【Java开发岗面试】八股文—Java基础&集合&多线程
声明:
- 背景:本人为24届双非硕校招生,已经完整经历了一次秋招,拿到了三个offer。
- 本专题旨在分享自己的一些Java开发岗面试经验(主要是校招),包括我自己总结的八股文、算法、项目介绍、HR面和面试技巧等等,如有建议,可以友好指出,感谢,我也会不断完善。
- 想了解我个人情况的,可以关注我的B站账号:东瓜Lee
文章目录
-
-
- Java基础
- Java集合
- 多线程(并发编程)
-
Java基础
- 面向对象的特征有哪些方面?
- 封装:合理隐藏、合理暴露
- 继承:单继承、子类可以继承父类的成员变量和方法,自己也可以追加内容,或者重写父类的方法、以实现代码复用
- 多态:
- 对象多态、行为多态
- 必须满足:
- 必须在继承体系下、子类需要对父类的方法进行重写、通过父类的引用调用重写方法
- 在代码运行时,当传递不同类对象时,会调用对应类中的方法。
- 抽象:抽象就是找出一些事物的相似和共性之处,然后将这些事物归为一个抽象类,这个类只考虑这些事物的相似和共性之处
- 抽象类不能被实例化
- 抽象类中可以有抽象方法和实例方法
- 抽象类的子类必须实现父类的全部抽象方法,否则也要定义为抽象类
Java和C++面向对象的区别?
- Java单继承、C++支持多继承
- Java有根基类Object、C++没有
- Java的访问修饰符是private、default、protected、public,C++没有default
- Java中没有析构函数这个概念,C++有析构函数(销毁对象的时候调用的)
- Java中的对象可以被GC回收,C++需要手动的释放空间
-
public,private,protected,default的区别

- public表示公开的,不管在哪里都可以直接访问
- protected表示受保护的,相比于public,用它修饰的变量或者方法不能在任意包的任意类里面被访问
- default表示默认的、缺省的,也可以称它为包访问,它只能在同一个包有效,其他包里面就不能直接访问了
- private表示私有的,访问范围最小,只能在本类中被访问
- String是最基本的数据类型吗?
- Java的八种基本数据类型:
- boolean
- byte、short、int、long
- float、double
- char
- 在Java中,整数默认是int、浮点数默认是double
- String属于引用数据类型
- Java的八种基本数据类型:
-
基本数据类型vs包装类
-
为了更好的实现面向对象的思想,引出了8种基本数据类型对应的8种包装类:
- Boolean
- Byte、Short、Integer、Long
- Float、Double
- character
它们均继承自抽象类Number
-
自动装箱和拆箱:
- 装箱:将基本数据类型自动转换为对应的包装类型,比如基本数据类型int直接赋值给Integer,就会实现自动装箱
- 拆箱:将包装类型自动转换为对应的基本数据类型,比如将Integer对象直接赋值给int变量,就会实现自动拆箱
-
int和Integer的区别(其他也一样)
- int是基本数据类型、Integer是引用类型、对象类型
- int的默认值是0,Integer的默认值是null
- Integer不能直接做运算,运算的时候会自动拆箱为int进行运算
-
注意:
- 无论如何,Integer与new Integer不会相等。不会经历拆箱过程,因为它们存放内存的位置不一样。
- (非new出来的)Integer的值在-128~127之间,就是从高速缓冲返回实例,如果值相同,直接用==号比较是true,说明是同一个对象,如果超出了这个范围,底层就会new新对象,==号比较就会false。
- 两个都是new出来的,即两个new Integer比较,则为false。
- int与Integer、new Integer()进行==比较时,结果永远为true,因为会把Integer自动拆箱为int,其实就是相当于两个int类型比较。
-
Integer.parseInt()和Integer.valueOf()的区别:
- 都是传入一个String返回整形,如果无法转换都是抛出NumberFormatException
- Integer.parseInt()返回值是int
- Integer.valueOf()返回值是Integer
-
double类型数值的计算经常会出现这种精度丢失的问题,尤其是有小数点的情况下,常常会因为精度丢失而导致程序出错。所以我们在运算高精度的数据的时候,可以使用
Java.math.BigDecimal类(涉及到金钱都最好用此类,理论不能用double)
-
- &和&&、|和||的区别
- &、|:逻辑与和逻辑或
- 性能没这么高,不管左边对整个表达式成不成立,都会执行到右边的部分
- 主要进行位运算:对01进行运算
- &:有0 则整个表达式为0
- |:有1 则整个表达式为1
- ^:相同为0,相异为1
- ~:取反操作
- &&、||:短路与和短路或
- 性能更好,如果判断左边对整个表达式就可以确定了,就不会执行到右边的部分,用的更多
- &、|:逻辑与和逻辑或
- 有关switch
- 用于做选择的,可以用if-else替代
- 和if-else的区别:
switch的设计按道理来说,是比if-else要快的,但是在99.99%的情况下,他们性能差不多,除非case分支量巨大。switch只支持byte,int,short,char,enum,String的类型switch虽然支持byte,int,short,char,enum,String但是本质上都是int,其他的只是编译器帮你进行了语法糖优化而已。
-
如何跳出当前的多重嵌套循环
-
使用 break 带上标识(类似于goto,最好不用)
//标识 ok: for(int i=0;i<10;i++){ for(int j=0;j<10;j++){ if(j==5){ //跳到循环外的ok出,即终止整个循环 break ok; } } } -
定义flag来进行判断
boolean flag = false; for(int i=0;i<10;i++){ for(int j=0;j<10;j++){ if(j==5){ //跳到循环外的ok出,即终止整个循环 flag = true; break; } } if(flag) { break; } }
-
-
重写和重载:
-
重载:对于同一个类,如果这个类里面有两个或者多个重名的方法,但是方法的参数个数、类型、顺序至少有一个不一样,就构成方法重载(重载overload,方法重载就是对不同数据类型的数据实现相似的操作)
-
重写:当一个子类继承父类,而子类中的方法与父类中的方法的名称,参数个数、类型都完全一致时,就称子类中的这个方法重写了父类中的方法(重写@Override),或者实现类重写接口中的方法
- 子类重写父类的方法的时候,方法的访问权限必须public >= 父类方法的访问权限private
- 子类重写父类的方法的时候,返回值类型必须是父类方法的返回值类型 或 该返回值类型的子类(<=),不能返回比父类更大的数据类型
-
构造器是否可以被重写@Override
构造器是不能被继承的,因为每个类的类名都不相同,而构造器名称与类名相同,所以根本谈不上继承。
构造器不能被继承,所以就不能被重写。但是,在同一个类中,构造器是可以被重载的。
-
-
==和equals区别
-
==
- 对于基本数据类型,比较值
- 对于引用数据类型,比较地址
-
equals()方法
-
是Object提供的一个方法
-
Object中equals()方法的默认实现就是返回两个对象==的比较结果。但是equals()可以被重写,所以我们在具体使用的时候需要关注equals()方法有没有被重写。
public boolean equals(Object obj) { return (this == obj); }
-
-
-
是否可以继承String类
-
String 类是不能被继承的,因为他是被final关键字修饰的
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final char value[]; -
从String的源码能看出来:
- 不能被继承
- 底层是char数组实现的
- 长度是不可变的,因为char数组是final修饰的
-
- String、StringBuilder、StringBuffer的区别
- String:不可变字符串(要操作少量的数据用 String)
- StringBuilder:可变字符串、效率高、线程不安全(单线程操作字符串缓冲区下操作大量数据 StringBuilder)
- StringBuffer:可变字符串、效率低、线程安全(多线程操作字符串缓冲区下操作大量数据 StringBuffer)(通过加synchronized锁来保证线程安全,类似的还有HashMap和HashTable)
- 静态变量和实例变量的区别
- 静态变量是有static修饰的,实例变量没有static修饰
- 静态变量是类变量,可以通过类名直接调用,也可以通过类的实例对象调用,它只有一份内存空间
- 实例变量是对象的变量,需要new出对象才能被调用,不同的对象的同一个实例变量 内存空间是不同的
- 你觉得 Java 好在哪儿?
- 跨平台(JVM):Java 是跨平台的,不同平台执行的机器码是不一样的,但是因为 Java 加了一层中间层 JVM ,所以可以做到一次编译到处运行(即Write once,Run anywhere)
- 垃圾回收机制(GC):Java 还提供垃圾自动回收功能,虽说手动管理内存意味着自由、精细化地掌控,但是很容易出错,在内存较充裕的当下,将内存的管理交给 GC 来做,减轻了程序员编程的负担,提升了开发效率,更加划算
- 语言生态好:Java 生态圈太全了,丰富的第三方类库、网上全面的资料、企业级框架、各种中间件等等,想要的都有。
-
抽象类和接口的区别:
抽象类是对类的抽象(是一种模板设计方法)、而接口是对行为的抽象(是一种行为的规范)
- 一个类只能继承一个抽象类,但是可以实现多个接口
- 抽象类可以有构造方法,接口中不能有构造方法
- 抽象类中可以有抽象和具体方法,jdk8之前接口中只能有抽象方法,jdk8之后接口可以有默认方法和静态方法
- 不管是抽象类还是接口,抽象方法都不能由private修饰(因为抽象方法必须能被重写)
-
内部类和静态内部类:
- 都是写在类内部的类,区别在于加不加static修饰符
- 静态内部类,可以使用外部类名直接访问,外部类对应的不同对象访问的是同一个静态内部类对象。而对于非静态内部类,不能直接外部类名直接访问,且不同对象访问的是不同的内部类对象。
- 在内部类里面可以访问外部类的所有成员变量,静态内部类只能访问静态成员变量
static关键字可以修饰什么?有什么语义?
- 修饰变量:表示静态变量、类变量,类加载的时候加载,内存中只有一份,类的多个对象共享同一个变量。
- 修饰方法:表示静态方法、类方法,可以通过对象调用,但是建议使用类名直接调用,静态方法只能访问静态的成员变量和方法,而且方法体中不能出现this关键字。
- 修饰类:表示静态类,而且就是静态内部类,静态内部类跟静态方法一样,只能访问静态的成员变量和方法
-
如何实现对象拷贝(复制):
将要拷贝的对象对应的类:
- 实现Cloneable接口,并重写Object类中的clone()方法【具体实现待学习】
- 实现Serializable接口,通过对象的序列化和反序列化实现克隆【具体实现待学习】
- 通过commons中的工具类BeanUtils或者PropertyUtils,调用对应的方法进行对象拷贝
将一个对象a克隆给另一个对象b
浅克隆:a和b指向的是同一个地址
深克隆:a和b指向的是不同的地址,但是内容一样
-
Java中有几种类型的io流:
- 按照方向分:输入流和输出流
- 按照流中数据的最小单位:字节流(所有文件)和字符流(文本文件)
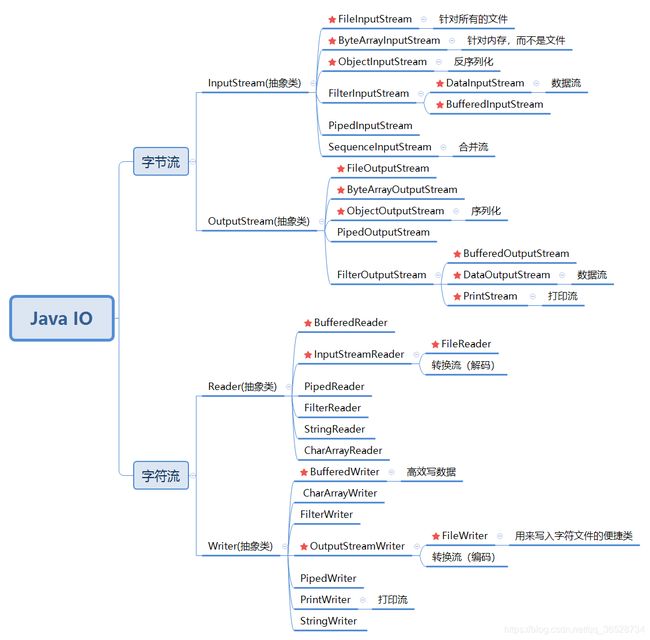
其他流:
- 缓冲流:提高读写数据的性能
- 转换流、打印流、数据流、序列化流
简单介绍Java I/O,其中NIO、BIO、AIO三种I/O模式的区别【待学习】
- BIO是阻塞I/O,每个连接对应一个线程
- NIO是非阻塞I/O,多个连接共享少量线程
- AIO是异步I/O,允许应用程序异步地处理多个操作
- NIO、AIO通常比BIO更适用于高并发的网络应用,可以更有效地管理多个连接和I/O操作。
- AIO是适合高吞吐量的应用程序,可以异步处理多个I/O操作,而不需要线程等待。
- Java中Error和Exception的区别:
- Error和Exception都是Java.lang.Throwable下的两个子类
- Error:系统级别的严重错误(开发人员不用管)
- Exception:
- RuntionException(运行时异常):编译的时候没有错误提醒,运行时出现的异常
- 其他异常(编译时异常):编译的时候出现错误就会提醒
- 还可以自定义异常,编译时异常继承Exception,运行时异常继承RuntionException
- 常见运行时异常:
- NullPointerException:空指针异常
- ArrayIndexOutOfBoundsException:数组下标越界
- ArithmeticException:算术异常
- ClassCastException:类型转换异常
- 常见编译时异常:
- ClassNotFoundException:类找不到异常
- FileNotFoundException:文件找不到异常
- IOException:IO 异常(输入输出异常)
- JDBC操作数据库的步骤:
- 加载(注册)数据库驱动(到JVM)。
- 建立(获取)数据库连接。
- 创建(获取)数据库操作对象。
- 定义操作的SQL语句。
- 执行数据库操作。
- 获取并操作结果集。
- 关闭对象,回收数据库资源(关闭结果集–>关闭数据库操作对象–>关闭连接)。
String driver = "com.mysql.jdbc.Driver";
// 数据库连接串
String url = "jdbc:mysql://127.0.0.1:3306/jdbctest";
// 用户名
String username = "root";
// 密码
String password = "123456";
// 1、加载驱动
Class.forName(driver);
// 2、获取数据库连接
Connection conn = DriverManager.getConnection(url, username, password);
// 3、获取数据库操作对象
Statement stmt = conn.createStatement();
// 4、定义操作的SQL语句
String sql = "select * from user where id = 100";
// 5、执行数据库操作
ResultSet rs = stmt.executeQuery(sql);
// 6、获取并操作结果集
while (rs.next()) {
}
// 7、关闭对象,回收数据库资源
rs.close();
stmt.close();
conn.close();
-
Statement和PreparedStatement的区别
Statement是Java执行数据库操作的一个重要方法,用于在已经建立数据库连接的基础上,向数据库发送要执行的SQL语句,PreparedStatement继承自Statement 。
- Statement:
- 对数据库只执行一次性存取的时侯,PreparedStatement 对象的开销比Statement大,所以可以用 Statement 对象进行处理。
- 不能防止sql注入,不安全
- 对应到MyBatis里面的${}
- PreparedStatement:#{}
- 是预编译的,对于批量处理可以大大提高效率。
- 能防止sql注入,安全
- 对应到MyBatis里面的#{}
- Statement:
-
数据库连接池的作用与基本原理
正常的创建数据库连接的流程就是,先加载数据库驱动,再得到数据库连接,在数据库访问量比较大的情况下,频繁的创建连接会带来较大的性能开销,而数据库连接池就是维护了一定数量的数据库连接,当需要用的时候,就可以直接获取。
好处:
1. 资源复用,避免频繁创建数据库连接,造成资源的消耗 2. 更快的系统响应速度,数据库连接池初始化后,就已经有了若干数据库连接对象,不需要重新创建 3. 统一的连接管理,避免数据库连接泄露常见数据库连接池:
1. Druid,最好的选择之一(高效的性能、高度的可扩展和可配置性、安全性) 2. C3P0连接池的几个关键参数:
1. 初始化连接数:表示启动的时候初始化多少个数据库连接 2. 最大连接数:表示最多同时能使用多少个连接 3. 最大等待时间:表示连接池里面的连接用完了以后,新的请求要获取连接 要等待的时间,超过这个时间就会提示超时异常
-
什么是DAO模式
一种数据访问模式,DAO位于业务逻辑和持久化数据之间,实现对持久化数据的访问。通俗来讲,就是将数据库操作都封装起来,对外提供相应的接口。
- 获得一个类的类对象有哪些方式
- 方式一:调用运行时类的属性:类名.class
- 方式二:通过运行时类的对象,对象名.getClass()
- 方式三:调用Class的静态方法:Class.forName(String classPath)(类的全路径)
-
JDK、JRE、JVM三者的关系
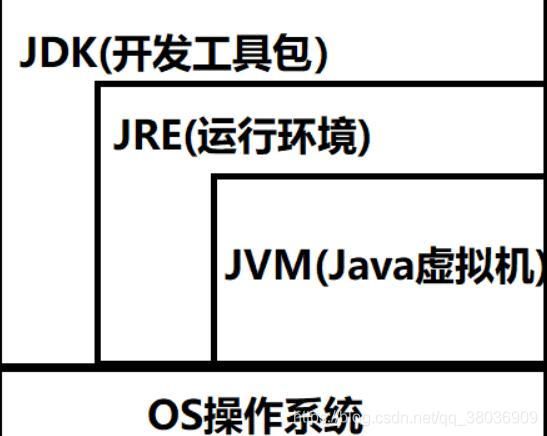
- JDK:Java开发工具包,包括了Java运行环境jre、编译器、基础类库等等,是整个Java语言的核心。
- JRE:Java运行时环境,是运行基于Java语言编写的程序所不可缺少的运行环境,用于解释执行Java的字节码文件,其中包含了JVM。
- JVM:Java虚拟机,属于JRE,是整个Java实现跨平台的最核心的部分,负责解释执行字节码文件,是可运行Java字节码文件的虚拟计算机。
对于开发者而言需要jdk,如果只是运行Java程序,配置jre环境即可
- JDK8有哪些新特性
- 引入了 Lambda 表达式(简化开发)
- 引入了 Stream 流(更加方便的操作集合和数组)
- 引入了新的日期API(更加方便的使用日期)
- 接口不再只有抽象方法,还可以有默认方法和静态方法
- Java中final、finally和finalize的区别
- final关键字用于声明某个变量(不可变)、方法(不可被重写)或者类(不可被继承)
- finally关键字用在异常处理中,无论try块中是否发生异常,finally块中的代码都会被执行(一般用于释放资源)。
- finalize不是关键字,而是Object类的一个方法,当垃圾回收器准备回收对象之前被调用,用于清理资源,可以在类中重写该方法(很少用到)。
-
Java中的finally一定会被执行吗?
不一定
- 如果程序都没有执行到try-catch-finally的代码块,比如try之前return了 或者 try之前就出现异常了(说明异常捕获的范围不够),那finally里面的内容肯定不会被执行。
- 即使程序已经执行到try里面了,如果出现了系统级别的错误,比如使用System.exit(0)把jvm关了,那finally也不会被执行了
-
Java反射了解吗?
实际开发中基本上没怎么用过,但是有学习过反射的原理。
- 反射其实就是Java提供的能在程序运行期间得到对象信息的能力,包括属性、方法、注解等,也可以调用其方法。
- 一般的开发过程不会用到反射,在框架上用的较多,因为很多场景需要很灵活,所以不确定目标对象的类型,届时只能通过反射动态获取对象信息。
反射的优点:
- 可以在程序运行期间 得到对象的信息,比如属性、方法,还能动态的调用方法
- 提高了代码的复用率,比如动态代理 就用到了反射来实现
缺点:
- 使用反射以后,代码的可读性会下降
- 反射可以绕过一些限制访问的属性或者方法,可能会破坏了代码本身的抽象性
-
Java泛型是什么?作用?
在定义类、接口、方法时,同时声明了一个或者多个类型变量(如: ), 就称为泛型类、泛型接口,泛型方法,它们统称为泛型。
- 泛型的本质 就是把具体的数据类型作为参数 传给类型变量E,简单来说 就是在创建对象或者调用方法的时候才去明确具体的类型。
- 泛型是工作在编译阶段的,一旦程序编译成class文件,class文件中就不存在泛型了,这就是泛型擦除。
- 好处就是使得代码更加简洁(不再需要强制转换),程序更加健壮(在编译期间没有警告,运行期间不会出现类型转换异常)
- 泛型不支持基本数据类型,只支持对象类型(引用数据类型)。
-
Java注解是什么?
注解就是代码中的特殊标记,这些标记可以在编译、类加载、程序运行时被读取,然后就可以执行相应的处理。
实际的开发中,比如在Spring、SpringMVC、SpringBoot这些框架中都有对应的注解,还比如会用到Lombok注解,记录日志之类的。除了在框架中的注解,Java原生也有一些常用的注解,比如说重写的注解@Overried等等。
还有一种注解叫做元注解,它其实就是用来修饰注解的。
- Java中throw和throws区别
throw是语句主动抛出一个异常,throw + 一个异常对象
throws是方法可能抛出的异常的声明,在声明方法的时候,throws + 该方法可能会抛出的异常的种类
- 为什么重写 equals() 就一定要重写hashCode() 方法?
我们自定义的类需要进行比较操作时,就需要重写 equals() 和 hashCode() 方法,如果不重写hashCode() 方法就会导致 该类无法使用基于散列的集合,比如HashMap、HashSet
比如说自定义了一个Student类,只重写了equals()方法,那么比较的就是两个对象的属性,如果两个对象的全部属性相同,equals()返回的就是true,但是此时两个对象的hashcode值是不一样的(采用的Object类默认的hashCode()方法),那这个时候,如果要把这两个对象放入map或者set中,因为hashcode值不一样,就会放到两个不同的位置,这样就违背了map和set的原理,所以也必须要重写hashCode()方法。
使得如果两个对象equlas()相等,那么hashcode也得相等,就不会在map或者set中放入重复的元素。
-
String可以是:
- “ ”直接生成,会放在堆内存的字符串常量池中存储,且相同内容的字符串只会存储一份(为了节约内存)
- new出一个字符串对象,每次new都会产生一个新的对象放在堆内存中
-
String对象都是不可变字符串对象
- 命令规范总结
- 包package:
- 小写英文字母
- 多层包之间用点进行分隔
- 采用域名倒写的方式,比如com.xx
- 类class、接口interface:
- 见名知意的名词
- 首字母大写
- 多个单词时,采用驼峰命名法
- 接口实现类加Impl、测试类加Test
- 方法method:
- 见名知意的名词
- 首字母小写
- 多个单词时,采用驼峰命名法
- 变量\属性:
- 见名知意的名词
- 首字母小写
- 多个单词时,采用驼峰命名法(对应的数据库表名用_)
- 常量:
- 见名知意的名词
- 全部大写字母
- 多个单词之间使用“_”进行分隔
- 包package:
- 常量是如何定义的?
- 使用 public static final 修饰符来声明一个静态常量,final表示不可以被修改,static表示是静态的(因为常量只需要一份),一般会用public修饰(因为常量要保证到处能够访问到)
- 当然也可以不加static,仅仅用final表示这个不可以被修改,也是常量(但是用的少)
-
变量\常量放在哪个内存空间?
- 类的成员变量(全局变量):
- 不论基本类型还是引用类型,变量名和值都随着类的实例(对象)存放在堆中
- 有初始值,基本数据类型为0,引用数据类型为null
- 方法的局部变量:
- 基本数据类型:局部变量变量名和值 都存放在虚拟机栈中
- 引用数据类型:局部变量变量名存放在栈中,而变量指向的对象存放在堆中
- 没有初始值,不给值会报错
- 常量(final修饰的):
- static final 修饰的常量,作为类信息,在类被加载的时候 放到了方法区
- 只加 final 修饰的常量,作为对象属性,在对象创建的时候被初始化 放到了堆空间
- 类的成员变量(全局变量):
-
不能被重写的方法
- final修饰的方法
- 类的static静态方法,子类可以和父类定义名称相同的方法,但这并不是重写
- 抽象方法不能定义为private,因为不可见了,但它又必须被重写
- 构造器不能被重写
-
序列化和反序列化是什么?
序列化是将对象转换为字节流,方便传输和存储,反序列化是将字节流转换为对象。
实现一个Serializable接口,用于标记这个类可以被序列化,里面没有需要重写的方法,如果不实现这个接口的话,就会报异常。
序列化ID的作用:
它决定着能否成功的反序列化,在反序列化时,JVM会把字节流中的序列号ID 和 本地实体类中的序列号ID做比对,只有两者一致,才能反序列化,否则就会报序列化版本不一致的异常。
一个类默认会有一个序列化ID,如果不变动这个类的话,那么反序列话的时候 序列化ID也会和这个实体类中的序列化ID保持一致,能够成功反序列化。但是如果后续对这个类进行字段的更改,序列化ID也会跟着改变,那再反序列化的时候,序列化ID就不一致了,就会报异常。所以最好不适用它默认的序列化ID,而是自己显式的声明一个确定的值。
如果要使得某个字段不被序列化,可以使用transient关键字修饰(前提是通过实现Serializable接口来实现序列化)
Java集合
-
为什么数组索引从0开始呢?假如从1开始不行吗?
因为在根据数组索引获取元素的时候,会用索引和寻址公式来计算内存所对应的元素数据,寻址公式是:数组的首地址+索引*存储数据的类型大小
如果数组的索引从1开始,寻址公式中,就需要增加一次减法操作,对于CPU来说就多了一次指令,性能不高。
-
ArrayList底层的实现原理是什么?
- ArrayList底层是用动态的数组实现的
- 初始容量:ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
- 扩容逻辑:ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组
-
ArrayList list=new ArrayList(10)中的list扩容几次?
- 该语句只是声明和实例了一一个ArrayList,i指定了容量为10,未扩容
- ArrayList list=new ArrayList(11) 也是扩容0次,创建时直接分配其大小,没有扩充。
-
如何实现数组和List之间的转换?
-
数组转List,使用JDK中Java.util.Arrays. 工具类的asList方法
List< String> list = Arrays.asList(strs);用Arrays.asList转List后,如果修改了数组内容,list受影响(指向同一块内存)
-
List转数组,使用List的toArray方法。无参toArray方法返回Object数组,传入初始化长度的数组对象,返回该对象数组,
String[] array = list.toArray(new String[list.size()]);List用toArray转数组后,如果修改了List内容,数组不受影响(不指向同一块内存)
-
-
ArrayList和LinkedList的区别是什么?
- 都是List接口下的两个实现类
- ArrayList底层时动态数组实现的,LinkedList是双向链表实现的
- 双向链表相比单向链表每个结点多了个前驱指针,操作链表更灵活
- 效率方面:
- ArrayList查询的时候效率更高,插入和删除效率低
- 已知索引查询O(1),未知索引查询O(n)
- 插入删除O(n)
- LinkedList查询的时候效率低,插入和删除效率高
- 查询O(n)
- 插入删除O(n)(因为要遍历找到元素才能插入和删除)
- ArrayList查询的时候效率更高,插入和删除效率低
- 内存空间占用:
- ArrayList底层是数组,内存连续,节省内存
- LinkedList是双向链表需要存储数据,和两个指针,更占用内存
- 两个变量都不是线程安全的,要保证线程安全:
- 在方法内使用,局部变量则是线程安全的
- 使用线程安全的ArrayList和LinkedList,new的时候
Collections.synchronizedList(new ArrayList<>();
-
说一下HashMap的实现原理?
- 底层使用哈希表来实现,具体来说就是:key经过哈希函数得到hash值(调用hashcode()方法,再做个抑或运算),也就是得到数组下标,然后再放入元素。
- jdk1.8之前,哈希表是使用数组+链表来实现的,如果没有哈希冲突就直接把元素放在数组中,数组有冲突元素,就使用头插法的方式放到对应的链表中。有个缺陷就是链表长度可能过长,那么查找效率就会到O(n)
- jdk1.8之后,对哈希表进行了改进,使用数组+链表+红黑树来实现,与1.7的第一个不同就是出现了冲突元素,是采用尾插法的方式放到链表中,第二个改进就是当链表的长度大于8且数组长度大于64,就会将链表转换成红黑树,那就可以实现一个O(logn)的高效查找效率了。当然也不是一成不变就是红黑树,当元素个数等于6时,红黑树也会退化成链表。
-
HashMap的put方法的具体流程 put(key,value)
put()方法就是hashmap保存键值对的方法,传入一个key和value,然后具体的流程就是:
- 判断数组table是否为空或者为null,如果是的话,就需要执行resize()方法对hashmap进行初始化扩容。
- 根据key,通过哈希函数计算得到hash值,再取模数组长度得到数组索引i
- 判断数组对应的位置是否有元素,也就是table[i]是否为null
- 如果为null,说明当前位置没有元素,可以直接将value放进来
- 如果不是null,说明当前位置已经有元素了,又可以分为三种情况:
- 判断key是否一样,如果一样的话,就可以将value进行覆盖
- 如果key不一样,那就是发生了哈希冲突了,然后再判断当前索引下是不是红黑树:
- 如果是红黑树,就直接在树中插入新的键值对。
- 如果不是红黑树,说明就是链表,先遍历链表,看当前的key是否和链表中的key相同:
- 如果是,那就覆盖对应的value
- 如果不是,那就以尾插法的方式插入新的键值对,然后记住,要判断链表长度是否大于8 数组长度是否大于64,如果是的话,就要把链表再转换为红黑树。
- 将一个键值对put进入hashmap之后,会判断 目前存在的键值对数量size是否超过了扩容阈值(数组长度*装载因子0.75),如果超过了,就要进行扩容操作。
-
HashMap的扩容机制
- 在第一次添加元素 或者 添加元素到了一定数量的时候,就需要扩容,实际就是调用resize()方法。
- 第一次扩容的时候,也第一次put元素的时候,数组长度为16,以后的扩容就是超过了扩容阈值(数组长度*默认的装载因子0.75)才开始的,比如说超过了12。
- 扩容的话,就扩容之前容量的两倍,比如说16 就是到 32。扩容之后会创建一个新的数组,就需要把原来的数据挪动到新数组中,分为三种情况
- 没有哈希冲突的节点,对key使用哈希函数得到哈希值,再得到新数组对应的索引位置
- 如果有哈希冲突:
- 如果是红黑树,走红黑树的添加逻辑
- 如果是链表,再走链表的添加逻辑,需要先遍历链表,拿到当前节点的哈希值 与运算(&)旧容量,看是否等于0
- 等于0的话,取出旧数组中的数据,直接赋给新数组,下标是一样的
- 不等于0的话,取出旧数组中的数据,赋给新数组,但是下标还要加一个旧容量的值
- HashMap的寻址算法【待学习】
-
HashMap和HashTable有什么区别?
-
HashMap不是线程安全的,HashTable是线程安全的
-
HashTable的性能要差一些,因为加了synchronized锁来保证线程安全性。
(通过加synchronized锁来保证线程安全,类似的还有StringBuilder和StringBuffer)
-
HashTable底层的哈希表就是数组+链表,HashMap在jdk1.8之后变成了数组+链表+红黑树
-
HashTable的初始化容量为11,HashMap的初始化容量为16
-
-
LinkedHashMap和TreeMap底层数据结构是什么?
- LinkedHashMap是数组+链表+红黑树+双向链表(保证了插入有序)
- TreeMap是红黑树(保证了按照key排序)
多线程(并发编程)
多线程基础知识:
-
线程与进程的区别
- 当一个程序被运行,从磁盘加载这个程序的代码至内存,这时就开启了一个进程(正在进行中的程序),一个进程之内可以包括一到多个线程。
- 一个线程就是一个指令流, 将指令流中的一条条指令以一定的顺序交给CPU执行。
- 不同的进程使用不同的内存空间,在当前进程下的所有线程可以共享内存空间。
- 线程更轻量,线程上下文切换成本一般上要比进程上下文切换低(上下文切换指的是从一个线程切换到另一个线程)
- 根本上的区别就是,进程是 操作系统资源分配 的基本单位,线程是 操作系统调度的 基本单位。
-
并行与并发的区别
-
单核CPU:
由于只有一个CPU核心,所以所有线程都不能同时执行,但是CPU对于执行线程的切换速度很快,所以对外感觉多个线程是同时执行的,所以单核CPU没有并行,本质上还是并发。
-
多核CPU:
CPU有多个核心,所以有的线程就可以同时被多个CPU核心执行,那么就达到了并行(真正的同时执行线程),但是一般线程数肯定大于CPU核心数,所以还是会有并发存在,所以多核CPU就是并行和并发同时执行。
-
-
线程创建的方式有那些
- (MyThread类)继承Thread类
- 重写run方法
- new一个线程对象MyThread
- 线程对象MyThread调用start方法启动线程
- (MyRunnable类)实现runnable接口
- 重写run方法
- 创建MyRunnable对象,并将对象封装到Thread对象中
- 线程对象Thread调用start方法启动线程
- (MyCallable类)实现Callable接口
- 重写call方法(有返回值)
- 创建MyCallable对象,并将对象封装到FutureTask对象中,再将FutureTask对象封装到Thread对象中
- 线程对象Thread调用start方法启动线程
- 通过FutureTask对象得到线程方法执行后的返回值
- 线程池创建线程,使用ThreadPoolExecutor类,设置七大参数(项目中一般都是用这个)
- (MyThread类)继承Thread类
-
runnable和callable有什么区别
- runnable无返回值、callable可以得到线程执行后的返回值(结合FutureTask对象)
- runnable实现的run()、callable实现的call()
- runnable实现的run()不能向上抛异常,只能在内部处理异常,callable实现的call()可以向上抛异常
-
线程的run()和start()有什么区别
- 线程对象调用start()才能启动一个新的线程,调用run()不能启动新的线程
- 同一个线程对象不可以多次调用start(),可以多次调用run()
-
线程包括哪些状态,状态之间是如何变化的
六种状态:State枚举类里面有定义
- 新建态(NEW):新建态(创建线程对象)
- 可执行态(RUNNABLE):新建态调用start(),就变成了可执行状态(有执行资格,如果被执行了就是运行态,没有被执行就是就绪态)
- 阻塞态(BLOCKED):运行态(可执行状态)的线程没有获得锁就会变成阻塞态,拿到了锁就会变成就绪态(可执行状态)
- 等待态(WAITING):主动让运行态的线程调用wait(),就会变成等待状态,调用notify()唤醒线程,就会变成就绪态(可执行状态)
- 计时等待态(TIMED_WAITING):主动让运行态的线程调用sleep(),就会变成时间等待状态,等时间一过,就会变成就绪态(可执行状态)
- 终止态(TERMINATED):(线程终止)
-
新建三个线程,如何保证它们按顺序执行
可以使用线程中的join方法解决
-
在Java中wait和sleep方法的不同
- wait() 、wait(long) 和sleep(long) 的效果都是让当前线程暂时放弃CPU的使用权,进入阻塞状态
- 方法归属不同:
- sleep(long)是Thread类的静态方法
- wait() 、wait(long)都是Object的实例方法
- 唤醒时间不同:
- 执行了sleep(long)、wait(long)的线程都会在等待响应时间后主动被唤醒
- wait() 、wait(long)可以被notify()和notifyAll()唤醒,其中wait() 必须被notify()和notifyAll()唤醒
- 锁的性质不同(重点):
- wait方法的调用必须先获取对象锁,而sleep不用
-
notify()和notifyAll()有什么区别
- notify():随机唤醒一个调用了wait()方法的线程
- notifyAll():唤醒所有调用了wait()方法的线程
-
如何停止一个正在运行的线程
- 使用stop方法强行终止(不推荐,方法已作废)
- 使用interrupt方法中断线程
- 打断阻塞的线程( sleep, wait, join)的线程,线程会抛出InterruptedException异常
- 打断正常的线程,可以根据打断状态来标记是否退出线程
- 使用退出标志,使线程正常退出,也就是当run方法完成后线程终止
-
什么是ThreadLocal?
ThreadLocal是一种线程隔离机制,它提供了多线程环境下对于共享变量访问的安全性。
在多线程中访问共享变量,要保证安全性,可以通过:
- 对共享变量加锁,从而保证同一时刻只有拿到锁的线程可以访问该变量,其他线程只能等待锁释放才能访问,但是加锁会带来一些性能开销,所以可以使用ThreadLocal来解决。
- ThreadLocal用了一种空间换时间的思想,在每个线程里面,都有一个容器来存储共享变量的副本,然后每个线程只能对这个变量的副本来进行操作,而不会影响到其他的线程对应的副本,那就可以保证了这个共享变量的安全性,又减少了加锁带来的开销。
而且ThreadLocal提供了线程本地存储机制,利用该机制将数据缓存到某个线程内部,该线程可以在任意方法中获取缓存的数据。
应用场景:
瑞吉外卖项目,有个场景就是在某个方法中要获取当前登录用户的id来进行数据库的操作,但是不能直接拿到这个id,此时就想到可以使用ThreadLocal来解决,因为这个用户id可以在另一个方法中获取到(过滤器的doFilter方法中,如果session中有登录信息,就放行页面,并且将登录信息放到ThreadLocal中),而这两个方法同属于一个线程,一个线程内的变量,在不同的方法内可以共享访问,那就可以在那个方法中set一下这个变量,然后在当前方法中get一下这个变量即可。
-
ThreadLocal的底层原理?
在 Thread 类里面有一个成员变量ThreadLocalMap,它专门来存储当前线程的共享变量副本,后续这个线程对于共享变量的操作,都是从这个 ThreadLocalMap 里面进行变更,不会影响全局共享变量的值,key为threadLocal对象,value为具体的值,具体涉及的方法一般就是set()、get()、remove()。
为了放置ThreadLocal出现内存泄漏的问题(key是弱引用的变量,value为强引用,key会被GC回收,value不会),可以使用remove()方法清理threadLocal对象。
并发安全:
-
你谈谈JMM (Java 内存模型)
JMM:Java memory model Java内存模型(不是jvm中的内存结构)
定义了共享内存中 多线程程序读写操作的行为规范,通过这些规则 来规范对内存的读写操作 从而确保指令的正确性。
JMM把内存分为两块:
- 工作内存:线程私有的工作区域
- 主内存:所有线程的共享区域
- 线程跟线程之间是相互隔离,线程跟线程交互需要通过主内存
-
在Java中有什么锁?(Java的锁机制)
按照锁的思想可以分为两类:
-
乐观锁:CAS
乐观锁的思想就是线程即使没有拿到锁,也会继续去尝试
- 是一种比较并交换的思想,是一个原子性的操作。与之相对的,synchronized锁每次只会让一个线程去操作共享资源,而CAS相当于没有加锁,多个线程都可以访问共享资源,在实际修改的时候才会去判断能否修改成功。
- CAS的应用(配合volatile使用):
- 自旋锁:while(CAS),不断的进行CAS的操作,用于对于重量级锁的优化
-
悲观锁:
悲观锁的思想就是线程如果没有拿到锁,就会被阻塞
- synchronized
- ReentryLock
-
-
Java常见的加锁方式
在并发编程中,加锁是一种常用的方法,用于保护临界区资源的访问安全
-
synchronized关键字:修饰代码块或者方法,保证只有一个线程能够获取对象锁,其他线程阻塞,访问完毕后自动释放锁
public synchronized void increment() { count++; } -
ReentryLock类:是一个可重入锁,相比于synchronized,ReentrantLock提供了更多的灵活性和可控性,例如可实现公平锁,可指定等待时间等。
需要new一个ReentryLock对象,调用lock()方法主动开启锁,访问完毕后需要调用unlock()方法主动释放锁
private Lock lock = new ReentrantLock(); public void increment() { lock.lock(); try { count++; } finally { lock.unlock(); } } -
ReadWriteLock接口:是Java提供的一种读写锁机制,它允许多个线程同时读取共享资源,但只允许一个线程写入共享资源,这种机制可以提高读操作的并发性能。
需要new一个ReentrantReadWriteLock对象(ReadWriteLock接口的实现类),
调用writeLock().lock()方法主动开启写锁,修改完毕后 需要调用writeLock().unlock()方法主动释放锁
调用readLock().lock()方法主动开启读锁,读取完毕后 需要调用readLock().unlock()方法主动释放锁
private ReadWriteLock lock = new ReentrantReadWriteLock(); public void increment() { lock.writeLock().lock(); try { count++; } finally { lock.writeLock().unlock(); } } public int getCount() { lock.readLock().lock(); try { return count; } finally { lock.readLock().unlock(); } } -
总结:
- synchronized关键字:适用于简单的加锁场景
- ReentrantLock类:具有更高的灵活性和可控性,例如公平锁、可中断锁、超时锁等
- ReadWriteLock接口:适用于读多写少的场景,提高读操作的并发性
-
-
synchronized关键字的底层原理
- Synchronized关键字可以修饰代码块或者方法,它采用互斥的方式 让同一时刻只能有一个线程持有对象锁,其它线程再想获取这个对象锁时就会被阻塞住,所以就可使得代码块或者方法是线程安全的
- 不管synchronized修饰的是什么,对应的锁都是一个对象,在java中,一个对象其实由三部分组成:对象头、实际数据区、对齐填充区
- 对其填充区就是为了填满字节数用的,没什么说的
- 实际数据区就是对象的一些属性和状态
- 对象头中有个Mark Word会记录 这个对象关于锁的信息
- 每个对象都会有一个与之对应的Monitor对象(监视器,是由jvm提供,C+ +语言实现)
- 在monitor内部有三个属性,分别是owner、entrylist、 waitset
- owner:关联的是获得锁的线程,只能关联一个线程
- entrylist:关联的是处于阻塞状态的线程
- waitset:关联的是处于等待状态的线程
- 在monitor内部有三个属性,分别是owner、entrylist、 waitset
-
synchronized在jdk1.8之前用的比较少,因为性能比较低,jdk1.8之后对锁进行了一些优化,具体有什么优化?
- synchronized锁的特点:锁的竞争不激烈就是轻量级锁,效率高,锁的竞争比较激烈就会转换称重量级锁,效率低
- 对锁的优化有:锁消除、锁膨胀、偏向锁等等
-
什么是AQS
- AQS叫做抽象队列同步器,它是一种锁机制,它是作为一个基础框架使用的,像ReentrantLock就是基于它实现的。
- 内部维护了一个双向队列,队列中就是排队等待获取锁的线程
-
什么是ReentrantLock
- ReentrantLock叫做可重入锁,一个线程可以多次调用lock方法
- 实现主要是通过CAS+AQS队列
-
synchronized和Lock有什么区别
- 语法层面:
- synchronized是关键字,源码在jvm中,用C++语言实现
- Lock是接口,源码由jdk提供,用Java语言实现
- 使用synchronized时,退出同步代码块 锁会自动释放,而使用Lock时,需要手动调用unlock方法释放锁
- 性能层面:
- 在没有竞争时,synchronized性能较好,竞争激烈时,会从轻量级锁升级为重量级锁,性能较差
- 在竞争激烈时,Lock 的实现通常会提供更好的性能
- 功能层面:
- 二者均属于悲观锁
- 语法层面:
-
死锁产生的条件是什么
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
死锁需要必要的条件才能产生,死锁的四个必要条件:
- 互斥:一个资源每次只能被一个进程使用;
- 请求与保持:一个进程因请求资源而阻塞时,对已获得的资源保持不放;
- 不可抢夺:进程已获得的资源,在末使用完之前,不能强行抢夺;
- 循环等待:若干进程之间形成一种头尾相接的循环等待资源关系;
解决死锁的方法:
(1)死锁要尽可能的避免,也就是打破其中的必要条件(预防死锁)
(2)真正的出现了死锁,就只能诊断到死锁的原因,然后采取一些措施,将死锁清除掉
-
在Java程序中出现了死锁,如何进行诊断
-
当程序出现了死锁现象,我们可以使用jdk自带的工具: jps和 jstack
- jps:输出JVM中运行的进程状态信息
- jstack:查看Java进程内线程的堆栈信息
-
还可以用其他可视化工具,例如jconsole(用于对jvm的内存、线程、类的监控,是一个基于jmx的GUI性能监控工具)
-
-
聊一下ConcurrentHashMap
- ConcurrentHashMap是线程安全的 而且是高效的map集合
- 底层实现:哈希表
- jdk1.8之前是采用分段的数组+链表,保证线程安全主要是通过 ReentrantLock可重入锁
- jdk1.8之后是采用数组+链表+红黑树,保证线程安全主要是通过 CAS的自旋锁+synchronized
-
请谈谈你对volatile的理解
volatile关键字可以作用于变量(一般是共享变量,类的成员变量、静态成员变量),它使得变被修饰的变量具有两种语义:
-
保证变量对所有线程的可见性,也就是说当一个线程修改了volatile修饰的变量的值,这对于其他线程来说都能够立即知晓新值。
-
禁止进行指令重排序,正常来讲,如果对变量不使用volatile关键字修饰的话,编译器会对指令进行重排序优化来获得更好的性能,但是有时候这种编译器优化可能会导致程序没有产生预期的结果,所以如果需要阻止编译器对变量作重排序, 就可以使用volatile关键字来修饰。
-
-
导致并发程序出现问题的根本原因是什么
并发问题出现,主要体现在三个方面:
- 原子性:指的是一个操作是不可以中断的,要么就全部执行,要么就都不执行。
- 可见性:是指当多个线程访问同一个变量的时候,一个线程修改了这个变量的值,那么其他线程能立马知晓这个变量的新值。
- 有序性:是指程序执行的顺序是按照代码的先后顺序来执行。
如果没有满足其中的一点,就有可能出现并发问题。
volatile关键字修饰的变量是可以保证可见性和有序性的,但是并不可以保证原子性,所以不能解决并发编程的问题。如果要满足并发编程的三个特性,可以使用synchronized或者lock锁来实现。
线程池:
线程池是一种池化技术,实现了资源的复用,具体好处有:
1. 降低资源消耗:通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
2. 提高响应速度:当任务到达时,任务可以不需要的等到线程创建就能立即执行。
3. 提高线程的可管理性:线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
-
线程池的核心参数、线程池的执行原理(ThreadPoolExecutor类的七大参数)
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {- corePoolSize:核心线程数
- maximumPoolSize:最大线程数(核心线程+临时线程)
- keepAliveTime:临时线程的生存时间
- unit:临时线程生存时间的 单位(s、ms)
- workQueue:阻塞队列(当没有空闲的核心线程时,新任务会放在阻塞队列中,阻塞队列一满,如果还有临时线程可用,就会分配给阻塞队列中的任务)
- threadFactory:线程工厂(可以定制线程对象的创建)
- handler:拒绝策略(当核心线程都在用+阻塞队列已满+临时线程都在用,再来任务就会拒绝)
线程池的执行原理:
- 提交任务交给线程执行
- 判断核心线程是否有空余
- 如果有,就把任务交给核心线程执行
- 如果没有,就将任务添加到阻塞队列
- 如果阻塞队列也已经满了,就判断是否有临时线程空余
- 如果有,就把任务交给临时线程执行
- 如果没有,就执行拒绝策略(抛出异常、直接丢弃任务)
-
线程池中有哪些常见的阻塞队列
-
ArrayBlockingQueue: 基于数组结构的有界阻塞队列,FIFO
-
LinkedBlockingQueue: 基于单向链表结构的有界阻塞队列,FIFO
-
DelayedWorkQueue: 是一个优先级队列,它可以保证每次出队的任务都是当前队列中执行时间最靠前的
-
SynchronousQueue: 不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作。
主要使用的是数组和链表阻塞队列,具体的区别:
- 数组阻塞队列底层是数组实现的,链表阻塞队列底层是链表实现的
- 数组阻塞队列必须有界,也就是初始化的时候必须给容量,链表阻塞队列默认是无界的,当然也可以给个初始容量
- 数组阻塞队列会根据容量提前初始化好数组,链表阻塞队列添加数据的时候再创建节点
- 数组阻塞队列采用的是一把锁的机制,链表阻塞队列是头尾两把锁,效率更高,更多采用这个
-
-
线程池的拒绝策略有哪些?
当核心线程数满了、阻塞队列满了、临时线程数满了,再来新任务就会引发拒绝策略
- AbortPolicy(默认的):抛出异常
- DiscardPolicy:直接丢弃任务
- CallerRunsPolicy:将任务返回给调用者,让调用者自行处理
- DiscardOldestPolicy:丢弃阻塞队列中最早的任务,然后就可以把新任务加进来
-
如何确定核心线程数
-
lO密集型任务(比如文件读写、数据库读写):设置2N+1(N为CPU核数),大多数时候的业务场景
-
CPU密集型任务(比如计算类型的代码):设置N+1
//查看机器的CPU核数N Runtime.getRuntime().availableProcessors();
-
-
线程池的种类有哪些
- newFixedThreadPool:创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待
- newSingleThreadExecutor:创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO)执行
- newCachedThreadPool:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
- newScheduledThreadPool:可以执行延迟任务的线程池,支持定时及周期性任务执行
-
为什么不建议用Executors创建线程池
涉及到一个Integer.MAX_INT,容易导致OOM内存溢出,一般还是采用ThreadPoolExecutor,设置七个参数来创建线程池。
【后续继续补充,敬请期待】