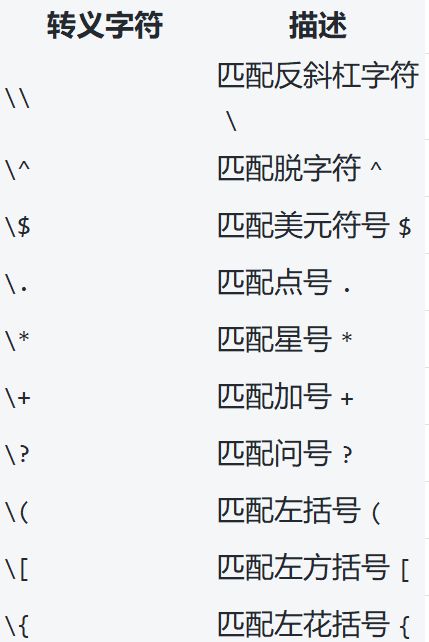
在正则表达式中,某些字符具有特殊含义,如 .、*、+、?、^、$、[、]、(、)、{、} 等。如果想要匹配这些字符本身,而不是它们的特殊含义,需要使用转义符 \。
例如,为了匹配字符串 a.b,可以使用正则表达式 a\.b。在这个表达式中,\. 表示匹配实际的 . 字符,而不是其特殊含义(匹配任意单个字符)。
以下是一些常用的正则表达式转义字符:
需要注意的是,在 Python 中,反斜杠本身也是一个特殊字符,因此在正则表达式中使用反斜杠时,需要使用两个反斜杠来表示一个。例如,要匹配字符串
C:\Windows\System32,可以使用正则表达式C:\\Windows\\System32。
量词:
在正则表达式中,量词(Quantifiers)用于指定模式重复出现的次数。常见的量词包括:
*:匹配前面的模式零次或多次。例如,ab*c可以匹配'ac'、'abc'、'abbc'等。+:匹配前面的模式一次或多次。例如,ab+c可以匹配'abc'、'abbc'、'abbbc'等。?:匹配前面的模式零次或一次。例如,colou?r可以匹配'color'或'colour'。{n}:匹配前面的模式恰好出现n次。例如,a{3}可以匹配'aaa'。{n,}:匹配前面的模式至少出现n次。例如,a{2,}可以匹配'aa'、'aaa'、'aaaa'等。{n,m}:匹配前面的模式出现n到m次。例如,a{2,4}可以匹配'aa'、'aaa'、'aaaa'。
除了上述基本的量词外,还可以使用特殊的量词简化匹配操作,例如:
*?:非贪婪模式的零次或多次匹配。+?:非贪婪模式的一次或多次匹配。??:非贪婪模式的零次或一次匹配。{n}?:非贪婪模式的恰好n次匹配。{n,}?:非贪婪模式的至少n次匹配。{n,m}?:非贪婪模式的n到m次匹配。
以下是一些使用量词的示例:
-
匹配重复出现的数字:
\d+:匹配一个或多个数字。
-
匹配重复出现的连续字母:
[a-z]+:匹配一个或多个小写字母。
-
匹配重复出现的日期格式:
\d{4}-\d{2}-\d{2}:匹配形如'YYYY-MM-DD'的日期。
希望以上解释和示例能帮助你更好地理解和使用正则表达式中的量词。
【 四】re模块的编译方法
Python 内置库re模块提供complie()方法来对正则表达式字符进行编译
re.compile(strPattern[, flag]):
-
strPattern 参数
- 这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。
- 对正则表达式进行编译后,会被提前缓存,重复使用提高效率
-
flag参数
-
该参数指定匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。
-
可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
-
import re
re = re.compile('正则表达式')
m = re.match('re')re.complie()会对正则表达提前缓存,提高正则表达式重复使用效率
【 四 】re模块进行只要正则表达式进行被人匹配:
1.编写Python正则表达式字符串re
2.使用re.compile()对正则表达式进行编译成正则对象Pattern ps
3.正则对象ps调用p.match()或者p.fullmatch()函数得到匹配对象Match m
4.通过匹配对象 m 内容进行判断,匹配是否成功
re = "正则表达式"
ps = re.compile(re)
m = ps.match("检测的文本")
if m:
print(m.group())re 模块使用正则表达式进行内容查找、替换等操作
-
sp.search("检测内容")使用编译后的模式sp在字符串 "检测内容" 中搜索匹配的第一个结果。返回的结果是一个Match对象,可以通过调用对象的方法获取匹配到的结果。 -
sp.findall("检测内容")使用编译后的模式sp在字符串 "检测内容" 中查找所有匹配的结果,并以列表形式返回所有匹配到的子串。 -
sp.finditer("检测内容")使用编译后的模式sp在字符串 "检测内容" 中查找所有匹配的结果,并返回一个迭代器,通过迭代器可以遍历所有匹配的子串。 -
sp.sub("替换内容", "检测内容")使用编译后的模式sp在字符串 "检测内容" 中查找匹配的子串,并将其替换为 "替换内容"。返回替换后的新字符串。 -
sp.subn("替换内容", "检测内容")使用编译后的模式sp在字符串 "检测内容" 中查找匹配的子串,并将其替换为 "替换内容"。返回替换后的新字符串和替换的总次数。 -
sp.split("检测内容")使用编译后的模式sp将字符串 "检测内容" 按照匹配的模式进行分割,返回分割后的子串列表。
ps = '正则表达式'
sp = re.compile(ps)
# 查找
mf1 = sp.search("检测内容")
mf2 = sp.findall("检测内容")
mf3 = sp.finditer("检测内容")
# 替换
ms = sp.sub("检测内容")
ms2 = sp.subn("检测内容")
# 分割
mp = sp.split("检测内容")具体示例:
import re
# 编译正则表达式模式
pattern = re.compile(r'^hello')
# 在字符串中查找匹配的子串
text = 'hello world, hello python, hello regex'
match_list = pattern.findall(text)
# 输出匹配到的子串列表
print(match_list) # ['hello', 'hello', 'hello']
# 替换匹配到的子串
new_text = pattern.sub('world', text)
# 输出替换后的新字符串
print(new_text) # 'world world, world python, world regex'
# ['hello']
# world world, hello python, hello regex正则表达式方法总结:
-
re.compile(pattern, flags=0):编译正则表达式模式,返回一个正则表达式对象。 -
re.search(pattern, string, flags=0):在字符串中搜索模式匹配的第一个位置,返回一个 Match 对象。如果没有匹配到,则返回 None。 -
re.match(pattern, string, flags=0):从字符串开头开始匹配模式,返回一个 Match 对象。如果没有匹配到,则返回 None。 -
re.findall(pattern, string, flags=0):查找字符串中所有与模式匹配的子串,并以列表形式返回所有匹配到的子串。 -
re.finditer(pattern, string, flags=0):查找字符串中所有与模式匹配的子串,并返回一个迭代器,通过迭代器可以遍历所有匹配的子串。 -
re.sub(pattern, repl, string, count=0, flags=0):使用指定的替换字符串repl,将字符串中与模式pattern匹配的子串替换为替换字符串。可选参数count指定最多替换的次数。 -
re.split(pattern, string, maxsplit=0, flags=0):按照模式匹配的位置,将字符串分割为若干子串,并返回一个列表。可选参数maxsplit指定最多分割的次数。 -
Match.group([group1, …]):返回与模式中的分组对应的子串。可选参数group指定要获取的分组,如果未指定,则默认返回整个匹配到的子串。 -
Match.groups(default=None):返回一个包含所有分组子串的元组。可选参数default指定当一个分组未匹配到时的默认值。 -
Match.groupdict(default=None):返回一个包含所有命名分组的字典。可选参数default指定当一个分组未匹配到时的默认值。
【1】匹配邮箱地址
import re
# 定义正则表达式模式
pattern = r'^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+\.[a-zA-Z0-9_-]+$'
# 测试样例
emails = ['[email protected]', '[email protected]', '[email protected]', 'invalid_email']
# 对每个样例进行匹配测试
for email in emails:
if re.match(pattern, email):
print(f'{email} is a valid email address')
else:
print(f'{email} is an invalid email address')
# [email protected] is a valid email address
# [email protected] is a valid email address
# [email protected] is an invalid email address
# invalid_email is an invalid email address
【 2 】匹配HTML标签中的内容
import re
# 定义正则表达式模式
pattern = r'<[^>]+>(.*?)]+>'
# 测试样例
html = 'Hello, world!'
# 查找所有匹配的子串
matches = re.findall(pattern, html)
# 输出匹配到的结果
print(matches) # ['Hello, ', 'world', '!']【 3 】过滤HTML标签
import re
# 定义正则表达式模式
pattern = r'<[^>]+>'
# 测试样例
html = 'Hello, world!'
# 使用 sub() 函数将所有标签替换为空字符串
text = re.sub(pattern, '', html)
# 输出替换后的文本
print(text) # 'Hello, world!'【 4 】匹配IP地址
import re
# 定义正则表达式模式
pattern = r'^((25[0-5]|2[0-4]\d|1\d{2}|[1-9]\d|\d)\.){3}(25[0-5]|2[0-4]\d|1\d{2}|[1-9]\d|\d)$'
# 测试样例
ips = ['192.168.0.1', '127.0.0.1', '10.0.0.1', '256.0.0.1', '1.2.3']
# 对每个样例进行匹配测试
for ip in ips:
if re.match(pattern, ip):
print(f'{ip} is a valid IP address')
else:
print(f'{ip} is an invalid IP address')以上是一些常见的正则表达式示例,你可以根据具体需求自定义正则表达式模式,并使用
re模块提供的函数对字符串进行匹配、替换和分割操作。