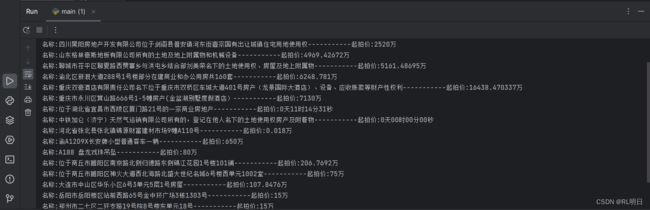
实战8、Python法拍网数据
一、前提声明
1、拍卖标题的Xpath路径
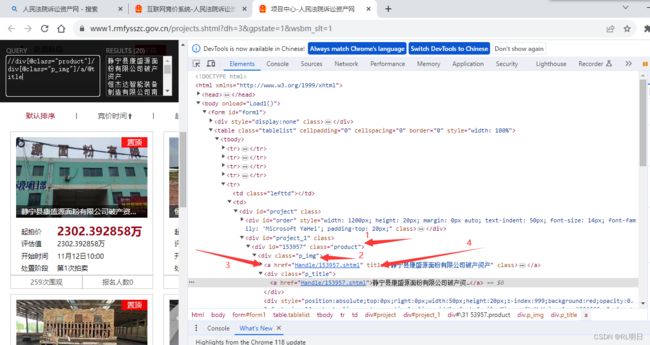
2、起拍价格的Xpath路径
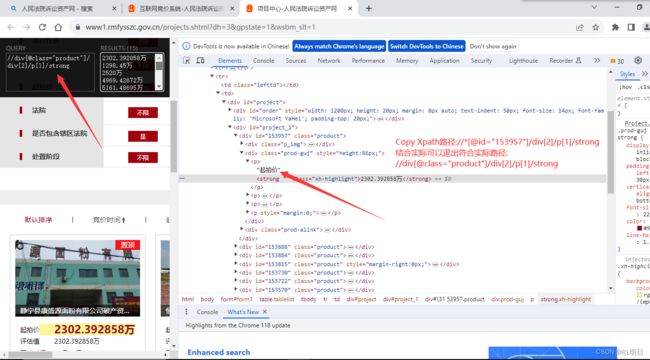
3、估值价格的Xpath路径
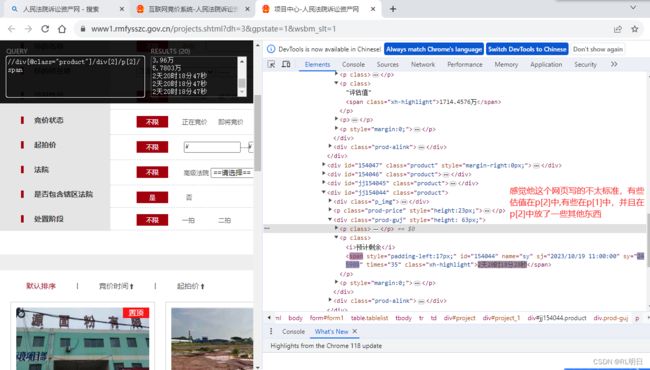
4、数据类型路径

二、Zip的用法
在Python中,zip() 是一个内置函数,用于将多个可迭代对象(例如列表、元组等)组合成一个元组的序列。每个元组包含来自输入可迭代对象的对应位置的元素。这可以用于同时遍历多个列表,进行并行迭代,或将多个列表的元素组合成键值对。
基本语法如下:
zip(iterable1, iterable2, ...)
iterable1,iterable2, ... 是您想要组合的可迭代对象(例如列表、元组、字符串等)。
以下是一些示例,说明了zip() 的用法:
1、示例1:并行迭代
fruits = ["apple", "banana", "cherry"]
prices = [1.0, 0.5, 2.0]
# 并行迭代两个列表
for fruit, price in zip(fruits, prices):
print(f"{fruit}: ${price}")
输出:
apple: $1.0
banana: $0.5
cherry: $2.0
2、示例2:组合成字典
keys = ["name", "age", "city"]
values = ["Alice", 30, "New York"]
# 使用zip()将两个列表组合成字典
info_dict = dict(zip(keys, values))
print(info_dict)
输出:
{'name': 'Alice', 'age': 30, 'city': 'New York'}
3、示例3:拆分元组
pairs = [(1, 'one'), (2, 'two'), (3, 'three')]
# 使用zip()拆分元组
numbers, words = zip(*pairs)
print(numbers)
print(words)
输出:
(1, 2, 3)
('one', 'two', 'three')
请注意,zip()会在输入的可迭代对象中找到最短的一个,然后停止。如果输入的可迭代对象长度不同,结果将以最短的为准。如果您需要处理不等长的可迭代对象,您可以使用itertools.zip_longest() 函数,它将填充缺失的值。
三、完整代码以及运行结果
1、代码
import requests
#使用Xpath 工具模块 pip install lxml
from lxml import etree
form_data ={
'type': '0',
'name': '',
'area':'',
'city': '不限',
'city1': '----',
'city2': '----',
'xmxz': '0',
'state': '0',
'money':'',
'money1':'',
'number': '0',
'fid1':'',
'fid2':'',
'fid3':'',
'order': '0',
'page': '1',
'include': '0'
}
#网站地址
url = 'https://www1.rmfysszc.gov.cn/ProjectHandle.shtml'
#伪装请求头,一般访问,只需要User-Agent即可,但是对于一些反爬网址,只需要更高级的伪装,如Rederer和Cookie等
heardes = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
'Referer':'https://www1.rmfysszc.gov.cn/projects.shtml?dh=3&gpstate=1&wsbm_slt=1',
'Cookie':'__jsluid_s=bc489f1039d2b3cbd0cf95ebfd9003c9; Cookies-01=59063098; ASP.NET_SessionId=ffti5cgkzyghc3qfgadsblc4; Hm_lvt_5698cdfa8b95bb873f5ca4ecf94ac150=1697433518; __jsl_clearance_s=1697466759.139|0|%2F%2F2vvtzGAGCc64HKJDrlvmFoU6g%3D; Hm_lpvt_5698cdfa8b95bb873f5ca4ecf94ac150=1697466761'
}
respond = requests.post(url,headers=heardes,data=form_data)
#查看结果
e = etree.HTML(respond.text)
#提取数据
titles = e.xpath('//div[@class="product"]/div[@class="p_img"]/a/@title')#标题
#数据类型
infos = e.xpath('//div[@class="product"]/div[2]/p[1]/text()')
price1 = e.xpath('//div[@class="product"]/div[2]/p[1]/strong/text()') #起拍价
price2 = e.xpath('//div[@class="product"]/div[2]/p[2]/span/text()') #估值
#将titles,infos,price1,price2分别赋给t,i,p1,p2进行组合
for t,i,p1,p2 in zip(titles,infos,price1,price2):
if i== '起拍价':
tp = p1
else:
tp = p2
print(f'名称:{t}-----------起拍价:{tp}')
2、结果
由与在获取评估值时,由个别正在进行拍卖,所以提取的数据有多余,如有时间参数等,如有感兴趣的同学,可以尝试去除一下.