CNN架构的演变:EfficientNet 简介

概述
在各种卷积神经网络中,EfficientNet 是其中最重要的一种。与所有前辈相比,它提供了更好的性能。EfficientNet 是复合缩放和神经架构搜索 (NAS) 的产物。在本文中,我们将深入探讨 EfficientNet 的细节。
什么是DenseNet?
DenseNet 是一种使用卷积层的深度学习架构。它是其前身 ResNet(Residual Network)的改进版本。残差网络通过将上一层的输出连接到下一层,改进了传统的 Convnet 架构。这种架构解决了层数增加时梯度消失/爆炸的问题。DenseNet 的训练参数比 CNN 或 ResNet 少。CNN有许多可以丢弃的冗余层。DenseNet架构克服了前几层被重用,每一层只添加一个小的特征图。

DenseNet 通过将所有前一层输出连接到下一层来改进 ResNet。,例如,第 4 层的输入将包含来自第 1、2 和 3 层的输出。这使更深层能够携带初始层的信息,并有助于提高性能。
为什么使用DenseNet?
与 ResNet 相比,DenseNet 有一些优势。除了解决梯度消失/爆炸问题外,DenseNet 还提高了性能。这是因为 DenseNet 具有强大的梯度流,这意味着训练阶段的纠错可以更好地实现。即使是初始层,在传递到最后一层时也会直接进行纠错。这带来了“直接监督”。 与 ConvNet 和 ResNet 相比,DenseNet 具有更好的参数和计算效率。它还在较高层中维护低级功能。例如,初始图层的低级要素的特征图也用于识别最后层中的较高层次要素。
EfficientNet 简介
EfficientNet 是一种神经网络架构,它使用复合缩放来实现更好的性能。EfficientNet 旨在通过减少参数和 FLOP(每秒浮点运算)的数量来提高性能,同时提高计算效率。
通常,在 CNN 架构中,扩展过程(增加层数)是一项艰巨的工作,因为有许多方法可以扩展。如果手动完成,选择最佳组合非常耗时。在EfficientNet中,还可以使用Compound Scaling和NAS(神经架构搜索)来处理扩展过程,本文稍后将对此进行解释。
高效网络由两部分组成:
- 使用 NAS 创建高效的基准体系结构
- 在纵向扩展时使用复合缩放方法以提高性能
EfficientNet 架构

基线架构非常重要,因为纵向扩展过程可以增强基线模型性能。因此,基线模型越好,缩放后的最终性能就越好。一般的复合扩展方法可以应用于 ResNet 等其他架构,因此基线架构性能非常重要。
上述架构是使用NAS(神经网络架构)形成的。NAS是寻找最有效的神经网络架构的操作,该架构具有最小的损失和最高的计算效率。此体系结构使用移动倒置瓶颈卷积 (MBConv),类似于 MobileNetV2 体系结构中的体系结构。然后,通过复合扩展来扩展此基线架构,以获得一系列 EfficientNet 模型。
复合缩放


有三种方法可以纵向扩展:
- 宽度缩放
- 深度缩放
- 分辨率缩放
使用这三种方法中的任何一种进行纵向扩展都会获得更好的性能,但性能的提高会饱和,并且在一段时间后不会改善。例如,100 层网络和 500 层网络的性能类似。

可以看出,当组合使用这些方法时,比仅使用一种方法会产生更好的结果。例如,从下图中我们可以看到,当分辨率和宽度都增加而不是单独增加它们时,会产生最佳结果。

这可以更直观地理解。当宽度增加时,像素数会增加。因此,现在,相同数量的卷积层将无法捕获与宽度较小时相同数量的特征。因此,还应增加深度以适应增加的宽度以捕获特征。
这种使用所有三个参数进行纵向扩展的方法是复合缩放。这是通过保持参数值平衡来实现的。因此,一个参数不会使另一个参数黯然失色,因为它会降低性能。我们使用下面的等式来保持平衡。
深度:d = ![]()
宽度:w = ![]()
分辨率:r = ![]()
这样,
![]()
α≥1 , β≥1 , γ≥1
我们可以看到,这些值以 alpha、Beta 和 Gamma 表示,并提高到一定的幂。他们的乘积等同于零。目标是保持常数以保持缩放平衡。我们注意到宽度和分辨率提高到 2 的幂。这与变量对 FLOPS 的影响相对应。深度加倍会使 FLOPS 值加倍,而宽度和分辨率加倍会使 FLOPS 分别乘以 4 倍。因此,这两个参数被提高到 2 的幂。 这种复合缩放方法是一种通用技术,可以应用于我们的 EfficientNet-B0 架构,以获得 EfficientNet 系列模型。
使用 NAS 的 EfficientNet 架构
神经架构搜索 (NAS) 正在寻找更高效、更优化的架构,并考虑几个参数,并具有更好的性能。它在搜索空间中搜索和评估许多架构,以找到给定任务的最佳模型。

这种 NAS 技术是 EfficientNet 架构的核心。NAS用于找到最强大的架构,同时检查参数数量,从而提供非常高效和优化的模型。
EfficientNet 性能
将EfficientNet模型与其他架构进行比较,并在下图中比较其参数。
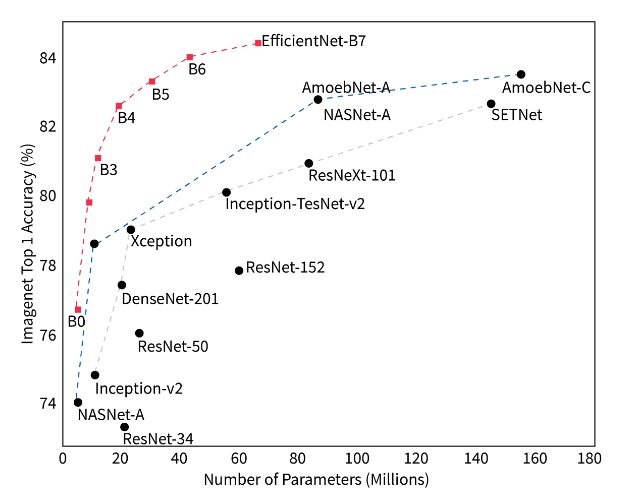
我们可以看到,EfficientNet 在性能和参数数量方面比其所有预先存在的模型都要好得多。此外,FLOPS 显著降低,同时性能优于 ResNet 和其他类似架构。这种显著的性能改进是由于使用 NAS 选择最佳基线架构,并在模型扩展时使用复合扩展。
实施 EfficientNet
我们将使用 TensorFlow 来实现 EfficientNetB3 架构并检查结果。
加载库和数据:
我们将使用 CIFAR10 图像数据集。训练数据集和测试数据集是预先拆分的,因此我们不必这样做。
from keras.datasets import cifar10
(x_train,y_train),(x_test,y_test)=cifar10.load_data()
import numpy as np
import pandas as pd
from sklearn.utils.multiclass import unique_labels
import os
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import seaborn as sns
from keras.preprocessing.image import ImageDataGenerator
import itertools
from sklearn.model_selection import train_test_split
import sklearn.metrics
from keras import Sequential
from sklearn.utils.multiclass import unique_labels
from keras.utils import to_categorical
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import SGD
from sklearn.model_selection import train_test_split
from keras.layers import Flatten, Dense, BatchNormalization, Activation
接下来,我们将训练数据集拆分为验证集和训练集。
x_train,x_val,y_train,y_val=train_test_split(x_train,y_train,test_size=.3)一热编码用于对分类数据进行编码。
y_train=to_categorical(y_train)
y_val=to_categorical(y_val)
y_test=to_categorical(y_test)
数据增强:
我们使用图像数据生成器方法增强图像数据。您可以使用参数值来查看哪个最适合该数据集。
train_data_generator = ImageDataGenerator(rotation_range=15, horizontal_flip=True,width_shift_range=0.1, height_shift_range=0.1)
val_data_generator = ImageDataGenerator(rotation_range=15, horizontal_flip=True,width_shift_range=0.1, height_shift_range=0.1)
test_data_generator = ImageDataGenerator(rotation_range=15, horizontal_flip=True,width_shift_range=0.1, height_shift_range=0.1)
train_data_generator.fit(x_train)
val_data_generator.fit(x_val)
test_data_generator.fit(x_test)
创建我们的 EfficientNet B3 模型:
我们安装所需的软件包,并使用以下代码行导入 EfficientNet B3 架构。
!pip install git+https://github.com/titu1994/keras-efficientnets.git
!pip install keras_applications
from keras_efficientnets import EfficientNetB3
我们创建基线 EfficientnetB3 模型。然后,我们向其中添加 ReLU 层,最后,以逐渐减少输出参数的数量。最后一层是用于分类的 softmax 层。
base_B3_model = EfficientNetB3(include_top=False, weights="imagenet", input_shape=(32,32,3),classes=y_train.shape[1])
B3_model= Sequential()
B3_model.add(base_B3_model)
B3_model.add(Flatten())
B3_model.add(Dense(1024,activation=('relu'),input_dim=512))
B3_model.add(Dense(512,activation=('relu')))
B3_model.add(Dense(256,activation=('relu')))
B3_model.add(Dense(128,activation=('relu')))
B3_model.add(Dense(10,activation=('softmax')))
base_B3_model.summary()
模型训练:
我们定义了学习率、损失函数和优化器。我们使用随机梯度下降作为优化器,使用分类交叉熵作为损失函数。最后,我们用这些值编译模型。
batch_size= 100
epochs =50
learning_rate=.001
sgd=SGD(lr=learning_rate,momentum=0.9,nesterov=False)
B3_model.compile(optimizer=sgd,loss='categorical_crossentropy',metrics=['accuracy'])
现在剩下要做的就是训练模型。
B3_model.fit(train_data_generator.flow(x_train, y_train, batch_size = batch_size), epochs = epochs, steps_per_epoch = x_train.shape[0]//batch_size,
validation_data = val_data_generator.flow(x_val, y_val, batch_size = batch_size), validation_steps = 200, verbose = 1)
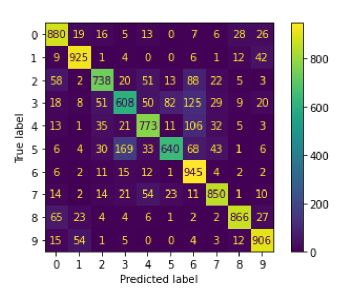
绘图混淆矩阵:
使用混淆矩阵,让我们预测测试数据集的输出值并查看准确性。
y_pred = np.argmax(B3_model.predict(x_test), axis=-1)
y_true=np.argmax(y_test,axis=1)
confusion_matrix = metrics.confusion_matrix(y_true, y_pred)
cm_display = metrics.ConfusionMatrixDisplay(confusion_matrix = confusion_matrix)
cm_display.plot()
plt.show()
输出:
结论
- DenseNet 是 ResNet 的改进版本,通过解决消失/爆炸梯度问题。
- EfficientNet 使用复合缩放技术来获得更好的结果。
- 使用神经架构搜索进行复合扩展产生了一系列 EfficientNet。
- EfficientNet在参数数量方面优于其所有前辈。