互联网用户信息处理
互联网用户信息处理
1.读取单文本中的序列号和上网时间年龄
import pandas as pd
import re
import os
inpath="association\\2012-05-07\\0B9205B65DE6BAF09AE4AA49F37011A1_2012-05-07_09-03-53.txt"
formatfile="user_duration.csv"
outpath="user_duration_new.csv"
files = pd.read_csv(formatfile,index_col=0)
df = pd.DataFrame(files)
f = open(inpath,encoding='gbk')
#对文件名进行解析,获取用户id
filename=os.path.split(inpath)[1].split(".")[0]
strlist=filename.split('_')
USERID=strlist[0]
file=f.readlines()
for i,line in enumerate(file):
if(i==0) :
a = line.strip('\n')
a=a.replace('[=]','@')
a_lists=a.split("@")
for str in a_lists:
str=str.replace('<=>','@')
result=str.split("@")
if len(result)!=2:
continue
name =result[0]
value =result[1]
if name!='Last':
continue
df.at[USERID,'Duration']=value
break
f.close()
df.to_csv(outpath)
效果如图

2.多文本序列号和上网时间
import pandas as pd
import re
import os
def txt_duration(inpath,formatfile,outpath):
files = pd.read_csv(formatfile,index_col=0)
df = pd.DataFrame(files)
f = open(inpath,encoding='gbk')
#对文件名进行解析,获取用户id
filename=os.path.split(inpath)[1].split(".")[0]
strlist=filename.split('_')
USERID=strlist[0]
file=f.readlines()
for i,line in enumerate(file):
if(i==0) :
a = line.strip('\n')
a=a.replace('[=]','@')
a_lists=a.split("@")
for str in a_lists:
str=str.replace('<=>','@')
result=str.split("@")
if len(result)!=2:
continue
name =result[0]
value =result[1]
if name!='Last':
continue
df.at[USERID,'Duration']=value
break
f.close()
df.to_csv(outpath)
'''
inpath="association\\2012-05-07\\0B9205B65DE6BAF09AE4AA49F37011A1_2012-05-07_09-03-53.txt"
formatfile="user_duration.csv"
outpath="user_duration_new.csv"
txt_duration(inpath,formatfile,outpath)
'''
#对该路径下的文件和目录进行遍历
def print_list_dir(dir_path):
dir_files=os.listdir(dir_path) #得到该文件夹下所有的文件
#formatfile="user_duration.csv"
outpath="user_duration_new.csv"
for file in dir_files:
file_path=os.path.join(dir_path,file) #路径拼接成绝对路径
if os.path.isfile(file_path): #如果是文件,就打印这个文件路径
txt_duration(file_path,outpath,outpath)
if os.path.isdir(file_path): #如果目录,就递归子目录
print_list_dir(file_path)
if __name__ == '__main__':
dir_path='E:\\Reptile_Data\\数智教育数据集\\互联网用户行为日志数据集.rardataset_616718\\association\\2012-05-07'
print_list_dir(dir_path)
效果如图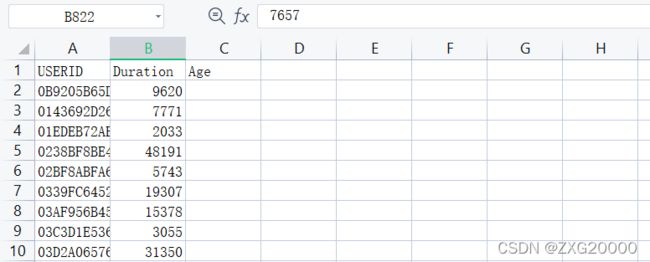
4.将年龄变更为年龄段,并将年龄段排序
转换参考的目录
https://blog.csdn.net/qxqxqzzz/article/details/88356678 could not convert string to float:
错误类型,文本原来的格式为int ,修改生成的数据类型,在头加一段代码
path1="user_duration_newss.csv"
file1 = pd.read_csv(path1,index_col=0)
file1 = pd.DataFrame(file1, dtype='str')
import pandas as pd
import re
import os
path1="user_duration_newss.csv"
file1 = pd.read_csv(path1,index_col=0)
file1 = pd.DataFrame(file1, dtype='str')
df1 = pd.DataFrame(file1)
for i in range(0,len(df1)):
tmpage=str(df1.at[i,'Age'])
Age=""
print(i)
#tmpage=int(strs)
if("0"<=tmpage<"10"):
Age="0_9"
elif ("10"<=tmpage<"20"):
Age="10_19"
elif ("20"<=tmpage<"30"):
Age="20_29"
elif ("30"<=tmpage<"40"):
Age="30_39"
elif ("40"<=tmpage<"50"):
Age="40_49"
elif ("50"<=tmpage<"60"):
Age="50_59"
elif ("60"<=tmpage<"70"):
Age="60_69"
elif ("70"<=tmpage<"80"):
Age="70_79"
elif ("80"<=tmpage<"90"):
Age="80_89"
elif ("90"<=tmpage<"100"):
Age="90_99"
df1.at[i,'Age']=Age
#数据按照年龄段大小排序
df1=df1.sort_values('Age',ascending=True)
df1.to_csv("user_duration_newss.csv")
效果如图
5.连接信息段
import pandas as pd
import math
import re
df1=pd.read_csv('demographic.csv')
df2=pd.read_csv('user_duration_newss.csv')
df3=pd.merge(df1.reset_index(),df2,left_on='USERID',right_on='USERID')
df3.to_csv('duration_demographic_wash.csv',index=False)
效果如图
6.互联网用户24小时使用时间段
import pandas as pd
import math
import os
import re
def process(inpath):
#对文件名进行解析,获取用户id和使用时间段
filename=os.path.split(inpath)[1].split(".")[0]
strlist=filename.split('_')
userid=strlist[0]
startTime=strlist[2].split('-')[0]
start=int(startTime)
startTime=str(start)
return userid,startTime
#对该路径下的文件和目录进行遍历
useridList=[]
usetimeList=[]
def print_list_dir(dir_path):
dir_files=os.listdir(dir_path) #得到该文件夹下所有的文件
for file in dir_files:
file_path=os.path.join(dir_path,file) #路径拼接成绝对路径
if os.path.isfile(file_path): #如果是文件,就打印这个文件路径
[userid,startTime]=process(file_path)
useridList.append(userid)
usetimeList.append(startTime)
#print(userid,startTime)
if os.path.isdir(file_path): #如果目录,就递归子目录
print_list_dir(file_path)
if __name__ == '__main__':
dir_path='E:/Reptile_Data/互联网用户行为日志数据集.rardataset_616718/association/2012-05-07'
print_list_dir(dir_path)
df=pd.DataFrame({'USERID': useridList, 'USETIME': usetimeList})
df.to_csv("USERTIME_wash.csv",encoding='gbk',index=False)
效果如图
互联网用户行为日志分析时间处理
速度很快
1.单文本处理出使用时间
import os
def txt_delete_condition(inpath,outpath):
f = open(inpath,encoding='utf-8')
c=[]
file=f.readlines()
time=0
for i,line in enumerate(file):
if i<2 :
c.append(line)
continue
a = line.strip('\n')
line=line.strip('\n')
a=a.replace('[=]','@')
a_lists=a.split("@")
strs=""
if(line.find("T")==-1):
line=line+"[=]"+"UTIME"+"<=>"+"0"+"\n"
for strss in a_lists:
strss=strss.replace('<=>','@')
result=strss.split("@")
name =result[0]
value =result[1]
if(name=="T"):
strs=str(int(value)-time)
time=int(value)
line=line+"[=]"+"UTIME"+"<=>"+strs+"\n"
c.append(line)
res="".join(c)
with open(outpath,'w') as f:
f.writelines(res)
inpath = "association\\2012-05-07\\0B9205B65DE6BAF09AE4AA49F37011A1_2012-05-07_09-03-53.txt"
txt_delete_condition(inpath,inpath)
处理效果如图UTIME字段为使用时间
2.多文本处理
import os
def txt_process(inpath,outpath):
#f = open(inpath,encoding='utf8')
f = open(inpath,encoding='utf-8')
c=[]
file=f.readlines()
time=0
for i,line in enumerate(file):
if i<2 :
c.append(line)
continue
a = line.strip('\n')
line=line.strip('\n')
a=a.replace('[=]','@')
a_lists=a.split("@")
strs=""
if(line.find("T")==-1):
line=line+"[=]"+"UTIME"+"<=>"+"0"+"\n"
for strss in a_lists:
strss=strss.replace('<=>','@')
result=strss.split("@")
if(len(result)<2):
continue
name =result[0]
value =result[1]
if(name=="T"):
strs=str(int(value)-time)
time=int(value)
line=line+"[=]"+"UTIME"+"<=>"+strs+"\n"
c.append(line)
res="".join(c)
with open(outpath,'w',encoding='utf-8') as f:
f.writelines(res)
#对该路径下的文件和目录进行遍历
def print_list_dir(dir_path):
dir_files=os.listdir(dir_path) #得到该文件夹下所有的文件
formatfile ='new_data.csv'
outpath ='newss_data.csv'
pos=0#定义当前位置
for file in dir_files:
file_path=os.path.join(dir_path,file) #路径拼接成绝对路径
if os.path.isfile(file_path): #如果是文件,就打印这个文件路径
txt_process(file_path,file_path)
if os.path.isdir(file_path): #如果目录,就递归子目录
print_list_dir(file_path)
if __name__ == '__main__':
dir_path='E:\\Reptile_Data\\互联网用户行为日志数据集.rardataset_616718\\association\\2012-05-07'
print_list_dir(dir_path)
3.获取应用使用时间和关联度
USERID和P和UTIME
3.1单文本处理
import pandas as pd
import os
USERIDlist=[]
Plist=[]
UTIMElist=[]
def txt_process(inpath):
f = open(inpath,encoding='utf-8')
filename=os.path.split(inpath)[1].split(".")[0]
strlist=filename.split('_')
USERID=strlist[0]
file=f.readlines()
for i,line in enumerate(file):
if i<2 :
continue
a = line.strip('\n')
USERIDlist.append(USERID)
if(a.find("P")==-1):
Plist.append(" ")
if(a.find("UTIME")==-1):
UTIMElist.append(" ")
a=a.replace('[=]','@')
a_lists=a.split("@")
pflag=True
utimeflag=True
for strss in a_lists:
strss=strss.replace('<=>','@')
result=strss.split("@")
if(len(result)<2):
continue
name =result[0]
value =result[1]
if(name=="P") and pflag:
Plist.append(value)
pflag=False
if(name=="UTIME") and utimeflag:
UTIMElist.append(value)
utimeflag=False
#对该路径下的文件和目录进行遍历
def print_list_dir(dir_path):
dir_files=os.listdir(dir_path) #得到该文件夹下所有的文件
formatfile ='new_data.csv'
outpath ='newss_data.csv'
pos=0#定义当前位置
for file in dir_files:
file_path=os.path.join(dir_path,file) #路径拼接成绝对路径
if os.path.isfile(file_path): #如果是文件,就打印这个文件路径
txt_process(file_path)
if os.path.isdir(file_path): #如果目录,就递归子目录
print_list_dir(file_path)
inpath = "association\\2012-05-07\\0B9205B65DE6BAF09AE4AA49F37011A1_2012-05-07_09-03-53.txt"
txt_process(inpath)
df=pd.DataFrame({"USERID":USERIDlist,"P":Plist,"UTIME":UTIMElist})
df.to_csv("user_P_time.csv",index=False)
处理效果如图
3.2多文本处理
import pandas as pd
import os
USERIDlist=[]
Plist=[]
UTIMElist=[]
def txt_process(inpath):
f = open(inpath,encoding='utf-8')
filename=os.path.split(inpath)[1].split(".")[0]
strlist=filename.split('_')
USERID=strlist[0]
file=f.readlines()
for i,line in enumerate(file):
if i<2 :
continue
a = line.strip('\n')
USERIDlist.append(USERID)
if(a.find("P")==-1):
Plist.append(" ")
if(a.find("UTIME")==-1):
UTIMElist.append(" ")
a=a.replace('[=]','@')
a_lists=a.split("@")
pflag=True
utimeflag=True
for strss in a_lists:
strss=strss.replace('<=>','@')
result=strss.split("@")
if(len(result)<2):
continue
name =result[0]
value =result[1]
if(name=="P") and pflag:
Plist.append(value)
pflag=False
if(name=="UTIME") and utimeflag:
UTIMElist.append(value)
utimeflag=False
#对该路径下的文件和目录进行遍历
def print_list_dir(dir_path):
dir_files=os.listdir(dir_path) #得到该文件夹下所有的文件
formatfile ='new_data.csv'
outpath ='newss_data.csv'
pos=0#定义当前位置
for file in dir_files:
file_path=os.path.join(dir_path,file) #路径拼接成绝对路径
if os.path.isfile(file_path): #如果是文件,就打印这个文件路径
txt_process(file_path)
if os.path.isdir(file_path): #如果目录,就递归子目录
print_list_dir(file_path)
if __name__ == '__main__':
dir_path='E:\\Reptile_Data\\互联网用户行为日志数据集.rardataset_616718\\association\\2012-05-07'
print_list_dir(dir_path)
df=pd.DataFrame({"USERID":USERIDlist,"P":Plist,"UTIME":UTIMElist})
df.to_csv("user_P_time.csv",index=False)
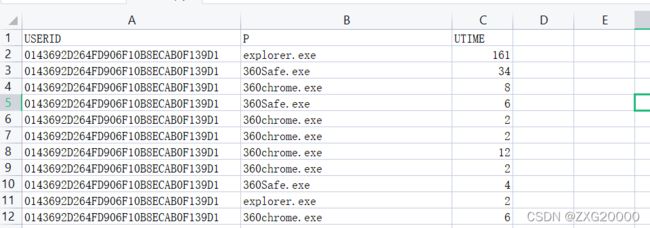
4.查找使用时间最长的15个应用
import pandas as pd
import os
import re
df1=pd.read_csv('user_P_time.csv')
#去除使用时间为负数的
df2=df1[df1['UTIME']>0]
df3=df2.pivot_table(index='P',values='UTIME',aggfunc='sum')
#获得15个时间最长的
df4=df3.nlargest(15,columns='UTIME')
df4.to_csv('user_P_time_wash.csv')
效果如图
5.处理这15个应用的关联度
import pandas as pd
import numpy as np
import os
import re
def process(x):
if(np.isnan(x)!=True):
x=1
return x
df1=pd.read_csv('user_P_time.csv')
#去除使用时间为负数的
df2=df1[df1['UTIME']>0]
df3=df2.pivot_table(index='USERID',columns="P",values='UTIME',aggfunc='count')
#要选取的列
lists=["explorer.exe","QQ.exe","360se.exe","iexplore.exe","IEXPLORE.EXE","sogouexplorer.exe","360chrome.exe","AliIM.exe","EXCEL.EXE","NetSurvey.exe"]
df4=pd.DataFrame(df3,columns=lists)
for name in lists:
df4[name]=df4[name].apply(process)
df4.to_csv('user_P_time_wash1.csv')
处理效果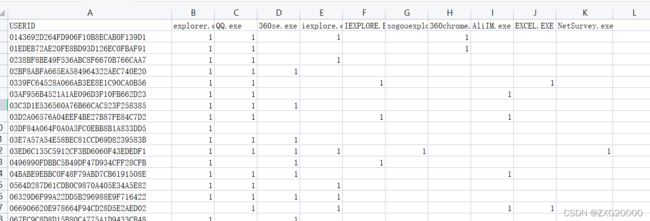
6.使用时间最长的15个网页
6.1获取网页停留时间
import pandas as pd
import os
import re
USERIDlist=[]
Ulist=[]
UTIMElist=[]
#正则匹配提取域名
def url_process(strs):
pattern='([\S]+?\.(com|cn))'
try:
a=re.search(pattern,strs)
strs=a.group(0)
#print('匹配成功,结果为:',a.group(0))
except:#删除不能匹配的行
strs=""
return strs
def txt_process(inpath):
f = open(inpath,encoding='utf-8')
filename=os.path.split(inpath)[1].split(".")[0]
strlist=filename.split('_')
USERID=strlist[0]
file=f.readlines()
for i,line in enumerate(file):
if i<2 :
continue
a = line.strip('\n')
if(a.find("U<=>")==-1):
continue
#Ulist.append(" ")
USERIDlist.append(USERID)
if(a.find("UTIME")==-1):
UTIMElist.append("")
a=a.replace('[=]','@')
a_lists=a.split("@")
uflag=True
utimeflag=True
for strss in a_lists:
strss=strss.replace('<=>','@')
result=strss.split("@")
if(len(result)<2):
if(result[0]=="U"):
Ulist.append("")
uflag=False
continue
name =result[0]
value =result[1]
if(name=="U") and uflag:
value=url_process(value)
Ulist.append(value)
uflag=False
if(name=="UTIME") and utimeflag:
UTIMElist.append(value)
utimeflag=False
f.close()
#对该路径下的文件和目录进行遍历
def print_list_dir(dir_path):
dir_files=os.listdir(dir_path) #得到该文件夹下所有的文件
for file in dir_files:
file_path=os.path.join(dir_path,file) #路径拼接成绝对路径
if os.path.isfile(file_path): #如果是文件,就打印这个文件路径
txt_process(file_path)
if os.path.isdir(file_path): #如果目录,就递归子目录
print_list_dir(file_path)
if __name__ == '__main__':
dir_path='E:\\Reptile_Data\\互联网用户行为日志数据集.rardataset_616718\\association\\2012-05-07'
print_list_dir(dir_path)
print(len(USERIDlist))
print(len(Ulist))
print(len(UTIMElist))
df=pd.DataFrame({"USERID":USERIDlist,"U":Ulist,"UTIME":UTIMElist})
df.to_csv("user_U_time.csv",index=False)
6.2获取网页
处理效果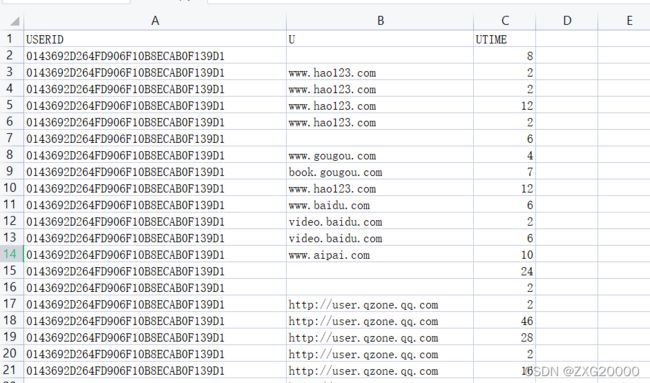
import pandas as pd
import os
import re
df1=pd.read_csv('user_U_time.csv')
#去除使用时间为负数的
df2=df1[df1['UTIME']>0]
df3=df2.pivot_table(index='U',values='UTIME',aggfunc='sum')
#获得15个时间最长的
df4=df3.nlargest(15,columns='UTIME')
df4.to_csv('user_U_time_wash.csv')
