〖Python网络爬虫实战㊸〗- 极验滑块介绍(五)
- 订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+
python项目实战
Python编程基础教程系列(零基础小白搬砖逆袭)
- 说明:本专栏持续更新中,订阅本专栏前必读关于专栏〖Python网络爬虫实战〗转为付费专栏的订阅说明
- 作者:爱吃饼干的小白鼠。Python领域优质创作者,2022年度博客新星top100入围,荣获多家平台专家称号。
最近更新
〖Python网络爬虫实战㊷〗- 极验滑块介绍(四)
极验验证码
目前,许多网站采取各种各样的措施来反爬虫,其中一个措施便是使用验证码。随着技术的发展,验证码的花样越来越多。验证码最初是几个数字组合的简单的图形验证码,后来加入了英文字母和混淆曲线。有的网站还可能看到中文字符的验证码,这使得识别愈发困难。我们今天来介绍极验验证码。
实战案例——某网站
我们前几篇文章,和大家详细介绍了一下极验滑块逆向的过程,最近,有粉丝让我来出个实战案例,由于某些特殊原因,本文的源码就不展示了,接下来,我以这个网站为例,和大家介绍。
严正声明:本文仅供交流学习,勿用于非法用途
实战分析
我们首先打开这个网站,我们看到是这样的,我们打开开发者工具,刷新页面,我们这里会发现,和我们在官网是差不多的,只有一些细微的差别,比如说,接口地址变了。


那我们接下来开始写代码,这里面调用的函数,我在之前的文章发过,大家可以自行翻看。
实战代码
获取gt,challenge
我们第一步,看到是拿到gt,challenge,我们可以看到这样的数据接口,我们直接写代码。

session = requests.session()
url = "https://passport.woshipm.com/sys/StartCaptchaServlet.html"
headers = {
"Referer":"https://passport.woshipm.com/user/verifyCodeLogin.html",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62"
}
response = session.get(url, headers=headers)
gt = re.findall('"gt":"(.*?)"',response.text)[0]
challenge = re.findall('"challenge":"(.*?)"',response.text)[0]
我们到这里,就拿到了gt,challenge,我们接下来,就是获取第一次的S。
获取第一次的S
我们前面讲过,这个S在后面请求中,会发生变化,我们这里可以不用管他,但是,要模拟请求。
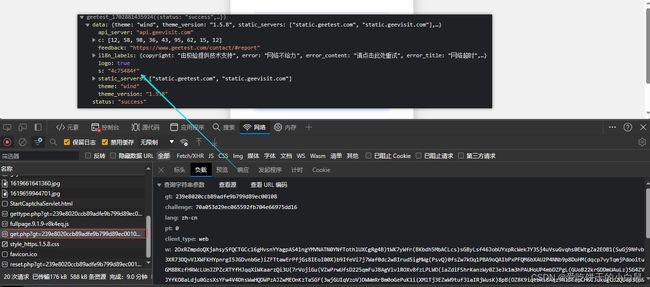
timetemp2 = int(time.time()*1000)
url2 = "https://api.geetest.com/get.php"# 初始化值
params2 = {
"gt": gt,
"challenge": challenge,
"lang": "zh-cn",
"pt": 0,
"client_type": "web",
"w":"",
"callback": f"geetest_{timetemp2}"
}
response2 = session.get(url2, params=params2)
S = re.findall('"s": "(.*?)"',response2.text)[0]## C是固定的
# print("S的值为:",S)我们这里的前两个W的值可以置空,这个和官网不一样,就不用我们去扣前两个W的代码了。
获取滑块类型
我们接下来,就是去获取滑块类型,我们很容易看到这样的接口:

这里很简单,在实战的过程中,这里不回去,会被标识为爬虫程序。
timetemp3 = int(time.time()*1000)
url3 = "https://api.geevisit.com/ajax.php"
params3 = {
"gt": gt,
"challenge": challenge,
"lang": "zh-cn",
"pt": 0,
"client_type": "web",
"w": "",
"callback": f"geetest_{timetemp3}"
}
response3 = session.get(url3,params=params3)
获取滑块图片
我们这里接下来就是获取滑块图片,我们主要在这里获取滑块距离和滑块轨迹。

timetemp4 = int(time.time()*1000)
url4 = "https://api.geevisit.com/get.php?"
params4 = {
"is_next": "true",
"type": "slide3",
"gt": gt,
"challenge": challenge,
"lang": "zh-cn",
"https": "false",
"protocol": "https://",
"offline": "false",
"product": "embed",
"api_server": "api.geevisit.com",
"isPC": "true",
"autoReset": "true",
"width": "100%",
"callback": f"geetest_{timetemp4}"
}
response4 = session.get(url4, params=params4)
str_data = re.findall(r'\((.*?)\)', response4.text)[0]
res = json.loads(str_data)
home_url = "https://static.geetest.com/"
new_challenge = res['challenge']
bg =home_url+ res['bg']
fullbg = home_url+res['fullbg']
SS = res['s']## C是固定的 取这里的S
sliceImg = home_url+res['slice']
# print("缺口图片:",bg,"\n背景图:",fullbg,"滑块:",sliceImg)
# print("S的值为:",SS)
# print('成功获取到new_challenge',new_challenge)
def save(bg,fullbg):
content1 = requests.get(bg).content
with open('./乱序缺口背景图.png', mode='wb') as f:
f.write(content1)
# print('乱序缺口背景图.png', 'successful')
content2 = requests.get(fullbg).content
with open('./乱序背景图.png', mode='wb') as f:
f.write(content2)
# print('乱序背景图.png', 'successful')
content3 = requests.get(sliceImg).content
with open('./slice.png', mode='wb') as f:
f.write(content3)
save(bg,fullbg)
restore_picture()
distance = get_gap('./缺口背景图片.png','./背景图片.png')
# print(distance)restore_picture()是调用了图片还原函数,get_gap()是获取滑块缺口距离的函数。这两个我在前面的文章都有发,可以直接复制使用。
我们在这里获取到了新的challenge和S,我们在最后一个W的加密要用到。
获取validate
我们只要成功逆向出最后的W,我们就能拿到validate,这个W怎么生成的可以看上一篇文章,由于,我在js中把这个gt写固定值,就没有传入这个值了。还是很简单的。

with open('w3.js','r', encoding='utf-8') as f:
js = f.read()
trace = get_slide_track(distance)
distance_t = trace[-1][0]
passtime = trace[-1][-1]
w = execjs.compile(js).call('get_w', distance, new_challenge, trace, SS, passtime)
# print(w)
timetemp5 = int(time.time() * 1000)
url5 = "https://api.geevisit.com/ajax.php"
params5 = {
"gt": gt,
"challenge": new_challenge,
"lang": "zh-cn",
"$_BCX": 0,
"client_type": "web",
"w": w,
"callback": f"geetest_{timetemp5}"
}
response5 = session.get(url5, params=params5)
# print(response5.text)
validate = re.findall('"validate": "(.*?)"',response5.text)[0]
# print(validate)
这里的trace是滑块轨迹,至于怎么来的,看我之前的文章,发过。passtime是滑块移动的时间。最后我们这里正常的化,会得到一个validate。接下来,我们就模拟请求验证码。
模拟请求验证码
我们会看到一个发送手机验证码的接口,这里肯定是传入了我们的手机号和刚刚得到的validate。
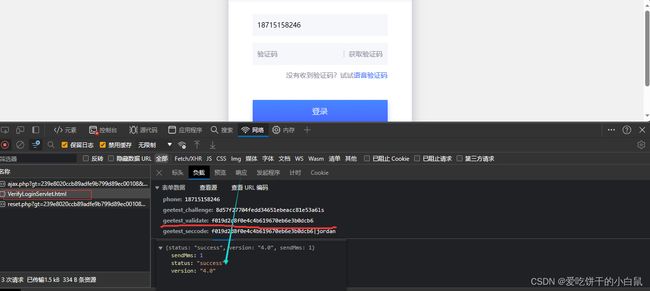
这个代码就很简单了,到这里,我们整个案例到这里就结束了。
send_timetemp= int(time.time() * 1000)
send_url = "https://passport.woshipm.com/sys/VerifyLoginServlet.html"
send_params = {
'phone': 手机号,
'geetest_challenge':new_challenge,
'geetest_validate': validate,
'geetest_seccode': f'{validate}|jordan',
}
send_res = requests.post(url= send_url,headers=headers, params=send_params)
print(send_res.text)
实战效果
我们总共模拟请求了6次,完成了模拟请求验证码,我们来看看效果。

至此,我们总共花了5篇文章来介绍了极验滑块3,现在,还有极验4,大家感兴趣的可以自己去试试,最后,这里再强调一下,本文仅供交流学习,勿用于非法用途。这个自己学习就可以了,请不要滥用这个去轰炸别人,好了,今天,就到这里了。
