Socket网络编程
网络编程(按照目前的了解,网上能找到更多是关于代码,还有实现架构的,反而一些心得体会的内容比较少,技术可能没有太高,想聊一下自己的体会和感受)
网络通信,和c++各种设计模式一样,没有实际感受到内容或者详细了解清楚的时候,感觉很是抽象。
服务器有明显的一对多特征(只针对服务器和客户端),最笼统的理解就是,很多个客户端访问服务器,就像我们都访问百度的时候。
特别是多用户同时访问服务器,想要打造高效的服务器,个人感觉还是使用异步机制更好(目前在研究异步机制或者 半同步/异步机制)。
同步机制服务器,线程工作流程有点像做数学题,用户做完一步才能做下一步。或者像去某些部门盖章,只能排队等别人盖完后,你才能拿着材料盖章,之后去别的部门排队盖章。
而异步机制下,到了盖章地点,你可以将此处需要盖章的材料放在某个地方去做别的事,到一定的时间或者被通知盖好章了再来取走,这期间也不用自己排队等着盖章,还可以去做别的部门盖章交材料(可能在跑遍所有部门后,就可以从第一个开始取自己的材料了))
记得小学大家都学过的一个问题,小明在一个小时里最多能做几件事(刷牙,烧水,煮粥。。。异曲同工)
一、socket实现过程
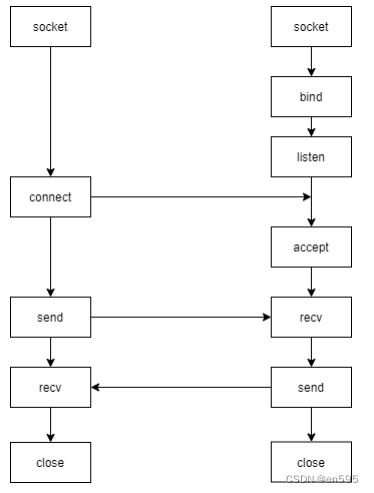
以TCP服务端和客户端建立链接的过程为例,还是参考TCP通信的流程图
1,其中socket ,(也可以当成理解为代表两个通信端的连接点,这个连接点连接着庞大的服务器和客户端),创建的两个套接字。至于listen(维护一个半链接和一个全链接队列,这里还有细节,为啥会有半/全之分,以后再写上) 和bind 函数作用,接触过socket编程的应该都了解
1、TCP协议
1、accept 从监听队列中取出(链接对象)的过程
使用talent 命令可以登录远程服务器端口,可以在服务器开发过程中做一些问题的验证,比
执行以下命令,访问服务器。
talnet如以下例子:其中testaccept是服务器程序,服务器对外的端口使用54321
执行一个操作相当于使用客户端链接后,直接给客户端断网,而后出现服务器仍然收到了链接请求,且在服务器端还建有链接。也就是考虑客户端的链接端进入监听队列后,之后服务端accept函数对链接请求的处理不会受到客户端的影响,只是单纯的从监听队列取出链接进行操作
不过关于accept函数是怎么从监听队列中取出链接的,有很多说法不一样的解释。
有一个说法:accept默认是阻塞的,当listen监听队列中没有连接时,accept将会等待,直到监听队列中有连接可以取出。(猜想可能是listen发送信号给accept去取出链接,有空了找找源码看。。。)这个点也一直让我感到纠结(略有强迫症)。
2、关闭网络链接 sockfd
很多人在使用的过程中,使用close关闭sockfd, 查过一些资料说使用close的时候会查看sockfd的引用计数值,等于0的时候才会关闭。这样应该也好,可以避免提前关闭sockfd对其他线程产生影响。类似share_ptr 智能指针的引用计数



2、AF_INET 是IPV4网路通信协议簇
TCP协议下的网络通信,使用sock_stream 的字节流传输方式。


3、HTTP(超文本传输协议)
是一种资源标识文件,可以使用URI定位网络资源(另外在HTTP应答中发现了一些绝大部分人在浏览网页时都会遇到的问题,如404等)
与之相似的还有XML(XML没有预定义的标记语言,可以自己设定专属的标记信息,可使用Tinyxml来解析和使用xml文件)
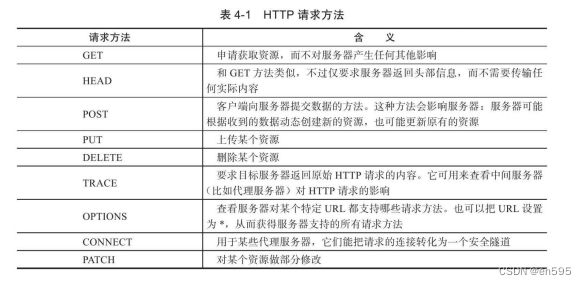
1、HTTP请求方法和含义
2、 值得一提的是,Linux上提供了几个命令:HEAD、GET和POST。 其含义基本与HTTP协议中的同名请求方法相同。它们适合用来快速测 试Web服务器。
3、HTTP请求
get 是请求方法,客户端以只读取的方式申请资源
user-agent 表示客户端使用的程序是wget
HTTP/1.0 表示客户端的协议版本号(主流或许是1.1)
Host 表示主机名,这里只是示例
Connection : close 表示处理完这个请求后,web服务器会对TCP链接做什么处理
(close 表示关闭,keep-alive 表示保持链接)
另外:使用netstat可以查看是否使用的长链接,以及链接持续的时间
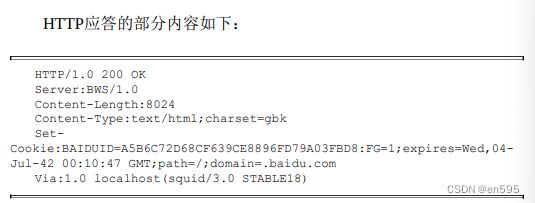
4、HTTP应答
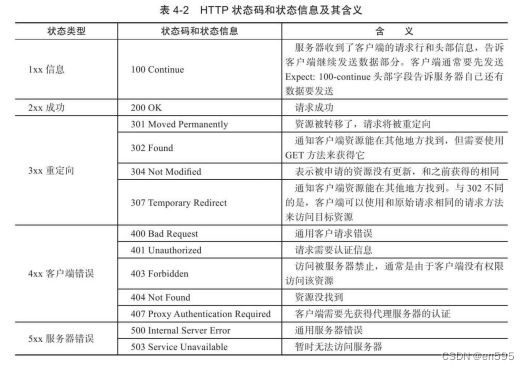
第一行:协议版本,还有状态。 常见的状态信息如下
( 估计很多人除了1 和2开头的,差不多都遇到过了)
第2~7行是HTTP应答的头部字段。其表示方法与HTTP请求中的头 部字段相同。 “Server:BWS/1. 0”表示目标Web服务器程序的名字是BWS(Baidu Web Server)。 “Content-Length:8024”表示目标文档的长度为8024字节。这个值和 wget输出的文档长度一致。
“Content-Type:text/html;charset=gbk”表示目标文档的MIME类型。 其中“text”是主文档类型,“html”是子文档类型。“text/html”表示目标文档index.html是text类型中的html文档。“charset”是text文档类型的一个参 数,用于指定文档的字符编码。
注意:HTTP报文的结构分两部分
一般都是首部字段+报文主体,就这两部分,不过这俩中间一般有个空行,对于我们来说方便查看



一、一些快捷键,使用vscode、
1、 宏定义格式对齐快捷键:
shift + alt + f,宏函数定义最好要对齐,否则会出现编辑格式错误
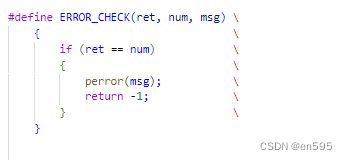
2、使用perror 和stderr时要注意,stderr是线程安全的
二、线程池的一些内容
首先呢,线程池这个东西,关键的一点就是需要我们提前创建很多个线程,这就比较明白了,只有使用pthread_creat() 函数,反复的执行去创建很多线程,之后将线程分给不同的用户任务。(这个分配过程,有些抽象,后续整理出来补上)
1、类似生产者和消费者的架构,(生产,存储到仓库 ->消费)
C++Model:
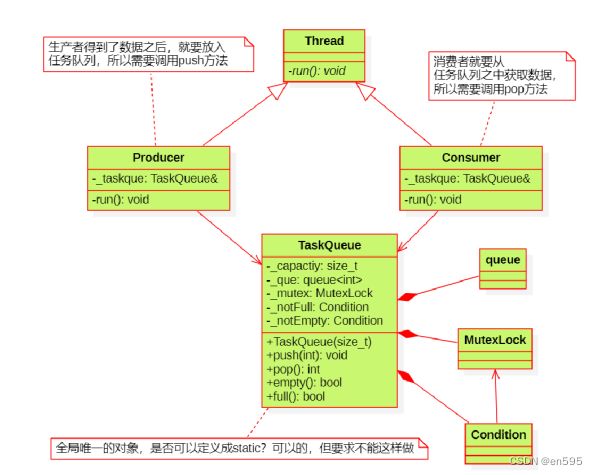
生产者消费者封装:因为生产和消费是有序的,只有生产出来产品才可以消费(不仅仅是生产消费模式,有序进行的工程步骤,都可以尝试使用此方式完成,有资源才能使用不是,巧妇难为无米之炊)
1、Thread 使用虚函数,给生产者和消费者提供任务函数接口,(此处使用虚函数可以在必要的时候直接添加其他功能接口,而生产者和消费者只需要继承,再添加一个函数的实现代码就行,开闭原则)。
2、TaskQueue,相当于创建了一个仓库(用来存储,或者进行一些用户要求的操作,生产者存储,处理数据等;再等消费者消费或者需要时,进行消费者相关的操作,取出数据或者处理后交给消费者),其中单独的queue类 可去掉,直接在TaskQueue中创建队列就好
(这里给的例子图使用的是queue,这是一个单向队列,先进先出;
而且在理解这些类似的模型时,一定要多考虑有大量用户的情况,类似这个,有很多生产者,也有很多消费者时,就能凸显 “虚函数(虚基类)做接口“ 的重要性了,继承下来使用接口实现自己的功能,等后面需要调用功能函数的时候,可以写出来较为通用的代码,比如都是使用的 run()。
3、主要而且仓库这里,在执行用户请求的任务时不得有个先来后到嘛,这里就是需要仓库对资源和各个用户的线程进行控制了。非特殊情况,插队挨揍。)
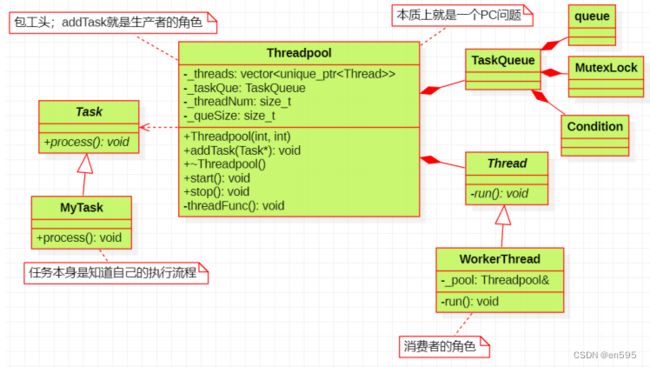
2、线程池封装
1、线程池封装,使用threadpool(vector
在Thread及派生类中实现执行pthread_create 函数需要运行的 function回调函数,注意传入参数指针的类型转换;
如果每个线程的功能作用不同,则此回调函数使用起来不方便,可能需要多次修改,可以考虑也设计为虚函数
在线程创建涵数中,int ret = pthread_create(&_thid, nullptr, threadFunc, this),因为C++中每个对成员函数创建后第一个参数就是this,想要消除此影响,可以将回调函数设计为static函数(没有this指针))
2、线程池的作用可以解耦,较为明显的和C语言相比,可以提高效率优化代码结构。所以在相关的类调用过程中可使用引用或者类对象,对象指针等方式让一个类知晓另一个类的存在。而继承更多的体现在虚函数,纯虚函数(抽象类)的接口继承实现上,使用抽象类时,注意将析构函数设定为虚函数,否则容易造成内存泄漏(不设定为虚函数。容易调用不到子类的析构函数)
3、此线程池总体以start 为开始(可以考虑在类对象创建之初就在参数列表和构造函数内初始化数据成员)
(剩余部分后续补充,很多还没写完,做个开篇,最近在研究服务器整个流程的实现操作,准备后面出一整个完整的记录,包括封装,不然容易忘记。在改错中学习)
以前朋友让我给她讲题时,我感觉还没学会,她的一句话让我受益颇深:不仅自己得会,还要能讲的明白才是吃透了。