C++实现布隆过滤器
目录
一、什么是布隆过滤器
二、布隆过滤器的映射
三、布隆过滤器的作用
四、布隆过滤器的实现
五、总结+测试
一、什么是布隆过滤器
之前我们学习了位图,我们知道位图主要是实现了整形的映射bit位,这样可以大幅度的节省空间,那么针对于我们也经常用的string类型,或者其他类型,该如何去映射呢?
可以说string类的个数是无限的,无线个数去映射到有限的位置,那么必定会发生哈希冲突,这是无法避免的,我们有没有办法去减少这种哈希冲突呢?
大佬布隆就提出了布隆过滤器。(不是弗雷尔卓德之心)
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
二、布隆过滤器的映射
比如说,如下有三个string字符串,分别为sort,left,right,利用哈希的思想,我们可以将他们映射到相应的位置,这里跟位图一样,映射到了bit位,就算我们哈希函数设置得再好,也无法避免哈希冲突。
比如下面sort和left发生了哈希冲突,如果我现在先插入了sort,将该bit位置为了1,当我去查询left的时候,会发现left映射的bit位为1,我们就会以为left存在,实际上left并没有存在,这样就会导致误判的发生。

大佬布隆提出了一个思想,我可以给字符串使用更多的哈希函数,同时映射更多的位置, 这些位置相互验证,几个映射位置一同存在,这样会更具有可靠性(虽然他也还没完全解决可靠问题,也无法解决)
具体情况如下,sort映射到了5,16,18 ,left映射到5,11,13, right映射到16,20,26。
这样映射后,虽然浪费了一些空间,但就算某个映射发生重复了,也没关系,只要不是三个位置都冲突就没事,大大的降低了冲突概率。(也可以选择更多的映射,但同时也会浪费更多的空间)

三、布隆过滤器的作用
前面我们分析了那么多,感觉这个布隆过滤器没啥用啊,始终有概率发生冲突,是不是在实际中用不上啊,大家别急,我们先来分析一下布隆过滤器的可靠性问题。
- 如果该string不存在,那么该bit位还没被映射,证明确实不存在,这肯定是可靠的。
- 如果该string存在,他映射的位置都存在,这有可能是其他string映射到这里的,这会导致告诉我们的是虚假消息(本来不存在,你说存在),这是不可靠的。
即不存在一定可靠,存在可能是虚假消息。根据这点,我们来看下面的用例
我爱玩英雄联盟,在我们玩LOL之前,都需要取名,并且每一个区名字不可以重复,用户名这个数据一般都存放在服务器,如果每一个输入的名字,我们都要去服务器里面判断是否存在,再返回给用户,这样就会牵扯到网络相关知识,同时也会让服务器访问变多。
如果在客户端里面塞一个布隆过滤器,在服务器启动时,往布隆过滤器里添加用户名的映射关系,如果用户名不存在,是可靠的,那么我就告诉你,这个名字可以取。如果用户名映射关系告诉我们存在,这是不可靠的,他可能不存在,因此只要映射到存在,我们就去服务器再寻找一下,看能不看找到,结果再返回给用户。
这样既不会让客户端大很多,也不会让服务器承担很多,是不是一举两得。这也是为什么我们叫他过滤器的原因,他的作用是过滤。

四、布隆过滤器的实现
这里我们BloomFilter类模板参数N,和类型K,还有三个哈希函数类,变量_bs使用了库里面的bitset来构建。
set函数就是分别计算三个哈希函数的映射值,再用_bs.set()置为1,Test函数就是分别判断_bs.test()是否为true,有一个是false就会返回false(这是准确的),三个都为true才会返回true(这是不准的)。
#pragma once
#include
#include
template
class BloomFilter
{
public:
void Set(const K& key)
{
HashFunc1 kf1;
size_t hash1 = kf1(key) % N;
size_t hash2 = HashFunc2()(key) % N;
size_t hash3 = HashFunc3()(key) % N;
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}
bool Test(const K& key)
{
//false是准确的
size_t hash1 = HashFunc1()(key) % N;
if (_bs.test(hash1) == false)
return false;
size_t hash2 = HashFunc2()(key) % N;
if (_bs.test(hash2) == false)
return false;
size_t hash3 = HashFunc3()(key) % N;
if (_bs.test(hash3) == false)
return false;
//可能误判
return true;
}
private:
bitset _bs;
}; 一般K为string,我们就可以给他一个string的缺省值,至于三个哈希函数我们去大佬博客字符串哈希函数拷贝三个过来使用即可。
哈希函数如下
struct BKDRHash
{
size_t operator()(const string& key)
{
// BKDR
size_t hash = 0;
for (auto e : key)
{
hash *= 31;
hash += e;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++)
{
char ch = key[i];
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& key)
{
size_t hash = 5381;
for (auto ch : key)
{
hash += (hash << 5) + ch;
}
return hash;
}
};修改一下缺省值
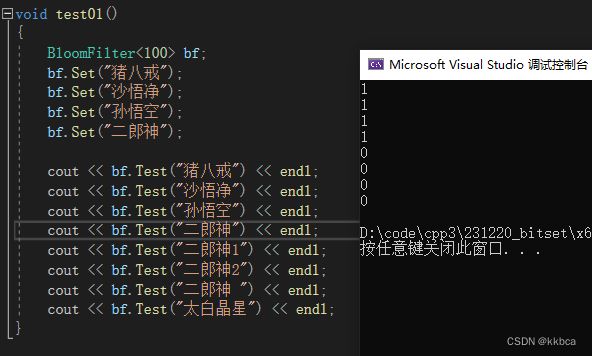
测试一下啊,运气还算不错,没有冲突
五、总结+测试
我们将将数据放大一下,看看冲突情况,这里我们开辟了十倍的空间,发现冲突还算比较小。

现在开辟了5倍的空间,发现冲突就变大了一些。
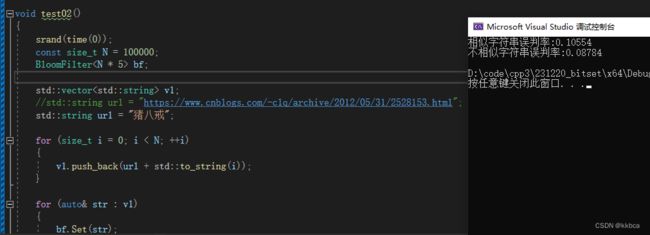
总结:适当的多开辟一些空间,会让误判率变得较小,足够多甚至可能会没有冲突,但同样也会浪费很多空间。但是这毕竟不算可靠,始终需要去数据库里再判断,因此适当开辟就好。
最后附上总代码BloomFilter.h
#pragma once
#include
#include
struct BKDRHash
{
size_t operator()(const string& key)
{
// BKDR
size_t hash = 0;
for (auto e : key)
{
hash *= 31;
hash += e;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++)
{
char ch = key[i];
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& key)
{
size_t hash = 5381;
for (auto ch : key)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template
class BloomFilter
{
public:
void Set(const K& key)
{
HashFunc1 kf1;
size_t hash1 = kf1(key) % N;
size_t hash2 = HashFunc2()(key) % N;
size_t hash3 = HashFunc3()(key) % N;
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}
bool Test(const K& key)
{
//false是准确的
size_t hash1 = HashFunc1()(key) % N;
if (_bs.test(hash1) == false)
return false;
size_t hash2 = HashFunc2()(key) % N;
if (_bs.test(hash2) == false)
return false;
size_t hash3 = HashFunc3()(key) % N;
if (_bs.test(hash3) == false)
return false;
//可能误判
return true;
}
private:
bitset _bs;
}; test.cpp
#include
using namespace std;
#include"BloomFilter.h"
void test01()
{
BloomFilter<100> bf;
bf.Set("猪八戒");
bf.Set("沙悟净");
bf.Set("孙悟空");
bf.Set("二郎神");
cout << bf.Test("猪八戒") << endl;
cout << bf.Test("沙悟净") << endl;
cout << bf.Test("孙悟空") << endl;
cout << bf.Test("二郎神") << endl;
cout << bf.Test("二郎神1") << endl;
cout << bf.Test("二郎神2") << endl;
cout << bf.Test("二郎神 ") << endl;
cout << bf.Test("太白晶星") << endl;
}
void test02()
{
srand(time(0));
const size_t N = 100000;
BloomFilter bf;
std::vector v1;
//std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
std::string url = "猪八戒";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}
for (auto& str : v1)
{
bf.Set(str);
}
// v2跟v1是相似字符串集(前缀一样),但是不一样
std::vector v2;
for (size_t i = 0; i < N; ++i)
{
std::string urlstr = url;
urlstr += std::to_string(9999999 + i);
v2.push_back(urlstr);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.Test(str)) // 误判
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集
std::vector v3;
for (size_t i = 0; i < N; ++i)
{
//string url = "zhihu.com";
string url = "孙悟空";
url += std::to_string(i + rand());
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.Test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}
int main()
{
//test01();
test02();
} 谢谢大家观看!