Spring 是如何解决循环依赖的
1.什么是循环依赖?
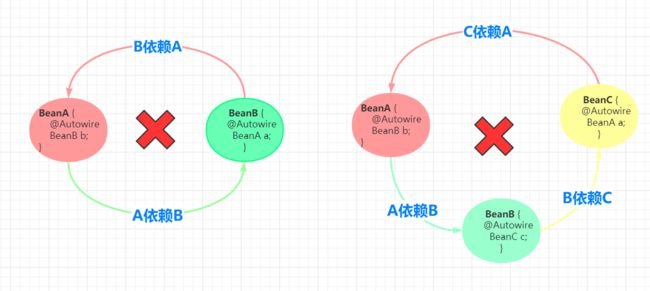
所谓的循环依赖是指,A 依赖 B,B 又依赖 A,它们之间形成了循环依赖。或者是 A 依赖 B,B 依赖 C,C 又依赖 A。它们之间的依赖关系如下:
2.通过手写代码演示理解Spring循环依赖
DEMO:
public class MainStart {
private static Map beanDefinitionMap = new ConcurrentHashMap<>(256);
/**
* 读取bean定义,当然在spring中肯定是根据配置 动态扫描注册
*/
public static void loadBeanDefinitions() {
RootBeanDefinition aBeanDefinition=new RootBeanDefinition(InstanceA.class);
RootBeanDefinition bBeanDefinition=new RootBeanDefinition(InstanceB.class);
beanDefinitionMap.put("instanceA",aBeanDefinition);
beanDefinitionMap.put("instanceB",bBeanDefinition);
}
public static void main(String[] args) throws Exception {
// 加载了BeanDefinition
loadBeanDefinitions();
// 注册Bean的后置处理器
// 循环创建Bean
for (String key : beanDefinitionMap.keySet()){
// 先创建A
getBean(key);
}
InstanceA instanceA = (InstanceA) getBean("instanceA");
instanceA.say();
}
// 一级缓存
public static Map singletonObjects=new ConcurrentHashMap<>();
// 二级缓存: 为了将 成熟Bean和纯净Bean分离,避免读取到不完整得Bean
public static Map earlySingletonObjects=new ConcurrentHashMap<>();
// 三级缓存
public static Map singletonFactories=new ConcurrentHashMap<>();
// 循环依赖标识
public static Set singletonsCurrennlyInCreation=new HashSet<>();
// 假设A 使用了Aop @PointCut("execution(* *..InstanceA.*(..))") 要给A创建动态代理
// 获取Bean
public static Object getBean(String beanName) throws Exception {
Object singleton = getSingleton(beanName);
if(singleton!=null){
return singleton;
}
// 正在创建
if(!singletonsCurrennlyInCreation.contains(beanName)){
singletonsCurrennlyInCreation.add(beanName);
}
// createBean
// 实例化
RootBeanDefinition beanDefinition = (RootBeanDefinition) beanDefinitionMap.get(beanName);
Class beanClass = beanDefinition.getBeanClass();
Object instanceBean = beanClass.newInstance(); // 通过无参构造函数
// 创建动态代理 (耦合 、BeanPostProcessor) Spring还是希望正常的Bean 还是再初始化后创建
// 只在循环依赖的情况下在实例化后创建proxy 判断当前是不是循环依赖
singletonFactories.put(beanName, () -> new JdkProxyBeanPostProcessor().getEarlyBeanReference(earlySingletonObjects.get(beanName),beanName));
// 添加到二级缓存
// earlySingletonObjects.put(beanName,instanceBean);
// 属性赋值
Field[] declaredFields = beanClass.getDeclaredFields();
for (Field declaredField : declaredFields) {
Autowired annotation = declaredField.getAnnotation(Autowired.class);
// 说明属性上面有Autowired
if(annotation!=null){
declaredField.setAccessible(true);
// byname bytype byconstrator
// instanceB
String name = declaredField.getName();
Object fileObject= getBean(name); //拿到B得Bean
declaredField.set(instanceBean,fileObject);
}
}
// 初始化 init-mthod
// 放在这里创建已经完了 B里面的A 不是proxy
// 正常情况下会再 初始化之后创建proxy
// 由于递归完后A 还是原实例,, 所以要从二级缓存中拿到proxy 。
if(earlySingletonObjects.containsKey(beanName)){
instanceBean=earlySingletonObjects.get(beanName);
}
// 添加到一级缓存 A
singletonObjects.put(beanName,instanceBean);
// remove 二级缓存和三级缓存
return instanceBean;
}
public static Object getSingleton(String beanName){
// 先从一级缓存中拿
Object bean = singletonObjects.get(beanName);
// 说明是循环依赖
if(bean==null && singletonsCurrennlyInCreation.contains(beanName)){
bean=earlySingletonObjects.get(beanName);
// 如果二级缓存没有就从三级缓存中拿
if(bean==null) {
// 从三级缓存中拿
ObjectFactory factory = singletonFactories.get(beanName);
if (factory != null) {
bean=factory.getObject(); // 拿到动态代理
earlySingletonObjects.put(beanName, bean);
}
}
}
return bean;
}
} 为什么需要二级缓存?
- 一级缓存和二级缓存相比:
二级缓存只要是为了分离成熟Bean和纯净Bean(未注入属性)的存放, 防止多线程中在Bean还未创建完成时读取到的Bean时不完整的。所以也是为了保证我们getBean是完整最终的Bean,不会出现不完整的情况。
- 一二三级缓存下二级缓存的意义:
二级缓存为了存储 三级缓存的创建出来的早期Bean, 为了避免三级缓存重复执行。
为什么需要三级缓存?
我们都知道Bean的aop动态代理创建时在初始化之后,但是循环依赖的Bean如果使用了AOP。 那无法等到解决完循环依赖再创建动态代理, 因为这个时候已经注入属性。 所以如果循环依赖的Bean使用了aop. 需要提前创建aop。
但是需要思考的是动态代理在哪创建? 在实例化后直接创建? 但是我们正常的Bean是在初始化创建啊。 所以可以加个判断如果是循环依赖就实例化后调用,没有循环依赖就正常在初始化后调用。
怎么判断当前创建的bean是不是循环依赖? 根据二级缓存判断?有就是循环依赖?
那这个判断怎么加?加载实例化后面行吗? 下面是伪代码:
实例化后.省略code....
if(二级缓存有说明是循环依赖?){
二级缓存=创建动态代理覆盖(判断当前bean是否被二级缓存命中);
}
这样写可以吗? 肯定不行啊, 因为实例化后始终会放入二级缓存中。 所以这样写不管是不是循环依赖都会在实例化后创建动态代理。
创建本身的时候没法判断自己是不是循环依赖,, 只有在B 引用A (不同bean的引用直接)下才能判断是不是循环依赖(比如B引用A,A正在创建,那说明是循环依赖), 所以判断要卸载getSingleton中。
假如A是proxy:
A创建Bean -->注入属性B-->getBean(B)-->创建B-->注入属性A---->getSingleton("a")之后写如下代码
==================================================================================================
public object getSingleton(beanName){
先从一级缓存拿 省略code...
if(二级缓存有说明是循环依赖?){
二级缓存=调用创建动态代BeanPostProcessor(判断是否使用aop,没有依然返回原实例);
}
}在这里创建行吗? 行! 所以说二级缓存确实完全可以解决循环依赖的任何情况:包括扩展能力(因为也可以在这里调用BeanPostProcessor, 当然AOP也是基于BeanPostProcessor,虽然也当然可以解决) 。 那要三级缓存干嘛? 我们只能这样解释: Spring的方法职责都比较单例,一个方法通常只做一件事, getBean就是获取bean 但是调用创建动态代BeanPostProcessor 是属于create的过程中的, 如果在这里明显代码比较耦合,阅读性也不太好。 所以为了解耦、方法职责单一、方便后期维护, 将调用创建动态代BeanPostProcessor 放在createBean中是最合适不过了, 但是我们判断当前是否循环依赖还是要写在getSingleton里面啊,这怎么办:
三级缓存 存一个函数接口, 函数接口实现 创建动态代理调用BeanPostProcessor 。 为了避免重复创建, 调用把返回的动态代理对象或者原实例存储在二级缓存, 三个缓存完美解决解耦、扩展、性能、代码阅读性。
为什么Spring不能解决构造器的循环依赖?
从流程图应该不难看出来,在Bean调用构造器实例化之前,一二三级缓存并没有Bean的任何相关信息,在实例化之后才放入三级缓存中,因此当getBean的时候缓存并没有命中,这样就抛出了循环依赖的异常了。
为什么多例Bean不能解决循环依赖?
我们自己手写了解决循环依赖的代码,可以看到,核心是利用一个map,来解决这个问题的,这个map就相当于缓存。
为什么可以这么做,因为我们的bean是单例的,而且是字段注入(setter注入)的,单例意味着只需要创建一次对象,后面就可以从缓存中取出来,字段注入,意味着我们无需调用构造方法进行注入。
- 如果是原型bean,那么就意味着每次都要去创建对象,无法利用缓存;
- 如果是构造方法注入,那么就意味着需要调用构造方法注入,也无法利用缓存。
循环依赖可以关闭吗
可以,Spring提供了这个功能,我们需要这么写:
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext();
applicationContext.setAllowCircularReferences(false);
applicationContext.register(AppConfig.class);
applicationContext.refresh();
}
}
3 源码:如何解决循环依赖?
哪三级缓存?
DefaultSingletonBeanRegistry类的三个成员变量命名如下:
/** 一级缓存 这个就是我们大名鼎鼎的单例缓存池 用于保存我们所有的单实例bean */
private final Map singletonObjects = new ConcurrentHashMap<>(256);
/** 三级缓存 该map用户缓存 key为 beanName value 为ObjectFactory(包装为早期对象) */
private final Map> singletonFactories = new HashMap<>(16);
/** 二级缓存 ,用户缓存我们的key为beanName value是我们的早期对象(对象属性还没有来得及进行赋值) */
private final Map earlySingletonObjects = new HashMap<>(16); 以 BeanA 和 BeanB 两个类相互依赖为例
创建原始 bean 对象
instanceWrapper = createBeanInstance(beanName, mbd, args);
final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);假设 beanA 先被创建,创建后的原始对象为BeanA@1234,上面代码中的 bean 变量指向就是这个对象。
暴露早期引用
该方法用于把早期对象包装成一个ObjectFactory 暴露到三级缓存中 用于将解决循环依赖...
protected void addSingletonFactory(String beanName, ObjectFactory singletonFactory) {
...
//加入到三级缓存中,,,,,暴露早期对象用于解决循环依赖
this.singletonFactories.put(beanName, singletonFactory);
...
}beanA 指向的原始对象创建好后,就开始把指向原始对象的引用通过 ObjectFactory 暴露出去。getEarlyBeanReference 方法的第三个参数 bean 指向的正是 createBeanInstance 方法创建出原始 bean 对象 BeanA@1234。
解析依赖
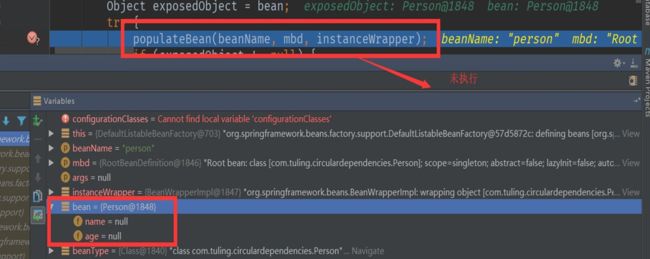
populateBean(beanName, mbd, instanceWrapper);还没有进行属性装配,自动注入的属性都是null
初始化好的Bean
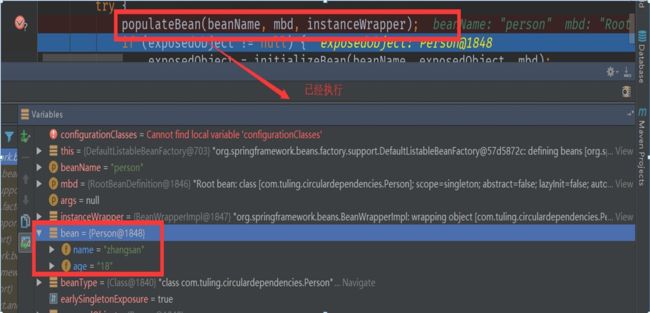
populateBean 用于向 beanA 这个原始对象中填充属性,当它检测到 beanA 依赖于 beanB 时,会首先去实例化 beanB。
beanB 在此方法处也会解析自己的依赖,当它检测到 beanA 这个依赖,于是调用 BeanFactroy.getBean("beanA") 这个方法,从容器中获取 beanA。
获取早期引用
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
/**
* 第一步:我们尝试去一级缓存(单例缓存池中去获取对象,一般情况从该map中获取的对象是直接可以使用的)
* IOC容器初始化加载单实例bean的时候第一次进来的时候 该map中一般返回空
*/
Object singletonObject = this.singletonObjects.get(beanName);
/**
* 若在第一级缓存中没有获取到对象,并且singletonsCurrentlyInCreation这个list包含该beanName
* IOC容器初始化加载单实例bean的时候第一次进来的时候 该list中一般返回空,但是循环依赖的时候可以满足该条件
*/
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
/**
* 尝试去二级缓存中获取对象(二级缓存中的对象是一个早期对象)
* 何为早期对象:就是bean刚刚调用了构造方法,还来不及给bean的属性进行赋值的对象(纯净态)
* 就是早期对象
*/
singletonObject = this.earlySingletonObjects.get(beanName);
/**
* 二级缓存中也没有获取到对象,allowEarlyReference为true(参数是有上一个方法传递进来的true)
*/
if (singletonObject == null && allowEarlyReference) {
/**
* 直接从三级缓存中获取 ObjectFactory对象 这个对接就是用来解决循环依赖的关键所在
* 在ioc后期的过程中,当bean调用了构造方法的时候,把早期对象包裹成一个ObjectFactory
* 暴露到三级缓存中
*/
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
//从三级缓存中获取到对象不为空
if (singletonFactory != null) {
/**
* 在这里通过暴露的ObjectFactory 包装对象中,通过调用他的getObject()来获取我们的早期对象
* 在这个环节中会调用到 getEarlyBeanReference()来进行后置处理
*/
singletonObject = singletonFactory.getObject();
//把早期对象放置在二级缓存,
this.earlySingletonObjects.put(beanName, singletonObject);
//ObjectFactory 包装对象从三级缓存中删除掉
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}接着上面的步骤讲:
- populateBean 调用 BeanFactroy.getBean("beanA") 以获取 beanB 的依赖。
- getBean("beanB") 会先调用 getSingleton("beanA"),尝试从缓存中获取 beanA。此时由于 beanA 还没完全实例化好
- 于是 this.singletonObjects.get("beanA") 返回 null。
- 接着 this.earlySingletonObjects.get("beanA") 也返回空,因为 beanA 早期引用还没放入到这个缓存中。
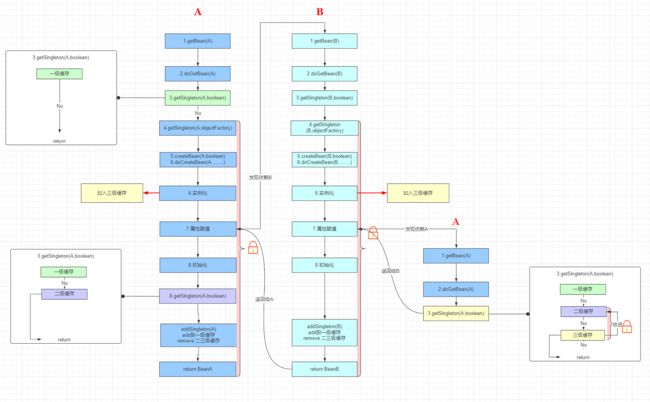
- 最后调用 singletonFactory.getObject() 返回 singletonObject,此时 singletonObject != null。singletonObject 指向 BeanA@1234,也就是 createBeanInstance 创建的原始对象。此时 beanB 获取到了这个原始对象的引用,beanB 就能顺利完成实例化。beanB 完成实例化后,beanA 就能获取到 beanB 所指向的实例,beanA 随之也完成了实例化工作。由于 beanB.beanA 和 beanA 指向的是同一个对象 BeanA@1234,所以 beanB 中的 beanA 此时也处于可用状态了。
以上的过程对应下面的流程图:
4 如何进行拓展?
bean可以通过实现SmartInstantiationAwareBeanPostProcessor接口(一般这个接口供spring内部使用)的getEarlyBeanReference方法进行拓展
何时进行拓展?
(进行bean的实例化时)
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)throws BeanCreationException {
//省略其他代码,只保留了关键代码
//...
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
//将刚实例化好的bean添加到一级缓存中
addSingletonFactory(beanName, new ObjectFactory
@Override
public Object getObject()throws BeansException {
//执行拓展的后置处理器
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
}getEarlyBeanReference方法
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
//判读我们容器中是否有InstantiationAwareBeanPostProcessors类型的后置处理器
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
//获取我们所有的后置处理器
for (BeanPostProcessor bp : getBeanPostProcessors()) {
//判断我们的后置处理器是不是实现了SmartInstantiationAwareBeanPostProcessor接口
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
//进行强制转换
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
//挨个调用SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}扩展示例:
@Component
public class TulingBPP implements SmartInstantiationAwareBeanPostProcessor {
public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {
if(beanName.equals("instanceA") || beanName.equals("instanceB")) {
JdkDynimcProxy jdkDynimcProxy = new JdkDynimcProxy(bean);
return jdkDynimcProxy.getProxy();
}
return bean;
}
}5.总结
Spring 框架在处理循环依赖问题方面展现出了其强大的依赖注入机制和灵活的 Bean 创建过程。通过构建依赖图并在运行时解析依赖关系,Spring 能够有效地解决循环依赖的困扰。
在本文中,我们深入探讨了 Spring 如何处理单例 Bean 之间的循环依赖。Spring 通过两阶段依赖注入的方式,首先创建对象并注入基本类型的属性,然后在完成对象创建后再进行循环依赖的处理。这种方式允许 Spring 在运行时动态解决循环依赖,确保 Bean 之间的正确初始化和注入。
需要注意虽然 Spring 能够解决许多情况下的循环依赖,但过度复杂或者混乱的依赖关系仍可能导致解析失败或性能问题。因此,在设计应用程序时,应该尽量避免过多的循环依赖,保持依赖关系的清晰和简洁。