运用爬虫和neo4j数据库制作体育人物图谱(demo)
运用爬虫和neo4j数据库制作体育人物图谱(demo)
总体思路:从虎扑网站爬取体育人物列表,再通过人物列表去百度百科爬取人物关系列表,将两个文件都以csv格式保存,导入neo4j数据库制成人物图谱。
其中爬虫筛选数据用的是xpath
1. 爬取数据
- 爬取体育人物列表
通过虎扑网站爬取体育人物,网址
导入的类以及UA的设置:
from lxml import etree
import requests
import time
import csv
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31',
}
定义一个工具函数,传入url解析数据用的xpath,返回爬取的列表:
def search_by_xpath(url, xpath):
resp = requests.get(url, headers=headers)
text = resp.text
parser = etree.HTML(text)
list = parser.xpath(xpath)
# print(list)
return list
由网站的格式可知要获得球员姓名,就必须先进入球队,再在球队的url中解析出人物,因此:
定义解析球队的函数:
def parse_team_url(url, xpath):
player_url_list = search_by_xpath(url, xpath)
for player_url in player_url_list:
parse_player_url(player_url, '/html/body/div[3]/div[4]/table/tbody/tr/td[2]/b/a/text()')
time.sleep(5)
定义解析球员的函数:
def parse_player_url(url, xpath):
player_list = search_by_xpath(url, xpath)
for player in player_list:
players.append(player)
print(player)
print("---")
其中players为定义的全局列表,用于储存player信息
便于模块化,定义调用以上两个函数的函数:(后续打算加入get其他players的函数)
def get_NBA_players(url):
parse_team_url(url, '//span/a/@href')
最后定义主函数:
def main():
get_NBA_players(url)
header = ['player']
with open('player.csv', 'w', encoding='utf-8', newline='') as fp:
writer = csv.writer(fp)
writer.writerow(header)
for player in players:
writer.writerow([player])
文件以csv格式保存,最后的[player]不加[]会导致 保存的文件每个字中间多个,
完成后的文件截取:

- 爬取体育人物关系
通过百度百科爬取人物关系
主函数中载入刚刚的player.csv,并解析出每个player对应的百科url:
def main():
# https://baike.baidu.com/item/
with open("player.csv", 'r', encoding='utf-8') as fp:
players = csv.reader(fp) # 返回列表
for player in players:
data = {'fromtitle': player[0]}
query = parse.urlencode(data)
path = query[10:]
url = 'https://baike.baidu.com/item/' + path + '?' + query
parse_relation(player[0],url)
time.sleep(2)
定义提取关系的函数:
def parse_relation(player,url):
relation_list = search_by_xpath(url,'//div[@class="info"]//span[@class="name"]/text()')
if relation_list == None: # 如果关系为空,则返回
return
relation_people_list = search_by_xpath(url,'//div[@class="info"]//span[@class="title"]/text()')
# for r in relation_list:
# print(r)
# for rs in relation_people_list:
# print(rs)
for i in range(0,len(relation_people_list)):
relations.append((player,relation_list[i],relation_people_list[i]))
print(relations)
其中relations为定义的全局列表,用于储存每个人物关系的三元组
最后主函数中保存文件:
header = {'subject','relation','object'}
with open('player_relation.csv', 'w', encoding='utf-8', newline='') as fp:
writer = csv.writer(fp)
writer.writerow(header)
for relation in relations:
writer.writerows([relation])
完成后的文件截图:(赏心悦目的三元组形式)

2、导入neo4j数据库制成人物关系图谱
- 导入数据

将爬取的两个文件导入neo4j的import目录下:
load两个文件:
load csv from 'file:///player.csv' as line
create (:player {name:line[0]})
导入成功显示player节点:

load csv from 'file:///player_relation.csv' as line
create (:playerRelaltion {subject:line[0],rela:line[1],object:line[2]})
导入成功效果:

- 创建节点间关系
通过语句创建图谱:
match (n:player),(m:playerRelation),(l:player) where n.name=m.subject and l.name=m.object
create (n)-[r:关系{relation:m.rela}]->(l)
创建成功结果:
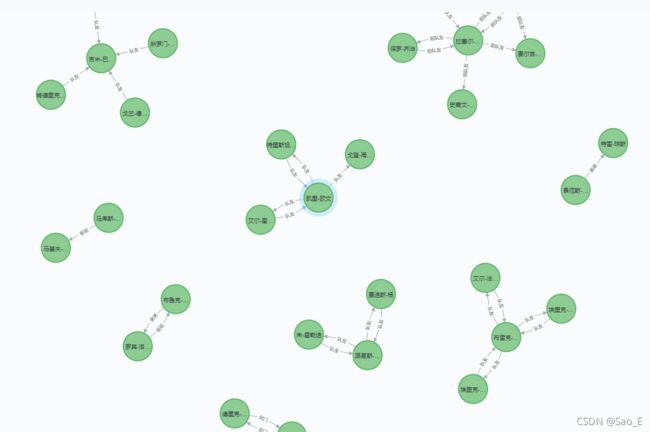
至此大功告成!
遇到的问题:
1、爬虫方面:
主要的问题在保存,总是不能以想要的形式保存,最后也算是一次次试,总算试出了合适的保存方式
2、数据库方面:
由于我爬取的体育人物数据中会存在这个情况,一边是勒布朗·詹姆斯,一边是勒布朗-詹姆斯,其中·和-的区别我一开始没注意,导致匹配不到对应节点,后来更改了才成功,可能是虎扑数据和百度百科数据格式的差异吧。
还有就是一些CQL的语句还不太熟练,翻一下使用文档还是可以解决的
不足之处:
从最后显示的人物图谱上来看,其实比我预期的要小,分析了一下原因:我通过爬取来的体育人物清单再去爬取他们的关系,而他们的关系中的家人、教练等等的关系人物,在我的体育人物清单中是不存在的,于是这个关系就没有,甚至一些队友关系的人物,如果已经退役或者其他什么原因,就不在人物清单上了,这样的一部分节点也无法形成图谱,目前只有考虑往人物清单中添加人物的方法来解决,不知道看到这的大家有没有什么更好的想法可以提供