Hadoop 2.4 完全分布式环境安装与配置
依赖项
Java
1. 从http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html下载tar.gz格式的,32位和64位机器对应下载,这里下的是64位的
wget http://download.oracle.com/otn-pub/java/jdk/7u51-b13/jdk-7u51-linux-x64.tar.gz
2. 解压到/usr/local
tar -jxvf jdk-7u51-linux-x64.tar.gz -C /usr/local
3. 配置符号链接:cd /usr/local; ln -snf jdk1.7.0_45/ jdk
4. 配置环境变量到~/.bashrc
export JAVA_HOME="/usr/local/jdk"
export PATH="$JAVA_HOME/bin:$PATH"
5. 命令行下使用java、javax命令判断是否安装成功。
6. 在其他机器上
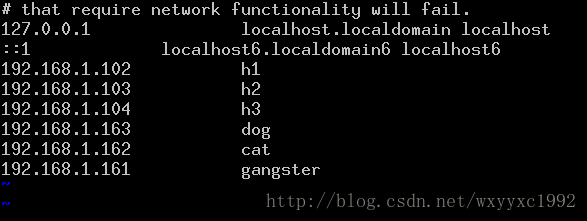
Hosts
所有的节点都修改/etc/hosts,使彼此之间都能把主机名解析为ip
SSH 无密码登陆
首先要配置本机的SSH服务器,运行 ps -e | grep ssh,查看是否有sshd进程,如果没有,说明server没启动,通过 /etc/init.d/ssh -start 启动server进程,如果提示ssh不存在 那么就是没安装server。Ubuntu下通过 sudo apt-get install openssh-server命令安装即可。
(1)生成当前用户的SSH公钥。
$ ssh-keygen -t rsa -P ''
它在/home/[你当前登录的用户名] 下生成.ssh目录(root用户即是在/root目录下),.ssh下有id_rsa和id_rsa.pub。id_rsa.pub即是本地SSH生成的公钥文件。客户端机器将id_rsa.pub文件添加到自己的~/.ssh/authorized_keys文件中即可免密码登录到本机。
(2)将~/.ssh/id_rsa.pub添加到目标机器的~/.ssh/authorized_keys文件中
- 如果是本机的操作,则使用
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
将要登录的机器的公钥添加到本地的认证密钥库中。注意这里必须要用>>操作符进行追加操作。
使用
ssh localhost
命令即可免密码登录到本地。
- 如果是将自己的公钥发送到别的机器上。
可以使用
scp ~/.ssh/id_rsa.pub [email protected]:.ssh/id_rsa.pub
这条scp命令进行文件上传操作。
安装Hadoop
下载Hadoop
最新版本hadoop-2.4.0安装包为 hadoop-2.4.0.tar.gz
下载官网地址 :http://www.apache.org/dyn/closer.cgi/hadoop/common/
下载到 /opt/hadoop/source 目录下
wget http://ftp.riken.jp/net/apache/hadoop/common/hadoop-2.4.0/hadoop-2.4.0.tar.gz
解压目录
tar zxvf hadoop-2.4.0.tar.gz
最终是这样子:
环境配置项
配置环境变量:
vim /etc/profile
添加
export HADOOP_DEV_HOME=/opt/hadoop/source
export PATH=$PATH:$HADOOP_DEV_HOME/bin
export PATH=$PATH:$HADOOP_DEV_HOME/sbin
export HADOOP_MAPARED_HOME=${HADOOP_DEV_HOME}
export HADOOP_COMMON_HOME=${HADOOP_DEV_HOME}
export HADOOP_HDFS_HOME=${HADOOP_DEV_HOME}
export YARN_HOME=${HADOOP_DEV_HOME}
export HADOOP_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
文件配置
配置之前,需要在Cluster文件系统创建以下文件夹,用于存放命名空间以及数据信息。
~/dfs/name
~/dfs/data
~/temp
这里要涉及到的配置文件有7个:
~/hadoop-2.4.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.4.0/etc/hadoop/yarn-env.sh
~/hadoop-2.4.0/etc/hadoop/slaves
~/hadoop-2.4.0/etc/hadoop/core-site.xml
~/hadoop-2.4.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.4.0/etc/hadoop/mapred-site.xml
~/hadoop-2.4.0/etc/hadoop/yarn-site.xml
以上个别文件默认不存在的,可以复制相应的template文件获得。
~/ect/hadoop/hadoop-env.sh 与 yarn-env.sh
原文件中设置Java环境:export JAVA_HOME=${JAVA_HOME},如果你环境变量中未配置JAVA_HOME,那么这里JAVA_HOME设置指向你的JAVA配置路径。
譬如:export JAVA_HOME="/usr/local/jdk"
~/etc/hadoop/slave
slaves (这个文件里面保存所有slave节点)
写入以下内容:
Slave1
Slave2
~/etc/hadoop/core-site.xml
在configuration节点里面添加属性
hadoop.tmp.dir
file:/opt/hadoop/hdfs/tmp
A base for other temporary directories.
io.file.buffer.size
131072
fs.default.name
hdfs://Master:9000
添加httpfs的选项
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
~/etc/hadoop/hdfs-site.xml
dfs.replication
3
dfs.namenode.name.dir
file:/opt/hadoop/hdfs/name
true
dfs.dataname.data.dir
file:/opt/hadoop/hdfs/data
true
dfs.namenode.secondary.http-address
Master:9001
dfs.webhdfs.enabled
true
~/etc/hadoop/yarn-site.xml
yarn.resourcemanager.address
Master:18040
yarn.resourcemanager.scheduler.address
Master:18030
yarn.resourcemanager.webapp.address
Master:18088
yarn.resourcemanager.resource-tracker.address
Master:18025
yarn.resourcemanager.admin.address
Master:18141
yarn.nodemanager.aux-services
mapreduce.shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
Hadoop 测试
HDFS
格式化NameNode
执行命令:hadoop namenode -format,可以格式化NameNode。
l 可能错误:出现未知的主机名问题。
java.net.UnknownHostException: localhost.localdomain: localhost.localdomain
at java.net.InetAddress.getLocalHost(InetAddress.java:1353)
at org.apache.hadoop.metrics.MetricsUtil.getHostName(MetricsUtil.java:91)
at org.apache.hadoop.metrics.MetricsUtil.createRecord(MetricsUtil.java:80)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.initialize(FSDirectory.java:73)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:853)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:947)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:964)
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at java.net.UnknownHostException: localhost.localdomain: localhost.localdomain
************************************************************/
使用hostname命令,可以发现当前的主机名为hadoop_master(Ubuntu系统下在/etc/hostname,Centos系统在 /etc/sysconfig/network文件中设置),而hosts文件中信息如下:
127.0.0.1 localhost
127.0.1.1 ubuntu
192.168.198.133 Master
192.168.198.134 Slave1
即无法解析hadoop_master的信息,将hosts文件信息改为如下:
127.0.0.1 hadoop_master
127.0.1.1 ubuntu
192.168.198.133 Master
192.168.198.134 Slave1
Hadoop集群
启动集群
~/sbin/start-all.sh 启动Hadoop集群,最好使用~/sbin/start-dfs.sh与~/sbin/start-yarn.sh来代替。
若正常启动:
NameNode上使用jps查询会显示如下:
DataNode上使用jps查询会显示如下:
.1 64位平台不兼容错误
Starting namenodes on [Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /opt/hadoop/source/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
在/etc/profile 或者 ~/.bash_profile中添加:
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_DEV_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_DEV_HOME/lib"
Command Lines
Hadoop
* start-all.sh 启动所有的Hadoop守护。包括namenode, datanode, jobtracker, tasktrack
* stop-all.sh 停止所有的Hadoop
* start-mapred.sh 启动Map/Reduce守护。包括Jobtracker和Tasktrack
* stop-mapred.sh 停止Map/Reduce守护
* start-dfs.sh 启动Hadoop DFS守护Namenode和Datanode
* stop-dfs.sh 停止DFS守护
HDFS
1. 查看文件列表
查看hdfs中/user/admin/hdfs目录下的文件。
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -ls /user/admin/hdfs
查看hdfs中/user/admin/hdfs目录下的所有文件(包括子目录下的文件)。
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -lsr /user/admin/hdfs
2. 创建文件目录
查看hdfs中/user/admin/hdfs目录下再新建一个叫做newDir的新目录。
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -mkdir /user/admin/hdfs/newDir
3. 删除文件
删除hdfs中/user/admin/hdfs目录下一个名叫needDelete的文件
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -rm /user/admin/hdfs/needDelete
删除hdfs中/user/admin/hdfs目录以及该目录下的所有文件
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -rmr /user/admin/hdfs
4. 上传文件
上传一个本机/home/admin/newFile的文件到hdfs中/user/admin/hdfs目录下
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs–put /home/admin/newFile /user/admin/hdfs/
5. 下载文件
下载hdfs中/user/admin/hdfs目录下的newFile文件到本机/home/admin/newFile中
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs –get /user/admin/hdfs/newFile /home/admin/newFile
6. 查看文件内容
查看hdfs中/user/admin/hdfs目录下的newFile文件
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs–cat /home/admin/newFile
配置文件详解
Core
hadoop-env.sh
记录脚本要用的环境变量,以运行hadoop。
文件位于~/hadoop/etc/hadoop/core-site.xml目录下。
# 设置JDK的位置
export JAVA_HOME=${JAVA_HOME}
如果你的环境变量中没有设置JAVA_HOME,这里即可设置为:
exportJAVA_HOME=/home/java/jdk/jdk1.7.0_51
另外,鉴于Hadoop默认的是32位系统,还需要加上64位支持:
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_DEV_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_DEV_HOME/lib"
core-site.xml
该文件是 hadoop core的配置项,例如hdfs和mapreduce常用的i/o设置等,位于~/hadoop/etc/hadoop/core-site.xml目录下。
| 属性 |
值 |
说明 |
| fs.default.name |
hdfs://master:9000 |
定义master的URI和端口 |
| fs.checkpoint.dir |
${hadoop.tmp.dir}(默认) |
SNN的元数据以,号隔开,hdfs会把元数据冗余复制到这些目录,一般这些目录是不同的块设备,不存在的目录会被忽略掉 |
| fs.checkpoint.period |
1800 |
定义ND的备份间隔时间,秒为单位,只对SNN效,默认一小时 |
| fs.checkpoint.size |
33554432 |
以日志大小间隔做备份间隔,只对SNN生效,默认64M |
| fs.checkpoint.edits.dir |
${fs.checkpoint.dir}(默认) |
SNN的事务文件存储的目录,以,号隔开,hdfs会把事务文件冗余复制到这些目录 |
| fs.trash.interval |
10800 |
HDFS垃圾箱设置,可以恢复误删除,分钟数,0为禁用,添加该项无需重启hadoop |
| hadoop.tmp.dir |
/tmp/hadoop |
临时文件夹,指定后需将使用到的所有子级文件夹都要手动创建出来,否则无法正常启动服务。 |
| hadoop.http.filter.initializers |
org.apache.hadoop.security. |
需要jobtracker,tasktracker |
| hadoop.http.authentication.type |
simple | kerberos | #AUTHENTICATION_HANDLER_CLASSNAME# |
验证方式,默认为简单,也可自己定义class,需配置所有节点 |
| hadoop.http.authentication.token.validity |
36000 |
验证令牌的有效时间,需配置所有节点 |
| hadoop.http.authentication.signature.secret |
默认可不写参数 |
默认不写在hadoop启动时自动生成私密签名,需配置所有节点 |
| hadoop.http.authentication.cookie.domain |
domian.tld |
http验证所使用的cookie的域名,IP地址访问则该项无效,必须给所有节点都配置域名才可以。 |
| hadoop.http.authentication. simple.anonymous.allowed |
true | false |
简单验证专用,默认允许匿名访问,true |
| hadoop.http.authentication.kerberos.principal |
HTTP/localhost@$LOCALHOST |
Kerberos验证专用,参加认证的实体机必须使用HTTP作为K的Name |
| hadoop.http.authentication.kerberos.keytab |
/home/xianglei/hadoop.keytab |
Kerberos验证专用,密钥文件存放位置 |
| hadoop.security.authorization |
true|false |
Hadoop服务层级验证安全验证,需配合hadoop-policy.xml使用,配置好以后用dfsadmin,mradmin -refreshServiceAcl刷新生效 |
| hadoop.security.authentication |
simple | kerberos |
hadoop本身的权限验证,非http访问,simple或者kerberos |
| hadoop.logfile.size |
1000000000 |
设置日志文件大小,超过则滚动新日志 |
| hadoop.logfile.count |
20 |
最大日志数 |
| io.bytes.per.checksum |
1024 |
每校验码所校验的字节数,不要大于io.file.buffer.size |
| io.skip.checksum.errors |
true | false |
处理序列化文件时跳过校验码错误,不抛异常。默认false |
| io.serializations |
org.apache.hadoop.io.serializer.WritableSerialization |
序列化的编解码器 |
| io.seqfile.compress.blocksize |
1024000 |
块压缩的序列化文件的最小块大小,字节 |
| io.compression.codecs |
org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.SnappyCodec |
Hadoop所使用的编解码器,gzip、bzip2为自带,lzo需安装hadoopgpl或者kevinweil,逗号分隔。 |
| io.compression.codec.lzo.class |
com.hadoop.compression.lzo.LzoCodec |
LZO所使用的压缩编码器 |
| io.file.buffer.size |
131072 |
用作序列化文件处理时读写buffer的大小 |
| webinterface.private.actions |
true | false |
设为true,则JT和NN的tracker网页会出现杀任务删文件等操作连接,默认是false |
| topology.script.file.name |
/hadoop/bin/RackAware.py |
机架感知脚本位置 |
| topology.script.number.args |
1000 |
机架感知脚本管理的主机数, |
xml version="1.0"?>
xml-stylesheet type="text/xsl" href="http://wsysisibeibei.blog.163.com/blog/configuration.xsl"?>
这里配置的是HDFS的地址和端口号。
Node
HDFS
hdfs-site.xml
hadoop守护进程的配置项,包括namenode、辅助namenode和datanode等。
该文件位于~/hadoop/etc/hadoop/目录下。
xml version="1.0"?>
xml-stylesheet type="text/xsl" href="http://wsysisibeibei.blog.163.com/blog/configuration.xsl"?>
If "true", enable permission checking in HDFS. If "false", permission checking is turned off, but all other behavior is unchanged. Switching from one parameter value to the other does not change the mode, owner or group of files or directories
在Hadoop中HDFS的默认备份方式为3,这里将其改为1。
Map/Reduce
mapred-site.xml
mapreduce守护进程的配置项,包括jobtracker和tasktracker。
xml version="1.0"?>
xml-stylesheet type="text/xsl" href="http://wsysisibeibei.blog.163.com/blog/configuration.xsl"?>