数据分析从MySQL开始(Python)(十四、爬虫四十天天气、MongoDB、Excel)
(源网页:http://www.weather.com.cn/ 中国天气网, js提取,由于工作需要爬取四十天温度预测和十五天天气预报并保存到Excel)
(中国天气网也有十五天天气预测但是不够准确,所以之后选了百度天气十五天预测,这里不放出百度天气的数据提(爬)取(虫))
(插入两种数据库,mongoDB、mysql)(有需要的话以后再介绍插入 mysql 的代码)
目录
准备:
第一部分:字典 插入 MongoDB(mysql)
目标网页
参数介绍
request 函数、请求头说明
parse函数、返回request函数
计算四十天日期
获取地区以及地区代号
save() 将字典保存到MongoDB数据库
第二部分:全部源码
注:
四十天天气成果图:
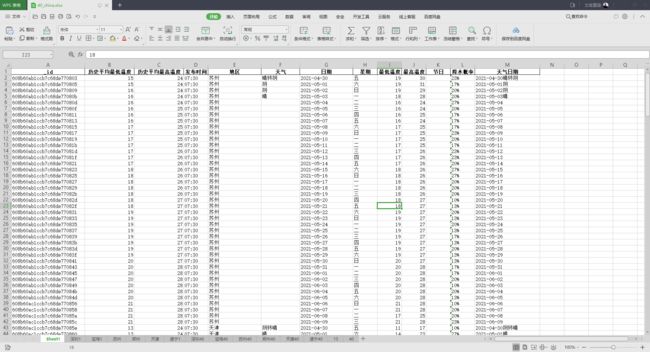
准备:
城市和城市代码;太多了,这里只拿六个测试一下;我上传资源站吧,网上很多自己找也行(正在审核,通过了给链接)
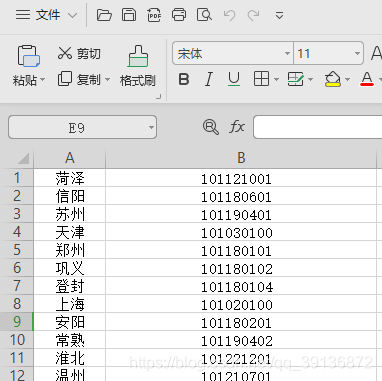
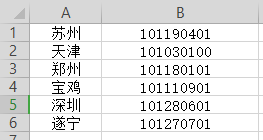
第一部分:字典 插入 MongoDB(mysql)
说明:
1、以天气预报作为参考,并不参与主要数据分析工作,因此采用原代码的方式插入mongoDB数据库(从网上找的源代码进行了关键字等修改)
2、然后需要从数据库中保存一份Excel做透视图就用到了mongoDB导出到Excel
参考博文:
天气:https://blog.csdn.net/python233/article/details/72824964
mongoDB导出:https://www.cnblogs.com/loaderman/p/12056767.html
-
目标网页
http://d1.weather.com.cn/calendar_new/2021/101190401_202104.html ;
网页结构:2021(年份)、101190401(地区代号)、202104(年月);(颜色对应)
网页内容:下表(网页截图,有点乱码,结果不会出现这种问题)
-
参数介绍
subkey = {'date': '日期', 'max': '最高温度', 'min': '最低温度', 'w1': '天气', 'hgl': '降水概率', 'fe': '节日', 'wk': '星期', 'time': '发布时间', 'hmax': '历史平均最高温度', 'hmin': '历史平均最低温度'}
-
request 函数、请求头说明
可以直接用也没问题,谷歌浏览器为例,右键检查,network,网页刷新一下,会出来很多,点击选中一个,可以在右侧中出现的 Request Headers 中替换 "User-Agent"
def request(year, month, codenum):
url = "http://d1.weather.com.cn/calendar_new/" + year + "/{}_".format(codenum) + year + month + ".html"
print('url:', url)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"Referer": "http://www.weather.com.cn/weather40d/{}.shtml".format(codenum),
}
return requests.get(url, headers=headers)
-
parse函数、返回request函数
将上面 request() 返回值变成字典
def parse(res):
json_str = res.content.decode(encoding='utf-8')[11:]
return json.loads(json_str)-
计算四十天日期
今天日期和四十天后日期
def date_now():
today = datetime.datetime.now()
return today
def date_40(today):
need_time = today + datetime.timedelta(days=+40)
re_date = need_time.strftime('%Y-%m-%d')
return re_date-
获取地区以及地区代号
根据地区代号代入 request() 函数 codenum 参数
df = pandas.read_excel(r"six_location.xlsx", engine='openpyxl', header=None) # 六个测试地区 为了方便写在了全局
max_row = df.shape[0]
print("表格地区数:", max_row)
def messcol_2(num_row, num_col): # 获取第num_col列单元格内容,来自地区和地区代号表
cell = df.loc[[num_row], [num_col]]
cells = np.array(cell)
cell_message = cells.tolist()
mess = cell_message[0][0]
return mess-
save() 将字典保存到MongoDB数据库
不想用数据库的直接在 save() 函数里遍历字典 list 的时候将 字典插入数据库 改成 字典插入表格就行,( list 内容也就是主函数 par)
这部分需要结合主函数一起看
主函数——创建并连接MongoDB数据库 test
主函数——删 forecast_weather 表重建(因为每天网站都会更新,本地也要更新,感觉删表重建比更新表更合适)
client = pymongo.MongoClient('localhost', 27017) # 连接mongodb,端口27017
test = client['test'] # 创建数据库文件test
collist = test.list_collection_names() # 获取mongoDB所有集合
print(collist)
if "forecast_weather" in collist:
print("数据表已存在!")
forecast = test['forecast_weather']
forecast.drop() # 存在则删表
forecast = test['forecast_weather'] # 创建表forecast主函数——从MongoDB导出到 data 表格
data = pandas.DataFrame(list(forecast.find()))
data.to_excel('data.xlsx', encoding='utf-8', index=False)save() 函数,字典中有些记录没有 最高温度 和 最低温度 的数据,这里用 历史平均温度 代替
def save(list, local):
subkey = {'date': '日期', 'max': '最高温度', 'min': '最低温度', 'w1': '天气', 'hgl': '降水概率', 'fe': '节日', 'wk': '星期', 'time': '发布时间',
'hmax': '历史平均最高温度', 'hmin': '历史平均最低温度'}
for dict in list:
subdict = {value: dict[key] for key, value in subkey.items()} # 提取原字典中部分键值对,并替换key为中文
if subdict['最高温度'] == '' or subdict['最低温度'] == '':
subdict['最高温度'] = subdict['历史平均最高温度']
subdict['最低温度'] = subdict['历史平均最低温度']
subdict["地区"] = local
date1 = subdict["日期"]
date2 = dateutil.parser.parse(date1)
date3 = date2.strftime('%Y-%m-%d')
today = date_now()
today2 = today.strftime('%Y-%m-%d')
re_date = date_40(today)
subdict["日期"] = date3
if (date3 >= today2) and (date3 <= re_date): # today2 今天 re_date 40天后
forecast.update_one(subdict, {'$setOnInsert': subdict}, True) # 可以改成字典插入表格
第二部分:全部源码
本地安装了 mangoDB 和 城市代码表格 的话可以直接复制了跑代码
import datetime
import pandas
import requests
import json
import pymongo
import numpy as np
import dateutil.parser
def request(year, month, codenum):
url = "http://d1.weather.com.cn/calendar_new/" + year + "/{}_".format(codenum) + year + month + ".html"
print('url:', url)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"Referer": "http://www.weather.com.cn/weather40d/{}.shtml".format(codenum),
}
return requests.get(url, headers=headers)
def parse(res):
json_str = res.content.decode(encoding='utf-8')[11:]
return json.loads(json_str)
def date_now():
today = datetime.datetime.now()
return today
def date_40(today):
need_time = today + datetime.timedelta(days=+40)
re_date = need_time.strftime('%Y-%m-%d')
return re_date
def save(list, local):
subkey = {'date': '日期', 'max': '最高温度', 'min': '最低温度', 'w1': '天气', 'hgl': '降水概率', 'fe': '节日', 'wk': '星期', 'time': '发布时间',
'hmax': '历史平均最高温度', 'hmin': '历史平均最低温度'}
for dict in list:
subdict = {value: dict[key] for key, value in subkey.items()} # 提取原字典中部分键值对,并替换key为中文
if subdict['最高温度'] == '' or subdict['最低温度'] == '':
subdict['最高温度'] = subdict['历史平均最高温度']
subdict['最低温度'] = subdict['历史平均最低温度']
subdict["地区"] = local
date1 = subdict["日期"]
date2 = dateutil.parser.parse(date1)
date3 = date2.strftime('%Y-%m-%d')
today = date_now()
today2 = today.strftime('%Y-%m-%d')
re_date = date_40(today)
subdict["日期"] = date3
if (date3 >= today2) and (date3 <= re_date): # today2 今天 re_date 40天后
forecast.update_one(subdict, {'$setOnInsert': subdict}, True)
df = pandas.read_excel(r"ab1.xlsx", engine='openpyxl', header=None)
max_row = df.shape[0]
print("表格地区数:", max_row)
def messcol_2(num_row, num_col): # 获取第num_col列单元格内容,来自地区和地区代号表
cell = df.loc[[num_row], [num_col]]
cells = np.array(cell)
cell_message = cells.tolist()
mess = cell_message[0][0]
return mess
if __name__ == '__main__':
year = "2021"
month = 4
client = pymongo.MongoClient('localhost', 27017) # 连接mongodb,端口27017
test = client['test'] # 创建数据库文件test
collist = test.list_collection_names() # 获取mongoDB所有集合
print(collist)
if "forecast_weather" in collist:
print("数据表已存在!")
forecast = test['forecast_weather']
forecast.drop()
forecast = test['forecast_weather'] # 创建表forecast
for i in range(0, max_row):
mess_url = messcol_2(i, 1) # 获取第2列单元格内容--代号
url = str(mess_url)
mess_local = messcol_2(i, 0) # 获取第1列单元格内容--地区 用于插入新表
local = str(mess_local)
print("地区", local, "代号:", url)
j = month
for j in range(month, 6):
n = j
months = str(n) if n > 9 else "0" + str(n) # 小于10的月份要补0
par = parse(request(year, months, url)) # 包含天气的字典
save(par, local)
data = pandas.DataFrame(list(forecast.find()))
data.to_excel('data.xlsx', encoding='utf-8', index=False)注:
- 这里我取了中国天气网的十几个数据(有需要的话可以在subkey参数部分扩充),但是在实际中的 十五天天气预测 不准确,甚至还出现了天气预测不足十五天的情况,所以只参考了它预测的四十天温度(表格数据是完整的,只是参考了其中的一部分)
- 为了十五天天气情况预测的准确,我换用了百度天气网的十五天天气预测,四十天温度预测仍然是使用的中国天气网的数据