TDengine(一)TDengine可视化操作界面TDengineGUI安装及基本操作
文章目录
-
-
- 一、服务安装
- 二、基本操作
-
- 1、创建用户
- 2、修改用户密码
- 3、登录数据库
- 4、库操作
-
- (1)创建库(如果不存在)
- (2)使用库
- (3)删除库(如果存在)
- (4)显示所有数据库
- (5)修改数据库文件压缩标志位
- (6)修改数据库副本数
- (7)修改数据文件保存的天数
- (8)修改数据写入成功所需要的确认数
- (9)修改每个VNODE (TSDB) 中有多少cache大小的内存块
- 5、表操作
-
- (1)超级表操作
-
- a、创建超级表
- b、查看超级表
- c、删除超级表
- d、修改超级表
- e、超级表查询
- (2)子表操作
-
- a、创建普通表:
- b、根据超级表创建子表
- c、 删除数据表
- d、 显示当前数据库下的所有数据表信息
- e、 获取表的结构信息
- f、 表增加列
- g、 表删除列
- 三、安装可视化界面 TDengineGUI
- 四、超级表、表(也叫子表)及Tag的关系
-
- 1、超级表定义
- 2、表(也叫子表)定义
- 3、举个例子
-
- (1)创建电表超级表:super_dianbiao
- (2)创建子表dianbiao……
- (3)往子表中插入数据
- (4)使用TDengineGUI看看直观的效果
- 总结
-
一、服务安装
最近公司在启用TDengine作为实时数据的存储数据库,目前这个数据库的使用方式,我还不是很熟悉,特此记录和总结一些使用技巧。
官方文档地址,按照文档描述,安装整体还是比较简单的,本文就不介绍安装过程了,附上官方地址:
https://docs.taosdata.com/get-started/package/
需要启动 taosd 和 taosadapter两个服务。
- taosd 是TDengine 服务,这个服务必须启动(默认端口 6030);
- taosadapter 是 TDengine restful服务(默认为6041),连接服务器的用户名和密码(默认为root:taosdata)。
二、基本操作
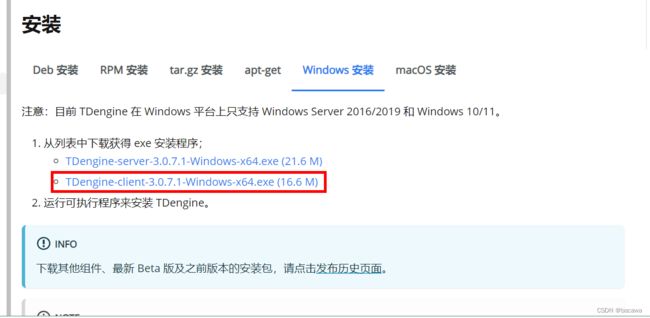
这里使用windows环境下 Taos Shell 工具进行测试,需要安装TDengine-client软件,如下图所示:
1、创建用户
create user `用户名` pass `密码`;
如:
create user myuser pass "123456";
2、修改用户密码
taos 数据库 root用户的默认密码为: taosdata,安装好taos数据库后,可以通过下语句修改密码。
alter user root pass `yourpassword`
如:
alter user root pass '123456';
3、登录数据库
taos -uroot -p密码
如:
taos -uroot -p123456 ;
4、库操作
(1)创建库(如果不存在)
keep 字段是指文件在表存储的时间,默认是天。
create database if not exists 库名 keep n days m blocks k;
#如:
create database if not exists mydb keep 365 days 10 blocks 4;
(2)使用库
use 库名;
#如:
use mydb;
(3)删除库(如果存在)
drop database [if exists] 库名;
#如:
drop database [if exists] mydb;
(4)显示所有数据库
show databases;
(5)修改数据库文件压缩标志位
alter database 库名 comp 位数;
#如:
alter database mydb comp 2;
(6)修改数据库副本数
alter database 库名 replica 数量;
#如:
alter database mydb replica 2;
(7)修改数据文件保存的天数
alter database 库名 keep 天数;
#如:
alter database mydb keep 35;
(8)修改数据写入成功所需要的确认数
alter database 库名 quorum 数目;
#如:
alter database mydb quorum 2;
(9)修改每个VNODE (TSDB) 中有多少cache大小的内存块
alter database 库名 blocks 大小;
#如:
alter database mydb blocks 100;
5、表操作
先说明语法格式,后续会统一说明超级表,子表以及Tag的关系,统一建表进行操作展示。
(1)超级表操作
a、创建超级表
创建STable, 与创建表的SQL语法相似,但需指定TAGS字段的名称和类型。说明:
- TAGS 列的数据类型不能是timestamp类型;
- TAGS 列名不能与其他列名相同;
- TAGS 列名不能为预留关键字;
- TAGS 最多允许128个,可以0个,总长度不超过16k个字符。
create stable [if not exists] stb_name (time timestamp,column_name int ...) tags (column_name1 dataType,column_name2 dataType,....)
#如
create stable if not exists st(time timestamp, column_name int) tags (t1 nchar(50), t2 nchar(100));
b、查看超级表
- 查看数据库内全部 STable,及其相关信息,包括 STable 的名称、创建时间、列数量、标签(TAG)数量、通过该 STable 建表的数量;
SHOW STABLES [LIKE tb_name_wildcard];
#如:显示当前数据库下的所有超级表信息
show stables like "%super%
- 显示一个超级表的创建语句,对一个已经存在的超级表,返回其创建语句;在另一个集群中执行该语句,就能得到一个结构完全相同的超级表。常用于数据库迁移。
SHOW CREATE STABLE stb_name;
- 获取超级表的结构信息,返回结果集的第一列为子表名,后续列为标签列。
DESCRIBE [db_name.]stb_name;
#如
describe super_table ;
- 获取超级表中所有子表的标签信息
SHOW TABLE TAGS FROM stbname;
#如:
SHOW TABLE TAGS FROM st;
c、删除超级表
删除 STable 会自动删除通过 STable 创建的子表以及子表中的所有数据。
DROP STABLE [IF EXISTS] [db_name.]stb_name
d、修改超级表
修改超级表的结构会对其下的所有子表生效。无法针对某个特定子表修改表结构。标签结构的修改需要对超级表下发,TDengine会自动作用于此超级表的所有子表。
- 超级表增加列
ALTER STABLE stb_name ADD COLUMN col_name column_type;
#如:
alter table super_table add column column_name int;
- 超级表删除列
ALTER STABLE stb_name DROP COLUMN col_name;
#如:
alter table super_table drop column column_name;
- 添加标签
ALTER STABLE stb_name ADD TAG tag_name tag_type;
#如:
alter table super_table add tag column nchar(60);
- 删除标签
ALTER STABLE stb_name DROP TAG tag_name;
#如:
alter table super_table drop tag tag_name;
- 修改标签名
ALTER STABLE stb_name RENAME TAG old_tag_name new_tag_name;
#如:
alter table super_table change tag old_tag_name new_tag_name;
- 修改子表标签值(TAG)
alter table item_table_name set tag column_key = “value”;
e、超级表查询
使用 SELECT 语句可以完成在超级表上的投影及聚合两类查询,在 WHERE 语句中可以对标签及列进行筛选及过滤。
如果在超级表查询语句中不加 ORDER BY,返回顺序是先返回一个子表的所有数据,然后再返回下个子表的所有数据,所以返回的数据是无序的。如果增加了 ORDER BY 语句,会严格按 ORDER BY 语句指定的顺序返回的。
(2)子表操作
创建表时timestamp 字段必须为第一个字段类型为主键
CREATE TABLE [IF NOT EXISTS] [db_name.]tb_name (create_definition [, create_definition] ...) [table_options]
a、创建普通表:
CREATE TABLE IF NOT EXISTS a(c timestamp,b int)
b、根据超级表创建子表
#这样建表之后,子表会复制除去超级表里面的tags字段外的所有字段;
create table table_name using super_table tags (column_value,column_value ...);
c、 删除数据表
drop table if exists 表名;
d、 显示当前数据库下的所有数据表信息
show tables;
#添加过滤条件
show tables like "%table_name%";
e、 获取表的结构信息
describe 表名;
f、 表增加列
alter table mytable add column addfield int;
g、 表删除列
alter table mytable drop column addfield;
三、安装可视化界面 TDengineGUI
https://github.com/arielyang/TDengineGUI
TDengineGUI是一个基于electron构建的,针对时序数据库TDengine的图形化管理工具。具有跨平台、易于使用、版本适应性强等特点。
安装windows版本,效果图如下:
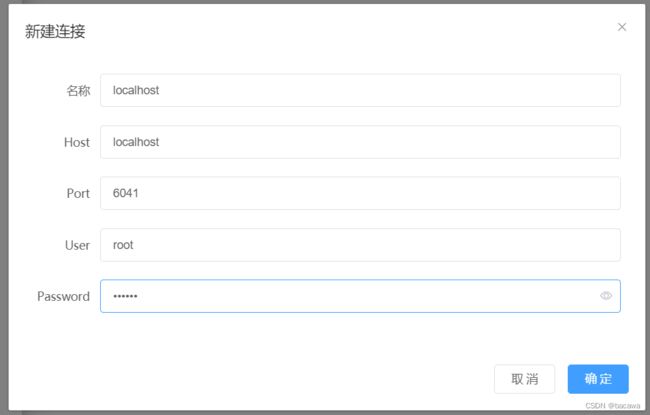
新建连接:服务的端口号(默认为6041)、连接服务器的用户名和密码(默认为root:taosdata),如果修改过用户名或者密码,请按实际情况进行配置。

四、超级表、表(也叫子表)及Tag的关系
TDengine要求每个数据采集点单独建表,这样能极大提高数据的插入/查询性能,但是导致系统中表的数量猛增,让应用对表的维护以及聚合、统计操作难度加大。因此,为降低应用的开发难度,TDengine引入了超级表 STable (Super Table)的概念。
1、超级表定义
STable 是同一类型数据采集点的抽象,是同类型采集实例的集合。每个 STable 包含多张数据结构一样的子表,并为其子表定义了表结构和一组标签。
- 表结构即表中记录的数据列及其数据类型;
- 标签名和数据类型由 STable 定义,标签值记录着每个子表的静态信息,用于对子表进行分组过滤。
2、表(也叫子表)定义
子表本质上就是普通的表,由一个时间戳主键和若干个数据列组成,每行记录着具体的数据,数据查询操作与普通表完全相同;但子表与普通表的区别在于每个子表从属于一张超级表,并带有一组由 STable 定义的标签值。
每种类型的采集设备可以定义一个 STable。数据模型定义表每列数据的类型,如温度、压力、电压、电流、GPS 实时位置等;而标签信息属于 Meta Data,如采集设备的序列号、型号、坐落位置等,它是静态的,是表的元数据。用户在创建表(数据采集点)时除可以指定 STable(采集类型)外,还可以指定标签的值。
3、举个例子
举例解释一下(超级表)super_table,(子表)sub_table,(标签)Tag之间的关系。
在物联网中,假设我们现在有一个小区的电表设备需要联网。那么电表就会存在张三家的电表,李四家的电表,张三家电表的电流和电压,李四家的电流和电压,以及王五等等家的设备信息。
那么作为电表这个物联设备,就可以设计成超级表super_table,这样电表就有了张三的电表sub_table1,李四家的电表sub_table2,等等,电流和电压就是超级表中定义表字段属性,而电表所属的业主名称,小区地址可以存放在TAG。
按照这个场景,我们就可以设计出一张超级表(super_dianbiao),和若干张子表(dianbiao1001,dianbiao1002,等等)。
(1)创建电表超级表:super_dianbiao
#创建数据库
create database mydb;
#使用数据库
use mydb;
# 创建超级表
create stable super_dianbiao (ts timestamp,dianya float,dianliu float) tags (yezhu_name nchar(15),xiaoqu_location nchar(50),menpai_num nchar(10));
(2)创建子表dianbiao……
create table dianbiao1001 using super_dianbiao tags('张三','东城小区','1-1101');
create table dianbiao1002 using super_dianbiao tags('李四','东城小区','1-1102');
(3)往子表中插入数据
insert into dianbiao1001 values(now,1.7,3.2);
insert into dianbiao1002 values(now,1.6,3.1);
(4)使用TDengineGUI看看直观的效果
- 先看超级表(super_dianbiao)

2. 看看子表(dianbiao1001)

- 看看子表(dianbiao1002)

总结
TDengine的关键创新点——一个采集点一张表,同一类型的采集点用一个超级表来描述,也就是一个表结构Schema和静态标签Schema 。动态采集的物理量作为各字段,静态属性(Location和groupId)作为子表标签。利用超级表作为模板,生成子表 – 对应各采集点,有了超级表,极大地方便了同类采集点的数据检索、查询、聚合。
这种设计有几大优点:
- 能保证一个采集点的数据在存储介质上是以块为单位连续存储的。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度。
- 由于不同采集设备产生数据的过程完全独立,每个设备的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
- 对于一个数据采集点而言,其产生的数据是时序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
如果采用传统的方式,将多个设备的数据写入一张表,由于网络延时不可控,不同设备的数据到达服务器的时序是无法保证的,写入操作是要有锁保护的,而且一个设备的数据是难以保证连续存储在一起的。采用一个数据采集点一张表的方式,能最大程度的保证单个数据采集点的插入和查询的性能是最优的。
本文旨在让各位能够基本了解TDengine的基本使用和核心概念,下文即将介绍TDengine与Springboot的工程实践,敬请期待!