【关于JVM,不得不知道的那些事儿】
一、JVM内存区域划分
JVM主要是分成四个区域:堆、栈、程序计数器、方法区
JVM本质上是一个java进程,JVM启动之后就会从操作系统这里申请到一大块内存~
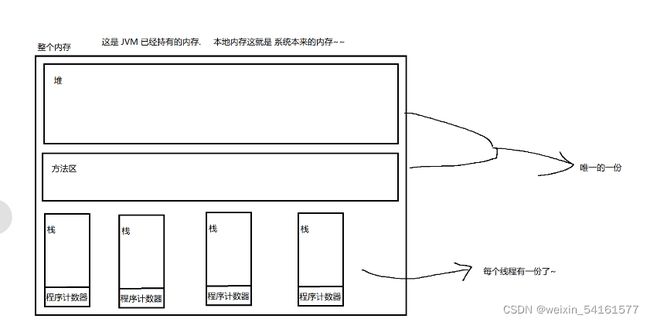
每个线程,都有自己的栈和程序计数器~
下面我们对于这四个区域进行详细的描述~
1.堆:里面放的就是new出来的对象
我们程序中每new一个实例对象,就会放到堆中。
2.方法区:里面放的是类对象
.java =》 .class =》 JVM就会把 .class进行加载,加到内存里=》类对象
类对象里都包含哪些内容:
类的static成员,作为类属性,同样也是在类对象中,也就是在方法区里~
1.包含了这个类的各种属性的名字、类型、访问权限
2.包含了这个类的各种方法的名字、参数类型、返回值类型、访问权限、以及方法的实现的二进制代码~
3.包含了这个类的static成员
.........
3.栈:放局部变量
4.程序计数器:内存区域中,最小的一个部分,里面放了一个内存地址,这个地址的含义,就是接下来要执行的指令地址~(咱们日常写的.java代码=》.class(二进制字节码,里面就是一些指令)=》放到内存中=》每个指令都有自己的地址=》CPU执行指令就需要去从内存中取地址,然后再在CPU上执行)
※:一个变量在内存的哪个区域,取决于它是一个成员变量,还是一个局部变量,还是一个静态变量。和它是不是引用类型没关系~
案例讲解:判断t所在的内存区域
1.
此时的t就是一个局部变量,因此t就是在栈上~
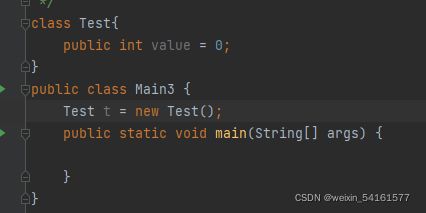
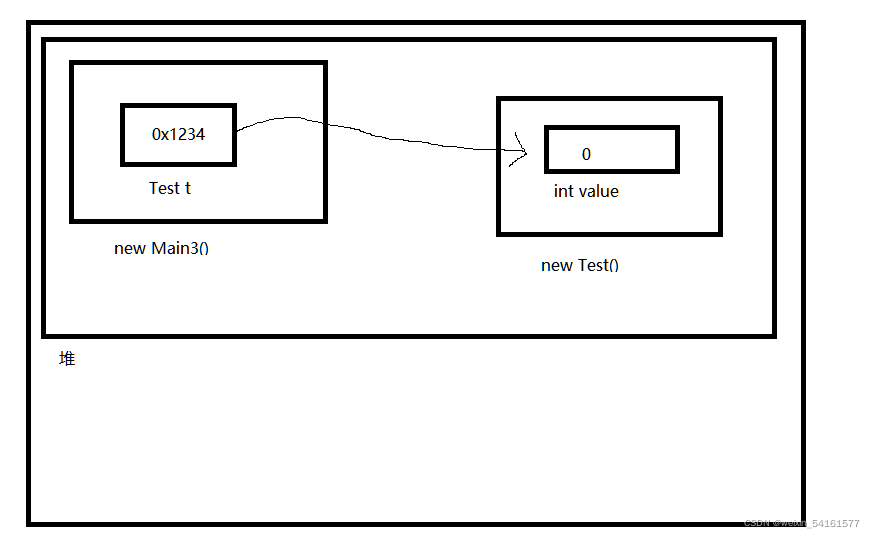
2.
注意:此时Main3 这个类是要在其他地方被new出来的
3.
注意:此时t是一个静态成员变量~
此时t作为Main3的静态成员变量, 随Main3放在方法区




二.和内存区域相关的两个异常
1.堆溢出(堆空间的耗尽,就会出现这个异常,典型情况就是一直new对象但是不去释放)
2.栈溢出(典型的场景,就是无限递归~栈里面除了要放局部变量之外,还要放方法的调用关系)
三、Java中的类加载
类加载其实就是JVM中一个非常核心的流程,做的事情就是把.class文件转换成JVM中的类对象~
四、类加载
1.类加载过程
对于一个类来说,他的生命周期是这样的:

我们此处前五个阶段是属于类加载的过程,所以我们只针对这五步进行描述:
(1)加载
把.class文件给找到,代码中需要加载某个类,就需要在特定的目录中找到这个.class文件,找到之后,就需要打开这个文件,并且进行读取文件,此时就把这些数据读到内存里了。
(2)验证
把刚才读到内存里的东西,进行一个校验,验证一下,刚才读到的内容是不是一个合法的.class文件,得是编译器生成的.class文件才能通过验证,如果是随便创建的一个文件,后缀名改为.class,这是不能通过验证的。除了验证文件格式,也会验证一下文件里面的一些字节码对不对(方法里面的具体要执行的命令)
(3)准备
为了类对象中的一些成员分配内存空间。(静态变量....),并且进行一个初步的初始化(把初始的空间设为全0)
(4)解析
针对字符串常量进行的处理,.class文件中就涉及到一些字符串常量,把这个类加载的过程中,就需要把这些字符串常量给替换成当前JVM内部已经持有的字符串常量的地址。
并非程序一启动,就立即把所有的类都给加载了,用到哪个类就加载哪个,而字符串常量池是最初启动JVM就有的(堆里)
(5)初始化
真正的对静态变量进行初始化,同时也会执行static代码块
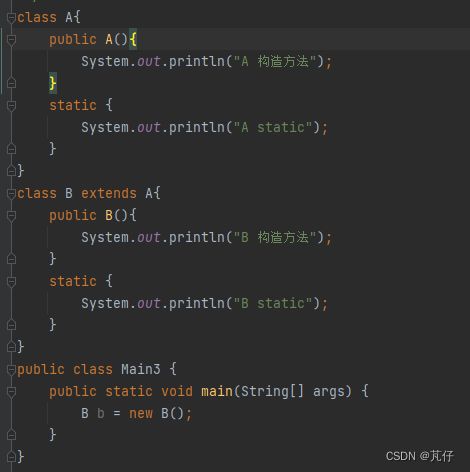
static变量的初始化以及static代码块的执行,是在对象的实例化之前的~
当new B()的时候,就先尝试加载B这个类,然后加载B这个类的时候发现,B继承自A,于是就又先去加载A,两个类加载完了,再进行这里的实例化操作~
总结:由父及子,静态先行~

2.类加载中的“双亲委派模型”
在JVM中,有三个类加载器(三个特殊的对象)来负责进行这里的找文件的操作
这三个类加载器对象各自有各自负责的区域

这三个类之间存在父子类关系(非继承里的父子类,而是类似于链表一样,每个类里面有个parent字段,指向了父类加载器)
当代码中用到某个类的时候,就会出发类加载:
先从AppClassLoader开始,但是AppClassLoader并不会真的开始去扫描自己负责的目录,而是先找他的爸爸,即ExtClassLoader,然后ExtClassLoader也不是立即去扫描自己负责的路径,而是也找他的爸爸,即BootStrap,BootStrap也不是立即扫描自己的路径,也想找自己的爸爸,但是他没爸爸呀,那么此时,只能自己开始干活,去自己负责的目录扫描,看是否含有其中的类,一般来说,BootStrap负责加载JAVA标准的一些类(String、ArrayList.....),如果找到了符合的类,就进行加载,就没有其他类的事儿了~如果找不到相匹配的类的话,就告诉儿子(ExtClassLoader),ExtClassLoader再来找自己负责的目录区域,一般来说,ExtClassLoader中放的是一些JVM扩展出来的类,平常很少用得到~如果还是没有找到,就告诉自己的儿子,也就是AppClassLoader,AppClassLoader再扫描自己的目录,一般是程序猿自己写的类或是引入的第三方库中的类,如果找到,就加载,还找不到,下面也没有自己的儿子,此时就抛出异常(ClassNotFoundException)
这个规则其实就是在约定上述三个被扫描目录的优先级,最高的是JRE/lib/rt.jar,其次是JRE/lib/ext/*.jar,最后是CLASSPATH指定的所有jar或目录~正常情况下,这个优先级并没有什么用,如果某个类的名字,重复出现在了多个目录中,这个时候,这个优先级就决定了最后加载的类到底是哪个~
五、垃圾回收(GC)
(1)什么是垃圾回收?
所谓垃圾回收,其实就是回收内存空间~JVM本质上是一个进程(Java),一个进程会持有很多的硬件资源(CPU、内存、硬盘、带宽资源....)系统的内存总量是一定的,程序在使用内存的时候,必须得先申请、再使用、后释放~由于内存是有限的,并且内存要同时供给给很多进程来使用,因此内存空间必须释放出来供其他进程来使用,不能持有一份内存不使用也不去释放~
从代码编写的角度来看,内存的申请时机是非常明确的,但是内存的释放时机,大多数情况下,可能并没有那么明确~此时就给内存的释放带来一些困难,典型的问题就是,这个内存后续我是否还需要继续使用?像C语言中的malloc出来的内存,不手动调用free,那么这个内存就会被一直持有,此时,内存的释放就全靠程序猿自己来控制,一旦程序猿忘记了,就很可能带来“内存泄漏”这样的问题。
什么是内存泄漏?
一直申请不释放,导致系统可用的内存资源越来越少,知道耗尽,此时其他进程再想申请资源,就申请不到了。
防止内存泄漏的措施有哪些:
①在C++中,采取的方案,智能指针,基于C++中的RAII机制,在合适的时机来自动释放内存(一般是通过引用计数的方式来衡量这个内存被调用了多少次,当引用计数为0的时候就真正释放内存)
②JAVA/Python/PHP/C#/Go更广泛采取的解决方案,就是我们所说的“垃圾回收机制”
对于手动回收内存来说,谁申请的,谁就释放。
对于垃圾回收机制来说,谁申请都行,有一个统一的人来负责释放(对于java来说,代码中的任何地方都可以申请内存,然后由JVM中统一的进行释放,具体来说,就是由JVM内部的一个专门负责垃圾回收的线程来进行这样的工作)
垃圾回收机制的优点:能够很好的保证不出现内存泄漏的情况(除非程序猿作死)
缺点:需要消耗额外的系统资源
内存的释放可能存在延时
可能导致出现STW问题(stop the world)
(2)java垃圾回收要回收的内存是哪些?
JVM中的内存有好几个区域
1.堆(垃圾回收机制的主要对象)
2.方法区(方法区里面是“类对象”,通过类加载过来的,对方法区进行垃圾回收,相当于是“类卸载”)
3.栈(内存都是和具体的线程绑定在一起的,这块的东西都是自己主动释放,代码块结束/线程结束,内存自动就释放了)
4.程序计数器
(3)回收堆上的内存,具体回收的是什么?
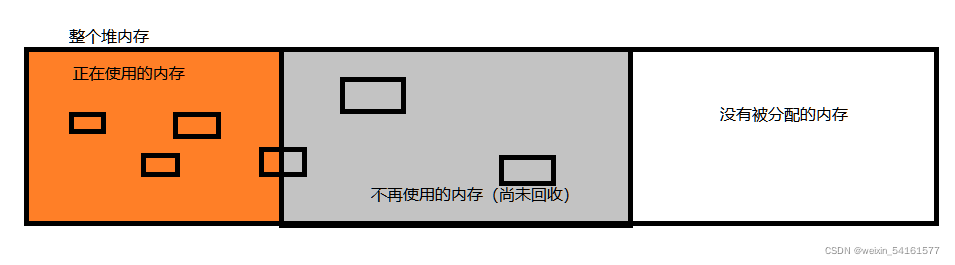
在堆上,是new出了很多对象,针对这些对象,分为三种:
1.完全要使用
2.完全不使用(需要被回收)
3.一半要使用,一般不使用(回收成本较大,实现起来较为麻烦,因此不回收)
Java中垃圾回收,是以“对象”为基本单位的,一个对象,要么被回收,要么不被回收,不会出现一个对象被回收一半的情况~
GC中的回收内存=>回收对象
(4)垃圾回收到底是咋回收的?
垃圾回收的基本思想:先找到垃圾,然后再回收垃圾~
(5)如何找垃圾/如何标记垃圾/如何判定垃圾?
抛开Java来说,单说GC的话,判定垃圾有两种典型的方案~
(a)引用计数
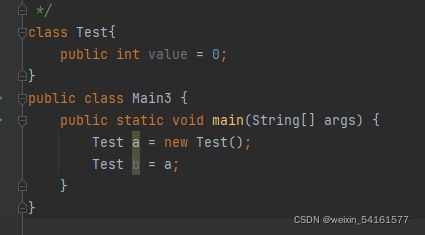
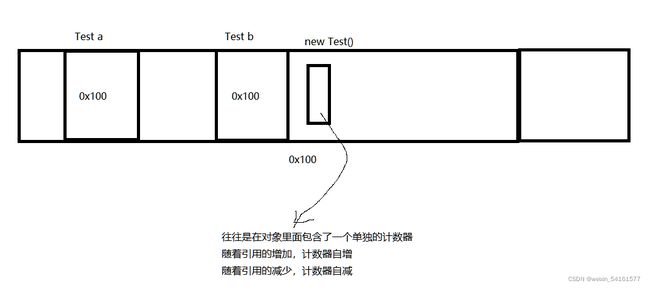
当前这个对象,有多少个引用在指向它~
此时就可以认为new Test()这个对象,有两个引用在指向它~
此时计数器的数字就为2~
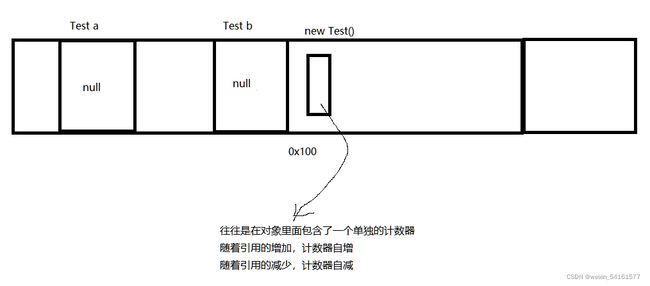
当:
a = null;
b = null;
此时内存图如下:
当两个对象都指向null的时候,然后这个对象就没有被引用被指向了,此时这个对象就认为是垃圾了(引用计数为0的时候,就认为是垃圾了)
(类似于JAVA这样的语言,引用是访问对象的唯一途径,因此如果没有引用了,就可以认为这个对象在代码中,再也无法被使用了)因此就可以通过引用是否存在,来判断对象的生死~~
引用计数的优缺点:
优点:规则简单,比较高效~
缺点:①空间利用率比较低(如果这个对象很大,在程序中的对象数目也不多,此时引用计数没啥问题,这个对象几M,在里面多加个int作为计数器都没啥负担;如果对象很小,程序中的对象数据也很多,此时引用计数会带来不可忽视的空间开销,一个对象4个字节,每个对象加int)②存在循环引用的问题(致命伤),特殊代码情况下,循环引用会导致代码的引用计数判断出错,从而无法回收
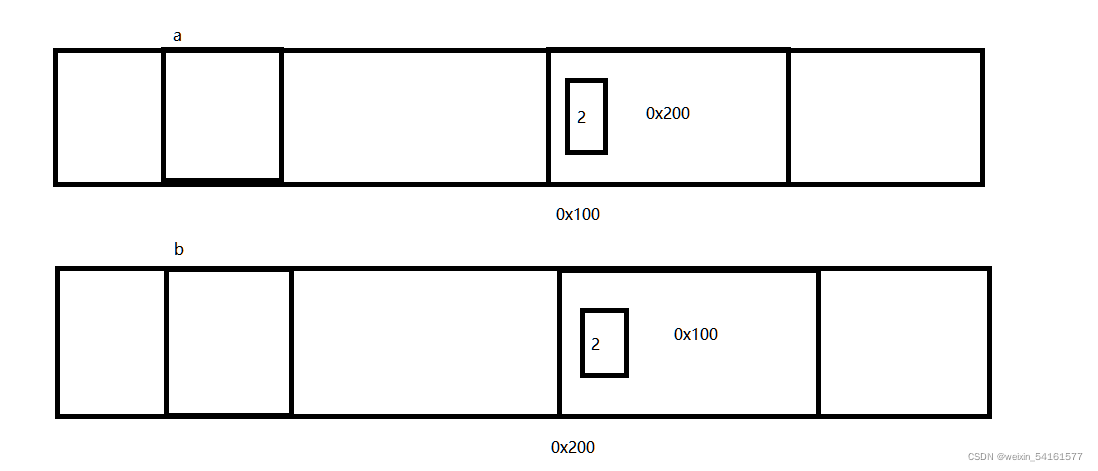
0x100被a指向,同时也被b.t所指向;0x200被b指向,同时也被a.t所指向。因此引用计数各自为2~
此时当我们执行如下操作:
a = null;
b = null;
这个操作其实是销毁了两个引用,但是引用计数只减少了1;(这个操作少了a,也少了a.t,没有a,就没法使用a.t)
由于上述缺点的存在,我们在Java中并没有采用引用计数这种方式来判定垃圾,而是采用第二种方式,可达性分析~

(b)可达性分析
从一组初始的位置出发(GCRoot),向下进行深度遍历,把所有能够访问到的对象都标记成“可达”(可以被访问到),对应的,不可达的对象,就是垃圾~

假设Root是一个方法中的局部变量
当前栈帧中的局部变量,也是进行可达性分析的一个初始位置~~从这里往下进行访问遍历
默认情况下,整棵树都是可达的,都不是垃圾,如果其中写了一个这样的代码:root.right.right = null;此时f这个节点就是不可达的,此时就可以被当做是垃圾进行回收了~如果写了这个代码:root.right=null;此时的c节点和f节点都是访问不到的(不可达的),此时c节点和f节点就会被当做垃圾进行回收了~
JVM中采用的方案,在JVM中就存在一个或者一组线程,来周期性的,进行上述的遍历过程,不但的找出这些不可达的对象,由JVM进行回收~
把可达性分析的初始从位置称为“GCRoot”:
1.栈上的局部变量表中的引用
2.常量池里面的引用指向的对象
3.方法区中,引用类型的静态成员变量
和引用计数相比,可达性分析,确实更加麻烦一点,同时实现可达性分析遍历过程也是开销比较大的(存在优化,稍后介绍)但是带来的好处就是解决了引用计数的两个缺点:内存上不需要消耗额外的空间,也没有循环引用的问题~
(6)具体怎么回收?
垃圾回收中的经典算法/策略~~
(a)标记-清除

白色代表正在使用的对象,灰色代表已经被释放的空间~
此时引入了额外的问题:内存碎片~
空闲的内存和正在使用的内存,是交替出现的,此时如果想要申请一块小的内存,那倒还没事~但是如果想要申请一块打的连续内存,此时就可能会分配失败~
由于内存碎片,假设整个系统内存空间100M,想申请50M的连续内存空间,仍然可能会分配失败
内存碎片问题,如果一直累计下去,就会导致,系统看起来空闲内存挺多,但实际上申请不了~
在“频繁申请释放”场景下,更加严重~
为了解决内存碎片,解决方案引入复制算法~
(b)复制算法
把整个内存分为两部分~~
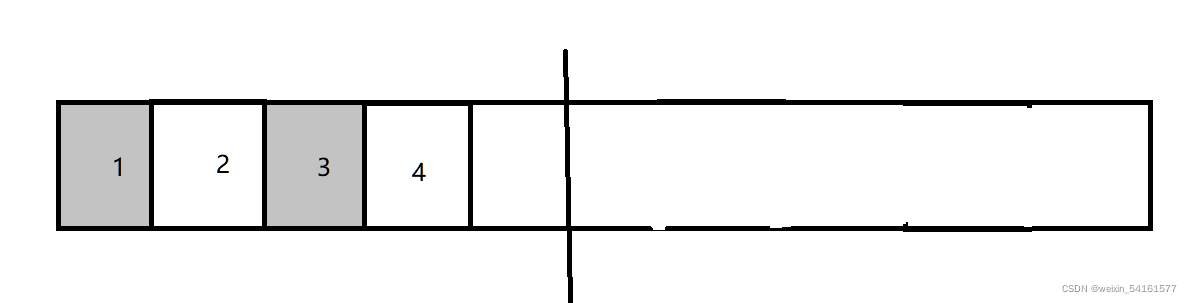
一次只使用一个部分,此时1和3要被回收了,于是就把剩下的2和4,拷贝到另外一侧,然后再回收这一整块空间
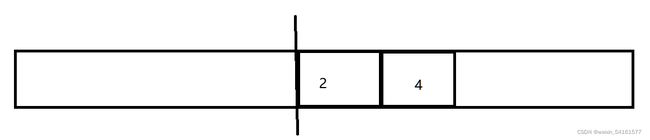
使用复制算法,就可以非常有效的避免出现内存碎片的问题~
复制算法的缺点:
1.可用的内存空间,只有一半~
2.如果要回收的对象比较少(剩下的对象比较多),复制的开销就很大了~
复制算法,适用于对象会被快速回收,并且整体内存不大的场景下~
(c)标记-整理
能够解决复制算法这里的内存空间利用率低的问题~
类似于“顺序表删除元素,搬运”

灰色代表要被回收的内存空间,白色代表仍要使用的内存空间
 这样的操作,就可以有效避免内存碎片,同时也能够提高空间利用率~
这样的操作,就可以有效避免内存碎片,同时也能够提高空间利用率~
缺点:在这个搬运过程中,也是一个很大的开销,这个开销要比复制算法里面复制对象的开销甚至更大
合并:分代回收~三合一,取长补短~
分代回收把内存中的对象分成了几个情况,每个情况下,采用不同的回收算法~
如何分代?根据对象的“年龄”来取进行划分~
在JVM中,进行垃圾回收扫描(可达性分析)也是周期性的~这个对象每次经历了一个扫描周期,就认为“长大一岁”,于是就根据这个对象的年龄,来对整个内存进行了分类,把年龄短的放在一起,年龄长的放在一起,不同年龄的对象,就可以采取不同的垃圾回收算法来进行处理~

分代回收过程:
1.一个新的对象,诞生于伊甸区(类似于HR收到简历)
2.如果活过一岁(对象经历了一轮GC还没死),就拷贝到生存区(类似于进入面试流程)
根据经验规律,伊甸区的对象,绝大部分都是活不过一岁,只有少数对象能给来到生存区,(朝生夕死)因此,生存区会比伊甸区小上一些~
3.在生存区中,对象也会经历若干轮GC,每一轮GC逃过的对象,都通过复制算法拷贝到另外一边的生存区里,这里面的对象来回拷贝,每一轮都会淘汰掉一波对象~(进入轮番面试,层层选拔淘汰)
4.在生存区的N论GC过后,这个对象仍然存活~此时JVM就会认为,这个对象未来会更持久的存活下去(经验规律,好比上战场打仗,小兵轮轮战役都存活,最终就会被这个小兵认为是兵王,提升至更高等级),于是就把这个对象拷贝到老年代~(拿到offer,入职成功)
5.进入老年代的对象,JVM都会认为是属于能持久存在的对象,这些对象也需要使用GC来扫描,但是扫描的频率就会大大降低,通常老年代这里使用标记整理算法~(类似于年终考核)
特殊情况:如果这个对象特别大,会直接进入老年代,因为这个大对象放在新生代,轮番拷贝的开销过大,甚至大道生存区放不下,因此直接放到老年代即可(类似于走后门)
(7)垃圾回收器
1.CMS(JDK1.7所主要使用的垃圾回收器),主要特点,尽可能的降低STW,标记-回收,先进行一个初步标记,(很快,但是会STW),接下来和业务线程并发的进行,深入的标记(不会STW),再进行一个重新标记(很快,但会STW),主要是对前面的标记结果进行简单修正~最后进行回收~
2.G1,把内存划分成了更多的小的区域(不像上面说的新生代老年代)以小区域为单位进行GC~