TransNeXt:稳健的注视感知ViT学习笔记

论文地址:https://arxiv.org/pdf/2311.17132.pdf
代码地址: GitHub - DaiShiResearch/TransNeXt: Code release for TransNeXt model
可以直接在ImageNet上训练的分类代码:GitHub - athrunsunny/TransNext-classify
代码中读取数据的部分修改一下就可以换成自定义的训练数据集,可以参考:SG Former实战:训练自定义分类数据集_sgformer-CSDN博客
Abstract
由于残差连接中的深度衰减效应,许多依赖堆叠层进行信息交换的高效视觉Transformer模型往往无法形成足够的信息混合,导致视觉感知不自然。为了解决这个问题,本文提出了一种基于生物模拟的聚合注意力,这是一种模拟生物注视(biological foveal vision)和连续眼动的设计基础的token mixer,它允许特征图上的每个Token都具有全局感知。
此外,作者还引入了可学习的Token,这些Token与传统的Query和Key相互作用,这进一步使亲和矩阵(affinity matrices)的生成多样化,而不仅仅依赖于Query和Key之间的相似性。作者的方法不需要堆叠进行信息交换,因此可以有效避免深度衰减,并实现自然视觉感知。
此外,作者还提出了一种卷积GLU,这是一种连接GLU和SE机制的channel mixer,每个Token根据其最近邻图像特征具有通道注意力,增强局部建模能力和模型鲁棒性。作者将聚合注意力和卷积GLU相结合,创建了一个新的视觉骨干网络叫做TransNeXt。
大量实验表明,作者的TransNeXt在多个模型大小上都实现了最先进的性能。在224的分辨率下,TransNeXt-Tiny在ImageNet上的准确率为84.0%,比ConvNeXt-B减少了69%的参数。作者的TransNeXt-Base在384的分辨率下,ImageNet上的准确率为86.2%,在ImageNet-A上的准确率为61.6%。在384的分辨率下,COCO目标检测mAP为57.1,ADE20K语义分割mIoU为54.7。
Introduction
近年来,视觉Transformer(ViT)已成为各种计算机视觉任务的热门Backbone架构。ViT模型由两个关键组件组成:自注意力层(token mixer)和MLP层(channel mixer)。自注意力机制在特征提取中起着至关重要的作用,通过计算Query和Key之间的相似性动态生成亲和矩阵(affinity matrix)。这种全局信息聚合方法在无需像卷积那样的归纳偏差的情况下,展示了出色的特征提取潜力,并可以构建强大的数据驱动模型。然而,ViT的encoder的设计,最初是为了语言建模,在下游计算机视觉任务中表现出固有的限制。具体来说,自注意力中全局亲和矩阵的计算由于其平方复杂度和高内存消耗而面临挑战,这限制了其在高分辨率图像特征上的应用。
为了减轻自注意力机制中固有的平方复杂度和内存消耗带来的计算和内存负担,许多稀疏注意力机制在前人的研究中已经被提出。其中一种典型的方法是局部注意力,它限制了注意力在特征图上的一个窗口内。然而,由于其有限的感受野,这种方法通常需要与不同类型的token mixer交替堆叠以实现跨窗口信息交换。另一种典型的方法是在空间上对注意力的Key和Value进行下采样(例如,池化,网格采样)。由于它牺牲了Query对特征图的细粒度感知,这种方法也存在一定的局限性。最近的研究[7,57]交替堆叠空间下采样注意力和局部注意力,取得了令人满意的表现结果。
然而,最近的研究和实验表明,具有残差块的深度网络类似于较浅的集成网络,表明堆叠块实现的跨层信息交换可能不如预期的那样有效。
另一方面,局部注意力和空间下采样注意力与生物视觉的工作方式有显著不同。生物视觉对视觉焦点附近特征的分辨率更高,而对远处特征的分辨率较低。此外,眼球移动时,生物视觉这种特性在图像中任何位置的像素上都保持一致,这意味着像素级的平移等价性。然而,在基于窗口分区的局部注意中,窗口边缘和中心的Token不被视为等价,这明显存在差异。
作者观察到,由于残差连接中的深度衰减效应,许多高效的视觉Transformer(ViT)模型在堆叠层时无法形成足够的信息混合。即使堆叠了很深的层,它们的窗口分区的痕迹也总是形成不自然的伪影,如图2所示。为了解决这个问题,作者研究了一种视觉建模方法,该方法与生物视觉非常接近,以减轻潜在的模型深度衰减,并实现接近人类注视(foveal vision)时的信息感知。

为此,作者首先引入了像素聚焦注意力,它采用双路径设计。在一条路径中,每个Query具有对其最近邻居特征的细粒度注意力,而在另一条路径中,每个Query具有对空间下采样特征的粗粒度注意力,允许进行全局感知。这种方法是基于每个像素的,有效地模拟了眼球的连续移动。
此外,作者将Query embedding和位置注意力机制引入到像素聚焦注意力中,从而提出了聚合像素聚焦注意力,作者简称为聚合注意力。这种方法进一步多样化地生成了亲和矩阵(affinity matrices),而不仅仅是依赖Query和Key之间的相似性,从而在单个注意力层内聚合多个注意力机制。作者还重新评估了视觉Transformer中的channel mixer设计要求,并提出了名为Convolutional GLU的新型channel mixer。这种混合器更适合图像任务,并集成基于局部特征的通道注意力来增强模型的鲁棒性。
作者引入了TransNeXt,这是一种分层视觉Backbone网络,其中包含聚合注意力(AA)作为Token mixer和Convolutional GLU作为channel mixer。通过在图像分类、目标检测和分割任务上的全面评估,作者证明了这些混合组件的有效性。
作者的TransNeXt-Tiny,仅在ImageNet-1K上预训练,在ImageNet上的准确率达到84.0%,超过了ConvNeXt-B。在COCO目标检测中,它使用DINO检测头,在分辨率为384时,实现了55.1的框mAP,比在384分辨率下预训练的ConvNeXt-L提高了1.7。作者的TransNeXt-Small/Base,仅在384分辨率下进行5个epoch的微调,在ImageNet上的准确率达到了**86.0%/86.2%**,比在30个epoch下微调的 previous state-of-the-art MaxViT-Base提高了0.3%/0.5%。此外,当在384分辨率的ImageNet-A测试集上评估时,作者的TransNeXt-Small/Base模型在top-1准确率上达到了**58.3%/61.6%**,显著优于ConvNeXt-L的7.6%/10.9%,为ImageNet-1K有监督模型的鲁棒性树立了新的基准。
本文的贡献如下:
-
提出像素聚焦注意力(pixel-focused attention),这是一种与生物注视高度一致的Token mixer,可以减轻模型的潜在深度衰减。这种新颖的注意力机制基于每个像素进行操作,有效地模拟了眼球的连续移动,并高度符合生物视觉的聚焦感知模式。它具有与卷积相当的视觉先验知识。
-
提出聚合注意力(aggregated attention),这是像素聚焦注意力的增强版,进一步将两种non-QKV注意力机制聚合到像素聚焦注意力中。值得注意的是,作者在这个框架内提出了一个非常高效的方法,其附加的计算开销仅占整个模型总计算开销的0.2%-0.3%,从而实现了在单个混合层中(single mixer layer),QKV注意力、LKV注意力和QLV注意力的异常低成本统一。
-
提出长度缩放余弦注意力(length-scaled cosine attention),以增强现有注意力机制对多尺度输入的扩展能力。这使得TransNeXt能够实现比纯卷积网络更好的大规模图像扩展性能。
-
提出convolutional GLU,它利用最近邻图像特征实现通道注意力。与卷积前馈相比,它能够在更少的FLOPs下实现channel mixer的注意化,从而有效提高模型的鲁棒性。
-
提出TransNeXt,这是一种视觉Backbone网络,在各种视觉任务如图像分类、目标检测和语义分割等相似大小的模型中,实现了最先进的性能。它还表现出最先进的鲁棒性。
Related Work
视觉Transformer:视觉Transformer(ViT)是第一个将Transformer架构引入视觉任务,其中图像被分割成非重叠的Patch,然后线性投影到Token序列中,这些Token序列随后由Transformer编码器进行编码。在大型预训练数据或精心设计的训练策略下,ViT模型在图像分类和其他下游任务上超过了卷积神经网络(CNNs),表现出显著的性能。
Non-QKV注意力变体:在自注意力中,动态亲和矩阵是通过Query和Key之间的相互作用生成的。最近,一些研究探索了使用可学习Token作为原始Query或Key的替代品来生成动态亲和矩阵的方法。Involution和VOLO等方法使用可学习Token替换原始Key,从而生成仅与Query相关的动态亲和矩阵。相比之下,QnA使用可学习Token替换Query,导致动态亲和矩阵仅与Key相关。这两种方法都显示出了有效性。
仿生视觉模型:人类视觉对视觉焦点的特征具有更高的分辨率,而对远处特征的分辨率较低。这种仿生设计已经被集成到几种机器视觉模型中。具体而言,Focal-Transformer根据这个概念设计了一种视觉注意力机制,但它基于窗口划分运行。位于窗口边缘的Token无法获得自然注视聚焦,并且其窗口化的方式无法模拟人类眼球的连续移动。作者的方法有效地解决了这些问题。
Method
3.1.Aggregated Pixel-focused Attention

3.1.1 Pixel-focused Attention
受到生物视觉系统的工作原理的启发,作者设计了一种像素聚焦注意力机制,它在每个Query附近具有细粒度的感知,同时保持全局信息的粗粒度意识。为了实现眼球运动中固有的像素级平移等价性,作者采用了一种双路径设计,包括以Query为中心的滑动窗口注意力和池化注意力。此外,为了在两个注意力路径之间诱导耦合,作者对两个路径的Query-Key相似度结果使用相同的softmax进行计算。这导致了细粒度和粗粒度特征之间的竞争,将像素聚焦注意力转化为多尺度注意力机制。
作者现在关注输入特征图上单个像素的操作。作者定义输入特征图上以 为中心的滑动窗口中的像素集合为
为中心的滑动窗口中的像素集合为![]() 。对于固定的窗口大小
。对于固定的窗口大小 ,
,![]() 。同时,作者定义从特征图池化得到的像素集合为
。同时,作者定义从特征图池化得到的像素集合为![]() 。对于池化大小
。对于池化大小![]() ,
,![]() 。因此,像素聚焦注意力(PFA)可以如下描述:
。因此,像素聚焦注意力(PFA)可以如下描述:

Activate and Pool:为了在后续应用中利用PFA的线性复杂度模式进行大规模图像推理,作者采用参数免费的适应性平均池化进行空间降采样。然而,平均池化操作会严重损失信息。因此,作者在特征图池化之前,使用单层神经网络进行投影和激活,以压缩和提取有用的信息,从而在降采样后提高信息压缩率。降采样后,作者再次使用LN来规范化输出,以确保 和
和![]() 的方差一致性。作者提出的降采样操作称为“激活与池化( Activate and Pool)”,可以用以下方程表示:
的方差一致性。作者提出的降采样操作称为“激活与池化( Activate and Pool)”,可以用以下方程表示:

作者用作者的'激活与池化机制替换了PVTv2-li中的降采样模块,并设计了一个2M大小的模型用于在CIFAR-100上的ablation实验。作者的模块将PVTv2-li的top-1准确率从68.1%提高到了70.4%,证明了这种方法的有效性。
Padding mask:在滑动窗口路径中,特征图边缘的像素不可避免地与边界外的零填充计算相似度。为了防止这些零相似度影响softmax操作,作者采用填充Mask将这些结果设置为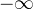 。
。
3.1.2 Aggregating Diverse Attentions in a Single Mixer
Query embedding:许多视觉语言模型利用来自文本模态的Query,对来自视觉模态的Key进行交叉注意力,从而实现跨模态信息聚合以完成视觉问答(VQA)任务。此外,已经证明在微调这些多模态模型以适应特定子任务时,合并并优化可学习的prefix Query Token是有效且高效的。
将这种想法自然地扩展到将可学习的QueryToken集成到Backbone网络的注意力机制中,以进行像图像分类、对象检测和语义分割等明确定义的任务,并直接优化它们。这种方法已经通过以前的工作的有效性得到了验证。
这种方法与传统的QKV注意力不同,因为它不使用输入中的Query,而是根据当前任务学习一个Query来执行交叉注意力。因此,作者将这种方法归类为Learnable-Key-Value(LKV)注意力,并与QKV注意力相平行。作者发现,在传统QKV注意力中为所有QueryToken添加learnable Query Embedding (QE),可以在忽略额外开销的情况下实现类似的信息聚合效果。作者只需要修改方程1如下:

Positional attention:信息聚合的另一种替代方法是使用一组可学习的Key,这些Key与来自输入的Query相互作用以获得注意力权重,即Query-Learnable-Value(QLV)注意力。这种方法与传统的QKV注意力不同,因为它破坏了Key和Value之间的一对一对应关系,导致为当前Query学习更多的隐式相对位置信息。
因此,它通常与滑动窗口相结合在视觉任务中使用。与静态的亲和矩阵如卷积或相对位置偏差不同,这种通过数据驱动建模方法生成的亲和矩阵考虑了当前Query的影响,并可以基于它动态适应。作者观察到,这种数据驱动建模方法比静态相对位置偏差更具鲁棒性,并且可以进一步增强局部建模能力。
利用这一特点,作者在每个注意力头中引入一组可学习的Token ![]() ,允许这些Token与Query相互作用以获得额外的动态位置偏差并将其添加到
,允许这些Token与Query相互作用以获得额外的动态位置偏差并将其添加到![]() 。使用这种增强只需要增加额外的计算开销
。使用这种增强只需要增加额外的计算开销![]() 。作者只需要修改方程4如下:
。作者只需要修改方程4如下:

3.1.3 Overcoming Multi-scale Image Input
Length-scaled cosine attention:与缩放点积注意力不同,长度缩放余弦注意力使用了余弦相似度,已被观察到可以生成更适中的注意力权重,并有效地增强了大型视觉模型的训练稳定性。长度缩放余弦注意力通常将一个额外的可学习系数 乘到Query和Key的余弦相似度结果上,使得注意力机制可以有效地忽略不重要的Token。
乘到Query和Key的余弦相似度结果上,使得注意力机制可以有效地忽略不重要的Token。
最近的研究发现,随着输入序列长度的增加,注意力输出的置信度会降低。因此,注意力机制的缩放因子应该与输入序列长度相关。进一步地,[52]提出了一个关于缩放点积注意力熵不变性的设计,以方便更好的泛化到未知长度。在[52]中,提供了当Query和Key被近似为具有 大小的向量时,序列长度为
大小的向量时,序列长度为 的缩放点积注意力熵的估计:
的缩放点积注意力熵的估计:

对于余弦相似度,作者定义Query和Key在其head dimensions上进行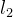 正则化后的向量分别为
正则化后的向量分别为![]() 和
和![]() ,它们的模长均为1。为了保持熵不变性并忽略常数项,作者设置
,它们的模长均为1。为了保持熵不变性并忽略常数项,作者设置![]() 。由于方程8仅是一个估计,作者设置
。由于方程8仅是一个估计,作者设置![]() ,其中
,其中 是每个注意力头初始化为
是每个注意力头初始化为![]() 的可学习变量。作者提出长度缩放余弦注意力如下:
的可学习变量。作者提出长度缩放余弦注意力如下:

在这里, 表示每个Query与有效Key交互的次数,不包括被 Mask Token的计数。具体来说,在Transformer decoder中应用时,由causal mask 所 Mask 的未来Token不应计入。在像素聚焦注意力的背景下,的计算方式为
表示每个Query与有效Key交互的次数,不包括被 Mask Token的计数。具体来说,在Transformer decoder中应用时,由causal mask 所 Mask 的未来Token不应计入。在像素聚焦注意力的背景下,的计算方式为![]() ,其中
,其中![]() 表示位置处的padding-masked tokens集合。
表示位置处的padding-masked tokens集合。
Position bias:为了进一步增强像素聚焦注意力的多尺度图像输入的扩展能力,作者采用不同的方法计算两个路径上的![]() 和
和![]() 。
。
1、在池化特征路径上,作者使用对数间隔连续位置偏差(log-CPB),它是一个2层MLP,其中激活使用ReLU,从![]() 和
和![]() 之间的空间相对坐标
之间的空间相对坐标![]() 计算
计算![]() 。
。
2、在滑动窗口路径上,作者直接使用可学习的![]() 。一方面,这是因为滑动窗口的大小是固定的,不需要通过log-CPB对未知的相对位置偏差进行扩展,从而节省计算资源。另一方面,作者观察到使用log-CPB计算
。一方面,这是因为滑动窗口的大小是固定的,不需要通过log-CPB对未知的相对位置偏差进行扩展,从而节省计算资源。另一方面,作者观察到使用log-CPB计算![]() 会导致性能下降。作者认为这是因为
会导致性能下降。作者认为这是因为![]() 表示细粒度Token和粗粒度Token之间的空间相对坐标,而
表示细粒度Token和粗粒度Token之间的空间相对坐标,而![]() 表示细粒度Token之间的空间相对坐标,它们的数值含义不同。作者在附录中进一步讨论这些细节。
表示细粒度Token之间的空间相对坐标,它们的数值含义不同。作者在附录中进一步讨论这些细节。
为了增强像素聚焦注意力的多尺度输入的扩展能力,作者提出了一种增强版像素聚焦注意力,称为聚合像素聚焦注意力,作者简称为聚合注意力(AA)。它可以描述如下:

3.1.4 Feature Analysis
Computational complexity:给定输入![]() ,池化大小
,池化大小![]() ,窗口大小,作者考虑‘激活与池化’操作和线性投影的影响。像素聚焦注意力和聚合注意力的计算复杂度如下:
,窗口大小,作者考虑‘激活与池化’操作和线性投影的影响。像素聚焦注意力和聚合注意力的计算复杂度如下:

作者观察到,当池化大小![]() 设置为与输入大小无关的值时,
设置为与输入大小无关的值时,![]() 和
和![]() 的长度都线性地与输入序列的长度成正比。这意味着PFA和AA都可以在线性复杂度模式下进行推理。
的长度都线性地与输入序列的长度成正比。这意味着PFA和AA都可以在线性复杂度模式下进行推理。
Optimal accuracy-efficiency trade-off:通过实证研究,作者观察到滑动窗口的大小对模型性能的影响可以忽略不计。因此,作者采用了最小形式的3*3滑动窗口来捕获靠近视觉焦点的特征,这显著降低了计算和内存消耗。作者认为这是由于池化特征路径的存在,每个Query都具有全局感受野,从而大大减少了扩展滑动窗口大小以扩大感受野的需要。详细的消融研究结果和讨论可以在附录中找到。
代码:
def get_seqlen_and_mask(input_resolution, window_size):
attn_map = F.unfold(torch.ones([1, 1, input_resolution[0], input_resolution[1]]), window_size,
dilation=1, padding=(window_size // 2, window_size // 2), stride=1) # [1,9,3136] / [1,9,784] / [1,9,196] / [1,9,49]
attn_local_length = attn_map.sum(-2).squeeze().unsqueeze(-1) # [3136,1] / [784,1] / [196,1] / [49,1]
attn_mask = (attn_map.squeeze(0).permute(1, 0)) == 0 # [3136,9] / [784,9] / [196,9] / [49,9]
return attn_local_length, attn_mask
class AggregatedAttention(nn.Module):
def __init__(self, dim, input_resolution, num_heads=8, window_size=3, qkv_bias=True,
attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.sr_ratio = sr_ratio
assert window_size % 2 == 1, "window size must be odd"
self.window_size = window_size
self.local_len = window_size ** 2
self.pool_H, self.pool_W = input_resolution[0] // self.sr_ratio, input_resolution[1] // self.sr_ratio
self.pool_len = self.pool_H * self.pool_W
self.unfold = nn.Unfold(kernel_size=window_size, padding=window_size // 2, stride=1)
self.temperature = nn.Parameter(torch.log((torch.ones(num_heads, 1, 1) / 0.24).exp() - 1)) #Initialize softplus(temperature) to 1/0.24.
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.query_embedding = nn.Parameter(
nn.init.trunc_normal_(torch.empty(self.num_heads, 1, self.head_dim), mean=0, std=0.02)) # [3,1,24]
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
#Components to generate pooled features.
self.pool = nn.AdaptiveAvgPool2d((self.pool_H, self.pool_W))
self.sr = nn.Conv2d(dim, dim, kernel_size=1, stride=1, padding=0)
self.norm = nn.LayerNorm(dim)
self.act = nn.GELU()
# mlp to generate continuous relative position bias
self.cpb_fc1 = nn.Linear(2, 512, bias=True)
self.cpb_act = nn.ReLU(inplace=True)
self.cpb_fc2 = nn.Linear(512, num_heads, bias=True)
# relative bias for local features
self.relative_pos_bias_local = nn.Parameter(
nn.init.trunc_normal_(torch.empty(num_heads, self.local_len), mean=0,
std=0.0004))
# Generate padding_mask && sequnce length scale
local_seq_length, padding_mask = get_seqlen_and_mask(input_resolution, window_size)
self.register_buffer("seq_length_scale", torch.as_tensor(np.log(local_seq_length.numpy() + self.pool_len)),
persistent=False)
self.register_buffer("padding_mask", padding_mask, persistent=False)
# dynamic_local_bias:
self.learnable_tokens = nn.Parameter(
nn.init.trunc_normal_(torch.empty(num_heads, self.head_dim, self.local_len), mean=0, std=0.02)) # [3,24,9] / [6,24,9] / [12,24,9]
self.learnable_bias = nn.Parameter(torch.zeros(num_heads, 1, self.local_len))
def forward(self, x, H, W, relative_pos_index, relative_coords_table):
B, N, C = x.shape # [B,3136,72] / [B,784,144] / [B,196,288]
#Generate queries, normalize them with L2, add query embedding, and then magnify with sequence length scale and temperature.
#Use softplus function ensuring that the temperature is not lower than 0.
q_norm=F.normalize(self.q(x).reshape(B, N, self.num_heads, self.head_dim).permute(0, 2, 1, 3),dim=-1)
# self.q->Linear(C,C)
# 1 [B,3136,72]->[B,3,3136,24]
# 2 [B,784,144]->[B,6,784,24]
# 3 [B,196,288]->[B,12,196,24]
q_norm_scaled = (q_norm + self.query_embedding) * F.softplus(self.temperature) * self.seq_length_scale # [B,3,3136,24] / [B,6,784,24] / [B,12,196,24]
# Generate unfolded keys and values and l2-normalize them
k_local, v_local = self.kv(x).chunk(2, dim=-1) # [B,3136,72] [B,3136,72] / [B,784,144] [B,784,144] / [B,196,288] [B,196,288]
k_local = F.normalize(k_local.reshape(B, N, self.num_heads, self.head_dim), dim=-1).reshape(B, N, -1) # [B,3136,72] / [B,784,144] / [B,196,288]
kv_local = torch.cat([k_local, v_local], dim=-1).permute(0, 2, 1).reshape(B, -1, H, W) # [B,144,56,56] / [B,288,28,28] / [B,576,14,14]
k_local, v_local = self.unfold(kv_local).reshape(
B, 2 * self.num_heads, self.head_dim, self.local_len, N).permute(0, 1, 4, 2, 3).chunk(2, dim=1) #[B,3,3136,24,9] [B,3,3136,24,9] / [B,6,784,24,9] [B,6,784,24,9] / [B,12,196,24,9] [B,12,196,24,9]
# Compute local similarity
attn_local = ((q_norm_scaled.unsqueeze(-2) @ k_local).squeeze(-2) \
+ self.relative_pos_bias_local.unsqueeze(1)).masked_fill(self.padding_mask, float('-inf')) # [B,3,3136,9] / [B,6,784,9] / [B,12,196,9]
# Generate pooled features
x_ = x.permute(0, 2, 1).reshape(B, -1, H, W).contiguous() # [B,72,56,56] / [B,144,28,28] / [B,288,14,14]
x_ = self.pool(self.act(self.sr(x_))).reshape(B, -1, self.pool_len).permute(0, 2, 1)
# 1 self.sr->Conv2d(72, 72, kernel_size=(1, 1), stride=(1, 1)) [B,72,56,56]->[B,49,72]
# 2 self.sr->Conv2d(144, 144, kernel_size=(1, 1), stride=(1, 1)) [B,144,28,28]->[B,49,144]
# 3 self.sr->Conv2d(288, 288, kernel_size=(1, 1), stride=(1, 1)) [B,288,14,14]->[B,49,288]
x_ = self.norm(x_)
# Generate pooled keys and values
kv_pool = self.kv(x_).reshape(B, self.pool_len, 2 * self.num_heads, self.head_dim).permute(0, 2, 1, 3) # [B,49,72]->[B,6,49,24] / [B,49,144]->[B,12,49,24] / [B,49,288]->[B,24,49,24]
k_pool, v_pool = kv_pool.chunk(2, dim=1) # [B,3,49,24] [B,3,49,24] / [B,6,49,24] [B,6,49,24] / [B,12,49,24] [B,12,49,24]
#Use MLP to generate continuous relative positional bias for pooled features.
# cpb_fc1->Linear(in_features=2, out_features=512, bias=True) cpb_fc2->Linear(in_features=512, out_features=3/6/12, bias=True)
pool_bias = self.cpb_fc2(self.cpb_act(self.cpb_fc1(relative_coords_table))).transpose(0, 1)[:,
relative_pos_index.view(-1)].view(-1, N, self.pool_len) # [10816,2]->[3,3136,49] / [2704,2]->[6,784,49] / [676,2]->[12,196,49]
# Compute pooled similarity
attn_pool = q_norm_scaled @ F.normalize(k_pool, dim=-1).transpose(-2, -1) + pool_bias # [B,3,3136,49] / [B,6,784,49] /[B,12,196,49]
# Concatenate local & pooled similarity matrices and calculate attention weights through the same Softmax
attn = torch.cat([attn_local, attn_pool], dim=-1).softmax(dim=-1) # [B,3,3136,58] / [B,6,784,58] / [B,12,196,58]
attn = self.attn_drop(attn)
#Split the attention weights and separately aggregate the values of local & pooled features
attn_local, attn_pool = torch.split(attn, [self.local_len, self.pool_len], dim=-1) # [B,3,3136,9] [B,3,3136,49] / [B,6,784,9] [B,6,784,49] / [B,12,196,9] [B,12,196,49]
x_local = (((q_norm @ self.learnable_tokens) + self.learnable_bias + attn_local).unsqueeze(-2) @ v_local.transpose(-2, -1)).squeeze(-2) # [B,3,3136,24] / [B,6,784,24] / [B,12,196,24]
x_pool = attn_pool @ v_pool # [B,3,3136,24] / [B,6,784,24] / [B,12,196,24]
x = (x_local + x_pool).transpose(1, 2).reshape(B, N, C) # [B,3136,72] / [B,784,144] / [B,196,288]
#Linear projection and output
x = self.proj(x)
# 1 Linear(in_features=72, out_features=72, bias=True)
# 2 Linear(in_features=144, out_features=144, bias=True)
# 3 Linear(in_features=288, out_features=288, bias=True)
x = self.proj_drop(x)
return x3.2. Convolutional GLU

3.2.1 Motivation
Gated channel attention in ViT era:以前的工作,由Squeeze-and-Excitation(SE)机制代表,首先将通道注意力引入计算机视觉领域,该机制使用一个带有激活函数的分枝来控制网络输出。在门控通道注意力(gated channel attention)中,门控分支(gating branch)具有比值分支更大的决策权,最终决定相应的输出元素是否为零。从这个角度来看,SE机制巧妙地使用全局平均池化后的特征作为门控分支的输入,实现更好的决策,同时解决了CNN结构中感受野不足的问题。然而,在ViT时代,全局感受野不再是稀缺的。
各种全局Token mixer由自注意力表示,已经比全局平均池化实现了更高的全局信息聚合质量。这使得SE机制使用的全局池化方法表现出一些缺陷,例如该方法使特征图上的所有Token共享相同的门控信号,导致其通道注意力缺乏灵活性并过于粗糙。尽管如此,值得注意的是ViT结构缺乏通道注意力。最近的研究发现,将SE机制集成到通道混合器中可以有效提高模型鲁棒性,如图4所示。
Convolution in ViT era:最近的研究表明,将3*3的零填充卷积引入到视觉Transformer中可以被视为一种条件位置编码(CPE),它有效地捕获了零填充带来的位置信息。
3.2.2 Rethinking Channel Mixer Design
GLU是一种通道混合器,已在各种自然语言处理任务中显示出比多层感知机(MLP)更好的性能。GLU由两个按元素乘法的线性投影组成,其中一个投影由门控功能激活。与SE机制不同,每个Token的gating信号都来自Token本身,并且其感受野大小不超过值分支的感受野。
More elegant design:作者发现,在GLU的gating分支的激活函数之前,简单地添加一个最小形式的3*3深度卷积,可以使它的结构符合基于最近邻特征的门控通道注意力(gated channel attention)的设计概念,并将其转换为门控通道注意力机制。作者称这种方法为Convolutional GLU,如图4所示。
Feature analysis:在Convolutional GLU(ConvGLU)中的每个Token都具有基于其最近精细特征的独特gating信号,这解决了全局平均池化在SE机制中的过于粗糙的问题。它也满足了某些没有位置编码设计的ViT模型,这些模型需要由深度卷积提供的位置信息。此外,这种设计的value分支仍保持与MLP和GLU相同的深度,使其易于反向传播。当保持与卷积前馈(ConvFFN)的参数体量一致,扩展比例为 ,卷积核大小为时,Convolutional GLU的计算复杂度为
,卷积核大小为时,Convolutional GLU的计算复杂度为![]() ,小于卷积前馈的
,小于卷积前馈的![]() 。这些属性使得Convolutional GLU成为一个简单而更强大的混合器,满足ViTs的多样化需求。
。这些属性使得Convolutional GLU成为一个简单而更强大的混合器,满足ViTs的多样化需求。
代码:
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W).contiguous()
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2)
return x
class ConvolutionalGLU(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
hidden_features = int(2 * hidden_features / 3)
self.fc1 = nn.Linear(in_features, hidden_features * 2)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x, H, W):
x, v = self.fc1(x).chunk(2, dim=-1)
x = self.act(self.dwconv(x, H, W)) * v
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x3.3. Architecture Design of TransNeXt

为了保证后续的消融实验4.2的一致性,TransNeXt采用与PVTv2相同的四阶段分层Backbone网络和重叠块嵌入。聚合注意力在1-3阶段的池化特征大小也设置为![]() ,与PVTv2相同。在阶段4中,由于特征图大小已减少到
,与PVTv2相同。在阶段4中,由于特征图大小已减少到![]() ,特征池化模块无法正常工作。作者采用了一种修改后的多头自注意力(MHSA)版本,它应用Query嵌入和长度缩放余弦注意力。这与PVTv2在第四阶段使用MHSA一致。对于1-4阶段的通道混合器,作者使用Convolutional GLU与GELU[22]激活。扩展比也遵循PVTv2的[8,8,4,4]设置。为了确保与典型MLP参数的一致性,卷积GLU的隐藏维数为
,特征池化模块无法正常工作。作者采用了一种修改后的多头自注意力(MHSA)版本,它应用Query嵌入和长度缩放余弦注意力。这与PVTv2在第四阶段使用MHSA一致。对于1-4阶段的通道混合器,作者使用Convolutional GLU与GELU[22]激活。扩展比也遵循PVTv2的[8,8,4,4]设置。为了确保与典型MLP参数的一致性,卷积GLU的隐藏维数为![]() 的集合值。此外,作者将头维数设置为24,以在通道维度上被3整除。TransNeXt变体的具体配置可以在附录中找到。
的集合值。此外,作者将头维数设置为24,以在通道维度上被3整除。TransNeXt变体的具体配置可以在附录中找到。
代码:
def get_relative_position_cpb(query_size, key_size, pretrain_size=None):
# pretrain_size (56, 56) query_size (56, 56) key_size (7, 7)
# pretrain_size (28, 28) query_size (28, 28) key_size (7, 7)
# pretrain_size (14, 14) query_size (14, 14) key_size (7, 7)
# pretrain_size (7, 7) query_size (7, 7) key_size (7, 7)
"""
关键函数:
F.adaptive_avg_pool1d 的作用是将输入进行自适应平均池化,将输入划分为key_size[0]个区域,然后在每个区域内计算平均值作为输出结果
torch.meshgrid 将输入的一维张量转换为多维坐标网格,生成的张量中每个元素都是输入的复制
torch.unique 输入张量中找到唯一的元素,在本例中relative_coords_table(从小到大排序)是输入张量在dim=0上唯一的元素,
idx_map则是relative_coords_table中的元素在relative_hw中的索引
"""
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pretrain_size = pretrain_size or query_size
axis_qh = torch.arange(query_size[0], dtype=torch.float32, device=device)
axis_kh = F.adaptive_avg_pool1d(axis_qh.unsqueeze(0).unsqueeze(0), key_size[0]).squeeze(0).squeeze(0)
# query_size[0]=56 -> tensor([ 3.5000, 11.5000, 19.5000, 27.5000, 35.5000, 43.5000, 51.5000],device='cuda:0')
# query_size[0]=28 -> tensor([ 1.5000, 5.5000, 9.5000, 13.5000, 17.5000, 21.5000, 25.5000], device='cuda:0')
# query_size[0]=14 -> tensor([ 0.5000, 2.5000, 4.5000, 6.5000, 8.5000, 10.5000, 12.5000],device='cuda:0')
# query_size[0]=7 -> tensor([0., 1., 2., 3., 4., 5., 6.], device='cuda:0')
axis_qw = torch.arange(query_size[1], dtype=torch.float32, device=device)
axis_kw = F.adaptive_avg_pool1d(axis_qw.unsqueeze(0).unsqueeze(0), key_size[1]).squeeze(0).squeeze(0)
# query_size[0]=56 -> tensor([ 3.5000, 11.5000, 19.5000, 27.5000, 35.5000, 43.5000, 51.5000],device='cuda:0')
# query_size[0]=28 -> tensor([ 1.5000, 5.5000, 9.5000, 13.5000, 17.5000, 21.5000, 25.5000], device='cuda:0')
# query_size[0]=14 -> tensor([ 0.5000, 2.5000, 4.5000, 6.5000, 8.5000, 10.5000, 12.5000],device='cuda:0')
# query_size[0]=7 -> tensor([0., 1., 2., 3., 4., 5., 6.], device='cuda:0')
axis_kh, axis_kw = torch.meshgrid(axis_kh, axis_kw) # [7,7] [7,7] / [7,7] [7,7] / [7,7] [7,7] / [7,7] [7,7]
axis_qh, axis_qw = torch.meshgrid(axis_qh, axis_qw) # [56,56] [56,56] / [28,28] [28,28] / [14,14 [14,14] / [7,7] [7,7]
axis_kh = torch.reshape(axis_kh, [-1]) # [49] / [49] / [49] / [49]
axis_kw = torch.reshape(axis_kw, [-1]) # [49] / [49] / [49] / [49]
axis_qh = torch.reshape(axis_qh, [-1]) # [3136] / [784] / [196] / [49]
axis_qw = torch.reshape(axis_qw, [-1]) # [3136] / [784] / [196] / [49]
relative_h = (axis_qh[:, None] - axis_kh[None, :]) / (pretrain_size[0] - 1) * 8 # [3136,49] / [784,49] / [196,49] / [49,49]
relative_w = (axis_qw[:, None] - axis_kw[None, :]) / (pretrain_size[1] - 1) * 8 # [3136,49] / [784,49] / [196,49] / [49,49]
relative_hw = torch.stack([relative_h, relative_w], dim=-1).view(-1, 2) # [153664,2] / [38416,2] / [9604,2] / [2401,2]
relative_coords_table, idx_map = torch.unique(relative_hw, return_inverse=True, dim=0) # [10816,2] [153664] / [2704,2] [38416] / [676,2] [9604] / [169,2] [2401]
relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
torch.abs(relative_coords_table) + 1.0) / torch.log2(torch.tensor(8, dtype=torch.float32)) #[10816,2] / [2704,2] / [676,2] / [169,2]
return idx_map, relative_coords_table
class TransNeXt(nn.Module):
'''
The parameter "img size" is primarily utilized for generating relative spatial coordinates,
which are used to compute continuous relative positional biases. As this TransNeXt implementation does not support multi-scale inputs,
it is recommended to set the "img size" parameter to a value that is exactly the same as the resolution of the inference images.
It is not advisable to set the "img size" parameter to a value exceeding 800x800.
The "pretrain size" refers to the "img size" used during the initial pre-training phase,
which is used to scale the relative spatial coordinates for better extrapolation by the MLP.
For models trained on ImageNet-1K at a resolution of 224x224,
as well as downstream task models fine-tuned based on these pre-trained weights,
the "pretrain size" parameter should be set to 224x224.
'''
def __init__(self, img_size=224, pretrain_size=None, window_size=[3, 3, 3, None],
patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4):
super().__init__()
self.num_classes = num_classes
self.depths = depths # [5,5,22,5]
self.num_stages = num_stages # 4
pretrain_size = pretrain_size or img_size # 224
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
#Generate relative positional coordinate table and index for each stage to compute continuous relative positional bias.
relative_pos_index, relative_coords_table = get_relative_position_cpb(query_size=to_2tuple(img_size // (2 ** (i + 2))),
key_size=to_2tuple(img_size // (2 ** (num_stages + 1))),
pretrain_size=to_2tuple(pretrain_size // (2 ** (i + 2))))
# [153664] [10816,2] / [38416] [2704,2] / [9604] [676,2] / [2401] [169,2]
self.register_buffer(f"relative_pos_index{i+1}", relative_pos_index, persistent=False)
self.register_buffer(f"relative_coords_table{i+1}", relative_coords_table, persistent=False)
patch_embed = OverlapPatchEmbed(patch_size=patch_size * 2 - 1 if i == 0 else 3,
stride=patch_size if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
block = nn.ModuleList([Block(
dim=embed_dims[i], input_resolution=to_2tuple(img_size // (2 ** (i + 2))), window_size=window_size[i],
num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + j], norm_layer=norm_layer,
sr_ratio=sr_ratios[i])
for j in range(depths[i])])
norm = norm_layer(embed_dims[i])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"block{i + 1}", block)
setattr(self, f"norm{i + 1}", norm)
# classification head
self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
for n, m in self.named_modules():
self._init_weights(m, n)
def _init_weights(self, m: nn.Module, name: str = ''):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, (nn.LayerNorm, nn.GroupNorm, nn.BatchNorm2d)):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
@torch.jit.ignore
def no_weight_decay(self):
return {}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'query_embedding', 'relative_pos_bias_local', 'cpb', 'temperature'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x)
relative_pos_index = getattr(self, f"relative_pos_index{i + 1}")
relative_coords_table = getattr(self, f"relative_coords_table{i + 1}")
for blk in block:
x = blk(x, H, W, relative_pos_index, relative_coords_table)
x = norm(x)
if i != self.num_stages - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() # [N,72,56,56]
return x.mean(dim=1)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return xExperiment
ImageNet-1K classification:作者的代码基于PVTv2实现,并遵循DeiT的训练方法。模型从 scratch 在ImageNet-1K数据集上进行300个epoch的训练,利用自动混合精度(AMP)在8个GPU上进行训练。训练过程中使用的具体超参数可以在附录中找到。
为了全面评估模型的鲁棒性,作者使用了几个额外的测试集。这些包括ImageNet-C,这是一个大小为224的测试集,它对ImageNet-1K验证集进行了算法扭曲;ImageNet-A,这是一个包含对抗样本的测试集;ImageNet-R,这是一个包含ResNet-50无法正确分类的样本的扩展测试集;ImageNet-Sketch,其中包含手绘图像;以及ImageNet-V2,这是一个采用与ImageNet-1K相同的采样策略的扩展测试集。
Experimental results:实验结果如表1所示,表明作者提出的模型在ImageNet-1K的准确性和鲁棒性方面均树立了新的基准。具体而言,作者的TransNeXt-Micro模型在ImageNet-1K上获得了**82.5%的Top-1准确率,比FocalNet-T(LRF)多使用了55%的参数。同样,作者的TransNeXt-Tiny模型在ImageNet-1K上获得了84.0%**的Top-1准确率,比ConvNeXt-B提高了69%的参数。
值得注意的是,在384的分辨率下,作者的TransNeXt-Small/Base模型仅用5个epoch的微调就超过了更大的MaxViT-Base模型,分别提高了0.3%/0.5%。在鲁棒性方面,作者的模型在五个附加测试集上表现出优越的性能。值得注意的是,在最具挑战性的ImageNet-A测试集上,TransNeXt在模型扩展时表现出显著的优势。在224的分辨率下,作者的TransNeXt-Base比MaxViT-Base提高了6.4%。在384的分辨率下,作者的TransNeXt-Small/Base在ImageNet-A上的准确率达到了**58.3%/61.6%**,比ConvNeXt-L提高了7.6%/10.9%,同时它们的参数数量分别只有ConvNeXt-L的25%和45%。

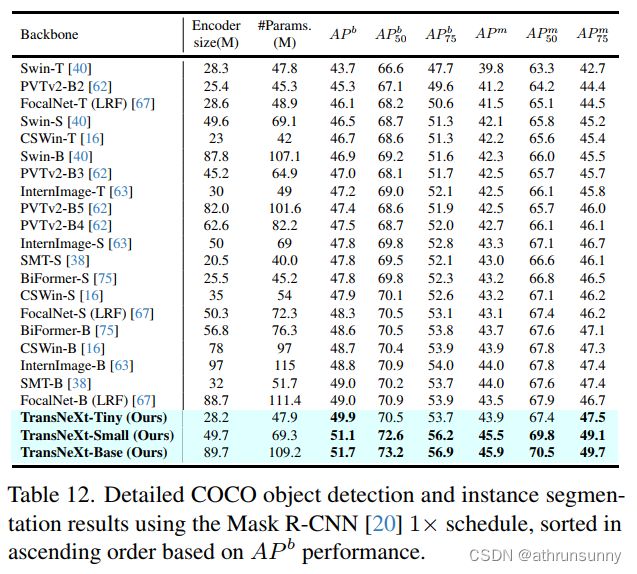
Object detection and instance segmentation:作者使用了一个Mask R-CNN检测头,在![]() 的调度下进行训练,来评估在COCO数据集上的ImageNet-1K预训练TransNeXt在目标检测和实例分割方面的性能。实验结果如图1所示。与先前的最先进模型相比,作者的模型在各方面都具有全面的优越性。值得注意的是,即使作者的微型模型在
的调度下进行训练,来评估在COCO数据集上的ImageNet-1K预训练TransNeXt在目标检测和实例分割方面的性能。实验结果如图1所示。与先前的最先进模型相比,作者的模型在各方面都具有全面的优越性。值得注意的是,即使作者的微型模型在![]() 方面也超过了FocalNet,InterImage和CSWin的基础模型。
方面也超过了FocalNet,InterImage和CSWin的基础模型。
同样,作者利用一个DINO检测头,在![]() 的调度下进行训练,进一步评估作者的模型在目标检测方面的潜力。作者的TransNeXt-Tiny模型在4尺度设置下
的调度下进行训练,进一步评估作者的模型在目标检测方面的潜力。作者的TransNeXt-Tiny模型在4尺度设置下![]() 达到了 55.1,超过了ConvNeXt-L( 53.4在4尺度设置下) 1.7,而后者只有后者的14%的Backbone参数。作者的TransNeXt-Base模型在5尺度设置下
达到了 55.1,超过了ConvNeXt-L( 53.4在4尺度设置下) 1.7,而后者只有后者的14%的Backbone参数。作者的TransNeXt-Base模型在5尺度设置下![]() 达到了 57.1,接近在ImageNet-22K上预训练的Swin-L(
达到了 57.1,接近在ImageNet-22K上预训练的Swin-L( ![]() 57.2在5尺度设置下)的性能。
57.2在5尺度设置下)的性能。

Semantic segmentation:作者使用UperNet和Mask2Former方法在512分辨率下训练ImageNet-1K预训练的TransNeXt,进行了160k次迭代,并在ADE20K上评估其语义分割性能。在UperNet方法中,如图1所示,作者的TransNeXt在各方面都表现出全面的优越性。
在所有大小上都超过了以前的方法。作者的TransNeXtBase甚至超过了ConvNeXt-B(mIoU 52.6),它是在ImageNet-22K上预训练的,并在640的分辨率下进一步训练。同样,在Mask2Former方法下,作者的TransNeXtSmall实现了54.1的mIoU,超过了在ImageNet-22K上预训练并在640的分辨率下进一步训练的Swin-B(mIoU 53.9)。此外,作者的TransNeXtBase实现了54.7的mIoU。这些结果表明,作者的方法有潜力超越模型大小的限制,突破数据量障碍。
作者的模型在密集预测任务中相比分类任务表现出更显著的性能优势。作者认为这验证了聚合注意力的生物视觉设计的有效性,这种设计可以在比以前方法更早的阶段实现更自然的光学感知,如图2所示。


4.1. Multi-scale Inference
在推理过程中,TransNeXt在正常模式下将![]() 和
和![]() 设置为输入大小的
设置为输入大小的![]() ,而在线性模式下,它们固定为
,而在线性模式下,它们固定为![]() 。如图6(左)所示,TransNeXt在正常和线性模式下都超过了纯卷积解决方案。大卷积核方案,也被提出来解决深度衰减问题,在大图像推理时表现出显著的性能下降。这揭示了作者的方法在解决大核方案这个问题上的优势。例如,RepLKNet-31B在640分辨率下仅达到0.9%的准确率。在传统观点中,纯卷积模型在多尺度适用性方面优于ViT模型,这些实验结果暗示着这种观点需要重新审视。大核方案的性能下降也值得研究界进一步调查。
。如图6(左)所示,TransNeXt在正常和线性模式下都超过了纯卷积解决方案。大卷积核方案,也被提出来解决深度衰减问题,在大图像推理时表现出显著的性能下降。这揭示了作者的方法在解决大核方案这个问题上的优势。例如,RepLKNet-31B在640分辨率下仅达到0.9%的准确率。在传统观点中,纯卷积模型在多尺度适用性方面优于ViT模型,这些实验结果暗示着这种观点需要重新审视。大核方案的性能下降也值得研究界进一步调查。

图6(右)说明了长度缩放余弦和插值对性能的影响。长度缩放余弦在640的分辨率处变得显著,表明超过8倍的序列长度变化开始显著降低缩放余弦注意力的信心。使用插值对相对位置偏差进行应用导致性能显著下降,这强调了在多尺度推理中使用extrapolative positional encoding(log-CPB)的有效性。
4.2. A roadmap from PVT to TransNeXt
Effectiveness of our method:作者的提出的Convolutional GLU(ConvGLU)、像素聚焦注意力(PFA)、位置注意力(PA)和Query embedding(QE)的有效性通过从步骤4到8的消融实验进行验证。在步骤4到5、6和7到8中,作者分别用ConvGLU代替卷积前馈(ConvFFN),用像素聚焦注意力(PFA)代替空间降采样的注意力(SRA),用聚合注意力(Aggregated Attention)代替像素聚焦注意力(PFA)。这三种替换分别导致了ImageNet-1K上的准确率提高0.8%、0.9%和0.7%,以及在ImageNet-A测试集上的准确率提高4.3%、3.4%和3.0%,表明这三个组成部分对性能的贡献显著。
值得注意的是,在像素聚焦注意力中引入QLV和LKV机制只需要增加0.2%的参数(从12.78M到12.81M),以及0.3%的计算开销(从2.65G到2.66G),但性能提高显著,从而实现了成本效益的权衡。
此外,在步骤4中,用GLU代替ConvFFN导致了显著的性能下降,强调了使用3*3的零填充卷积作为条件位置编码(CPE)的重要性,特别是因为PVTv2的SRA在这个阶段没有使用任何其他位置编码。因此,步骤5也证明了使用ConvGLU作为位置编码的有效性。
Conclusion
在这项工作中,作者提出了一种基于生物模仿视杆细胞视觉设计的Token混合器聚合注意力和一种具有门控通道注意力的通道混合器卷积GLU。作者将它们结合起来,提出一种强大的高度鲁棒的视觉模型TransNeXt,它在各种视觉任务如分类、检测和分割等方面都实现了最先进的性能。TransNeXt在多尺度推理的出色性能突显了它在解决深度衰减问题方面优于大型核策略的优势。此外,作者还提供了一个CUDA实现,在训练中实现了高达103.4%的加速,在推理中实现了60.5%的加速。更多详细的实验数据和讨论包括在附录中。
最后就是附录的内容,这里作者做了一些消融实验验证该算法的有效性,感兴趣的可以看一下原文。