Ref 系列 UniRef++: Segment Every Reference Object in Spatial and Temporal Spaces 论文阅读笔记
Ref 系列 UniRef++: Segment Every Reference Object in Spatial and Temporal Spaces 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 统一的模型
- 3.2 特定任务的目标分割
-
- 指代图像分割
- Few-shot 分割
- 指代视频目标分割
- 视频目标分割
- 四、方法
-
- 4.1 总览
- 4.2 指代编码
-
- Few-shot Segmentation and Video Object Segmentation
- Referring Image Segmentation
- Referring Video Object Segmentation
- 4.3 多尺度 UniFusion 模块
- 4.4 统一的架构
-
- Transformer
- Mask 解码器
- 4.5 训练和推理
-
- 训练
- 推理
- 五、实验
-
- 5.1 实验设置
-
- 数据集
- 实施细节
- 5.2 定量分析
-
- 指代图像分割 RIS
- Few-shot Segmentation
- Referring Video Object Segmentation
- Video Object Segmentation
- 5.3 消融研究
- 5.4 定性结果
- 六、将 UniFusion 插入到 SAM
- 七、结论
写在前面
这周得加更两篇论文阅读笔记,完成 2023 的 flag。
此论文也是 Arxiv 比较新的文章,设计了一个大一统模型,解决图像和视频的指代分割问题,应该是篇大佬工作。
- 论文地址:UniRef++: Segment Every Reference Object in Spatial and Temporal Spaces
- 代码地址:https://github.com/FoundationVision/UniRef
- 预计提交于:CVPR 2024
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 6 千粉丝有你的参与呦~
一、Abstract
基于指代的目标分割任务,有 指代图像分割 referring image segmentation (RIS)、少样本图像分割 few-shot image segmentation (FSS)、指代视频目标分割 referring video object segmentation (RVOS) 和视频目标分割 video object segmentation (VOS)。这些任务要么利用语言或 masks 标注作为指代去分割出特定的目标。虽然这些任务的进展很大,但当前方法仍然设计于特定任务,应用于不同的方向,这妨碍了多任务的能力。于是本文提出一种统一的框架 UniRef++ 统一这四个基于指代的目标分割任务。方法的核心思想在于提出的 UniFusion 模块执行不同任务的多种方式融合。UniRef++ 能够在广泛的数据集中进行训练,同时兼容其它多种任务。实验表明本文的方法在 RIS、RVOS、FSS、VOS 上达到了 SOTA。此外,本文的 UniFusion 模块很容易整合进 SAM 中,从而实现高效参数微调。
二、引言
基于指代引导的分割任务定义,四个:指代图像分割 referring image segmentation (RIS)、少样本图像分割 few-shot image segmentation (FSS)、指代视频目标分割 referring video object segmentation (RVOS) 和半监督视频目标分割 video object segmentation (VOS)。
尽管这些任务各自发展都很不错,但需要特定的模型,以及额外的训练时间和模型权重,导致计算成本较高,同时产生冗余的参数。此外,这些单独的模型未能应用于其它任务。于是本文基于一个主旨:这些任务都是使用指代(语言或标注的 masks) 作为引导从而进行特定目标的像素分割。这就需要一个统一的模型在同一套参数下执行不同的任务。
目前存在的问题:不同领域内的主流方法差异很大,RIS 方法主要关注视觉语言信息的深度跨模态融合,而 FSS 主要在基于关联的方法上,用于稠密的语义关联。VOS 方法主要是空间-时间记忆网络用于像素匹配。最近的 RVOS 方法则极度依赖于基于 query 的方法;图像水平的方法不能简单拓展到视频领域。图像任务仅需要分割单张图像内的目标,而视频任务则有可能会出现目标遮挡、快速运动、消失再重新出现的情况,这就需要网络利用空间-时序信息来追踪整个视频上的目标。于是图像上的情况很难应用在视频上;视频任务(VOS 和 RVOS) 当前以两种不同的算法来解决——之前的 RVOS 拿整个视频作为输入,一步到位,对所有帧产生预测,而 VOS 方法则以在线的方式将冗余的历史信息投影到下一帧。
因此本文提出一种统一的模型 UniRef++ ,用于基于指代的目标分割任务。核心思想将四个任务塑造为实例水平的分割问题,而指代的信息则可以通过基于注意力的融合过程注入到网络中。
如上图所示,UniRef++ 接收当前的帧信息,然后利用相应的指代信息去执行融合过程,名为多方式-融合。具体来说,用于指代图像的标注 mask 用作 FSS 和 VOS 的指代,而源于语言描述的指代则用作 RIS 的指代。对于 RVOS,所有的语言和 mask 指代都被使用。这一设计不仅以在线的方式解决 RVOS 问题,同时也能利用 mask 的历史信息来确保时序的一致性。
本文贡献总结如下:
- 提出 UniRef++,一种统一的模型在一套权重下执行 4 个基于指代的目标分割任务(RIS、FSS、RVOS、VOS)。
- 引入 UniFusion 模块,将指代信息注入到网络中而不管模态结构。利用语言和 masks 作为指代,为 RVOS 建立一种新的在线方法。
- 实验表明本文提出的模型在 RIS、RVOS、FSS、VOS 上达到了 SOAT 的性能。
三、相关工作
3.1 统一的模型
有很多工作致力于在视觉或视觉-语言任务上实现统一的交互。例如 Unified-IO 在大量的图像水平的任务上,例如图像分类、图像字幕、VQA 上,以一种 sequence-to-sequence 生成的方式统一。另外一些工作旨在采用一种统一的架构用于密切关联的任务:GLIP 将所有的目标检测和短语定位任务视为句子-区域对齐问题。OneFormer 则采用一个 Transformer 网络统一了图像分割任务。Unicorn 提出先验任务的设计用于解决四个跟踪任务。然而这些方法仅仅关注图像域或者视觉任务。本文旨在建立一种统一的模型用于基于指代的目标分割任务。
3.2 特定任务的目标分割
指代图像分割
RIS 的定义,先前的研究主要关注于多模态特征交互技术,要么利用 CNN 中的注意力机制,要么使用多模态 Transformer。还有一些工作旨在建立统一的框架用于指代表达式理解 REC 和 RIS 任务。
Few-shot 分割
FSS 任务的定义,早期的方法主要通过给定集合的 masks 平均池化来计算类别的原始 masks,然后利用给定集合的信息细化 query 的图像特征。由于此类方法中的池化操作会造成明显的信息丢失,于是基于关联的方法,提出建模 query 和给定图像间的像素联系。
指代视频目标分割
RVOS 是 RIS 在视频领域的拓展。之前的一些方法独立的处理视频帧,或是简单采用 3D CNNs 来提取时序特征。最近一些基于 query 的 Transformer 方法以在线处理的方式实现了 SOTA。然而这种方式不适用于长视频或者不间断视频。与这些工作相比,本文提出的在线处理方法 UniRef++ 利用了 mask 投影过程中的历史信息,确保了目标的时序一致性。
视频目标分割
之前的方法大致分为两类:基于模板的方法,将标注帧视为模板,从而将模板信息融合到当前帧内;基于记忆的方法,STM 利用一个记忆网络将过去帧的预测记住,从而学习空间-时间像素水平的关联。后续的工作主要关注于如何提高记忆的 embedding,例如设计新颖的记忆网络或者合适的记忆读取策略。这些工作将 VOS 任务视为像素水平的二分类任务,缺乏了对目标的理解,而本文将 VOS 视为实例分割任务。
四、方法
4.1 总览

UniRef++ 整体结构如上图所示,其框架由一个视觉编码器,两个指代编码器(分别用于文本和 mask),一个提出的 UniFusion 模块和一个基于 Transformer的检测器组成。给定图像 I ∈ R H × W × 3 \bold I\in \mathbb{R}^{H\times W\times3} I∈RH×W×3 和相应的指代,首先使用视觉编码器 E n c V \mathbf{Enc}_V EncV 提取当前图像的多尺度特征 F = { F ℓ } ℓ = 1 4 \mathcal{F}=\{F_{\ell}\}_{\ell=1}^4 F={Fℓ}ℓ=14,其中 l l l 表示级联的视觉特征的索引,其空间尺度从 4 到 32。然后指代编码器用于编码指代的信息,后面跟着 UniFusion 模块,将指代信息注入到视觉特征中。最后,通过一个统一的基于 Transformer 的网络,为指代目标生成一个二值 mask m ∈ R H × W m\in\mathbb{R}^{H\times W} m∈RH×W。
4.2 指代编码
这一部分,将介绍如何编码指代的信息用于四个基于指代的任务。
Few-shot Segmentation and Video Object Segmentation
对于 FSS 和 VOS 任务。提供的指代图像 mask 标注作为指代。与 STCN 中对比两帧图像的相似度类似,采用统一视觉编码器 E n c V \mathbf{Enc}_V EncV 来提取指代帧 I ref I_{\text {ref}} Iref 的级联的视觉特征 F V f = { F V , ℓ f } \mathcal{F}_{V}^\mathrm{f}=\left\{F_{V,\ell}^\mathrm{f}\right\} FVf={FV,ℓf}。然后采用一个轻量化的 mask 编码器,利用 ResNet18 来接受指代帧 I ref I_{\text {ref}} Iref。目标 mask 标注 m 0 m_0 m0 以及编码的帧特征 F V \mathcal{F}_{V} FV 用于生成指代帧目标的多尺度 mask 特征 F V f = { F V , ℓ f } \mathcal{F}_{V}^\mathrm{f}=\left\{F_{V,\ell}^\mathrm{f}\right\} FVf={FV,ℓf}。这里 F V , ℓ f F_{V,\ell}^\mathrm{f} FV,ℓf, F V , ℓ m F_{V,\ell}^\mathrm{m} FV,ℓm 中, l = 2 , 3 , 4 \mathcal l=2,3,4 l=2,3,4。用公式表示如下:
F V f = Enc V ( I r e f ) F V m = Enc M ( I r e f , m o , F V f ) \begin{gathered}\mathcal{F}_V^f=\operatorname{Enc}_V(I_{\mathrm{ref}})\\\mathcal{F}_V^m=\operatorname{Enc}_M(I_{\mathrm{ref}},m_o,\mathcal{F}_V^f)\end{gathered} FVf=EncV(Iref)FVm=EncM(Iref,mo,FVf)
Referring Image Segmentation
RIS 任务的指代是语言描述 T T T。为编码语言信息,应用一个离线的文本编码器(例如 BERT,或 RoBERTa)提取语言特征 F T ∈ R L × C F_T\in\mathbb{R}^{L\times C} FT∈RL×C,其中 L L L 为句子的长度, C C C 为通道维度: F T = E n c T ( T ) F_{T}=\mathbf{Enc}_{T}(T) FT=EncT(T)。
Referring Video Object Segmentation
RVOS 需要模型不仅理解语言描述,而且要跟踪整个视频中的指代目标。于是在此任务中同时编码语言和视觉信息。类似的,提取语言特征,然后应用编码器进一步编码特征。需要注意的是 mask 标注仅在训练中可用,而在前一帧中使用预测的 mask 作为推理中的视觉指代。
4.3 多尺度 UniFusion 模块
在指代信息编码完成后,有一个问题自然产生了:如何注入指代信息到网络中?接下来引入提出的多尺度 UniFusion 模块用于指代信息的注入。
首先以级联的方式融合视觉特征 F \mathcal F F 和指代特征。以第 ℓ \ell ℓ 层( ℓ = 2 , 3 , 4 \ell=2,3,4 ℓ=2,3,4)视觉水平特征为例:当前图像第 ℓ \ell ℓ 层的视觉特征 F ℓ F_{\ell} Fℓ 和源于指代特征的相应的 key、value embedding( F r k F_{r}^{\mathrm{k}} Frk 和 F r v F_{r}^{\mathrm{v}} Frv)。对于 mask 指代: F r k = F V f F_{r}^{\mathrm{k}}=\mathcal{F}_{V}^{f} Frk=FVf, F r v = F V m F_{r}^{\mathrm{v}}=\mathcal{F}_{V}^{m} Frv=FVm。对于语言指代: F r k = F r v = F T F_{r}^{\mathrm{k}}=F_{r}^{\mathrm{v}}={F_{T}} Frk=Frv=FT。这些输入首先通过线性投影转化为三个向量: Q ℓ Q_{\ell} Qℓ、 K ℓ K_{\ell} Kℓ 和 V ℓ V_{\ell} Vℓ。首先在这些向量间执行多头跨注意力操作,然后指代特征 F r k F_{r}^{\mathrm{k}} Frk 通过池化和回归分别获得尺度、偏移量和门参数: γ \gamma γ、 β \beta β、 α \alpha α,应用在注意力块中。最终输出的特征通过残差连接注入到原始的视觉特征中。UniFusion 处理过程表示如下:
O ℓ = A t t e n t i o n ( Q ℓ , K ℓ , V ℓ ) γ , β , α = L i n e a r ( P o o l i n g ( F r k ) ) F ℓ ′ = F ℓ + α ( O ℓ ( 1 + γ ) + β ) \begin{gathered} O_{\ell}=\mathrm{Attention}(Q_{\ell},K_{\ell},V_{\ell}) \\ \gamma,\beta,\alpha=\mathrm{Linear}(\mathrm{Pooling}(F_{r}^{\mathrm{k}})) \\ \begin{aligned}F_{\ell}'=F_{\ell}+\alpha(O_{\ell}(1+\gamma)+\beta)\end{aligned} \end{gathered} Oℓ=Attention(Qℓ,Kℓ,Vℓ)γ,β,α=Linear(Pooling(Frk))Fℓ′=Fℓ+α(Oℓ(1+γ)+β)其中 O ℓ O_{\ell} Oℓ 为注意力操作的中间结果, F ℓ ′ F_{\ell}' Fℓ′ 为 UniFusion 的最终输出。在所有视觉尺度上,UniFusion 模块贡献相同的参数。UniFusion 与其他方法的区别在于:使用 FlashAttention 执行跨注意力操作,当计算稠密的特征图时效率更高且内存消耗更小;受 adaLN-zero 块的启发,偏移和门的参数都是 zero-initialized 的。这使得网络逐渐地学到指代的知识,使得 UniFusion 更容易插入到预训练的目标分割模型中。
4.4 统一的架构
多尺度视觉特征 F ′ = { F ℓ ′ } ℓ = 2 4 \mathcal{F}^{\prime}=\left\{\boldsymbol{F}_{\ell}^{\prime}\right\}_{\ell=2}^{4} F′={Fℓ′}ℓ=24 通过特定的目标指代后,有着明显的表示。
Transformer
采用两阶段的 Deformable-DETR 作为目标检测器。其接收融合的级联视觉特征 F ℓ ′ F_{\ell}' Fℓ′ 作为输入,在编码器中执行多尺度可变形 self-attention 操作。而在解码器内, N N N 个目标 queries 经过堆叠的解码器层进行提炼,最终转化为 query 表示 Q o b j ∈ R N × C Q_{\mathrm{obj}}\in\mathbb{R}^{{N}\times C} Qobj∈RN×C。三个预测头(类别头、box head、mask head)建立在解码器的顶部来预测目标得分 S ∈ R N × 1 S\in\mathbb{R}^{N\times{1}} S∈RN×1,boxes B ∈ R N × 4 B\in\mathbb{R}^{N\times{4}} B∈RN×4 以及 mask 的动态卷积核参数 G = { g i } i = 1 N \mathcal{G}=\{{g_{i}}\}_{i=1}^{N} G={gi}i=1N。
Mask 解码器
将 Transformer 编码器的输出特征(步长从 8 到 32)以类似 FPN 的方式进行级联融合。步长为 4 4 4 的特征图 F 1 F_1 F1 也添加上。于是,得到高分辨率的 mask 特征 F s e g ∈ R H 4 × W ˉ 4 × C F_{\mathrm{seg}}\in{\mathbb{R}}^{\frac{H}{4}\times\frac{\bar{W}}{4}\times C} Fseg∈R4H×4Wˉ×C。最终,指代目标的 masks 通过执行 F s e g F_{\mathrm{seg}} Fseg 和 G \mathcal{G} G 间的动态卷积实现:
m i = Upsample ( DynamicConv ( F s e g , g i ) ) , i = 1 , . . . , N m_i=\text{Upsample}(\text{DynamicConv}(F_{\mathrm{seg}},g_i)),i=1,...,N mi=Upsample(DynamicConv(Fseg,gi)),i=1,...,N
在推理过程中,选择最高得分的 mask 作为指代目标的最终结果 m m m。尽管一个目标 query 对于基于指代的任务来说已经足够,但是实验发现更多的目标 queries 有助于更好的性能。
4.5 训练和推理
训练
网络预测 N N N 个目标得分和分割 masks,其中目标得分表示目标是否在当前帧中可见。在训练过程中,应用集合预测损失。仅有一个 GT 对应基于指代的目标分割任务。根据最优转移方法(见原文引用文献),通过选择 top-k 个预测达到最小损失。匹配损失构建如下:
C = λ c l s ⋅ C c l s + λ L 1 ⋅ C L 1 + λ g i o u ⋅ C g i o u \mathcal{C}=\lambda_{cls}\cdot\mathcal{C}_{cls}+\lambda_{L1}\cdot\mathcal{C}_{L1}+\lambda_{giou}\cdot\mathcal{C}_{giou} C=λcls⋅Ccls+λL1⋅CL1+λgiou⋅Cgiou其中 C c l s \mathcal{C}_{cls} Ccls 为 focal loss,box 损失包含广泛使用的 ℓ 1 \ell_1 ℓ1 损失和 GIoU 损失,最小损失的 top-k 个预测被赋值为正样本,其它则为负样本。UniRef++ 通过最小化下列损失函数进行优化:
L = λ c l s ⋅ L c l s + λ L 1 ⋅ L L 1 + λ g i o u ⋅ L g i o u + λ m a s k ⋅ L m a s k + λ d i c e ⋅ L d i c e \mathcal{L}=\lambda_{cls}\cdot\mathcal{L}_{cls}+\lambda_{L1}\cdot\mathcal{L}_{L1}+\lambda_{giou}\cdot\mathcal{L}_{giou}+\lambda_{mask}\cdot\mathcal{L}_{mask}+\lambda_{dice}\cdot\mathcal{L}_{dice} L=λcls⋅Lcls+λL1⋅LL1+λgiou⋅Lgiou+λmask⋅Lmask+λdice⋅Ldice其中类别损失和 boxes 损失与前面一个式子相同,与 mask 相关的损失包含 mask 二值交叉熵损失和 DICE 损失。
推理
对于 RIS 和 FSS,直接输出的 query 预测中最高得分的 mask,而对于 RVOS 和 VOS,则无需后处理,以在线帧到帧方式推理视频。具体来说,对于当前帧,网络使用相应的指代信息来生成特定目标的 masks。若目标得分高于预定义的阈值 σ \sigma σ,则 mask 即为输出,反之输出的 mask 所有值均设为 0。为解决视频中包含多个目标的问题,采用之前工作中广泛使用的 soft-aggregation 方法。
五、实验
5.1 实验设置
数据集
- RIS:RefCOCO、RefCOCO+、RefCOCOg(UMD)
- FSS:FSS-1000
- RVOS:Ref-Youtube-VOS、Ref-DAVIS17
- VOS:Youtube-VOS、LVOS、MOSE
实施细节
两种 Backbone,ResNet50 + Swin Transformer-Large;文本编码器 BERT-base。句子最大长度 77。Transformer 架构有 6 层编码器,6 层解码器,通道维度 256。目标 query 的数量设为 300。损失系数 λ c l s = 2.0 , λ c l s = 2.0 , λ L 1 = 5.0 , λ m a s k = 2.0 , λ d i c e = 5.0 \lambda_{cls}=2.0,\lambda_{cls}=2.0,\lambda_{L1}=5.0,\lambda_{mask}=2.0,\lambda_{dice}=5.0 λcls=2.0,λcls=2.0,λL1=5.0,λmask=2.0,λdice=5.0。
整体训练过程包含三个序列阶段,其中来源于前一阶段的预训练权重将用于下一阶段的训练。(1) Objects365 预训练,应用 BoxInst 损失来监督 mask 的生成。这一阶段旨在训练目标检测器;(2)图像水平的训练,首先结合 RefCOCO/+/g 的训练集来训练整体网络,然后在 RIS 和 FSS 任务上进行训练;(3)视频级别的训练,随机从视频中采样两帧,第一帧作为指代帧。为避免 RIS 的知识泄露,从 RefCOCO/+/g 中生成伪标签。网络共同训练在所有数据集上,包含 RefCOCO/+/g、Ref-YoutubeVOS、Ref-DAVIS17、COCO、Youtube-VOS19、OVIS、LVOS。
使用 Pytorch toolkit 来进行所有实验,NVIDIA A100 GPUs。使用 4 × 8 4\times8 4×8 块 A100 用于 Object365 的预训练, 2 × 8 2\times8 2×8 块 GPUs 训练接下来的图像和视频。AdamW 优化器。每块 GPU batch 2。(有钱的大佬啊,一般的实验室就甭想了~~)
5.2 定量分析
ResNet-50 和 Swin Transformer-Large 作为视觉 Backbone 用于实验,表示为 UniRef+±R50 和 UniRef+±L。
指代图像分割 RIS
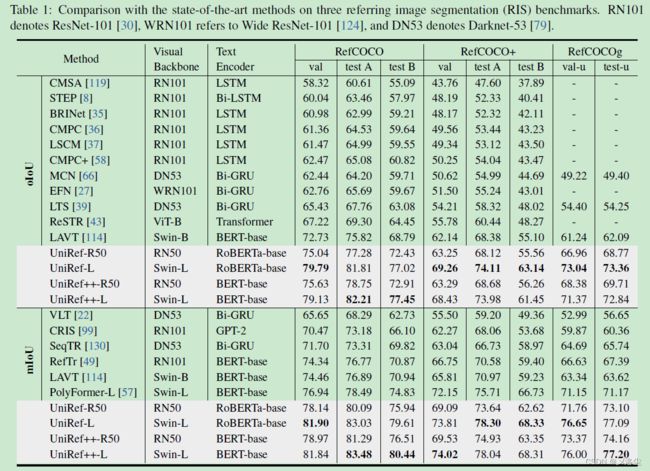
Few-shot Segmentation
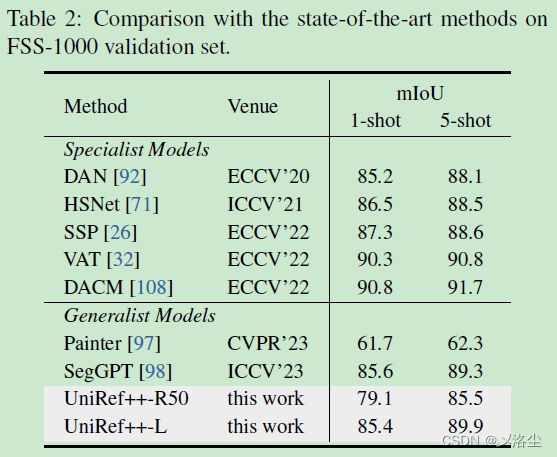
Referring Video Object Segmentation

Video Object Segmentation

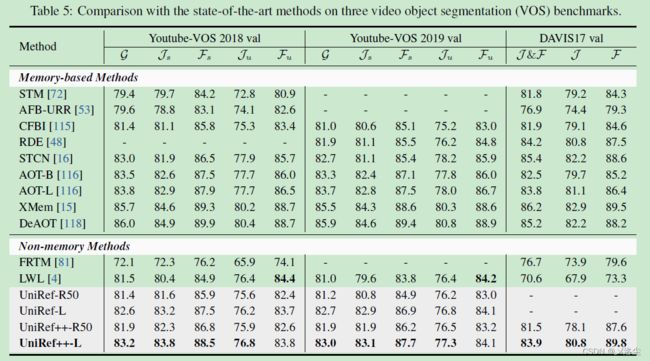
5.3 消融研究
- Task-specific Training
- Parameter-sharing for UniFusion Module
- Query Number

- Does Mask Reference Help RVOS?

5.4 定性结果
六、将 UniFusion 插入到 SAM


七、结论
本文提出 UniRef++,一个统一的模型用于四个基于指代的目标分割任务(RIS, FSS,
RVOS and VOS),通过引入 UniFusion 模块整合不同类型的指代信息,模型能够弹性地执行多任务。实验表明 UniRef 效果很好,也能做到即插即入,可用于后续微调(例如 SAM)。
写在后面
这篇文章工作量是真的大,附录还有 4 页,这里就不多介绍了。咋说,这篇文章绝对会中的,立意也是够新颖,实验充分,写作水平也是极为简洁,不拖沓。是篇好文章,值得好评!