常用的sql语句汇总(个人版)
基础语句
1、SELECT:选择数据表中的数据
SELECT column_name1, column_name2 FROM table_name;
2、WHERE:筛选符合条件的数据
SELECT column_name FROM table_name WHERE column_name = 'value';
3、AND:用于连接 WHERE 子句中的多个条件
SELECT column_name FROM table_name WHERE column_name1 = 'value1' AND column_name2 = 'value2';
4、OR:用于连接 WHERE 子句中的多个条件,其中至少一个条件必须成立
SELECT column_name FROM table_name WHERE column_name1 = 'value1' OR column_name2 = 'value2';
5、IN:筛选符合指定值中任意一个的数据
SELECT column_name FROM table_name WHERE column_name IN ('value1', 'value2', 'value3');
6、NOT IN:筛选不符合指定值中任意一个的数据
SELECT column_name FROM table_name WHERE column_name NOT IN ('value1', 'value2', 'value3');
7、LIKE:筛选符合指定模式的数据
SELECT column_name FROM table_name WHERE column_name LIKE 'pattern';
SELECT column_name FROM table_name WHERE column_name LIKE '%value%'
8、NOT LIKE:筛选不符合指定模式的数据
SELECT column_name FROM table_name WHERE column_name NOT LIKE 'pattern';
SELECT column_name FROM table_name WHERE column_name NOT LIKE '%value%'
9、BETWEEN:筛选在指定范围内的数据
SELECT column_name FROM table_name WHERE column_name BETWEEN 'value1' AND 'value2';
9、NOT BETWEEN:筛选不在指定范围内的数据
SELECT column_name FROM table_name WHERE column_name NOT BETWEEN 'value1' AND 'value2';
10、ORDER BY:按指定列进行排序
SELECT column_name FROM table_name ORDER BY column_name ;//默认升序
SELECT column_name FROM table_name ORDER BY column_name DESC;//降序
11、GROUP BY:按指定列进行分组
SELECT column_name1,column_name2 FROM table_name GROUP BY column_name1;
备注: 从 MySQL 5.7.5 开始,默认 SQL 模式包括 ONLY_FULL_GROUP_BY。 (在 5.7.5 之前,MySQL 不检测函数依赖,并且默认不启用 ONLY_FULL_GROUP_BY。),所以select的内容如果不在group by 中,将会报错,可以参考这里的解决方法
DISTINCT :基于指定列的唯一值去重
SELECT DISTINCT(column_name1) FROM table_name;
区别:distinct和group by具体区别点击查看
12、HAVING:筛选分组后符合指定条件的数据
SELECT column_name1, SUM(column_name2) FROM table_name GROUP BY column_name1 HAVING SUM(column_name2) > 100;
进阶一下
13、JOIN:连接多个数据表
SELECT table1.column_name1, table2.column_name2 FROM table1 JOIN table2 ON table1.column_name1 = table2.column_name1;
14、LEFT JOIN:连接左侧数据表,并包括右侧数据表中与左侧数据表中没有匹配项的行
SELECT table1.column_name1, table2.column_name2 FROM table1 LEFT JOIN table2 ON table1.column_name1 = table2.column_name1;
//右连接
SELECT * FROM table1 RIGHT JOIN table2 ON table1.column_name = table2.column_name;
15、UNION:合并多个查询结果
SELECT column_name FROM table1 UNION SELECT column_name FROM table2;
16、EXISTS:检查子查询结果是否存在
SELECT column_name FROM table1 WHERE EXISTS (SELECT column_name FROM table2 WHERE column_name = 'value');
//NOT EXISTS:检查子查询结果是否不存在
SELECT column_name FROM table1 WHERE NOT EXISTS (SELECT column_name FROM table2 WHERE column_name = 'value');
17、AVG:计算平均值
SELECT AVG(column_name) FROM table_name;
18、COUNT:计算数据行数
SELECT COUNT(*) FROM table_name;
19、MAX:计算最大值
SELECT MAX(column_name) FROM table_name;
20、MIN:计算最小值
SELECT MIN(column_name) FROM table_name;
21、SUM:计算总和
SELECT SUM(column_name) FROM table_name;
22、CASE:根据条件返回不同的结果
SELECT column_name,
CASE
WHEN column_name = 'value1' THEN 'result1'
WHEN column_name = 'value2' THEN 'result2'
ELSE 'result3'
END AS new_column_name
FROM table_name;`
23、ROW_NUMBER:按照指定列进行分组并排序(就是对column_name字段进行分组,并在组内对column_name2字段降序排)
SELECT column_name, ROW_NUMBER() OVER (PARTITION BY column_name ORDER BY column_name2 DESC) FROM table_name;
示例如下:

24、DENSE_RANK:按照指定列进行分组并排序,相同值的行具有相同的排名,不跳过下一个排名(RANK:跳过下一个排名)
SELECT column_name, DENSE_RANK() OVER (PARTITION BY column_name ORDER BY column_name2 DESC) FROM table_name;
示例如下:
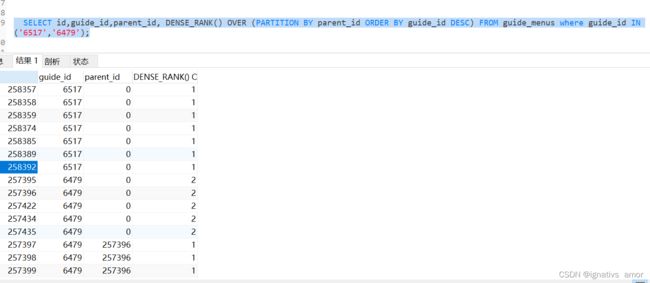
25、FIRST_VALUE:返回分组中第一个行的列值
SELECT column_name, FIRST_VALUE(column_name2) OVER (PARTITION BY column_name ORDER BY column_name2) FROM table_name;
//返回分组中最后一个行的列值
SELECT column_name, LAST_VALUE(column_name2) OVER (PARTITION BY column_name ORDER BY column_name2 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) FROM table_name;
26、CONCAT:连接多个字符串值为一个字符串
SELECT CONCAT(column_name1, ' ', column_name2) FROM table_name;
示例如下:

附加使用的sql
1、连表更新,将一张表的某个字段更新为另一张表的某个字段值
#将1表的reward更新为b表的reward值
UPDATE project_submits a
INNER JOIN projects b ON a.project_id = b.id
SET
a.reward = b.reward
2、DATE_FORMAT:查询指定日期的数据
select * from `order_exam_logs` where DATE_FORMAT(created_at, "%Y-%m-%d")='2023-06-05'
因为数据表中created_at存到了秒,所以要使用DATE_FORMAT函数