【Redis交响乐】Redis中的通用命令
文章目录
- 1. 基本命令 get set
- 2. 全局命令
-
- (1)keys
- (2)exists
- (3)del
- (4)expire && ttl
-
- 面试题: redis中key的过期策略是怎么实现的?
- 定时器的实现原理
-
- (1)基于优先级队列/堆
- (2)基于时间轮实现的定时器
- (5) type
我们知道,redis是按照键值对的方式存储数据的.
Redis中基本的命令:
| 命令 | 作用 |
|---|---|
| get | 根据key来取value |
| set | 把key和value存储进去 |
| keys | 用来查看匹配规则的key |
| exists | 用来判断指定key是否存在 |
| del | 删除指定的key |
| expire | 给key设置过期时间 |
| ttl | 查询key的过期时间 |
| type | 查询key对应的value的类型 |
1. 基本命令 get set
| 命令 | 作用 |
|---|---|
| get | 根据key来取value |
| set | 把key和value存储进去 |
注意要先使用redis-cli命令进入客户端程序,如果设置了密码还需要使用密码登录后才能够输入redis命令哦~
set和get的演示如下:

set key value : key和value都是字符串.
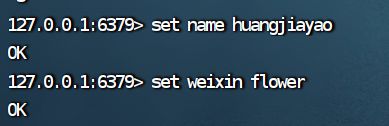
对于上述的key value,不需要加上引号,就是表示字符串的类型,要是加单引号或者双引号也行.
redis命令不区分大小写.

get命令 直接输入key就会得到value
如果key不存在,就会返回nil(null)
2. 全局命令
Redis支持很多种数据结构,整体上来说,Redis键值对结构,key固定就是字符串,value是加上有很多种数据类型.比如:字符串,哈希表,列表,集合,有序集合等.操作不同的数据结构就会有不同的命令.
所谓全局命令,就是能够搭配任意一个数据结构来使用的命令.
| 命令 | 作用 |
|---|---|
| keys | 用来查看匹配规则的key |
| exists | 用来判断指定key是否存在 |
| del | 删除指定的key |
| expire | 给key设置过期时间 |
| ttl | 查询key的过期时间 |
| type | 查询key对应的value的类型 |
(1)keys
用来查询当前服务器上匹配的key
key pattern
pattern包含特殊符号的字符串.
?匹配任意一个字符
*匹配0个或者多个任意字符
[abc]只能匹配到a b c,别的不行,相当于给出固定的选项
[^a]除了a意外的都能匹配到
[a-c]匹配a-c之间的字符 包含两侧边界
注意: keys命令的时间复杂度是O(N)
所以在生产环境上,一般都会禁用keys命令,尤其是keys *.这是因为生产环境上的key可能会非常多,而redis是一个单线程的服务器,执行keys * 的时间非常长,就使redis服务器被阻塞了,就无法给其他用户提供服务了.
redis常作为缓存,是挡在mysql前面,为mysql遮风挡雨的人,万一redis被一个key * 阻塞住了,此时其他查询redis操作就超时了,此时就会直接查询mysql数据库.而mysql是比较脆弱的,此时大量的请求过来,mysql承受不住,就会导致系统瘫痪.
上面说到了生产环境,那么什么是生产环境呢?
生产环境是指软件或系统在实际运营和使用的真实环境中的部署和运行状态。它是指软件、应用程序或系统在正式投入使用,并提供服务给最终用户或客户的环境。
生产环境通常与开发环境、测试环境和预演环境等进行区分。在开发环境和测试环境中,开发人员和测试人员可以进行软件开发、调试和测试。而在预演环境中可以模拟真实的生产环境进行系统验证和性能测试。一旦通过了这些环境的验证,软件或系统才会部署到生产环境中供用户使用。
(2)exists
判定key是否存在
exists key [key...]
返回值:key存在的个数
针对多个key来说,是非常有用的.
时间复杂度:O(1)
redis组织key是按照哈希表的方式来组织的.
示例如下:

值得注意的是,以下两种写法的效果是相同的,但是有很大的区别.

这是因为Redis是一个客户端服务器结构的程序,客户端和服务器之间通过网络来进行通信.第一种方式:
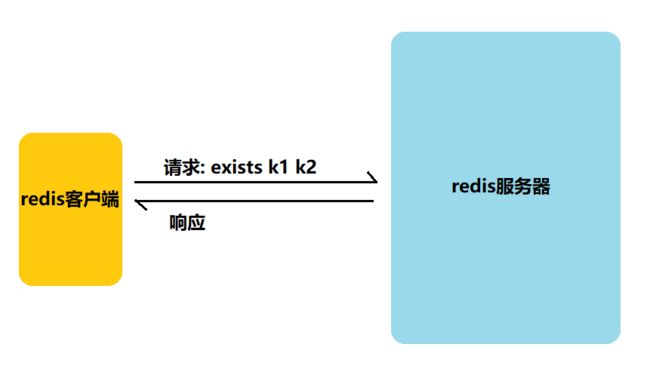
第二种方式:

我们可以看到,分开的写法中,会产生更多轮次的网络通信.网络通信的效率相比于直接操作内存来说比较低.所以redis的很多命令都是支持一次就能操作多个key的.
(3)del
DEL key [key ...]
可以一次删除一个或多个key
时间复杂度:O(1)
返回值为:删除掉key的个数
示例:(k5不存在)
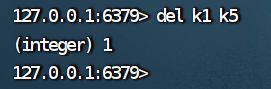
del命令类似于MySQL中的drop database drop table,但是在不同场景中的作用不同.
redis的主要应用场景,是作为缓存,此时redis中存储的只是一个热点数据,全量数据在mysql中,如果使用del命令删除少量数据,那么影响不大.但是如果删除了大量redis中的数据,此时mysql的请求量就高了,前面我们说过,MySQL是比较脆弱的,面对大量请求就有可能会承担不住.
redis作为数据库时,此时使用del命令就需要格外注意了.误删就会造成严重的后果.
redis作为消息队列(mq),时,这种情况下误删数据的影响就要具体结合场景分析了.
(4)expire && ttl
expire key seconds
作用是给指定的key设置过期时间,key存活时间超出这个指定的值,就会被自动删除.
在很多业务场景中,是有时间限制的.比如:
(1)手机验证码(在指定时间内有效)
(2)外卖优惠券(在指定时间内有效)
(3)基于redis实现分布式锁.为了避免出现不能正常解锁的情况,通常都在加锁的时候设置一下过期时间.
上述指令的单位是秒,在计算机中是非常长的.我们可以使用
pexpire key 毫秒
来进行毫秒级别的设置.
此处的设定过期时间,必须是针对已经存在的key设置,设置成功返回1,设置失败返回0.
时间复杂度:O(1)
ttl key
time to live 超时时间
作用是查看当前key的过期时间还剩多少,与expire搭配使用
pttl
与pexpire搭配使用.
面试题: redis中key的过期策略是怎么实现的?
一个redis 中可能同时存在很多很多key.这些 key 中可能有很大一部分都有过期时间.此时, redis服务器怎么知道哪些key已经过期要被删除,哪些key 还没过期呢?
redis的整体策略是:
(1)定期删除
每次抽取一部分,进行验证过期时间.保证这个抽取检查的过程足够快.(此处明确要求定期删除的时间足够快,是因为redis是单线程的程序,主要的任务就是处理每个命令的任务,扫描过期的key,但是如果扫描过期key消耗的时间太多,就可能会导致正常处理请求命令就被阻塞了,所以此处对定期删除的时间是由要求的.)
(2)惰性删除
假设这个key已经到了过期时间了,但是暂时还没有删除他,key还存在,紧接着,后面有一次访问正好用到了这个key,于是这次访问就会让redis服务器触发删除key操作,同时在返回一个nil
以上两种策略结合使用,整体的效果一般.仍然可能会有很多过期的key被残留了,没有及时删除掉.redis为了对以上进行补充,还提供了一系列的内存淘汰策略.
定时器的实现原理
(1)基于优先级队列/堆
正常的队列是先进先出.优先级队列则是按照指定的优先级先出.所谓优先级高就是按照自定义的顺序先出.在redis 过期key的场景中,就可以按照过期时间越早,优先级越高.
现在假定有很多key设置了过期时间.就可以把这些 key加入到一个优先级队列中,指定优先级规则是过期时间早的,先出队列.队首元素,就是最早的要过期的key.比如:
key1: 12:00
key2: 13:00
key3: 14:00
此时定时器中只要分配一个线程,让这个线程去检查队首元部,看是否过期即可.如果队首元素还没过期,后续元素一定没过期.此时扫描线程不需要遍历所有key,而是只看队首元素即可.另外在扫描线程检查队首元素过期时间的时候,也不能检查的太频繁.
此时可以根据当前时刻和队首元素的过期时间,设置一个等待,当时间差不多到了,系统再唤醒这个线程.此时扫描线程不需要高频扫描队首元素.把cpu的开销也节省下来了.
万一在线程休眠的时候,来了一个新的任务,是11:30要执行.可以在新任务添加的时候,唤醒一下刚才的线程.重新检查一下队首元素,再根据时间差距重新调整阻塞时间即可.
(2)基于时间轮实现的定时器
时间轮就是把时间划分成很多份.比如现在有一个任务要300ms后执行,那么就把这个任务挂在300ms后的这个链表上,这个指针会过100ms往后移动,尝试执行格子上的任务.以此来执行.

以上的两种方案,redis都没有采取.但是这两种方案都是属于搞笑的定时器的实现方式,很多场景中可能会使用到.
在Redis中,有一个比较核心的机制是事件循环,我们以后讲解.
(5) type
type key
作用是返回key对应的数据类型.
此处redis所有的key都是string,key对应的value可能会存在多种类型.
比如: none string list set zset hash stream
stream 是在redis作为消息队列的时候使用这个类型的value.