Bazel作为构建工具之王,将会颠覆你对CI的认知

说到构建工具,不同语言技术栈的人,想起的构建工具不同。
Java程序员想到的是Maven,前端程序员想的是NPM或者Webpack、Android程序员想到的是Gradle、Rust程序想到的是Cargo、C++程序员想到的是Make等等。
然而这些工具在Bazel面前,层次有些低。所以,我愿称Bazel是构建工具之王。
P.S. Android平台的构建,2020年已经开始了迁移到Bazel的工作。 具体地址:https://blog.bazel.build/2020/11/12/aosp_migrating_to_bazel.html
Bazel介绍
Bazel是Google在2015年开源的一款构建工具。
目前使用Bazel的知名公司有:Esty、Canva、Databricks、Dropbox、Huawei、Line、LinkedIn、Stripe、Twitter、Tinder、Uber、VMware、Wix等。具体可以看:https://bazel.build/community/users 。
其中Twitter是从自家的Pants迁移到的Bazel的,具体迁移过程介绍:https://opensourcelive.withgoogle.com/events/bazelcon2020/watch?talk=day1-talk2
Facebook使用的是其自研的Buck2,但是,其与Bazel使用的是相同的远程执行的API。
除了公司,某些著名的开源软件也使用Bazel构建,包括自动化测试领域的Selenium,AI领域的TensorFlow,容器编排领域的Kubernetes等。具体还有:https://bazel.build/community/users#open-source-projects-using-Bazel
相对于其它构建工具,它的显著的特点有:
1. 支持多语言;
2. 支持远程分布式构建;
3. 支持增量构建;
4. 支持强大的密闭性;
5. 支持构建缓存;
6. 支持并行构建。
假设存在一个复杂的软件工程
假设存在一个软件工程中,它包含5部分:Web前端、Android端、Java后端、Go后端、嵌入式端。
作为Java后端的程序员,他们修改了一个API。但是他作为个人,他无法预知到底发生了哪些影响。
所以,他把这个问题交给了持续集成(CI),让它去发现集成问题。
在过去很长一段时间里,行业里只有一种CI模式,我称之为传统的CI模式。
殊不知,还有另一种模式。
传统的CI模式
目前行业里比较传统的CI架构,通常如下:

在这样的架构下,实现CI的步骤如下:
1. 开发人员提交代码;
2. Gitlab检测到开发人员提交代码,然后触发Jenkins controller执行;
3. Jenkins controller根据该代码仓库预先设计的pipeline执行;
4. Jenkins controller根据pipeline中的任务所需要的构建环境,将任务分配给不同的Jenkins agent;
5. 在agent构建完成后,将制品release到制品仓库中。
如果开发者希望验证自己写的代码,就必须将代码commit到Gitlab中。因为整个验证环境被定义在CI环境的Pipeline中。而且这个过程,越大的工程,集成速度越慢。开发者也无法在本地进行全量验证。
作为Pipeline的维护者,他需要清楚知道哪些任务是可以并行执行的,并手工配置并行,这样才能加快构建速度。比如前端构建和后端构建可以并行进行。
也就是说在传统的CI模式下,开发者的效率会随着软件的规模越大而降低。换句话,这样的模式,开发效率无法scale。
案例
希望以下案例可以给你一个感性的认知。下图是Google在2010年到2015年的周commit数量。绿线代表commit总数,黄线是人数。我们取离我们最近的2015年的数据来讨论。2015年的代码量如下:

在这个代码量下,每周能达到300左右的commit。如下图:

根据持续集成的原则,每一个commit都必须构建通过。20亿行代码一次全量构建需要多久?
我们以一个开源项目作参考。apitable是一个开源的数据表格项目,它有200万左右的代码,全量构建一次需要20分钟左右。那么,根据不准确的类推,20亿行代码,全量构建一次需要:20/2,000,000 * 2000,000,000=200,000,000分钟,也就是13天左右。要实现一个commit一次全量构建是不可能的,通过传统CI的模式。
在传统的CI模式下,是要尽量避免执行全量构建这样庞大的代码量的。所以,传统CI模式下,通常是多仓库模式管理代码。
那么Bazel呢?Bazel如果真要构建这样庞大的代码量,估计也够呛。但是由于Bazel天然支持并行构建、构建缓存和增量构建,所以,Bazel通常不会遇到真正意义的全量构建的情况。
为什么其它公司不使用Bazel
也许有人会问:为什么阿里2018年新增的代码行(https://zhuanlan.zhihu.com/p/54435171)就有12亿,不也没有使用Bazel吗?
这个是一个好问题。
但是,无法简单的回答这个问题,而是需要深入到各自组织内部才能分析清楚。个人觉得可以从以下维度分析:
1. 在代码仓库上工作的人员的规模:同样的代码量,不同的组织需要不同数量的人维护;
2. 代码管理方式:阿里使用多仓库的管理办法,不需要统一的版本号;
3. 持续集成的程度不同:阿里可能不需要对每一个commit跑一次全量。
为什么Bazel会颠覆你对CI的认知
Bazel是如何解决传统CI模式下开发效率无法scale的问题呢?其主要通过它的六个特性来解决。
首先,Bazel支持远程分布式构建。
在一个使用Bazel构建的仓库中,开发者写好代码后,不用commit代码到Git仓库,只要在本地命令行执行bazel run --remote_executor=grpc://localhost:8980 //... ,代码仓库中所有构建和测试任务都将运行在远程执行服务器。远程执行服务器越多,构建速度越快。
这一特性可以明显地提高开发者本地的开发效率。因为开发者在本地就可以执行全量构建和全量测试。
传统CI模式下,无法提升开发者本地的开发效率。
第二,Bazel支持增量构建和增量测试(精准测试)。
开发者在本地执行build命令时,Bazel检测出修改了a.java文件,所以,Bazel只将构建a.java的任务及其相关的构建任务给远程执行服务器执行。这就是增量构建。
如果开发者执行test命令,Bazel则能检测出被影响的测试,然后只运行这些测试。其实这就是精准测试了。在Bazel中,精准测试实现起来并不难。
传统CI模式下,它是不关心增量构建和增量测试的。所以,每次运行都是全量。这是一种极大的浪费。
第三,支持构建缓存。
当程序员A执行完成构建后,Bazel会将所有的构建结果缓存起来。另一个程序员在同样的代码基础上执行相同的构建时,Bazel会直接读取缓存,而不再重复执行构建。
传统CI模式不关心构建缓存。
第四,支持强大的密闭性。
传统CI模式通过构建节点提供构建环境。当要执行mvn构建命令时,它会依赖构建环境是否已经安装好Maven。当要对Prometheus的配置进行验证时,就需要构建环境提供promtool命令行程序。
而Bazel提供一种叫工具链的机制,在执行到相应的任务时,Bazel通过该机制实现根据操作系统下载相应版本的构建工具。而不需要开发者操心构建工具的问题。
同时这一机制也是实现分布式构建的基础。
另,行业里构建工具之间的速度对比的报告,往往没有将构建环境准备的时间计算在内,这是不合理的对比方式。因为Bazel在真正开始构建前,会自动准备构建环境,以保证环境的密闭性。比如准备NodeJS环境或者Go环境。
感兴趣的同学可以看看自Gradle(https://blog.gradle.org/gradle-vs-bazel-jvm)的报告:
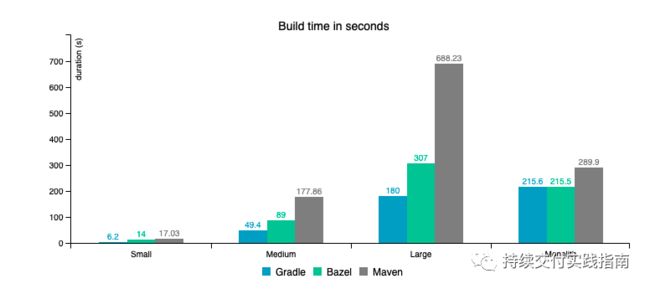
密闭性的另一个好处是提升构建的准确性。现实中经常出现的现象——程序员向DevOps平台抱怨“为什么我本地构建可以,在DevOps平台上构建就不行”——就可以得到很好的解决。
第五、支持多语言。
与针对单一语言而设计的构建工具不同,Bazel提供了一种叫rule的扩展机制,无限支持不同的语言。
当然,Java程序员不关心go程序员写的代码,但是,同一个软件工程下,不论哪门语言程序员都必须关心他写的代码是否对其他人写的代码有影响。
现实中,不同语言之间的引用关系是一定存在的。比如Java程序员改一个protobuf的定义,而go程序引用了这个定义。传统CI模式是无法感知到这个引用关系的,自然就无法容易的实现分布式构建和增量构建。
在Bazel中,不同语言之间的构建任务也是可以相互引用的。
第六、支持并行构建。
Bazel使用声明式的语言描述构建任务,使得它可以自动分析出哪些构建任务是可以并行执行的。
传统CI模块下,需要人工维护并行任务。这不仅需要人力,还不一定比Bazel做得好。
总之,有了Bazel之后,很多以前在CI pipeline中做的事情,就可以放在Bazel中实现了。
Bazel与IaC的关系
当基础设施被写成代码(Infrastructure as Code)后,实际上是需要构建和测试才能真正上线的。虽然Terraform提供了plan命令,方便开发人员在真正部署前就知道真正部署的内容,但是,整个基础设施不仅仅用Terraform,还会使用其它工具。
这些工具的配置又该如何在真正部署前进行自动构建测试呢?
由于Bazel支持多语言、密闭性和扩展机制,你可以通过Bazel实现对于基础设施的构建。
这是我通过扩展Bazel实现对Prometheus配置和告警规则进行单元测试的案例: https://github.com/zacker330/rules_prometheus 。
Bazel与单仓库的关系
单仓库指的是将多语言、多项目的代码放在同一个代码仓库中,而不是分成多个代码仓库。它有很多好处,我们可以另开一篇文章讨论。
代码的规模大到一定的程度,一定会遇到各种问题。而单仓库是解决这些问题的良方。大家可以看看Google的解决方案:https://www.youtube.com/watch?v=W71BTkUbdqE
如果是单仓库,就必须使用类似Bazel能很好支持单仓库的工具。
但是使用Bazel,就一定要推广单仓库吗?不一定。原来的多代码仓库下,也可以使用Bazel。
后记
写本文的目的,并不是鼓励大家无脑地在自己的工程中使用Bazel。因为现实中,一个构建工具的引入,除了考虑构建速度,还有其它的因素需要考虑。
接下来,我还会花很多时间在Bazel上。如果对Bazel或者构建工具感兴趣的同学,可以加群交流:

相关文章推荐:
比构建速度,Bazel是Gradle的10倍,不服不行!!!
DevOps平台两种实现模式
探讨基础设施即代码所带来的挑战