小白学爬虫-进阶-PySpider操作指北
2020,努力做一个无可替代的人!
作者|小一
![]()
全文共1455字,阅读全文需6分钟
写在前面的话
在PySpider 的使用过程中,还是会遇到大大小小的问题。
所以今天的内容可能截图会多一些,差不多是按照踩坑流程一步步走下来的
如果你在在使用过程中遇到不一样的问题,也欢迎一起讨论交流。
关于PySpider 的相关概念,大家看上篇文章就行了,这节主要是配置使用
小白学爬虫-进阶-爬虫框架知多少
正文
首先,是安装
这个应该大家都不陌生了,毕竟从前面的BeautifulSoup、Numpy、Pandas等都是通过同样的方式安装的
打开cmd 窗口,输入以下命令:
pip install pyspider
如果超时的话建议连手机热点,几MB流量,很快就下好了
安装成功之后,会出现这个界面

接下来,是启动PySpider
注意,这块的问题比较多
正常情况下,我们在cmd 中可以直接启动PySpider
pyspider all正常启动的界面应该是这样的:

但是,事与愿违,大多数情况下你是无法正常启动的
首先,你会遇到这个问题:
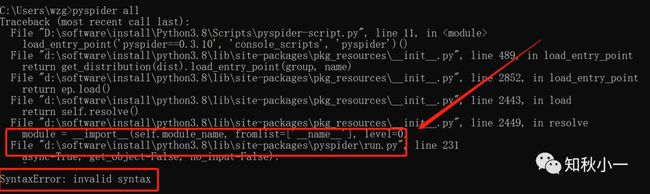
竟然是一个语法错误的提示,是不是有点懵?
启动语句写的没有任何问题,拼写也不会有错,也没有多空格字符啥的,为什么会错?
SyntaxError: invalid syntax解决方法:
async 从 python3.7 开始已经加入保留关键字中. 所以async 不能作为函数的参数名
所以,在我们python3的安装目录下的部分文件中需要给async 重新起个名字,至于改成什么,随你姓啦
这里的部分文件包括这些:
安装目录下\python3.8\lib\site-packages/pyspider 路径下的
run.py
fetcher\tornado_fetcher.py
webui\app.py
打开之后将里面的async 改成其他非Python 关键字
需要注意的是,在部分Python 文件中会需要改动好几处这种情况
比如在app.py 中,小一这里直接改成 async1

你以为这样就成功了吗?
不出意外的话,第二个错误来了
这个当时没有截到图,报错大概是下面这样的:
ValueError: Invalid configuration: - Deprecated option ‘domaincontroller’: use 'http_authenticator这个你需要在刚才的webui 文件里面的webdav.py 文件打开,修改第209行,把
'domaincontroller': NeedAuthController(app),改为:
'http_authenticator':{
'HTTPAuthenticator':NeedAuthController(app),
},ok,基本就这两个问题
然后再使用前面说的代码正常启动吧
pyspider all创建PySpider
在浏览器中输入
http://localhost:5000/会出现这样一个画面
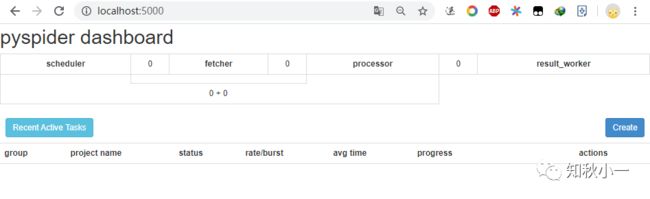
没有问题,你们都能打开这个页面的对吧
点击create,会弹出这样一个窗口,名称和url 链接,这里我们以之前做过的豆瓣Top250电影为例

使用PySpider
创建成功之后,会出现这样一个页面
注意观察这个网址,这是我们的主页面没错吧
点击右上角的保存按钮

然后在左边栏点击run,会发现follows 中出现一个红色的小①
点击发现正是我们的主页面,点击中间红框右边的运行按钮

如果这一步点击run 报错或者无效之后,你可以保存页面后刷新浏览器再试
发现多了更多的url,仔细观察,这不就是我们的二级目录吗
top250一共10页,每页25个影片,对应红框中的网址url(第一页是主页面)

我们随便改一下右边框的网址为我们任意一个二级目录,同时为了方便查看源码,增加detail 函数的返回结果
执行和上面步骤同样的操作

这个页面就是我们的最终页面了
切换到html 选项卡可以看到是整个页面的所有元素,切换到web 选项卡是整个页面的网页显示
是不是和我们当时手写的爬虫流程一样?
到这,整个流程就差不多走完了,你应该也知道了PySpider 是怎样去实现爬取数据的。
至于剩下编码部分,代码我们之前都写过,改一改就可以用了
贴一下之前的爬虫链接
爬虫实战-手把手教你爬豆瓣电影
总结一下:
本节主要讲了PySpider 的配置和使用,应该对于大部分没接触过的人来说可以轻松掌握。
如果你在配置使用的过程有遇到新的问题,可以在留言区一起交流
下节继续爬虫框架,下节见!
写在后面的话
爬虫框架小一只能带你们过一遍,真正要会使用还得自己亲手过一遍
在编程上,千万不能眼高手低,一定要自己码一遍代码。
另外,上节提到的八爪鱼也比较好玩,如果你的爬虫数据需求很少,直接用这个软件就行了,倒也不用折腾着非得去写代码搞定它。
好巧啊,你也读到这了!
点个在看让小一看到你![]()