elasticsearch系列九:异地容灾-CCR跨集群复制
概述
起初只在部分业务中采用es存储数据,在主中心搭建了个集群,随着es在我们系统中的地位越来越重要,数据也越来越多,针对它的安全性问题也越发重要,那如何对es做异地容灾呢?
今天咱们就一起看下官方提供的解决方案cross-cluster replication(简称ccr)。
环境准备
物理机:96核 64G 2THDD 国产UOS系统的服务器一台 ip 192.168.229.48
通过docker快速启动2个es 节点、2个kibana节点,es2个节点为2套独立集群。
| 名称 | ip | 版本 |
|---|---|---|
| es | 172.17.0.2 172.17.0.4 |
7.15.0 |
| kibana | 7.15.0 | |
| jdk | openjdk version 16.0.2 |
进程如下图:

规划:172.17.0.2 为master 172.17.0.4 为follower
设置CCR
由于CCR是收费版本,如果购买公有云的服务就自带这个功能,此处我们通过试用30天来体验一下。
我们先在0.4所在的kibana上打开ccr设置主节点的信息如下图:

接口级设置:
PUT _cluster/settings{"persistent": {"cluster": {"remote": {"ccr_test": {"skip_unavailable": false,"mode": "sniff","proxy_address": null,"proxy_socket_connections": null,"server_name": null,"seeds": ["192.168.229.48:9300"],"node_connections": 3}}}}}
该功能采用TCP协议,所以我们设置默认端口9300,设置完以后如下图:
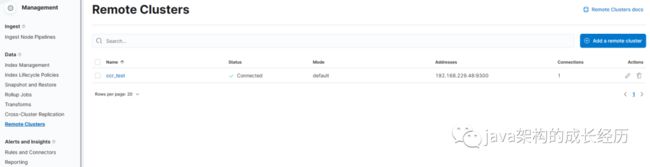
并且该功能是基于索引级别的,提供2种方式:创建指定索引同步、自动同步按照索引规则,接下来我们看下2种情况分别如何设置。
设置特定的索引同步
打开follower的kibana,找到ccr设置项如下图:
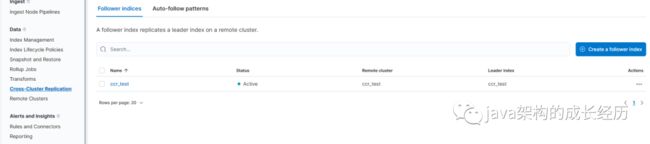
可以创建一个同步任务,此处只能单个索引设置同步。
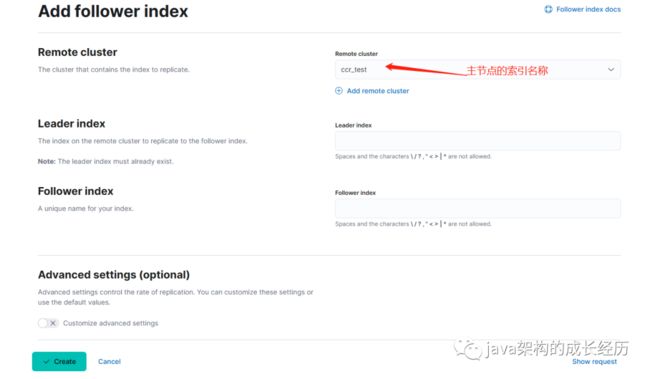
接口级设置:
PUT /ccr_test/_ccr/follow{"remote_cluster": "ccr_test","leader_index": "ccr_test","max_read_request_operation_count": 5120,"max_outstanding_read_requests": 12,"max_read_request_size": "32mb","max_write_request_operation_count": 5120,"max_write_request_size": "9223372036854775807b","max_outstanding_write_requests": 9,"max_write_buffer_count": 2147483647,"max_write_buffer_size": "512mb","max_retry_delay": "500ms","read_poll_timeout": "1m"}
创建以后我们就可以在主节点上对索引ccr_test进行crud操作了,在主节点上新增4百万的数据,再去follower上查看发现数据成功同步过来。
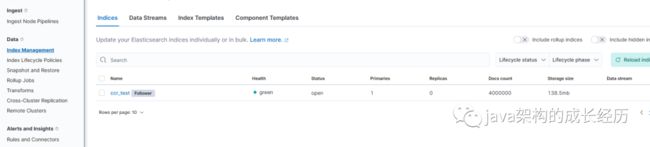
但是这种方式有局限性,因为实际生产环境可能有n个索引,比如这种按天生成的日志数据索引如何同步呢?总不能一个个的配置吧,接下来我们就看下自动同步。
设置自动同步
我们打开自动同步,添加一个自动任务,通过弹框发现按照固定的格式设置索引同步:
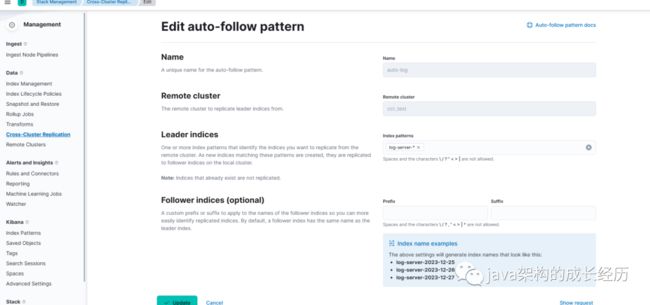
接口级设置:
PUT /_ccr/auto_follow/auto-log{"remote_cluster": "ccr_test","leader_index_patterns": ["log-server-*"],"follow_index_pattern": "{{leader_index}}"}
这样我们就可以将log-server-开头的索引设置自动同步了,此时我们在主节点新增一个索引:
POST /log-server-2023-12-25/_doc/1{"name": "John Doe","age": 30,"email": "[email protected]"}
接着去从节点上看下发现数据已经同步成功
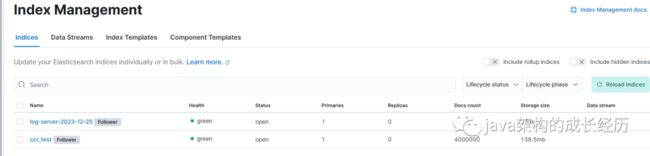
总结
以上就是es官方针对跨集群同步的解决方案,官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/ccr-getting-started-tutorial.html#ccr-getting-started-tutorial
当然还有其他的方案比如应用双写、自研数据同步、MQ双写等等。对于自己维护的集群来通过MQ双写相对简单,对于公有云服务还是官方的解决方案更为合适。
好了今天的分享就到这了,有什么疑问欢迎留言讨论。
Elasticsearch系列经典文章
-
elasticsearch列一:索引模板的使用
-
elasticsearch系列二:引入索引模板后发现数据达到一定量还是慢怎么办?
-
elasticsearch系列三:常用查询语法
-
elasticsearch系列四:集群常规运维
-
elasticsearch系列五:集群的备份与恢复
-
elasticsearch系列六:索引重建
-
elasticsearch系列七:聚合查询
-
elasticsearch系列八:如何解决聚合结果不精确问题
