MySQL之对表内容的增删查改
目录
增加表中的内容
增加否则更新表中的内容
增加否则替换表中的内容
查找表中的内容
修改表中的数据
删除表中的数据
截断表中的数据
向表中插入查询结果
聚合函数
count函数
sum函数
avg函数
max函数
min函数
分组查询
增加表中的内容
insert [into] 表名 [(属性1,属性2...)] values (第一条数据的属性1的值,第一条数据的属性2的值...),(第二条数据的属性1的值,第二条数据的属性2的值...),...;
说一下,[ ]中的内容代表的是可选项,即可以省略不写。
接下来咱们实操演示一下。
如果在insert语句中省略下图1红框处的属性列表,则insert语句代表全列插入,这时即使某属性是自增长的,即使某属性有默认值,我们也必须按照属性列表的顺序挨个指明每个属性的值,否则就会插入失败。演示如下图2,可以发现在其中虽然num1和num2都有默认值、num3还是自增长,但只要insert语句少指明一个属性的值,就会插入失败,必须全部指明才能成功。
- 图1如下。

- 图2如下。

如果在insert语句中不省略属性列表,则对于没有设置not null约束的属性,对于设置了default约束的属性,对于设置了自增长约束的属性,是可以不指明属性的值完成插入的;排除这些情况外,如果不指明属性的值就会插入失败。演示如下图,可以看到属性num1设置了not null约束,属性num2没有设置任何约束,num3设置了default约束,num4设置了自增长约束,所以根据本段理论,按理来说【只指明num1的值即可完成插入,如果不指明num1则无法完成插入】,而事实上也的确如此,比如下图红框和蓝框处就分别证明了这一点。

然后要说的是,如果在insert语句中不省略属性列表,则属性列表中的属性顺序是可以随意指定的,如下图所示。
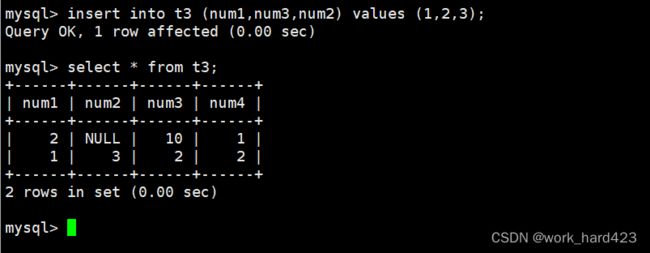
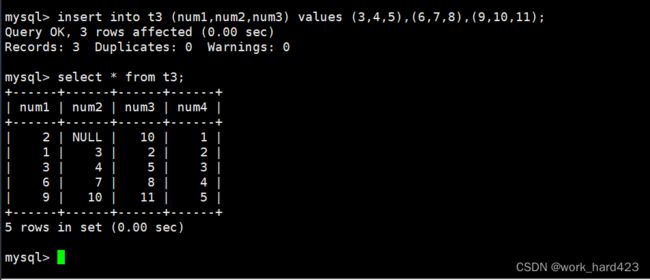
最后要说的是,是可以一次性insert插入多条数据的,演示如下。
增加否则更新表中的内容
向表中插入数据时,如果待插入数据中被设置了主键约束的属性的值和表中数据冲突,那么就会因为主键冲突导致插入失败;同理,如果待插入数据中被设置了唯一键约束的属性的值和表中数据冲突,那么就会因为唯一键冲突导致插入失败。演示如下:

这时在MySQL中有一种SQL语句,支持在有唯一键或者主键冲突时,对表中的数据进行更新,如果不冲突则直接插入。说具体点就是:
- 如果待插入数据中被设置了主键约束或者唯一键约束的属性的值和表中数据不冲突,则直接插入数据。
- 如果待插入数据中被设置了主键约束或者唯一键约束的属性的值和表中数据冲突,则将表中的数据进行更新。
该SQL语句的语法如下。
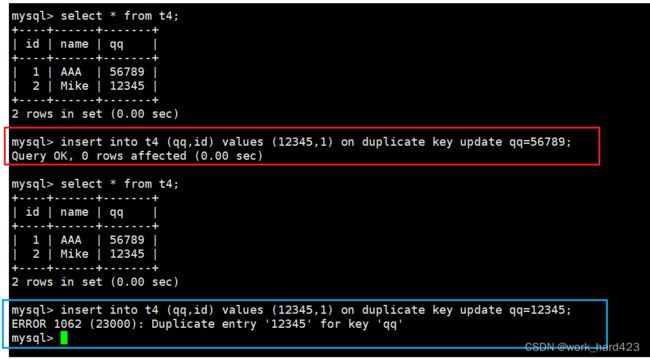
完整的select语句 on duplicate key update 指定的属性1=指定值1,指定的属性2=指定值2,...;演示如下。如下图红框处所示,因为属性id被设置了主键约束,所以在插入第一条数据,即插入id为1、姓名为Mike的同学时就会导致主键冲突,此时就会直接将表中的数据更新;然后如下图蓝框处所示,可以看到因为属性qq被设置了唯一键约束,所以在插入第二条数据,即插入id为1、姓名为Lihua、qq号为56789的同学时就会导致唯一键冲突,此时也会将表中的数据更新,并且在更新后我们发现,就因为我们在更新时没有在update后面显示写name='Lihua',导致更新后学生姓名name没有被更新成Lihua,这就说明了想要更新表中一条数据的某个属性的值,就一定得显示指明,否则该属性的值就还是会等于原来的值,不会进行更新。
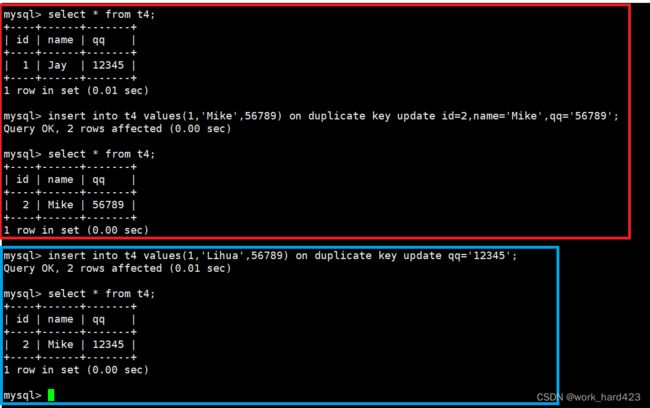
然后要知道的是,根据下图1红框处的SQL语句我们即可得知一个结论,即如果在插入一条数据时,该数据中被设置了主键约束的属性A的值和表中的数据1冲突、并且该数据中被设置了唯一键约束的属性B的值和表中的数据2冲突,那么MySQL只会更新表中的一条数据,并且还是更新发生了主键冲突的数据1,而不会更新发生了唯一键冲突的数据2。
凭什么得到上面的【那么MySQL只会更新表中的一条数据,并且还是更新发生了主键冲突的数据1,而不会更新发生了唯一键冲突的数据2】这个结论呢?首先,因为属性name并没有设置唯一键约束,所以表中的姓名是可以相同的。如果MySQL会更新表中的两条数据,按理来说下图1红框处的SQL语句是支持把表中的两个同学的姓名都更新成AAA的(因为即使都更新成AAA,两条数据也不会冲突),但事后我们select查看表中内容时却发现没有都更新成AAA,而是只更新了发生主键冲突的学生Jay的姓名,这即可证明上面的结论是正确的。
并且如下图2也可以佐证上面的结论是正确的,比如在插入的数据中,属性qq的值和表中Mike同学的qq相等、属性id的值和表中AAA同学的id相等时,如下图2红框处所示,如果选择把qq更新成56789即可成功,但如果如下图2蓝框处所示,选择把qq更新成12345就会失败,这也是因为MySQL只会更新发生了主键冲突的AAA同学的属性值,比如说,因为属性qq被设置了唯一键约束,所以当把AAA的属性qq更新成56789时,因为AAA同学的qq原来就是56789,相当于没变,并且不会和其他同学的qq发生冲突,所以下图2红框处的SQL语句可以成功,但当把AAA同学的属性qq更新成12345时,因为Mike同学的qq也是12345,所以如果能更新成功就会导致唯一键冲突,所以下图2蓝框处的SQL语句就失败了。这就证明了MySQL只会更新发生了主键冲突的AAA同学的属性值。
- 图1如下。

- 图2如下。
增加否则替换表中的内容
向表中插入数据时,如果待插入数据中被设置了主键约束的属性的值和表中数据冲突,那么就会因为主键冲突导致插入失败;同理,如果待插入数据中被设置了唯一键约束的属性的值和表中数据冲突,那么就会因为唯一键冲突导致插入失败。演示如下:
这时在MySQL中有一种SQL语句,支持在有唯一键或者主键冲突时,对表中的数据进行替换,如果不冲突则直接插入。说具体点就是:
- 如果待插入数据中被设置了主键约束或者唯一键约束的属性的值和表中数据不冲突,则直接插入数据。
- 如果待插入数据中被设置了主键约束或者唯一键约束的属性的值和表中数据冲突,则直接先将表中的数据删除,然后再插入数据。
用于替换表中内容的SQL语句和用于增加表中内容的SQL语句(即insert into巴拉巴拉)的使用方式完全一致,只需要把insert改成replace,如下。
replace [into] 表名 [(属性1,属性2...)] values (第一条数据的属性1的值,第一条数据的属性2的值...),(第二条数据的属性1的值,第二条数据的属性2的值...),...;
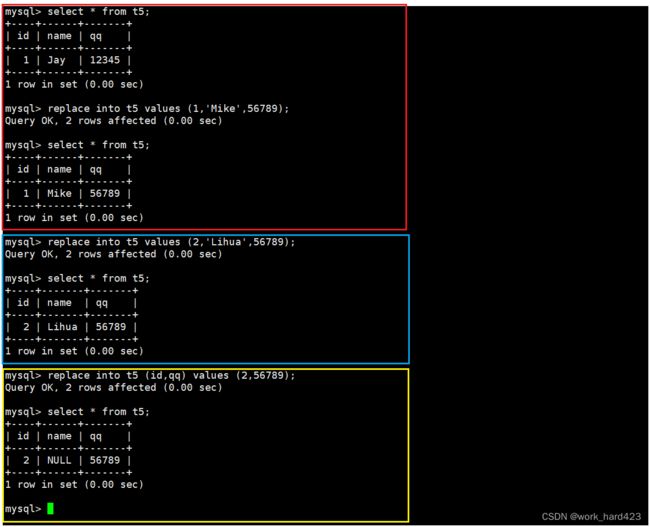
演示如下。如下图红框处所示,因为属性id被设置了主键约束,所以在插入第一条数据,即插入id为1、姓名为Mike的同学时就会导致主键冲突,此时就会直接将表中的数据替换(即先删除表中数据,然后再插入);然后如下图蓝框处所示,可以看到因为属性qq被设置了唯一键约束,所以在插入第二条数据,即插入id为2、姓名为Lihua、qq号为56789的同学时就会导致唯一键冲突,此时也会将表中的数据替换(即先删除表中数据,然后再插入);并且如下图黄框处所示,如果一个属性没有被设置not null约束,并且如果我们在进行替换(即先删除表中数据,然后再插入)时不指明该属性的值,则该属性的值就会等于默认值或者NULL,而不是等于原来的值(这也很好理解,毕竟替换的语义是先删除表中的旧数据,然后再插入新数据)。
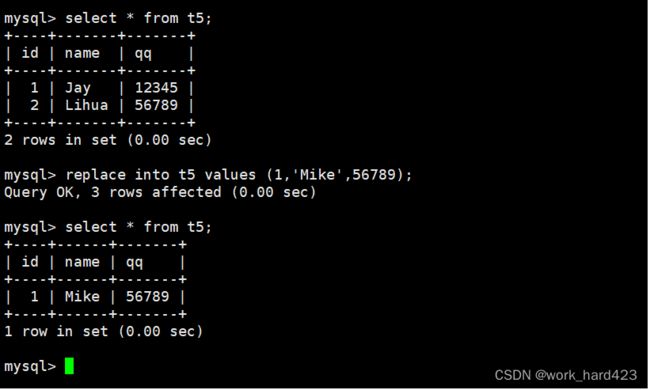
然后要知道的是,如下图所示,如果在使用replace语句插入一条数据时,该数据中被设置了主键约束的属性A的值和表中的数据1冲突、并且该数据中被设置了唯一键约束的属性B的值和表中的数据2冲突,那么MySQL会先把表中的数据1和数据2都删除,然后再插入新数据。
查找表中的内容
select [distinct] {* | {属性1,属性2,...}} from 表名称 [where 查询条件] [order by 排序条件] [limit 分页条件];
用于查询的SQL语句如上所示,说明一下:
- [ ]中的内容代表的是可选项,即可以省略不写。
- { }中的 | 表示或者,表示可以选择 | 左侧的语句,也可以选择 | 右侧的语句,但不能同时选择。
接下来咱们实操演示一下。
如下图所示,为了进行演示,我们创建一个成绩表,表当中包含被设置了自增长约束的属性id(即学号)、属性name(即同学的姓名)以及该同学的语文成绩、数学成绩和英语成绩。并且创建表后再向表中插入几条测试记录,以供我们进行查找。
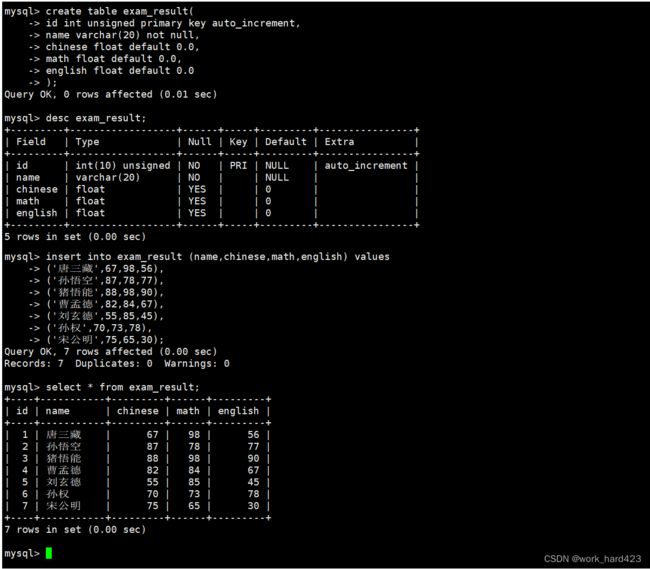
全列查询
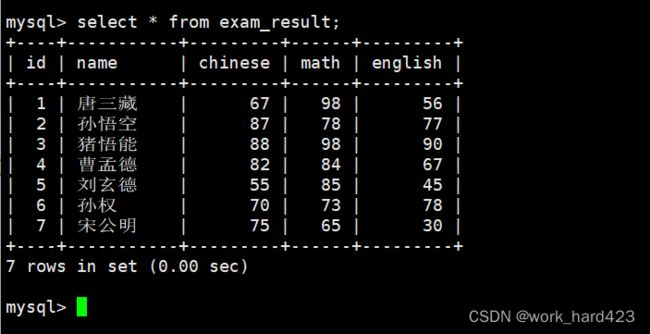
如下图所示,如果在查询数据时直接用 * 代替属性列表,则表示进行全列查询,这时将会显示被筛选出来的每一条数据的所有属性的值。
说一下,在公司的数据库中的数据可不像下图这样只有几条,而可能是成千上万条,这时如果使用select * 全列查询,则一条条数据就会不断刷屏导致你压根无法看清数据,除此之外,select * 全列查询相当于在磁盘中一下子把当前查询的表对应的磁盘文件给load到内存中,这也会很消耗主机的资源,可以看到,因为select *全列查询有种种缺点,所以在实际工作中,我们十分不推荐使用select * 全列查询。
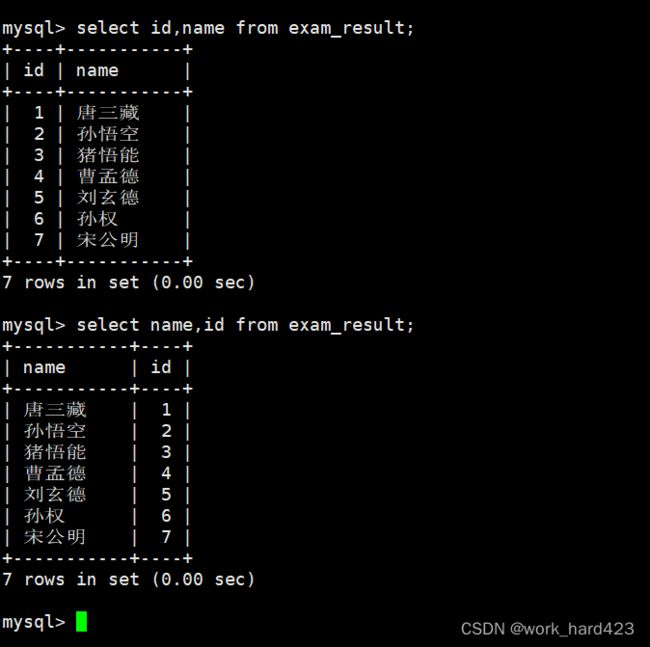
指定列查询
如下图所示,在查询数据时我们可以只对指定的属性进行查询,这时将需要查询的属性在属性列表中指定即可。注意,在指定多个属性时,这些属性的顺序是可以随意拟定的。
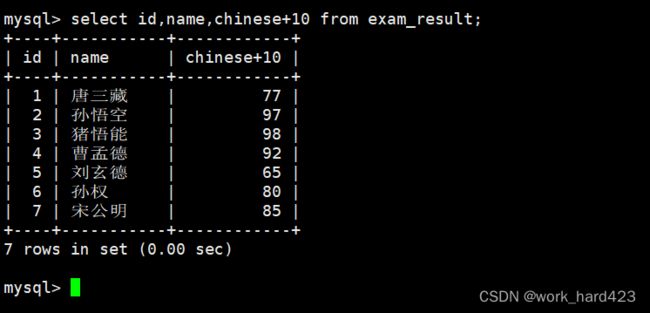
查询字段为表达式
如下图所示,查询数据时,属性列表中除了能指定表中存在的属性外,我们还可以将表达式放到属性列表中,这是因为select不仅能用来查询数据,还可以用来计算某些表达式或执行某些函数,如果我们将表达式放到属性列表,那么每当一条数据被筛选出来时就会执行这个表达式,然后将表达式的计算结果当作这条数据的一个属性的值进行显示(但实际上该计算结果并不是数据的一个属性,所以我们说的是“当作”)。

如下图1所示,属性列表中的表达式可以包含表中已有的属性,这时每当一条数据被筛选出来时,就会将数据中对应的属性值提供给表达式进行计算。同理在属性列表的表达式中当然也可以包含表中已有的多个属性,如下图2所示,这时我们就可以通过表达式计算出更多有意义的数据。
- 图1如下。
- 图2如下。
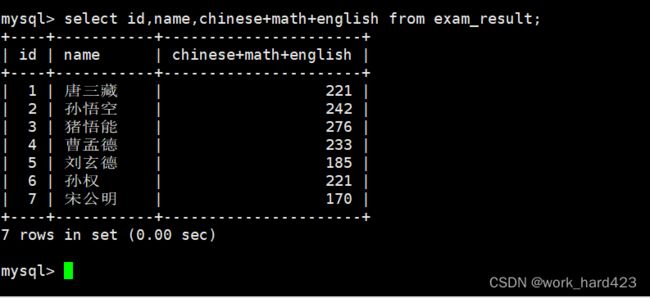
然后说一下,我们还可以为属性列表中的属性或者表达式起别名,如下图红框处所示,方式1就是直接在属性名或者表达式后面增设一个别名;如下图蓝框处所示,方式2就是先在属性名或者表达式后面加上as,然后再增设一个别名。

结果去重
查询成绩表时指定查询数学成绩,可以看到数学成绩中有重复的分数,如果想要对查询结果进行去重操作,可以在select后面带上distinct,如下:

where子句,即带上指定条件进行查询
在上文所有的select查询中,我们都是没有加上where子句,也就是没有指定查询条件的,所以在上文所有的select查询中,MySQL都是直接将表中所有的数据作为数据源挨个交给select语句。
而现在我们要知道的是,如果在查询数据时加上了where子句,也就是指定了查询条件,那么在查询数据时MySQL就会根据where子句指定的条件进行判断,比如如果一条数据符合指定的条件,则MySQL才会将这条数据作为数据源交给select语句,然后再判断下一条数据;如果一条数据不符合指定的条件,则MySQL就不会将这条数据作为数据源交给select语句,而是直接判断下一条数据。以后我们就要知道,where查询本质是从上到下一行一行进行遍历比对的。
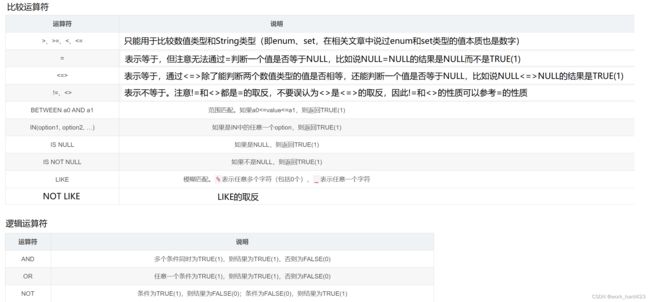
where子句中可以指明一个或多个筛选条件,可以将多个筛选条件用逻辑运算符AND或OR进行关联,下图中给出了where子句中常用的比较运算符和逻辑运算符。
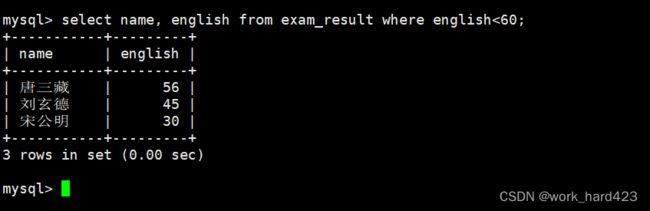
通过where子句查询英语不及格的同学及其英语成绩,如下:
通过where子句查询语文成绩在80到90分的同学及其语文成绩,如下:
- 方式1如下。
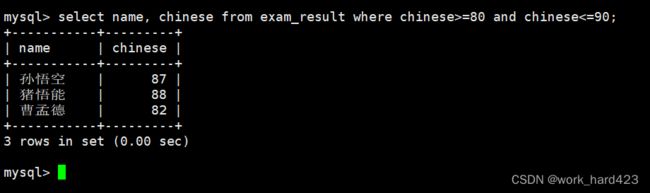
- 方式2如下。

通过where子句查询数学成绩是58或59或98或99分的同学及其数学成绩,如下:
- 方式1如下。
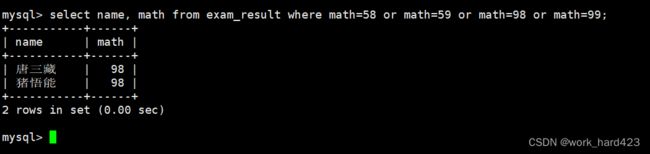
- 方式2如下。可以看到,只要某条数据的math属性的值和in后面圆括号中的任意一个数字相等,则MySQL就会将这条数据筛选出来作为数据源交给select语句。
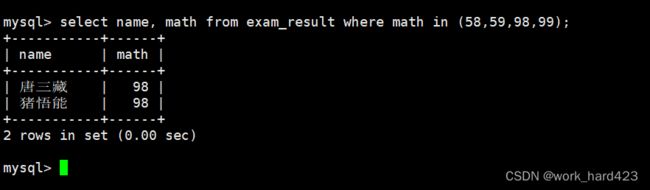
通过where子句查询查询姓孙的同学,如下:
说一下,在where子句中通过模糊匹配来判断当前同学是否姓孙(需要用到%来匹配多个字符)。
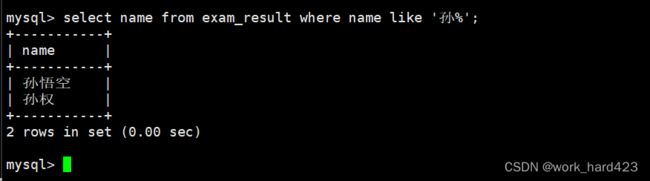
通过where子句查询孙某和孙某某同学,如下:
说一下,在where子句中通过模糊匹配来判断当前同学是否姓孙(需要用到 _ 来严格匹配单个字符,需要模糊匹配几个字符就要有几个 _ )。
通过where子句查询语文成绩好于英语成绩的同学,如下:
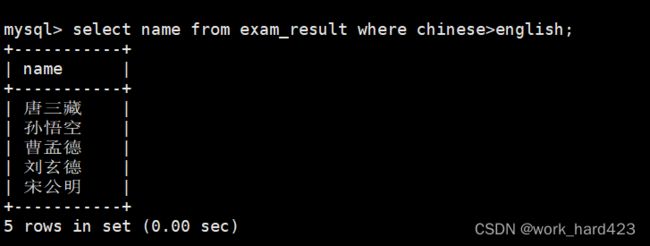
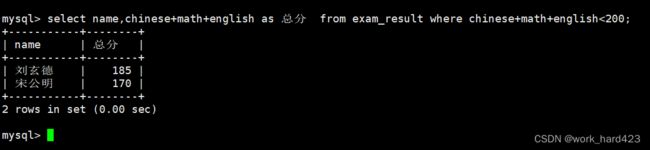
通过where子句查询总成绩在200分以下的同学,如下:
在select语句的属性列表中添加表达式,表达式为语文、数学和英语成绩之和,为了方便观察,咱们为表达式对应的列起个别名叫“总分”,然后在where子句中指明筛选一条数据的条件为三科成绩之和小于200。如下:
注意,如下图所示,在where子句中是不能使用在属性列表中指定的别名的。为什么呢?我们要知道,查询数据的顺序是,先在该表中根据where子句中指定的条件将所有数据逐行筛选,每筛选出一行数据,就将该行数据保存到某个缓冲区中,筛选完毕后,然后再将该缓冲区中的所有数据作为数据源交给select语句,然后select语句再根据属性列表中指定的属性把这一行行数据的对应属性值显示出来。也就是说,where子句的执行是先于select语句的,而别名是在select语句中起的,所以where子句在执行时就不认识该别名,所以在where子句中不能使用别名,如果在where子句中使用别名,那么在查询数据时就会产生报错。

通过where子句查询语文成绩大于80分并且不姓孙的同学,如下:

通过where子句查询孙某同学和总成绩大于200分并且语文成绩小于数学成绩并且英语成绩大于80分的同学,如下:

NULL的查询
为了演示NULL的查询,咱们先创建一个表并插入一些数据,如下:

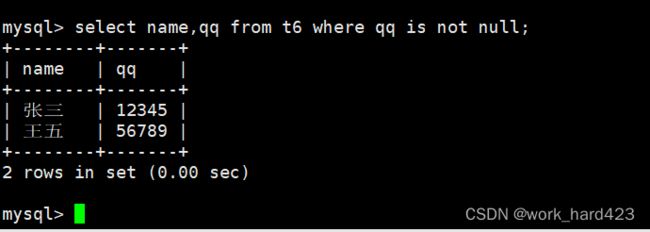
通过where子句查询qq号不为NULL的人,如下:
通过where子句查询QQ号为NULL的人,如下:
- 方式1如下。
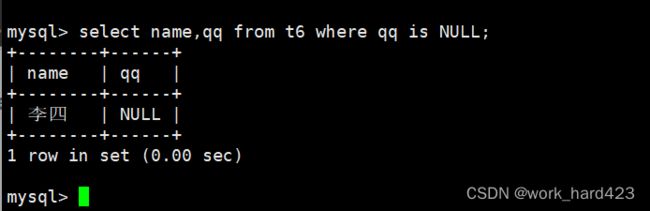
- 方式2如下。
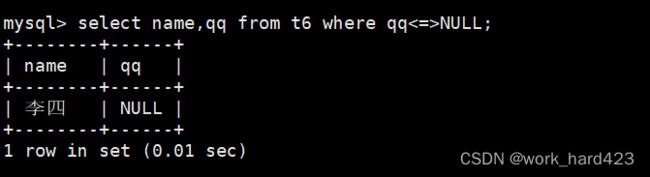
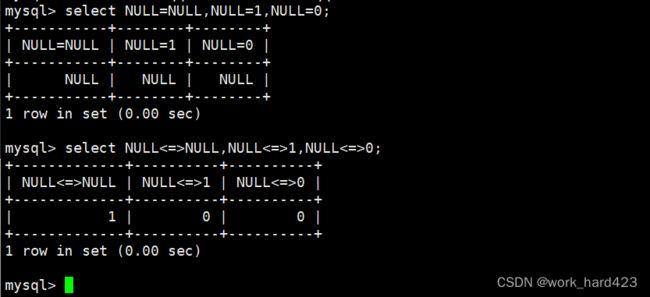
再次强调,在与NULL值作比较的时候应该使用<=>运算符,使用=运算符无法得到正确的查询结果,这是因为=运算符是NULL不安全的,将任何值使用=运算符与NULL作比较时,得到的结果都是NULL,而不是true(即1),如下:
order by子句,即在多条数据中根据数据的某些属性将多条数据排序
在上文所有的select查询中,我们都是没有加上order by子句,也就是没有对需要显示的数据进行排序的,而现在我们要知道的是,如果在查询数据时加上了order by子句,也就是指定了要对显示出的数据进行排序、指定了排序的依据,那么在查询数据时MySQL把所有符合条件的一行行数据筛选出来并保存到某个缓冲区后、MySQL把缓冲区中的所有数据交给select语句让select语句显示时,这些需要被显示的数据就会根据order by子句指定的排序依据进行排序。
order by子句的语法如下:
select 属性列表 from 表名称 where子句 order by 作为排序依据的属性1 [asc | desc],作为排序依据的属性2 [asc | desc],...;
说明一下:
- [ ]中的内容代表的是可选项,即可以省略不写。
- [ ]中的 | 表示或者,表示可以选择 | 左侧的语句,也可以选择 | 右侧的语句,但不能同时选择。
- asc表示按照作为排序依据的属性的大小排升序(ascending翻译为升序);desc表示按照作为排序依据的属性的大小排降序(descending翻译为降序)。
通过where子句查询同学及其数学成绩,并通过order by子句将所有同学按照数学成绩排成升序,如下:

通过where子句查询同学的各门成绩,并通过order by子句将所有同学按照数学成绩排成升序、如果数学成绩相同,则再按照英语成绩排成升序、如果英语成绩也相同,则再按照语文成绩排成升序,如下:
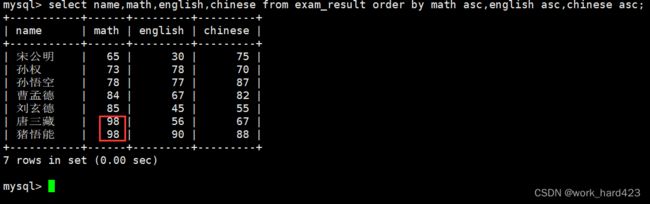
如上图红框处,可以看到数学成绩相同的唐三藏同学和猪悟能同学的确会再按照英语成绩排升序。说明一下,在order by子句中可以指明按照多个属性将一行行数据进行排序,每个属性都可以指明按照升序或降序进行排序,各个属性之间使用逗号隔开,排序优先级与书写顺序相同。这也是为什么上图中是先按照数学排,再按照英语排,最后按照语文排。
通过where子句查询同学及其总分,并通过order by子句将所有同学按照总分成绩排成降序,如下:

说明一下,在order by子句中是可以使用在select中指定的别名“总分”的。为什么呢?
- 我们要知道,查询数据的顺序是,先在该表中根据where子句中指定的条件将所有数据逐行筛选,每筛选出一行数据,就将该行数据保存到某个缓冲区A中,筛选完毕后,然后再将该缓冲区A中的所有数据作为数据源交给select语句,然后select语句再根据【用户指定要显示数据的哪些属性】把所有数据进行“裁剪”,然后把“裁剪”后的所有数据保存在另一个缓冲区B中,然后再将缓冲区B中的所有数据交给order by子句,让order by子句将一行行数据进行排序,最后MySQL再将排好序的数据显示出来。
- 也就是说,查询数据时是先根据where子句筛选出符合条件的数据。然后再将符合条件的数据作为数据源来依次执行select语句。最后再通过order by子句对select语句的执行结果进行排序。换言之,order by子句的执行是在select语句之后的,而因为别名是在select语句中拟定的,所以在order by子句中也就可以使用别名了。
- 为什么order by子句的执行是在select语句之后的呢?因为排序多条数据本质是需要拷贝挪动多条数据的,相比于拷贝一条数据的所有属性,只拷贝一条数据的某几个属性(即只拷贝被“裁剪”后的数据)当然更加省力、更加简便、更加能提高排序的效率,所以才让select语句先执行以“裁剪”数据,再让order by子句执行以排序“裁剪”后的数据。这就是为什么order by子句的执行是在select语句之后的原因了。
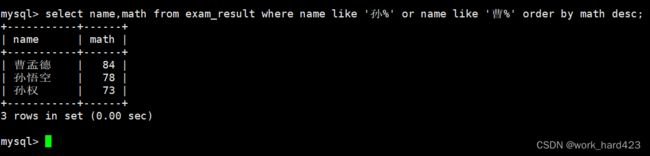
通过where子句查询【孙某和曹某】的姓名和数学成绩,并通过order by子句将这些人按照数学成绩排成降序,如下:
关于order by,最后再补充一些细节,如下:
在下图中我们对varchar(L)这种字符类型的值进行了排升序,并且还让NULL也参与了排升序,从下图的排序结果我们可以看出,虽然在上文中我们说过NULL表示空、NULL不参与比较,但如果非要对NULL进行排序,那么NULL一定是最小值;
然后要说的是,对char(L)或者varchar(L)类型的值做比较的时候,值与值之间不是根据字符串的长度来比较大小的,而是根据字符串中的每个字符的阿斯克码值的大小来比较大小,举几个例子。
- 比如说在下图中,空字符的阿斯克码值是0,字符1的阿斯克码是49,字符3的阿斯克码是51,所以空字符除了比NULL大,是比[email protected]、[email protected]、[email protected]都要小的,所以空字符才在NULL的下面一个位置上。
- 再比如在下图中,因为@的阿斯克码值是64,6的阿斯克码值是54,所以[email protected]中的字符6和[email protected]中的字符@比较时,排出的结果是[email protected]小于[email protected],所以[email protected]才在[email protected]的下面一个位置上。

limit子句,即带上指定的条件将查询结果进行分页(说简单点就是指明要显示查询结果中的哪几行数据)
我们有时候是有一种【只显示查询结果中的第x行到第y行的数据】的需求的,比如在学生的成绩表中通过order by子句对查询结果做排序后,只想看到前20名同学的成绩。这时就需要加上limit子句对需要显示的数据(即查询结果)进行分页了(说简单点就是在需要被显示的数据也就是查询结果中再指明只显示这部分数据中的哪些数据),limit子句的语法如下。
//表示从查询结果的第1条数据开始显示,总共向后显示n条数据
select语句 [where子句] [order by子句] LIMIT n;
//表示从查询结果的第s条数据开始显示,总共向后显示n条数据
select语句 [where子句] [order by子句] LIMIT s,n;
//表示从查询结果的第s条数据开始显示,总共向后显示n条数据
select语句 [where子句] [order by子句] LIMIT n offset s;对上面SQL语句的说明如下:
- [ ]中的内容代表的是可选项,即可以省略不写。
- 如果想从查询结果的第一条数据开始显示,总共向后显示5条数据,则指定的参数s应该为0,而不是1;指定的参数n则为5。
对上面SQL语句的演示如下。需要注意的是,如果是从查询结果的第s条数据开始显示,总共向后显示n条数据,当后面的数据已经不够n条时,则有多少就显示多少,如下图中从第6条数据开始向后显示3条数据时,因为数据不够3条,所以只显示出了宋公明;如果后面完全没有数据,则MySQL会直接提示empty set。

再补充一个limit子句的用途,比如说我们在leetcode刷题时,通常一个页面只能容纳得下30题题目,想要看到下一个30题就得进入第二页,本质上这也是通过limit子句实现的。
修改表中的数据
update 要修改的表的名称 set 要修改的属性1=值1,要修改的属性2=值2,... [where子句] [order by子句] [limit子句];
用于【修改表中数据的某些属性的值】的SQL语句如上所示。说一下,[ ]中的内容代表的是可选项,即可以省略不写。
提醒一下,在修改表中数据的某些属性的值时,如果只是想修改表中某几行数据的对应属性的值,而不是想修改表中每一行数据的对应属性的值,则是一定要在SQL语句中加上where、或者是order by、又或者是limit子句进行数据筛选的,因为如果不进行筛选,则update语句会把表中每一行数据的对应属性的值给修改掉。
接下来咱们实操演示一下update语句。
将孙悟空同学的数学成绩修改为80分,如下:
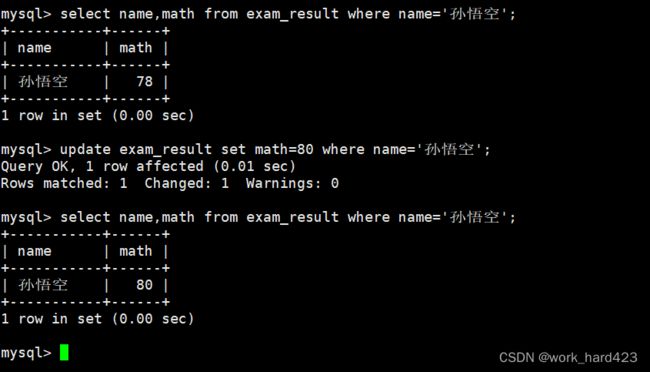
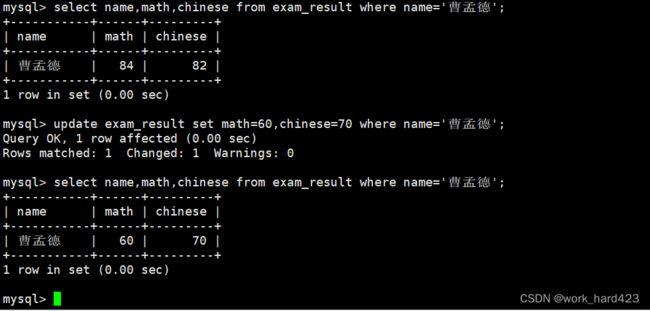
将曹孟德同学的数学成绩修改为60分,语文成绩修改为70分,如下:
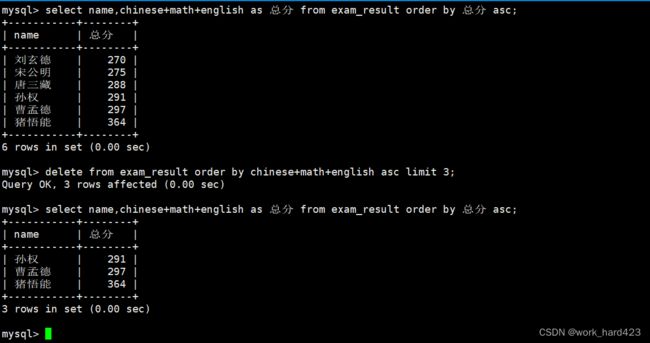
将总成绩倒数前三的3位同学的数学成绩加上30分,如下:
说明一下,下图红框处的表格是全班的总成绩;下图蓝框处的SQL语句用于找出总成绩倒数前三的3位同学;下图黄框处的SQL语句用于给总成绩倒数前三的3位同学的数学成绩加上30分;下图粉框处的SQL语句用于查看加上30分后的3位同学的成绩情况。
注意,在MySQL中是不支持+=、-=这样的复合赋值运算符的,并且这里在查看更新后的数据时不能查看总成绩倒数前三的3位同学,因为之前总成绩倒数前三的3位同学,数学成绩加上30分后可能就不再是倒数前三了,所以下图粉框处的SQL语句才用了where name in去指定查看对应的3位同学的成绩。

将所有同学的语文成绩修改为原来的2倍,如下:

删除表中的数据
delete from 表的名称 [where子句] [order by子句] [limit 子句];
用于【删除表中数据】的SQL语句如上所示。说一下,[ ]中的内容代表的是可选项,即可以省略不写。然后要说的是,delete from语句不能只删除一行数据中的某几个属性,而只能删除整行数据。
提醒一下,在删除表中的数据时,如果只是想删除表中的某几行数据,而不是想删除表中的每一行数据,则是一定要在SQL语句中加上where、或者是order by、又或者是limit子句进行数据筛选的,因为如果不进行筛选,则delete from语句会把表中每一行数据给删除掉,如下:
接下来咱们实操演示一下delete from语句。
删除孙悟空同学的考试成绩,如下:

删除总分成绩倒数前三的3位同学,如下:
关于delete from语句,我们最后再补充一些细节,如下。
如下图所示,为了演示,我们先创建一张测试表,表中包含设置了自增长约束的属性id和属性name。创建完毕后,我们再任意插入一些数据。
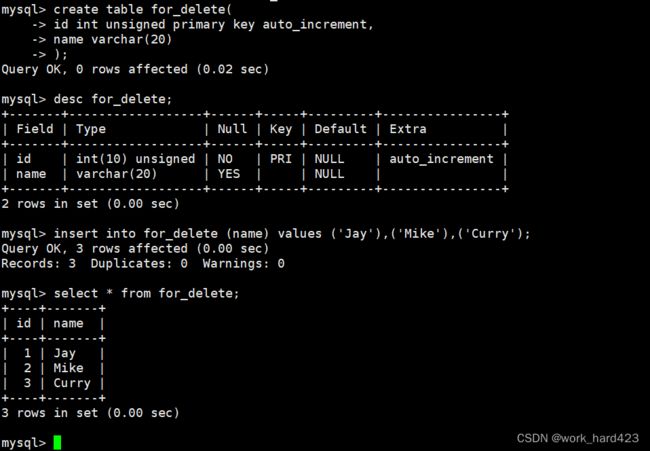
在上文中说过,如果delete from语句不通过where、order by、limit子句中的任意一个子句进行数据的筛选,则delete from语句会把表中每一行数据给删除掉,即删除整张表的数据,如下图1所示,我们先把整张表的数据删除,然后再插入一些新的数据(有人可能会疑惑,说【整张表都被删除了,表都不存在了,凭什么还能插入新的数据呢?】这里笔者要说的是,delete from删除的是表的数据,而不是表的结构,所以我们delete from删除整张表的数据后是可以再插入新数据的,不要把delete from和drop table语句混淆了),插入后再查看表可以发现,插入数据对应的自增长id值是在之前的基础上继续增长的。
那么这是为什么呢?如下图2的红框处所示,就是因为【有一个AUTO_INCREMENT字段记录了下一次插入数据时,该把数据中被设置了自增长约束的属性的值填成多少】。从这我们也能看出,当通过delete from语句删除整表数据时,MySQL是不会重置AUTO_INCREMENT字段上的值的,如下图3可以更加佐证这一点。这就是删除整表数据后再插入新数据时,新数据中自增长的属性id会在原来的基础上继续增长的原因了。
- 图1如下。
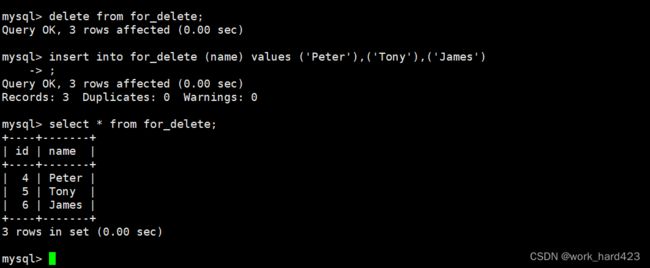
- 图2如下。

- 图3如下。
截断表中的数据
truncate [table] 表名称;
用于【截断表中数据】的SQL语句如上所示,说一下,[ ]中的内容代表的是可选项,即可以省略不写。truncate语句本质也用于删除表中的数据,但通过truncate语句的语法我们可以发现,truncate语句是不能通过where、order by、limit子句指定只删除被筛选出来的数据的,而是只能对整张表做操作,所以说简单点截断表就是删除整张表中的每一行数据。
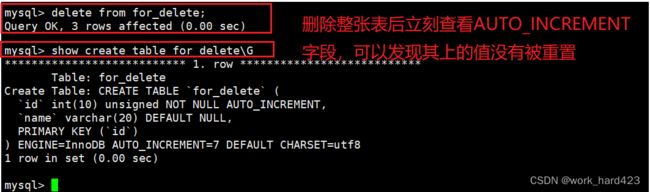
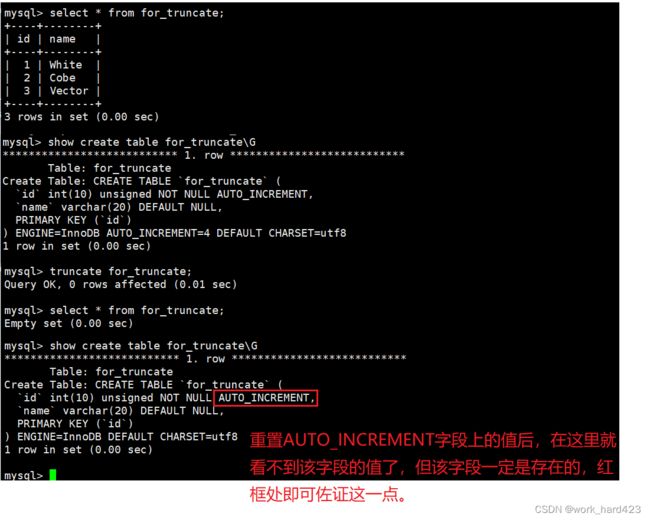
换言之【truncate 表名称】就基本等价于【delete from 表名称】,二者唯一的区别在于,truncate会重置在上一段中说的AUTO_INCREMENT字段上的值,比如说如下图1即可证明这一点:在其中我们先把整张表的数据删除(即先删除下图1红框处的表),然后再插入一些新的数据,插入后再查看表(即下图1蓝框处的表)可以发现,插入数据对应的自增长id值的确被重置了。
再比如说如下图2也可以证明这一点:在其中截断表后立刻通过show create table语句查看其中的AUTO_INCREMENT字段,可以发现无法在其中看见该字段,这就说明该字段的值被重置了、说明目前该字段上没有值(注意看不见该字段只是表示该字段被重置了,而不表示自增长约束被取消了,如下图2的红框处即可证明该约束还存在)。
- 图1如下。

- 图2如下。
向表中插入查询结果
insert [into] 表名称 [(属性1,属性2,...)] select语句 [where子句] [order by子句] [limit子句];
上面SQL语句的作用为:【将完整的select语句所要显示的每一条数据全部插入到指定的表中,insert语句中的属性1、属性2表示在插入时只插入这些属性】。说一下,[ ]中的内容代表的是可选项,即可以省略不写。
接下来咱们实操演示一下该SQL语句。
删除表中重复的记录,重复的数据只能有一份,如下:
如下图所示,为了演示,咱们先创建一张测试表,表中包含属性id和属性name。创建表完毕后,再向测试表中插入一些测试数据,数据中要存在重复的记录。
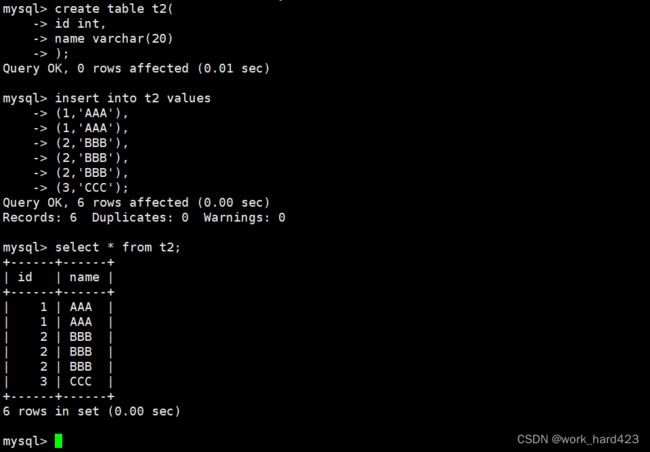
现在要求删除测试表中重复的数据,思路为:先创建一张临时表,让该表的结构与测试表的结构相同。然后以去重的方式查询测试表中的数据,并将查询结果插入到临时表中。最后将测试表重命名为其他名字,再将临时表重命名为测试表的名字,这样一来,就变相地实现了【删除测试表中重复的数据】。
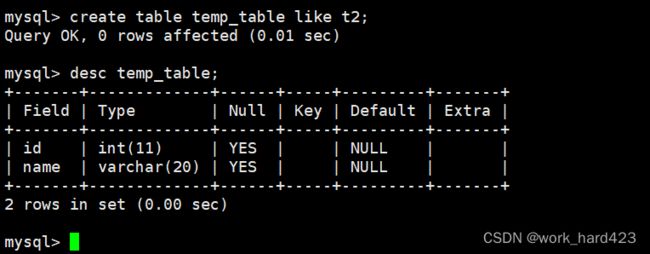
根据上面的思路,由于临时表的结构与测试表相同,因此在创建临时表的时候可以借助like进行创建。如下:
根据上面的思路,此时再以去重的方式查询测试表中的数据并将查询结果插入到临时表中,说一下,由于临时表和测试表的结构相同,并且select进行的是全列查询,因此在insert插入时不用在表名称后指明属性列表。如下:

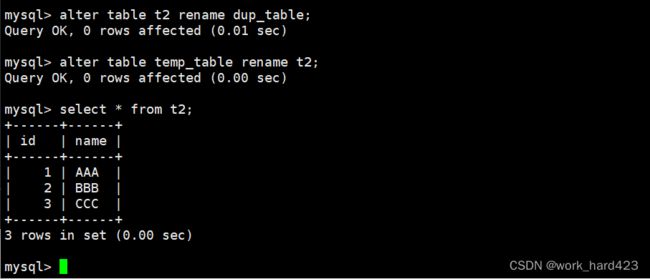
将测试表重命名为其他名字(这相当于对去重前的数据进行备份,如果不需要可以直接删除),将临时表重命名为测试表的名字,这时就变相地完成了表中数据的去重操作。如下:
聚合函数
聚合函数用于对多条数据的若干属性做操作,常见的聚合函数如下所示。说一下,聚合函数之所以叫“聚合”,就是因为这些函数是对多条数据做操作。说一下,[ ]中的内容代表的是可选项,即可以省略不写。

接下来咱们实操演示一下聚合函数。
count函数

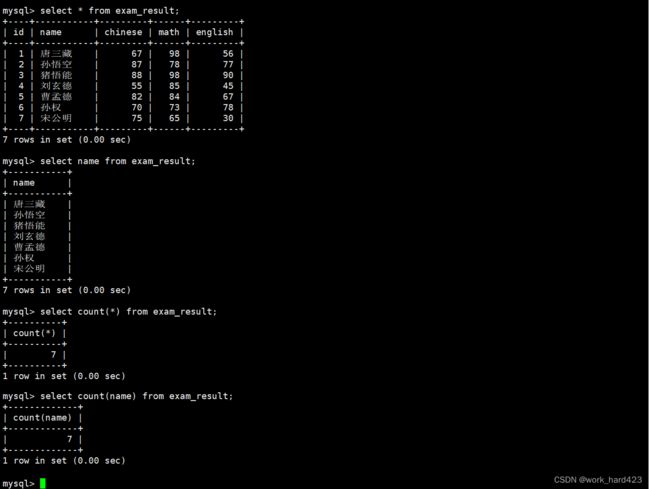
统计班级共有多少同学,如下:
- 方式1如下。如下图的count(name)就叫做【返回根据表达式(该表达式中只有属性name)查到的数据的数量或者说条数】。说一下,因为每一条数据都有属性name,所以我们就可以通过count聚合函数和表达式 name 来统计表中共有多少条数据。
- 方式2如下。注意下图的count(1)也叫做【返回根据表达式(该表达式就是 1 )查到的数据的数量或者说条数】。之所以可以存在count(1)这样的写法,是因为如下图红框处所示,在MySQL中如果在select语句后面添加一个表达式,则该表达式会被拼凑在每一条数据中,所以我们就可以通过count聚合函数和表达式 1 来统计表中共有多少条数据。

注意count函数在【返回根据表达式查到的数据的数量或者说条数】时,如果在某条数据中该表达式的值是NULL,则count函数就不会将该条数据统计进最后的统计结果中,如下:
可以发现下图中的现象即可证明上面的这一观点,比如说根据表达式 num1 查到的数据的数量为2(第二条数据的num1值为NULL,第一条和第三条数据的num1值不为NULL,即共有两条数据的num1属性值不为NULL,所以根据表达式num1查到的数据的数量或者说条数为2);
再比如说根据表达式 num2 查到的数据的数量为1(第一条和第二条数据的num2值为NULL,第三条数据的num2值不为NULL,即共有一条数据的num2属性值不为NULL,所以根据表达式num2查到的数据的数量或者说条数为1);
再比如说根据表达式 num3 查到的数据的数量为3(第一条、第二条和第三条数据的num3值都不为NULL,即共有三条数据的num3属性值不为NULL,所以根据表达式num3查到的数据的数量或者说条数为3);
最后比如说根据表达式 num1+num2+num3 查到的数据的数量为1(要知道,任何值强行和NULL相加减乘除,都会得到NULL,如下图中1+NULL得到的结果就是NULL,所以在第一条数据中,因为属性num2的值是NULL,所以第一条数据在表达式num1+num2+num3上的值就是NULL,同理第二条数据在表达式num1+num2+num3上的值也是NULL,只有第三条数据在表达式num1+num2+num3上的值不为NULL,即共有一条数据在表达式num1+num2+num3上的值不为NULL,所以根据表达式num1+num2+num3查到的数据的数量或者说条数为1)。
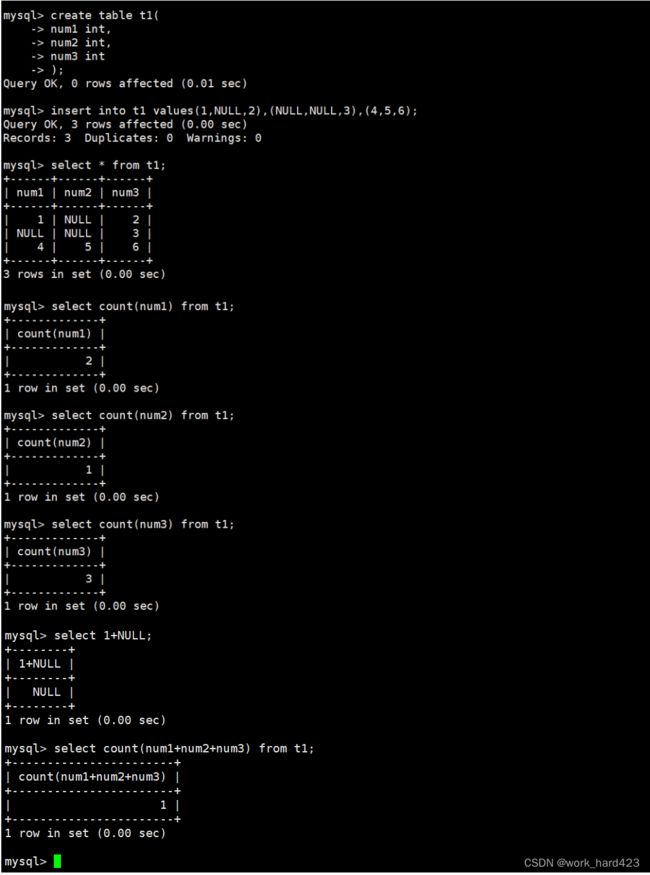
分别统计没有经过去重的数学成绩的分数个数和去重后的数学成绩的分数个数,如下:
说一下,如下图红框处所示,如果在count函数中不加上distinct关键字,则统计的是表中数学成绩的个数;如下图蓝框处所示,如果在count函数中加上distinct关键字,则统计的是表中数学成绩去重后的个数。
sum函数
![]()
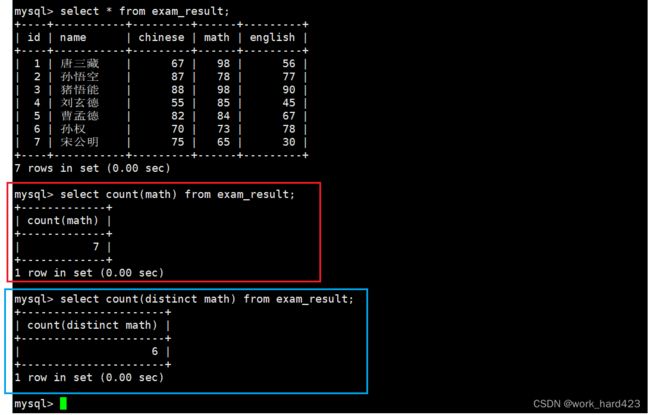
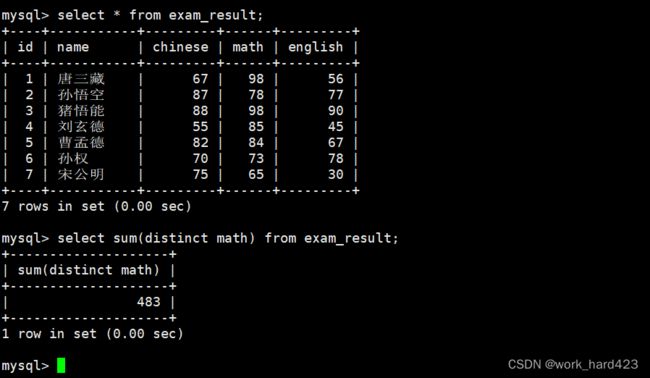
计算所有数学成绩的总和,如下:
如下图的sum(math)就叫做【返回所有数据在该表达式(该表达式中只有属性math)上的总和】。说一下,因为每一条数据都有属性math,所以我们就可以通过sum聚合函数和表达式 math 来计算表中所有数据在属性math上的总和。
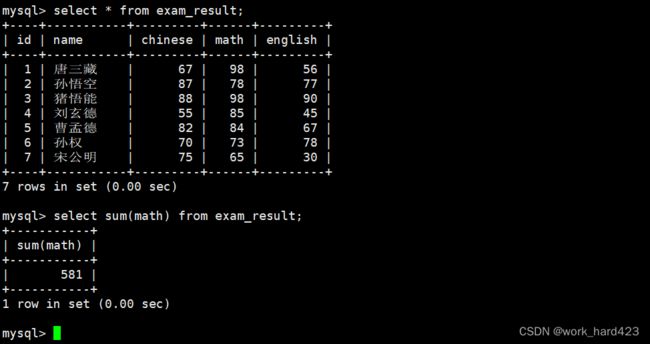
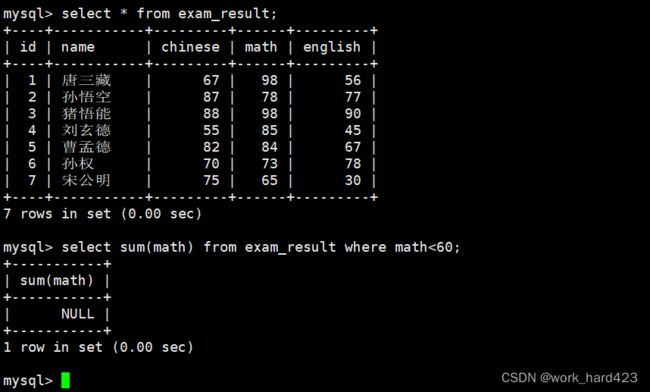
计算所有不及格的数学成绩的总和,如下:
聚合函数一定是后于where子句执行的,所以这里的情况相比于上一段的情况,唯一的区别就是先筛选出一些数据,然后再由sum(math)返回【所有筛选出的数据在该表达式(该表达式中只有属性math)上的总和】。
说一下,由于当前没有数学不及格的同学,因此被筛选出来的数据条数为0条,因此sum(math)的求和结果为NULL。
计算去重后的所有数学成绩的总和,如下:
即所有数学成绩先去重,再计算总和。
注意sum函数在【返回所有数据在表达式上的总和】时,如果在某条数据中该表达式的值是NULL,则sum函数就不会让该条数据参与计算,如下:
可以发现下图中的现象即可证明上面的这一观点,比如说计算出的所有数据在表达式 num1 上的总和为5(第二条数据的num1值为NULL,第一条和第三条数据的num1值不为NULL,所以第一条和第三条数据参与计算,最后1+4=5);
再比如说计算出的所有数据在表达式 num2 上的总和为5(第一条和第二条数据的num2值为NULL,第三条数据的num2值不为NULL,所以只有第三条数据参与计算,最后5=5);
再比如说计算出的所有数据在表达式 num3 上的总和为11(第一条、第二条和第三条数据的num3值都不为NULL,所以三条数据全部参与计算,最后2+3+6=11);
最后比如说计算出的所有数据在表达式 num1+num2+num3 上的总和为15(要知道,任何值强行和NULL相加减乘除,都会得到NULL,如下图中1+NULL得到的结果就是NULL,所以在第一条数据中,因为属性num2的值是NULL,所以第一条数据在表达式num1+num2+num3上的值就是NULL,同理第二条数据在表达式num1+num2+num3上的值也是NULL,只有第三条数据在表达式num1+num2+num3上的值不为NULL,所以只有第三条数据参与计算,最后15=15)。

avg函数

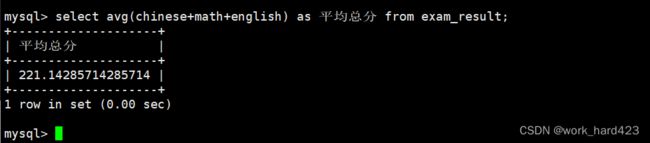
计算所有同学的平均总分,如下:
如下图的avg(chinese+math+english)就叫做【返回所有数据在该表达式(表达式为chinese+math+english)上的平均值】。说一下,因为每一条数据都有属性chinese、math、english,所以我们就可以通过avg聚合函数和表达式 chinese+math+english 来计算表中所有数据在表达式 chinese+math+english 上的平均值。
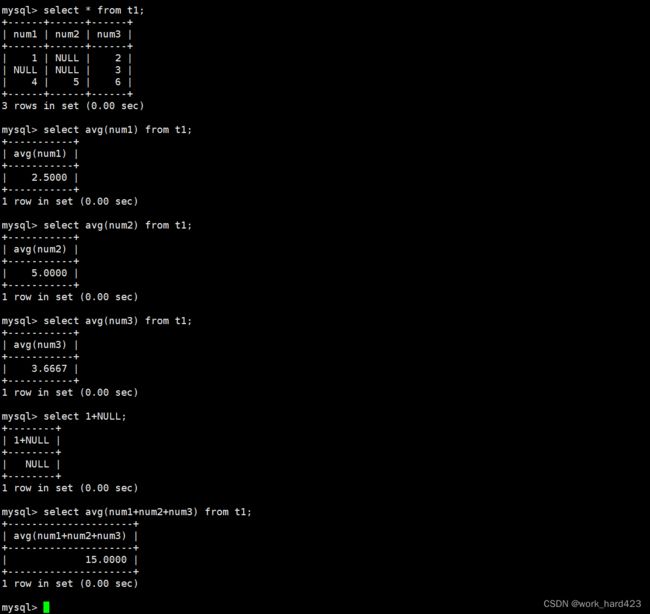
注意avg函数在【返回所有数据在表达式上的平均值】时,如果在某条数据中该表达式的值是NULL,则avg函数就不会让该条数据参与计算,如下:
可以发现下图中的现象即可证明上面的这一观点,比如说计算出的所有数据在表达式 num1 上的平均值为2.5(第二条数据的num1值为NULL,第一条和第三条数据的num1值不为NULL,所以第一条和第三条数据参与计算,最后(1+4)/2=2.5);
再比如说计算出的所有数据在表达式 num2 上的平均值为5(第一条和第二条数据的num2值为NULL,第三条数据的num2值不为NULL,所以只有第三条数据参与计算,最后(5)/1=5);
再比如说计算出的所有数据在表达式 num3 上的平均值为3.6667(第一条、第二条和第三条数据的num3值都不为NULL,所以三条数据全部参与计算,最后(2+3+6)/3=3.6667);
最后比如说计算出的所有数据在表达式 num1+num2+num3 上的平均值为15(要知道,任何值强行和NULL相加减乘除,都会得到NULL,如下图中1+NULL得到的结果就是NULL,所以在第一条数据中,因为属性num2的值是NULL,所以第一条数据在表达式num1+num2+num3上的值就是NULL,同理第二条数据在表达式num1+num2+num3上的值也是NULL,只有第三条数据在表达式num1+num2+num3上的值不为NULL,所以只有第三条数据参与计算,最后(15)/1=15)。
计算去重后的所有数学成绩的平均值,如下:
即所有数学成绩先去重,再计算平均值。

max函数
![]()
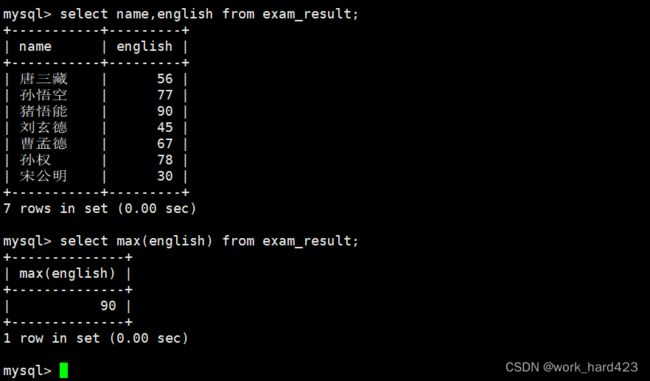
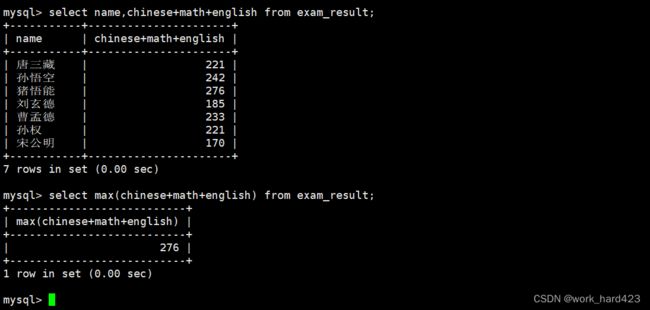
返回英语最高分,如下:
如下图的max(english)就叫做【返回所有数据在该表达式(表达式为english)上的最大值】。说一下,因为每一条数据都有属性english,所以我们就可以通过max聚合函数和表达式 english 来计算表中所有数据在表达式 english 上的最大值。
返回总分最高分,如下:
如下图的max(chinese+math+english)就叫做【返回所有数据在该表达式(表达式为chinese+math+english)上的最大值】。说一下,因为每一条数据都有属性chinese、math、english,所以我们就可以通过max聚合函数和表达式 chinese+math+english 来计算表中所有数据在表达式 chinese+math+english 上的最大值。
min函数

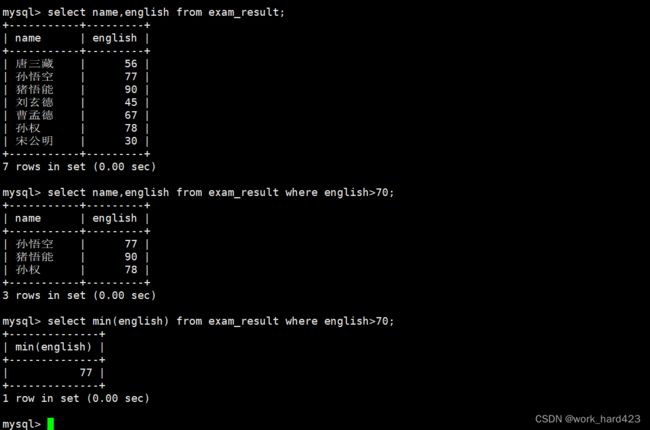
返回70分以上的英语最低分,如下:
聚合函数一定是后于where子句执行的,所以如下图所示,这里先通过where子句筛选数据,然后再由min(english)返回【所有被筛选出来的数据在该表达式(表达式为english)上的最小值】。说一下,因为每一条数据都有属性english,所以我们就可以通过min聚合函数和表达式 english 来计算被筛选出的所有数据在表达式 english 上的最小值。
分组查询
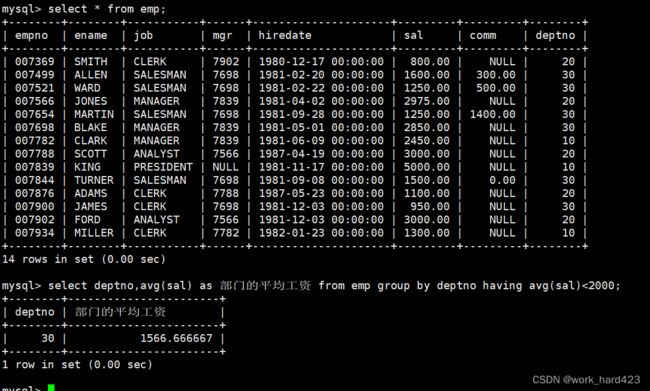
有时我们在现实中是有获取【一个公司中的各个部门的平均工资】的需求的,所以在MySQL中,MySQL是一定要支持按照某些属性将整张表进行分组的功能的,否则如下图所示,如果所有部门的所有员工都被存在一张表中,则想要统计出每个部门的平均工资就得频繁先通过where子句和部门号单独把每个部门中的所有员工筛选出来,再计算该部门中所有员工的平均工资。有多频繁呢?有多少个部门,则就要写多少次该SQL语句,这是因为每次该SQL语句都只会计算出一个部门的平均工资,换言之,通过这样的方式我们还不能在一张表中看见每个部门的平均成绩,因为一张表中只有一个部门的平均工资。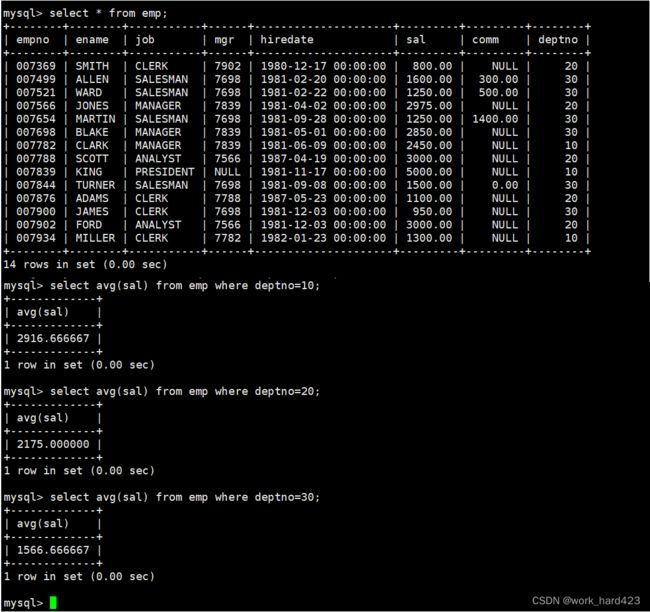
综上所述,我们可知MySQL是一定要支持按照某些属性将整张表进行分组的功能的,而用于分组的SQL语句就如下。
select语句 [where子句] group by 作为分组依据的属性1,作为分组依据的属性2,... [order by子句] [limit子句];
说明一下:
- [ ]中的内容代表的是可选项,即可以省略不写。
- 然后目前我们要知道的是,查询SQL语句中各个关键字的执行顺序为:from、where、group by、select、order by、limit。
- group by后面的属性名,表示按照指定属性将所有数据进行分组。
- 注意,除了聚合函数外,如果一个属性不在group by关键字的后面,则该属性不能出现在select关键字的后面。所以如下图所示,红框处的聚合函数可以出现,而黄框处的属性job不能出现,否则报错。

- 最后说一个非常重要的结论,group by子句一定是用于配合在select关键字后的聚合函数在未来做聚合统计的。换言之,如果未来用户需要进行group by分组,则一定是因为用户需要在select关键字后使用聚合函数,比如说就是因为用户需要使用avg()聚合函数来计算每个部门的平均工资,所以才需要group by按照部门号进行分组;换言之,如果未来用户不需要在select关键字后使用聚合函数,则未来用户是不需要进行group by分组的,当然如果你非要分组,则也是可以的,只是说此时分组就没有什么意义,这是因为当你不需要使用聚合函数做聚合统计时,无论你的目的是什么,你不进行group by分组也一定同样可以达到你的目的。
接下来咱们实操演示一下该SQL语句。
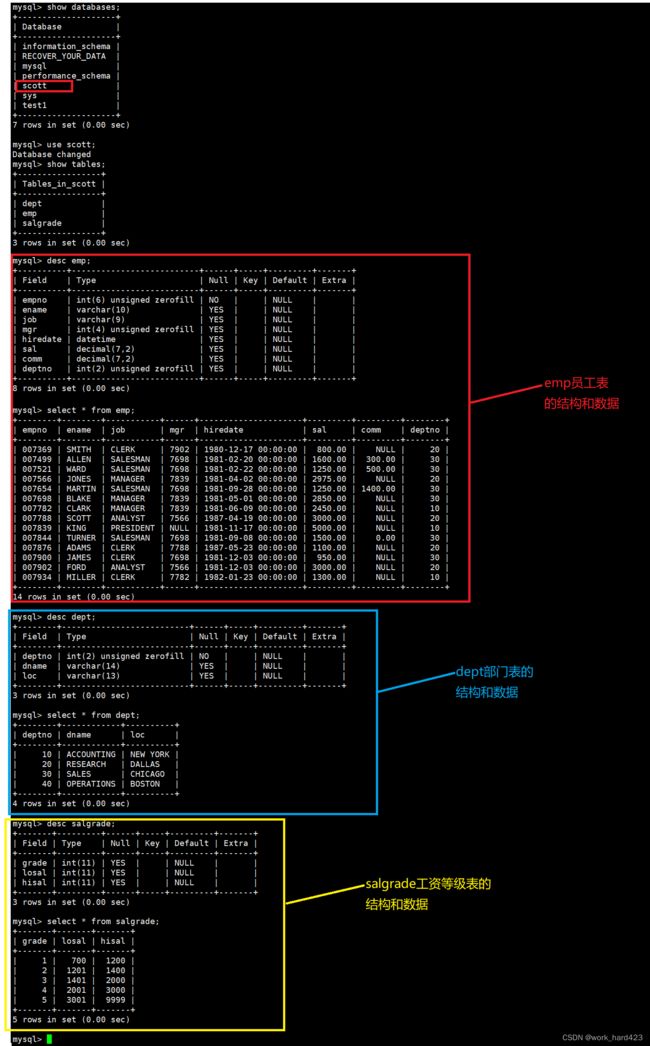
为了演示,咱们先创建一个用于存储所有雇员信息的scott数据库DB,再在该DB中创建三张表,分别是员工表(emp)、部门表(dept)和工资等级表(salgrade),各个表的结构如下图所示。数据库DB和3张表的结构创建完毕后,咱们再插入一些数据。

在上一段中说的所有的前置工作,直接通过【把下面的SQL语句拷贝到MySQL中执行一遍】即可全部做到。
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `scott`;
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',
`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',
`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (
`grade` int(11) DEFAULT NULL COMMENT '等级',
`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',
`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);
insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
如下图所示,执行完上面的SQL语句后,就有数据库scott和三张表、以及各个表中的数据了。
准备工作完毕后,咱们进入正题。
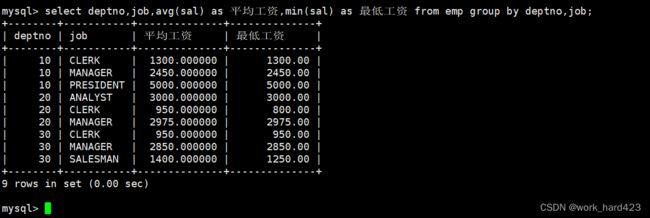
显示每个部门的平均工资和最高工资,如下:
如下图所示,在group by子句中指明按照部门号进行分组,在select语句中使用聚合函数avg和max分别计算每个部门的平均工资和最高工资。注意,下图的SQL语句是先将表中的数据按照部门号进行分组,然后各自在组内做聚合查询得到每个组的平均工资和最高工资,所以可以认为下面的每一条数据实际上代表的是由一组个体组成的群体,而不是代表一个个体。
- 说一下,因为属性sal(即工资)只存在于员工表emp中,所以下面在select from查表时就只能查emp表了。同时又因为员工表中和部门有关的属性只有deptno(即部门编号),没有dname(即部门名称)和loc(即部门所在地),所以在group by分组时我们就只能通过属性deptno了。

显示每个部门的每种岗位的平均工资和最低工资,如下:
在group by子句中指明依次按照部门号和岗位进行分组(将整张表先按照部门号划分,即把所有在属性deptno上相等的数据划分成一组,然后将划分好的每一组数据再按照岗位划分,即在每一组数据中,把所有在属性job上相等的数据再划分成一组),然后在select语句中使用avg函数和min函数分别查询每个部门的每种岗位的平均工资和最低工资。
- 说一下,因为属性sal(即工资)只存在于员工表emp中,所以下面在select from查表时就只能查emp表了。同时又因为指明了要依次按照部门号和岗位进行分组,所以在group by分组时我们通过的属性就是deptno和job了。
- 然后要说的是,group by子句中是可以指明按照多个属性进行分组的,各个属性之间使用逗号隔开,分组优先级与书写顺序相同。比如上述SQL中,当多条数据的部门号相同时,MySQL会继续按照岗位将多条数据进行分组。
having子句
有时我们在现实中除了有获取【一个公司中的各个部门的平均工资】的需求外,我们还有【找出平均工资大于1500的部门】的需求,所以MySQL不光要支持分组功能(以此按照部门号将整张员工表进行分组进而计算出各个部门的平均工资),还要支持筛选功能(以此在计算出的各个部门的平均工资中找出平均工资大于1500的部门),为此,MySQL就提供了having关键字来进行数据的筛选。完整的SQL语句如下:
select语句 [where子句] [group by子句] [having子句] [order by子句] [limit子句];
说明一下:
- [ ]中的内容代表的是可选项,即可以省略不写。
- 然后目前我们要知道的是,查询SQL语句中各个关键字的执行顺序为:from、where、group by、select、having、order by、limit。
- having子句中可以指明一个或多个筛选条件。
- 注意,除了聚合函数外,如果一个属性不在group by关键字的后面,则该属性不能出现在having关键字的后面。所以如下图所示,红框处的聚合函数可以出现,而黄框处的属性job不能出现,否则报错。
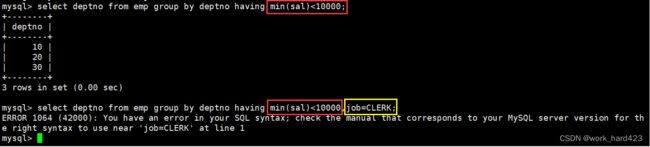
问题:where子句不是已经能筛选数据了吗?为什么还需要搞出一个having子句呢?
- 答案:如下图所示,通过红框中的SQL语句我们可以得知各个部门的平均工资,而黄框处的SQL语句只是在红框处的SQL语句的基础上加了where avg(sal)>2000想以此筛选出平均工资大于2000的部门,然后就导致了黄框处的SQL语句执行失败。这是为什么呢?我们要知道,avg等聚合函数想要执行,首先是得先有数据,然后才能被执行以此聚合多条数据,而where子句是用于筛选出数据的,如果写成where avg(sal)>2000,就相当于数据都还没有被筛选出来时就执行avg聚合函数,这当然会执行失败了。也正是因为在这样的场合下,where子句无法完成筛选数据的任务,于是就诞生了having子句。
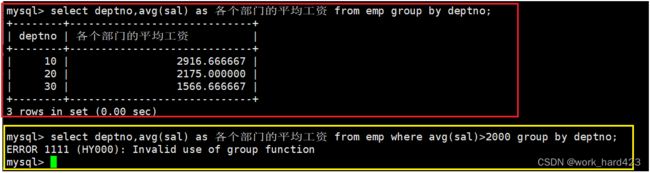
从上面的问题和答案中,我们还能得知如下启示:
- 根据上面的说法【有时where子句无法完成筛选数据的任务,于是就诞生了having子句】,我们可知where子句和having子句是不冲突的,他俩是互补的、是可以同时存在的,所以在一个SQL语句中可以同时存在where子句和having子句。
- where子句和having子句起作用、即进行筛选数据的时机不一样,比如说where子句是在最初筛选数据时起作用;而having子句是在where子句最初筛选数据后、在group by子句对筛选出的数据做分组后、在select对分组后的数据做聚合后,再进行筛选数据。
- 也正是因为having子句的执行是在where、group by、select之后的,所以走到having子句时,用于做聚合的数据已经存在了,select中起的别名也已经知道了,所以having子句中可以使用聚合函数和别名;而where子句中是不能使用聚合函数和别名的,其原因也在上文中都分别说过了,这里不再赘述。
接下来咱们实操演示一下该SQL语句。
显示平均工资低于2000的部门和它的平均工资,如下: