python采集电影数据JS逆向, 并制作可视化
嗨喽~大家好呀,这里是魔王呐 ❤ ~!
python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取
环境使用:
-
Python 3.10
-
Pycharm
-
nodejs
模块使用:
-
requests -> pip install requests
-
execjs -> pip install pyexecjs
-
json
-
csv
模块安装:
win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安装速度比较慢, 你可以切换国内镜像源)
实现爬虫流程:
一. 数据来源分析
1. 明确需求: 明确采集的网址以及数据内容
- 网址: https://www.endata.com.cn/BoxOffice/BO/Year/index.html
- 数据: 电影数据
2. 抓包分析: 通过开发者工具(浏览器自带)进行分析
- 打开开发者工具: F12 / 右键点击检查选择network (网络)
- 选择任意年份: 让它加载对应的数据内容
查看返回的数据内容:
请求网址: https://www.endata.com.cn/API/GetData.ashx
请求方式: POST (需要向服务器提交表单数据)
请求头: (是否有加密参数)
请求参数:
year: 2023
MethodName: BoxOffice_GetYearInfoData
响应数据:
密文内容 (加密内容)
- 对于加密的数据, 进行解密
分析加密规则, 如何解密 (查看启动器)
断点目的: 刷新网页 / 翻页时候, 网页运行到这个地方可以暂停住
传入了什么参数, 返回了什么内容
二. 代码实现步骤
1. 发送请求 -> 模拟浏览器对于url地址发送请求
2. 获取数据 -> 获取服务器返回响应数据
获取密文数据 -> 解密
3. 解析数据 -> 提取我们数据内容
4. 保存数据 -> 保存数据
数据采集
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
# 导入数据请求模块: 需要安装 pip install requests
import requests
# 需要安装 pip install pyexecjs
import execjs
# 导入json模块
import json
# 导入csv模块
import csv
“”“保存数据”“”
# 创建文件对象
csv_file = open('data.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(csv_file, fieldnames=[
'影片名称',
'类型',
'总票房',
'平均票价',
'场均人次',
'国家地区',
'上映时间',
])
csv_writer.writeheader()
“”“1. 发送请求 -> 模拟浏览器对于url地址发送请求”“”
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
# 模拟浏览器
headers = {
# User-Agent 用户代理 表示浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
for year in range(2008, 2024):
# 请求网址
url = 'https://www.endata.com.cn/API/GetData.ashx'
# 请求参数
data = {
'year': year,
'MethodName': 'BoxOffice_GetYearInfoData'
}
# 发送请求
response = requests.post(url=url, data=data, headers=headers)
“”“2. 获取数据 -> 获取服务器返回响应数据”“”
content = response.text
print('密文数据: ', content) # 查看是否得到数据内容
"""解密数据
- 通过JS代码变成明文数据 (分析解密数据代码位置)
- 通过python代码调用js代码
"""
# 读取js代码
f = open('demo.js', encoding='utf-8').read()
# 编译js代码
js_code = execjs.compile(f)
# 调用js代码函数
res = js_code.call('get_content', content)
# 转成字典数据
json_data = json.loads(res)
print('明文数据: ', res)
print(json_data)
“”“3. 解析数据 -> 提取我们数据内容”“”
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
Table = json_data['Data']['Table']
# for 循环遍历, 提取列表元素
for index in Table:
# 把数据保存到字典里面
dit = {
'影片名称': index['MovieName'],
'类型': index['Genre_Main'],
'总票房': index['BoxOffice'],
'平均票价': index['AvgPrice'],
'场均人次': index['AvgPeoPle'],
'国家地区': index['Area'],
'上映时间': index['ReleaseTime'],
}
# 写入数据
csv_writer.writerow(dit)
print(dit)
数据可视化
# 需要安装 pip install pandas
import pandas as pd
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
# 读取文件
df = pd.read_csv('data.csv')
# 显示前5行数据
df.head()
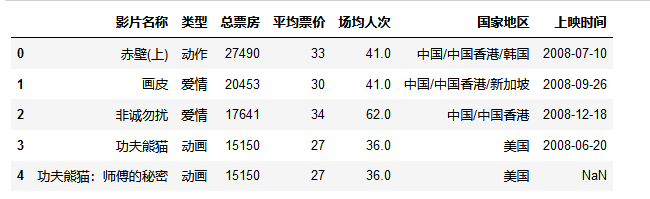
可以直接通过pyechrats 官文文档 实现可视化分析
https://gallery.pyecharts.org/#/README
info = df['类型'].value_counts().index.to_list() # x轴的数据
num = df['类型'].value_counts().to_list() # y轴的数据
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
info,
num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(title="2008-2023年部分电影类型分布"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# 把可视化图保存成html文件
# .render("2008-2023年部分电影类型分布(饼图).html")
)
c.load_javascript()
c.render_notebook()
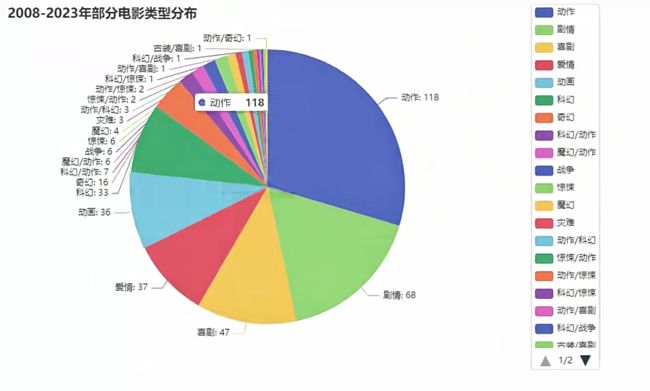
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
info = df['国家地区'].value_counts().index.to_list() # x轴的数据
num = df['国家地区'].value_counts().to_list() # y轴的数据
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
info,
num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(title="2008-2023年部分电影国家地区分布"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# 把可视化图保存成html文件
# .render("2008-2023年部分电影类型分布(饼图).html")
)
c.render_notebook()
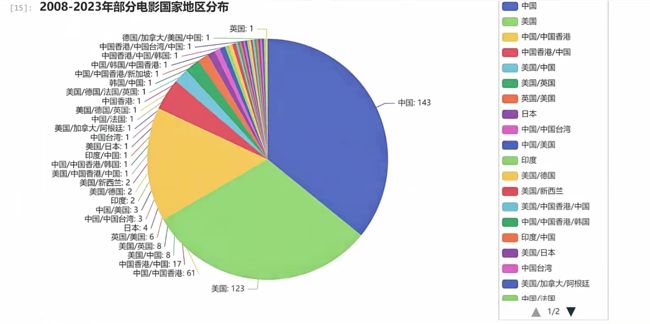
df.head()

Top = df[['影片名称', '总票房']].sort_values('总票房')[-10:]
name = list(Top['影片名称'])
num = list(Top['总票房'])
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
from pyecharts import options as opts
from pyecharts.charts import Bar
c = (
Bar()
.add_xaxis(name)
.add_yaxis("", num)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="2008-2023年部分电影总票房Top10分布", subtitle=""),
)
# .render("bar_rotate_xaxis_label.html")
)
c.render_notebook()
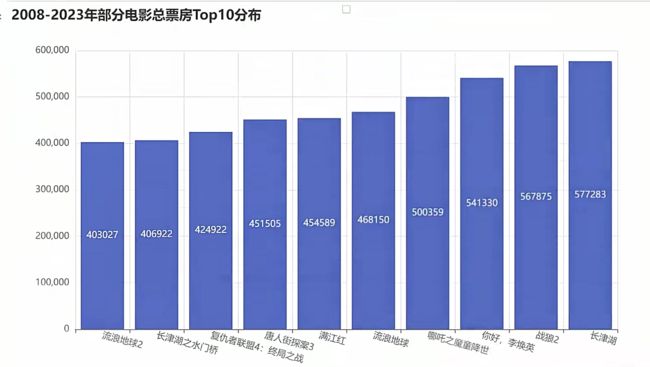
尾语
最后感谢你观看我的文章呐~本次航班到这里就结束啦
希望本篇文章有对你带来帮助 ,有学习到一点知识~
躲起来的星星也在努力发光,你也要努力加油(让我们一起努力叭)。
最后,宣传一下呀~更多源码、资料、素材、解答、交流皆点击下方名片获取呀