Scrapy入门到放弃04:下载器中间件,让爬虫更完美
前言
MiddleWare,顾名思义,中间件。主要处理请求(例如添加代理IP、添加请求头等)和处理响应
本篇文章主要讲述下载器中间件的概念,以及如何使用中间件和自定义中间件。
MiddleWare分类
依旧是那张熟悉的架构图。
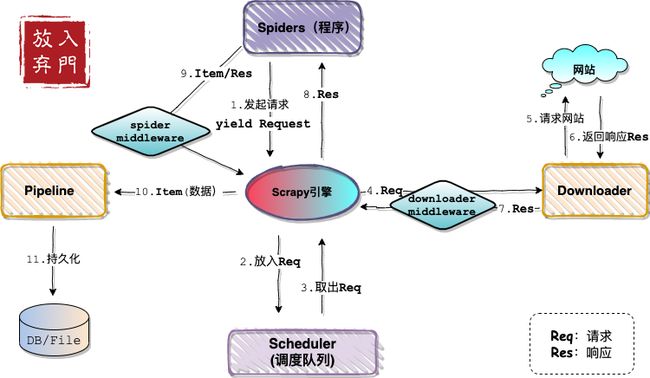
从图中看,中间件主要分为两类:
- Downloader MiddleWare:下载器中间件
- Spider MiddleWare:Spider中间件
本篇文主要介绍下载器中间件,先看官方的定义:
下载器中间件是介于Scrapy的request/response处理的钩子框架。 是用于全局修改Scrapy request和response的一个轻量、底层的系统。
作用
如架构图中所描述的一样,下载器中间件位于engine和下载器之间。engine将未处理的请求发送给下载器的时候,会经过下载器中间件,这时候在中间件里可以包装请求,例如修改请求头信息(设置UA、cookie等)和添加代理IP。
当下载器将网站的响应发送给engine的时候,也会经过下载器中间件,这里我们就可以对响应内容进行处理。
内置下载器中间件
Scrapy内置了很多下载器中间件供开发者使用。当我们启动一个Scrapy爬虫时,Scrapy会自动帮助我们启用这些中间件。如图:

图中就是在启动Scrapy程序时控制台打印的日志信息,我们发现Scrapy帮我们启用了很多下载器中间件和Spider中间件。
这里,先看看这些内置的中间件是如何发挥作用的?
RetryMiddleware
其实,这些内置中间件是和settings中的配置配套使用的。这里就拿RetryMiddleware为例。它的作用主要是:当请求失败时,可以根据RETRY_ENABLED和RETRY_TIMES配置来启用重试策略以及决定重试次数。就酱!!
那么问题又来了,这么多中间件,我去哪里找这个settings配置和中间件的对应关系啊??
这里我的方法有两种:
- 去官方文档,上篇文章有链接
- 看源码注释,在scrapy包下的都有中间件对应的py文件
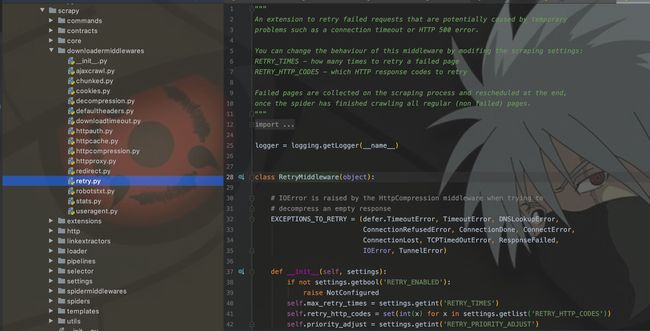
注释里面写的明明白白,代码中获取的参数也一览无余。
自定义中间件
有时候,内置的中间件满足不了自己的需求,所以我们就要自力更生,自定义中间件。所有的中间件都在middlewares.py中进行定义。
我们打开middlewares.py,发现里面已经自动生成了一个下载器中间件和Spider中间件。
先看自生成的下载器中间件模板:

可以看到里面主要有五个方法:
- from_crawler:类方法,用于初始化中间件
- process_request:每个request通过下载中间件时,都会调用该方法,对应架构图步骤4
- process_response:处理下载器返回的响应内容,对应架构图步骤7
- process_exception:当下载器或者处理请求异常时,调用此方法
- spider_opened:内置的信号量回调方法,这里先不关注,先不关注!
这里主要关注3,顺带了解一下4、5。
process_request()
此方法有两个参数:
- request:spider发起的需要处理的request
- spider:该request对应的spider,暂定信号量细讲这个对象
def process_request(self, request, spider):
# Called for each request that goes through the downloader middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
这里主要是为了让大家看注释,看注释的目的是为了告诉大家:此方法必须返回值。
- None:基本上用的都是这个返回值。表示这个请求可以进去下一个中间件进行处理了。
- request:停止调用process_request方法,并重新将request放回队列重新调度
- response:不会调用其他的 process_request,直接返回response,执行process_response。
还有一个是raise抛出异常,其实基本上返回值都用None,其他的目前可以仅做了解,有兴趣的可以自己探索一下。
process_response()
此方法有三个参数:
- request:response所对应的request
- response:被处理的response
- spider:response所对应的spider
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
一样是看注释,返回值有两个:
- response:下载器返回的响应内容,在各个中间件的process_response处理
- request:停止调用process_response方法,响应不会到达spider,并重新将request放回队列重新调度
这里记住,只要return response就行。
process_exception()
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
此方法就是当上面两个方法抛出异常的时候就会进入此方法,返回值有三个,意思和上面的差不多,用None就行。
启用和禁用中间件
自定义的中间件,有时候会和内置中间件功能重复,也担心功能上互相覆盖。所以这里我们可以选择,在配置中关掉内置中间件。
我个人比较喜欢自定义User-Agent中间件,但是Scrapy内置UserAgentMiddleware中间件,这就冲突了。如果内置中间件执行优先级低,后执行的话,则内置的UA就会覆盖自定义的UA。所以,我们需要关掉这个内置中UA中间件。
DOWNLOADER_MIDDLEWARES参数用来设置下载器中间件。其中,Key为中间件路径,Value为中间件执行优先级,数字越小,越先执行,当Value为None时,表示禁用。
# settings.py
DOWNLOADER_MIDDLEWARES = {
# 禁用默认的useragent插件
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
# 启用自定义的中间件
'ScrapyDemo.middlewares.VideospiderDownloaderMiddleware': 543,
}
这样,内置的UA中间件则被禁用。
调用优先级
其次我们要明确的是:中间件是链式调用,一个请求会根据中间件的优先级,先后经过每个中间件,响应也是。
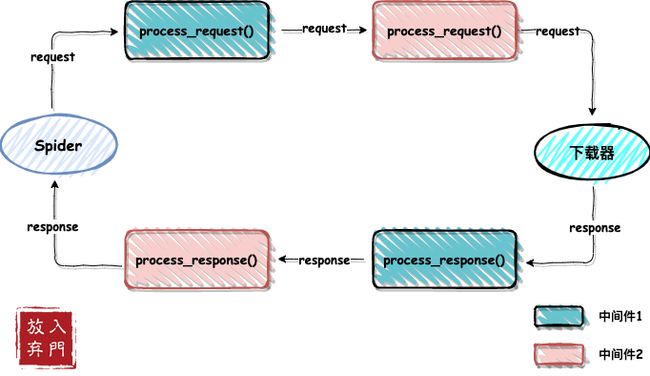
上面也说了,每个中间件都会设置一个执行优先级,数字越小越先执行。例如中间件1的优先级设置为200,中间件2的优先级设置为300。
当spider发起一个请求时,request会先经过中间件1的process_request进行处理,然后到达中间件2的此方法进行处理,当经过所有的中间件的此方法处理之后,最后到达下载器进行网站请求,然后返回响应内容。
process_response就是逆序处理,先到达中间件2的此方法,再到达中间件1,最后响应返回spider中,由开发者处理。
实践
这里我们自定义一个下载器中间件,来添加User-Agent。
自定义中间件
在middlewares.py中定义一个中间件:
class CustomUserAgentMiddleWare(object):
def process_request(self, request, spider):
request.headers['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
return None
def process_response(self, request, response, spider):
print(request.headers['User-Agent'])
return response
启用中间件
为了直观,我们不修改settings.py全局配置,依旧使用代码内局部配置。
import scrapy
class DouLuoDaLuSpider(scrapy.Spider):
name = 'DouLuoDaLu'
allowed_domains = ['v.qq.com']
start_urls = ['https://v.qq.com/detail/m/m441e3rjq9kwpsc.html']
custom_settings = {
'DOWNLOADER_MIDDLEWARES': {
# 禁用默认的useragent插件
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
# 启用自定义的中间件
'ScrapyDemo.middlewares.CustomUserAgentMiddleWare': 400
}
}
def parse(self, response):
pass
这里首先禁用了默认的UA中间件,然后启用了自定义的UA中间件。并且我在最后一行打上断点,Debug看UA是否设置成功。
测试结果
Debug模式启动程序,这里先把自定义的UA中间件禁用。
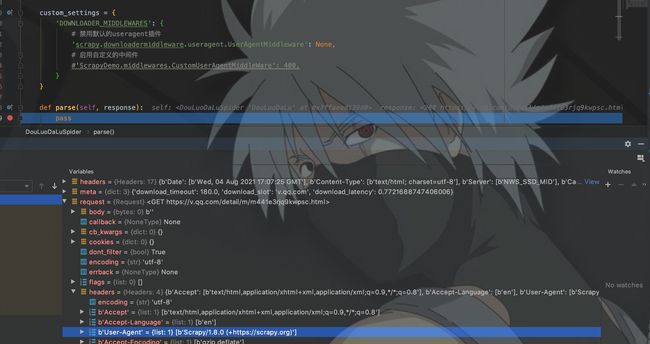
如图,request的UA是Scrapy。我们将注释去掉,启动UA中间件,再次启动程序测试。

如图,request的UA已经变成我在中间件中设置的UA了。
设置代理IP
依旧是在process_request方法中设置代理IP。
代码如下:
request.meta["proxy"] = 'http://ip:port'
结语
下载器中间件主要的功能还是包装请求,我个人自定义下载器中间件都是用来动态设置UA和实时检测更换代理IP。至于其他的场景需求,内置的下载器中间件基本上够用。
当然,不去学习下载器中间件这一块的知识同样可以开发Scrapy爬虫,但是下载器中间件会让你的爬虫更加完美。
本来想把下载器中间件和Spider中间件写在一篇中,但是知识点太碎,不好排版,而且还容易混淆,所以Spider中间件就留在下一篇写,期待下一次相遇。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。文章会在公众号 [入门到放弃之路] 首发,期待你的关注。
