Python3 定义DataFrame,删除其中某一或多个行列
Python3 定义DataFrame,删除其中某一或多个行列
- win10截屏快捷键
- 创建一个DataFrame变量
-
- 定义一个空的
- 自定义数据
-
- 代码:
- 输出:
- 读取excel文件数据
-
- 代码:
- 删除(方法:drop)
-
- 文字说明:
- 具体参数说明(用到部分说明)
- 删除列
-
- 方法一:用列名
-
- 举例:
- 结果
- 方法二:不用列名
-
- 举例:
- 结果:
- 删除行
-
- 方法一:用索引
-
- 举例1:
- 结果:
- 举例2:
- 结果:
- 方法二:不用索引
-
- 举例:
- 结果:
- 删除列和行组合使用
-
- 举例:
- 结果:
- 错误提示
-
- index 1 is out of bounds for axis 0 with size 1
-
- 解决方案:
win10截屏快捷键
键盘:Win+Shift+S
粘贴:Ctrl+V
创建一个DataFrame变量
定义一个空的
import pandas as pd
df = pd.DataFrame()
自定义数据
代码:
import pandas as pd
#所有的列都显示
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#定义
df = pd.DataFrame({'A':[1,2,3,4],'B':[1,2,3,4],'C':[1,2,3,4],'D':[1,2,3,4]})
#输出
print(df)
输出:

读取excel文件数据
代码:
import pandas as pd
#所有的列都显示
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
path="D:\\Users\\ky\\Desktop\\20201201.xlsx"
sheetname = "Line"
#读取excel用read_excel方法
df = pd.read_excel(path, sheet_name=sheetname)
rows_num = df.shape[0]
columns_num = df.shape[1]
#切块
block1 = df.iloc[9:rows_num,3:columns_num]
last_row_num = block1.shape[0] + 8
del block1
column_B = 2 - 1
#不知道为什么16就是显示到16,不需要减
column_P = 16
row_nine = 9 - 2
block1 = df.iloc[row_nine:last_row_num,column_B:column_P]
print(block1)
del df
df = block1
print(df)
删除(方法:drop)
文字说明:
drop(labels, axis=0, inplace=True)
具体参数说明(用到部分说明)
| 参数名 | 内容 | 具体说明 | 有无默认 |
|---|---|---|---|
| labels | string或者array; | 删除的行或列的标签。 | 无默认 |
| axis | 0 或 1 | 轴向(0表示行,1表示列) | 0 |
| inplace | boolean类型 | 是否修改源数据 | False |
删除列
方法一:用列名
1、df.drop(columns=[‘column_name’],axis=1,inplace=True)
2、df.drop([‘column_name’],1,True)
举例:
#column_name为待删列的列名,data本身是不会有变化的!
#df.drop(columns=['column_name'],axis=1)
#需要赋值(赋值给新的不会破坏源数据
#df2=df.drop(columns=['bodyType'],axis=1)
#加了inplace=True df本身就会有变化了,
df.drop(columns=['A'],axis=1,inplace=True)
结果

方法二:不用列名
举例:
#循环连续删除几列,这里6不用变(6删除的是第7列)
#range(1,2+1) 循环的是1到8
for column_no in range(1,2+1):
#print(column_no)
#print("删除"+str(column_no)+"之后")
df.drop(df.columns[[1]],axis=1,inplace=True)
print(df)
结果:
说明:1 删除的B列,连续删除两列

删除行
方法一:用索引
举例1:
import pandas as pd
#所有的列都显示
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#定义
df = pd.DataFrame({'A':[1,2,3,4],'B':[1,2,3,4],'C':[1,2,3,4],'D':[1,2,3,4]})
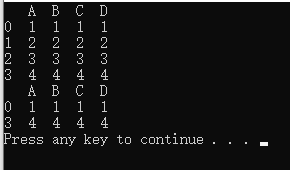
print("源数据:")
print(df)
#修改行索引
df.rename({0:'a',1:'b',2:'c',3:'d'},inplace=True)
print("修改行索引后:")
print(df)
df.drop(labels='b',axis=0,inplace=True)
print("删除b后:")
print(df)
结果:

举例2:
listRowRemove = [1,2]
#listRowRemove存入的是所有需要删除的行索引组成的list
#定义一个空的list的方法是:listRowRemove=list()
#list类型添加listRowRemove.append(row[0])
for item in listRowRemove:
#按行循环df,row是一行的数据
#row[0]:行索引
#row[1]:获取该行全部字段
for row in df.iterrows():
if row[0] == item:
df = df.drop(row[0])
print(df)
结果:
方法二:不用索引
举例:
import pandas as pd
#所有的列都显示
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#定义
df = pd.DataFrame({'A':[1,2,3,4],'B':[1,2,3,4],'C':[1,2,3,4],'D':[1,2,3,4]})
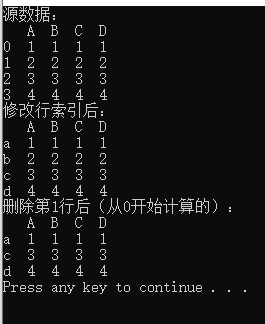
print("源数据:")
print(df)
df.rename({0:'a',1:'b',2:'c',3:'d'},inplace=True)
#修改行索引
print("修改行索引后:")
print(df)
#不按照索引删除
df.drop(df.index[[1]],axis=0,inplace=True)
print("删除第1行后(从0开始计算的):")
print(df)
结果:
删除列和行组合使用
举例:
row=1
for column_no in range(1,3):
print("删除列:"+str(column_no))
#labels代表删除的行或者列的标签(索引)
df.drop(labels=row,axis=0,inplace=True)
print(df)
row=row+1
print("删除行:"+str(row))
#inplace是否对源数据生效
#按序号删除
df.drop(df.columns[[1]],axis=1,inplace=True)
print(df)
结果:

错误提示
index 1 is out of bounds for axis 0 with size 1
解决方案:
可能是循环超过了范围,range里面超过了也会提示