redis:地理位置信息geo
简介
- redis3.2版本提供了GEO(地理信息定位)功能,支持存储地理位置信息。
- 可以用来实现比如附近位置,摇一摇这类依附于地理位置的功能
- GEO功能是 Redis 的另一位作者Matt Stancliff 借鉴 NoSQL 数据库 Ardb 实现的,Ardb 的作者来自中国,它提供了优秀的GEO功能。
命令
geoadd :添加/更新地理位置的坐标
作用
- geoadd 用于存储指定的地理空间位置
- 可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。
- 这些数据会以有序集合的形式被储存在键里面, 从而使得像
GEORADIUS和GEORADIUSBYMEMBER这样的命令可以在之后通过位置查询取得这些元素。
注意:
- GEOADD 命令以标准的 x,y 格式接受参数, 所以用户必须先输入经度, 然后再输入纬度
- GEOADD 能够记录的坐标是有限的: 非常接近两极的区域是无法被索引的
- 有效的经度从-180°到180°
- 有效的纬度从-85.05112878度到85.05112878度。
当用户尝试输入一个超出范围的经度或者纬度时, GEOADD 命令将返回一个错误
语法
GEOADD key longitude latitude member [longitude latitude member ...]
longitude、latitude、member分别是该地理位置的经度、纬度、成员
返回值
- 新添加到键里面的空间元素数量,
- 不包括那些已经存在但是被更新的元素。
实例

127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
(integer) 1
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
(integer) 0
geoadd可以同时添加多个地理位置信息。
127.0.0.1:6379> geoadd cities:locations 117.12 39.08 tianjin 114.29 38.02 shijiazhuang 118.01 39.38 tangshan 115.29 38.51 baoding
(integer) 4
geopos:获取地理位置信息
作用
- 从键里面返回所有给定位置元素的位置(经度和纬度)。
语法
返回值
- GEOPOS 命令返回一个数组, 数组中的每个项都由两个元素组成:
- 第一个元素为给定位置元素的经度
- 第二个元素则为给定位置元素的纬度。
- 当给定的位置元素不存在时, 对应的数组项为空值。
实例
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEOPOS Sicily Palermo Catania NonExisting
1) 1) "13.361389338970184"
2) "38.115556395496299"
2) 1) "15.087267458438873"
--- 2) "37.50266842333162"
3-) (nil)
1-27.0.0.1:6379> geopos cities:locations tianjin
1) 1) "117.12000042200088501"
- 2) "39.0800000535766543"
geodist:获取两个地理位置的距离
作用
返回两个给定位置之间的距离。
如果两个位置之间的其中一个不存在, 那么命令返回空值。
指定单位的参数 unit 必须是以下单位的其中一个:
- m 表示单位为米。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
如果用户没有显式地指定单位参数, 那么 GEODIST 默认使用米作为单位。
GEODIST 命令在计算距离时会假设地球为完美的球形, 在极限情况下, 这一假设最大会造成 0.5% 的误差。
语法
GEODIST key member1 member2 [m|km|ft|mi]
最后一个距离单位参数说明:
- m :米,默认单位。
- km :千米。
- mi :英里。
- ft :英尺。
返回值
- 计算出的距离会以双精度浮点数的形式被返回。
- 如果给定的位置元素不存在, 那么命令返回空值。
实例
127.0.0.1:6379> geodist cities:locations beijing tianjin km
"89.2061"
redis> GEODIST Sicily Foo Bar
(nil)
georadius :获取指定位置范围内的地理信息位置集合
georadius 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
语法
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
- withcoord:返回结果中包含经纬度;
- withdist:返回结果中包含离中心节点位置的距离;
- withhash:返回结果中包含geohash;
- COUNT count:指定返回结果的数量;
- asc|desc:指定结果按照离中心节点的距离做升序或者降序;
- store key:将返回结果的地理位置信息保存到指定键;
- storedist key:将返回结果离中心离中心节点的距离保存到指定键。
作用
以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
范围可以使用以下其中一个单位:
- m 表示单位为米。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
在给定以下可选项时, 命令会返回额外的信息:
- WITHDIST :
- 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。
- 距离的单位和用户给定的范围单位保持一致。
- WITHCOORD : 将位置元素的经度和维度也一并返回。
- WITHHASH :
- 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。
- 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
命令默认返回未排序的位置元素。 通过以下两个参数, 用户可以指定被返回位置元素的排序方式:
- ASC : 根据中心的位置, 按照从近到远的方式返回位置元素。
- DESC : 根据中心的位置, 按照从远到近的方式返回位置元素。
在默认情况下, GEORADIUS 命令会返回所有匹配的位置元素。 虽然用户可以使用 COUNT 选项去获取前 N 个匹配元素, 但是因为命令在内部可能会需要对所有被匹配的元素进行处理, 所以在对一个非常大的区域进行搜索时, 即使只使用 COUNT 选项去获取少量元素, 命令的执行速度也可能会非常慢。 但是从另一方面来说, 使用 COUNT 选项去减少需要返回的元素数量, 对于减少带宽来说仍然是非常有用的。
返回值
GEORADIUS 命令返回一个数组, 具体来说:
- 在没有给定任何 WITH 选项的情况下, 命令只会返回一个像 [“New York”,“Milan”,“Paris”] 这样的线性(linear)列表。
- 在指定了
WITHCOORD 、 WITHDIST 、 WITHHASH等选项的情况下, 命令返回一个二层嵌套数组, 内层的每个子数组就表示一个元素。
在返回嵌套数组时, 子数组的第一个元素总是位置元素的名字。 至于额外的信息, 则会作为子数组的后续元素, 按照以下顺序被返回:
- 以浮点数格式返回的中心与位置元素之间的距离, 单位与用户指定范围时的单位一致。
- geohash 整数。
由两个元素组成的坐标,分别为经度和纬度。
举个例子,GEORADIUS Sicily 15 37 200 km withcoord withdist这样的命令返回的每个子数组都是类似以下格式的:
实例
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEORADIUS Sicily 15 37 200 km WITHDIST
1) 1) "Palermo"
2) "190.4424"
2) 1) "Catania"
2) "56.4413"
redis> GEORADIUS Sicily 15 37 200 km WITHCOORD
1) 1) "Palermo"
2) 1) "13.361389338970184"
2) "38.115556395496299"
2) 1) "Catania"
2) 1) "15.087267458438873"
2) "37.50266842333162"
redis> GEORADIUS Sicily 15 37 200 km WITHDIST WITHCOORD
1) 1) "Palermo"
2) "190.4424"
3) 1) "13.361389338970184"
2) "38.115556395496299"
2) 1) "Catania"
2) "56.4413"
3) 1) "15.087267458438873"
2) "37.50266842333162"
georadiusbymember:获取指定位置范围内的地理信息位置集合
语法
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
作用
- 这个命令和 GEORADIUS 命令一样, 都可以找出位于指定范围内的元素,
- 但是 GEORADIUSBYMEMBER 的中心点是由给定的位置元素决定的, 而不是像 GEORADIUS 那样, 使用输入的经度和纬度来决定中心点。
返回值
一个数组, 数组中的每个项表示一个范围之内的位置元素。
实例
127.0.0.1:6379> georadiusbymember cities:locations beijing 100 km #距离北京100km内的城市
1) "beijing"
2) "tianjin"
geohash:将二维经纬度转换为一维字符串
语法
geohash key member [member ... ]
作用
Redis使用geohash将二维经纬度转换为一维字符串
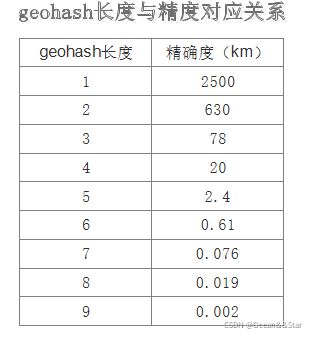
geohash有如下特点:
- GEO的数据类型为zset,redis将所有地理位置信息的geohash存放在zset中
- 字符串越长,表示的位置更精确
- 两个字符串越相似,他们之间的距离越近,Redis利用字符串前缀匹配算法实现相关命令
- geohash编码和经纬度是可以相互转换的。
Redis正是使用有序集合并结合geohash的特性实现了GEO的若干命令。
返回值
- 一个数组, 数组的每个项都是一个 geohash 。
- 命令返回的 geohash 的位置与用户给定的位置元素的位置一一对应。
实例
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEOHASH Sicily Palermo Catania
1) "sqc8b49rny0"
2) "sqdtr74hyu0"
zrem:删除地理位置信息
zrem key member
GEO没有提供删除成员的命令,但是因为GEO的底层实现是zset,所有可以借用zrem实现对地理位置信息的删除。
127.0.0.1:6379> zrem cities:locations tangshan
(integer) 1
GEO的底层结构
存储:sorted set
一般来说,在设计一个数据类型的底层结构时,我们首先要知道,要处理的数据有什么访问特定。所以,我们要先搞清楚位置信息是怎么被存取的。
以叫车服务为例,来分析下 LBS 应用中经纬度的存取特点。
- 每一辆网约车都有一个编号(例如 33),网约车需要将自己的经度信息(例如116.034579)和纬度信息(例如 39.000452 )发给叫车应用。
- 用户在叫车的时候,叫车应用会根据用户的经纬度位置(例如经度 116.054579,纬度39.030452),查找用户的附近车辆,并进行匹配。
- 等把位置相近的用户和车辆匹配上以后,叫车应用就会根据车辆的编号,获取车辆的信息,并返回给用户。
可以看到,一辆车(或一个用户)对应一组经纬度,并且随着车(或用户)的位置移动,相应的经纬度也会变化。
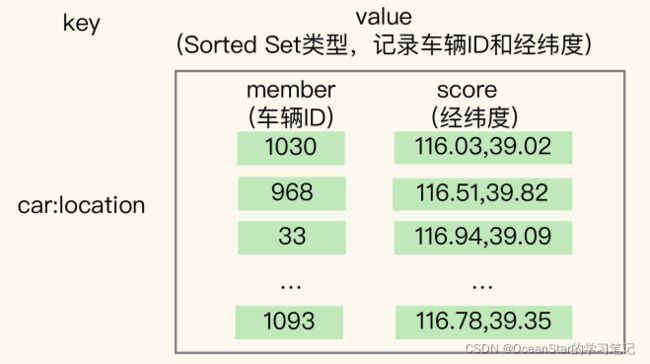
这种数据记录模式属于一个 key(例如车 ID)对应一个 value(一组经纬度)。当有很多车辆信息要保存时,就需要有一个集合来保存一系列的 key 和 value。 Hash集合类型可以快速存取一系列的key和value,正好可以用来记录一系列车辆ID和经纬度的对应关系。所以,我们可以把不同车辆的ID和它们对应的经纬度信息存在Hash集合中。如下图

但是,除了记录经纬度信息,我们还需要根据用户的经纬度信息在车辆的Hash集合中进行范围查询。一旦设计到范围查询,就意味着集合中的元素需要有序,但是Hash类型的元素是无需的,所以不能用hash
那能不能用sorted set呢? Sorted Set 类型也支持一个 key 对应一个 value 的记录模式,其中,key 就是 SortedSet 中的元素,而 value 则是元素的权重分数。更重要的是,Sorted Set 可以根据元素的权重分数排序,支持范围查询。这就能满足 LBS 服务中查找相邻位置的需求了。
实际上,GEO类型的底层数据结构就是用sorted Set来实现的。用 Sorted Set 来保存车辆的经纬度信息时,Sorted Set 的元素是车辆 ID,元素的权重分数是经纬度信息,如下图所示:
这时问题来了,Sorted Set 元素的权重分数是一个浮点数(float 类型),而一组经纬度包含的是经度和纬度两个值,是没法直接保存为一个浮点数的,那具体该怎么进行保存呢?
这就要用到 GEO 类型中的 GeoHash 编码了。
编码方法:GeoHash
GeoHash 编码方法的基本原理是“二分区间,区间编码”
当我们要对一组经纬度进行GeoHash编码时,我们先对经度和维度分别编码,然后再把经纬度各自的编码组成一个最终编码。
首先,我们来看下经度和纬度的单独编码过程。
-
对于一个地理位置信息来说,它的经度范围是[-180,190]。GeoHash编码对把一个经纬度编码成一个N位的二进制值,我们来对经度范围[-180,180]做 N 次的二分区操作,其中 N可以自定义。
-
在进行第一次二分区时,经度范围[-180,180]会被分成两个子区间:[-180,0) 和[0,180](左、右分区)。此时,我们可以查看一下要编码的经度值落在了左分区还是右分区。如果是落在左分区,我们就用 0 表示;如果落在右分区,就用 1 表示。这样一来,每做完一次二分区,我们就可以得到 1 位编码值。
-
然后,我们再对经度值所属的分区再做一次二分区,同时再次查看经度值落在了二分区后的左分区还是右分区,按照刚才的规则再做 1 位编码。当做完 N 次的二分区后,经度值就可以用一个 N bit 的数来表示了。
举个例子,假设我们要编码的经度值是 116.37,我们用 5 位编码值(也就是 N=5,做 5次分区)。
- 我们先做第一次二分区操作,把经度区间[-180,180]分成了左分区[-180,0) 和右分区[0,180],此时,经度值 116.37 是属于右分区[0,180],所以,我们用 1 表示第一次二分区后的编码值。
- 接下来,我们做第二次二分区:把经度值 116.37 所属的[0,180]区间,分成[0,90) 和[90,180]。此时,经度值 116.37 还是属于右分区[90,180],所以,第二次分区后的编码值仍然为 1。等到第三次对[90,180]进行二分区,经度值 116.37 落在了分区后的左分区[90, 135)中,所以,第三次分区后的编码值就是 0。
- 按照这种方法,做完 5 次分区后,我们把经度值 116.37 定位在[112.5, 123.75]这个区间,并且得到了经度值的 5 位编码值,即 11010。这个编码过程如下表所示:

对纬度的编码方式,和对经度的一样,只是纬度的范围是[-90,90],下面这张表显示了对纬度值 39.86 的编码过程。

当一组经纬度值都编完码后,我们再把它们的各自编码值组合在一起,组合的规则是:最终编码值的偶数位上依次是经度的编码值,奇数位上依次是纬度的编码值,其中,偶数位从 0 开始,奇数位从 1 开始。
我们刚刚计算的经纬度(116.37,39.86)的各自编码值是 11010 和 10111,组合之后,第 0 位是经度的第 0 位 1,第 1 位是纬度的第 0 位 1,第 2 位是经度的第 1 位 1,第 3位是纬度的第 1 位 0,以此类推,就能得到最终编码值 1110011101,如下图所示:
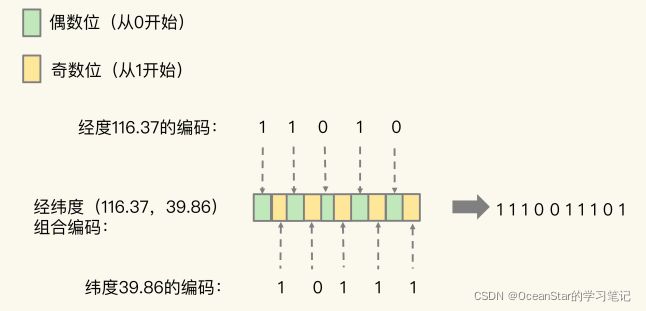
用了 GeoHash 编码后,原来无法用一个权重分数表示的一组经纬度(116.37,39.86)就可以用 1110011101 这一个值来表示,就可以保存为 Sorted Set 的权重分数了。
当然,使用 GeoHash 编码后,我们相当于把整个地理空间划分成了一个个方格,每个方格对应了 GeoHash 中的一个分区。
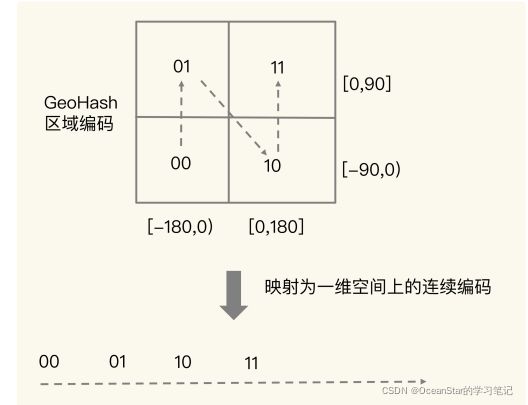
举个例子。我们把经度区间[-180,180]做一次二分区,把纬度区间[-90,90]做一次二分区,就会得到 4 个分区。我们来看下它们的经度和纬度范围以及对应的 GeoHash 组合编码。
- 分区一:[-180,0) 和[-90,0),编码 00;
- 分区二:[-180,0) 和[0,90],编码 01;
- 分区三:[0,180]和[-90,0),编码 10;
- 分区四:[0,180]和[0,90],编码 11。
这 4 个分区对应了 4 个方格,每个方格覆盖了一定范围内的经纬度值,分区越多,每个方格能覆盖到的地理空间就越小,也就越精准。我们把所有方格的编码值映射到一维空间时,相邻方格的 GeoHash 编码值基本也是接近的,如下图所示:
所以,我们使用 Sorted Set 范围查询得到的相近编码值,在实际的地理空间上,也是相邻的方格,这就可以实现 LBS 应用“搜索附近的人或物”的功能了。
不过,有的编码值虽然在大小上接近,但实际对应的方格却距离比较远。例如,我们用 4 位来做 GeoHash 编码,把经度区间[-180,180]和纬度区间[-90,90]各分成了 4 个分区,一共 16 个分区,对应了 16 个方格。编码值为 0111 和 1000 的两个方格就离得比较远,如下图所示:
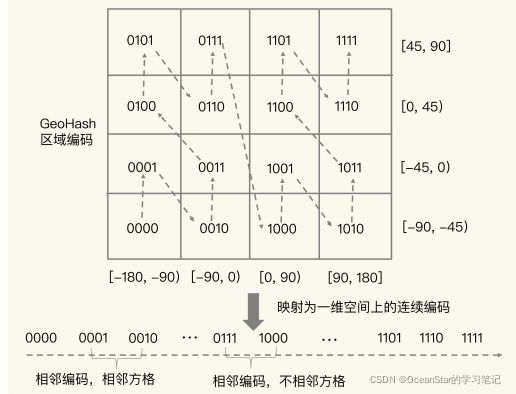
所以,为了避免查询不准确问题,我们可以同时查询给定经纬度所在的方格周围的 4 个或8 个方格。
总结:GEO 类型是把经纬度所在的区间编码作为 Sorted Set 中
元素的权重分数,把和经纬度相关的车辆 ID 作为 Sorted Set 中元素本身的值保存下来,这样相邻经纬度的查询就可以通过编码值的大小范围查询来实现了。