架构设计内容分享(六十九):100w人在线的 弹幕 系统,是怎么架构的?
目录
100w用户同时在线的弹幕系统背景
问题分析
架构设计和优化
业务解耦+服务拆分
业务解耦+服务拆分的具体架构方案
解耦之后的优势:
引入本地缓存优化高并发读
引入限流,优化高并发写
使用滑动窗口,实现无锁化读写
通过短轮训实现弹幕促达
弹幕卡顿、丢失分析
基于AJAX的长轮询方案 (Long Polling via AJAX)
基于WebSockets 的双向通讯方案
Long Polling vs Websockets
传输优化、节约带宽
总结
100w用户同时在线的弹幕系统背景
为了更好的支持 shopee 东南亚直播业务,Shopee 平台产品设计为直播业务增加了弹幕。
第一期弹幕使用腾讯云支持,效果并不理想,
主要问题是:
-
经常卡顿、
-
弹幕偏少等问题。
最终促使Shopee团队,定制开发自己的弹幕系统。
其性能规划是:单房间百万用户同时在线。
没有看错:「百万用户同时在线,而且是单房间」。
假如说每3秒促达用户一次,百万用户同时在线,单房间具体QPS将超过30w QPS
没有看错:「单房间具体QPS将超过30w QPS」
问题分析
按照背景来分析,系统将主要面临以下问题:
-
带宽压力
❝
假如说每3秒促达用户一次,那么每次内容至少需要有15条才能做到视觉无卡顿。
15条弹幕+http包头的大小将超过3k,那么每秒的数据大小约为8Gbps,
而运维同学通知我们所有服务的可用带宽仅为10Gbps。
❞ -
弱网导致的弹幕卡顿、丢失
❝
该问题已在线上环境
❞ -
性能与可靠性
❝
百万用户同时在线,按照上文的推算,具体QPS将超过30w QPS。
如何保证在双十一等重要活动中不出问题,至关重要。性能也是另外一个需要着重考虑的点。
❞
架构设计和优化
那么,该如何做架构设计和优化呢?
主要的架构优化有:
-
业务解耦+服务拆分
-
引入本地缓存,优化高并发读
-
引入限流,优化高并发写
-
使用滑动窗口,实现无锁化读写
-
通过短轮训实现弹幕促达
-
传输优化、节约带宽
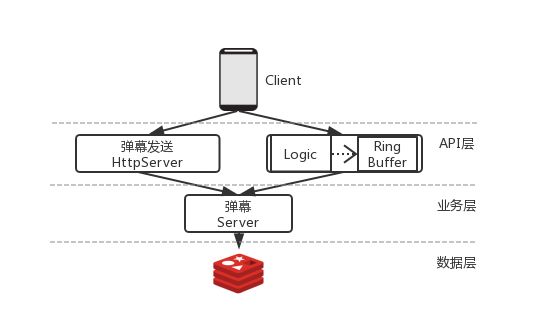
业务解耦+服务拆分
为了保证服务的稳定性我们对服务进行了拆分,进行业务解耦+服务拆分
业务解耦+服务拆分的具体架构方案
将逻辑较为复杂、调用较少的发送弹幕业务与逻辑简单、调用量高的弹幕拉取服务拆分开来。
将复杂的逻辑收拢到发送弹幕的一端。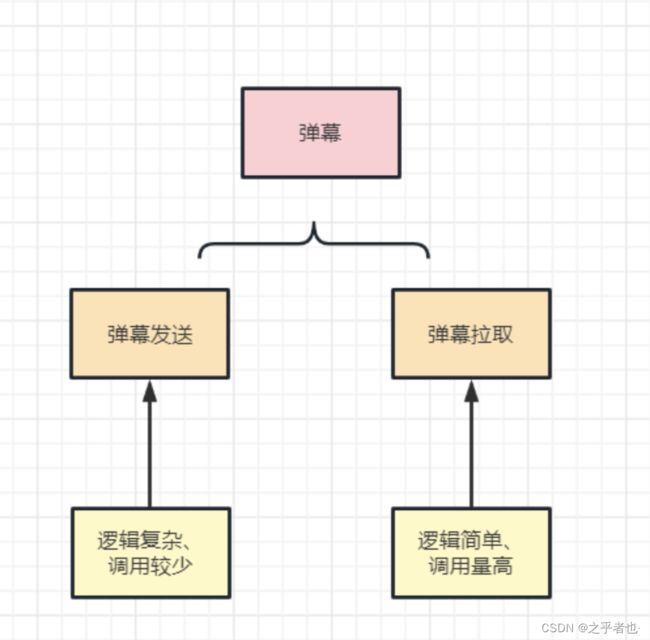
服务拆分主要考虑因素是为了不让服务间相互影响,
对于这种系统服务,不同服务的QPS往往是不对等的,
例如像拉取弹幕的服务的请求频率和负载,通常会比发送弹幕服务高1到2个数量级,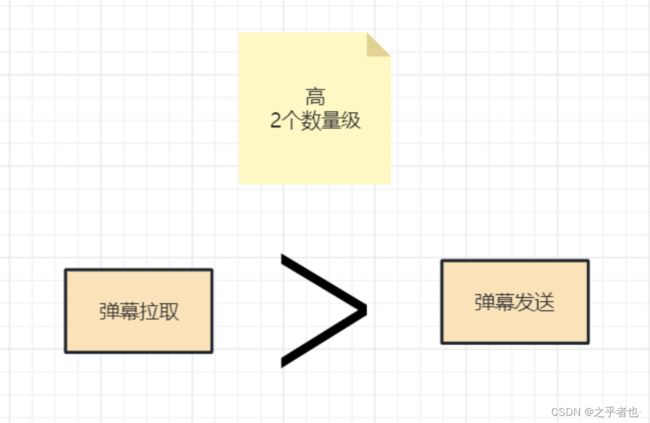
解耦之后的优势:
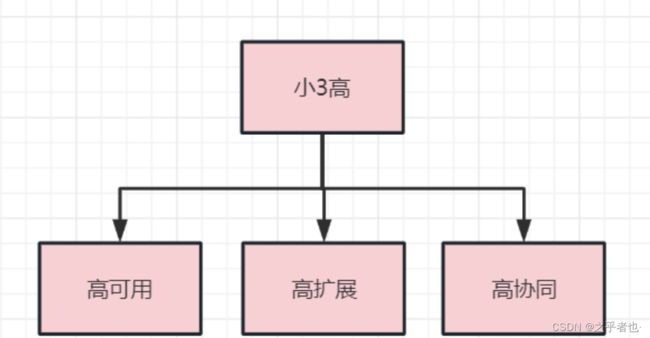
实现一个小3高的目标:高可用、高扩展、高协同
-
高可用
最⼤度地保证系统的可用性,
在这种情况下,不能让拉弹幕服务把发弹幕服务搞垮,
反之亦然,不能让 发弹服务把拉弹幕服务 搞垮
-
高扩展
方便扩容和缩容
更加方便对各个服务做Scale-Up和Scale-Out。
-
高协同
方便协同开发
服务拆分也划清了业务边界,方便协同开发。
引入本地缓存优化高并发读
「在拉取弹幕服务的一端:引入本地缓存」
数据更新的策略是:
服务会定期发起RPC调⽤,从弹幕服务拉取数据,拉取到的弹幕缓存到内存中,
这样后续的请求过来时便能直接⾛走本地内存的读取,大大幅降低了调用时延。
这样做还有另外一个好处就是缩短调⽤链路,把数据放到离⽤户最近的地⽅
同时还能降低外部依赖的服务故障对业务的影响,
引入限流,优化高并发写
「在发送弹幕的一端: 限流(有损服务)」,
因为用户一定时间能看得过来弹幕总量是有限的,
所以可以对弹幕进行限流,有选择的丢弃多余的弹幕。
同时,采用柔性的处理方式,拉取用户头像、敏感词过滤等分支在调用失败的情况下,仍然能保证服务的核心流程不受影响,即弹幕能够正常发送和接收,提供有损的服务。
使用滑动窗口,实现无锁化读写
弹幕数据的读写,如果使用阻塞队列,那么需要加锁
如果加锁,在超高并发场景,会性能非常低
如何实现无锁化读写呢
基于滑动窗口技术,实现无锁化读写,保证在「超高并发场景并发读写的性能」
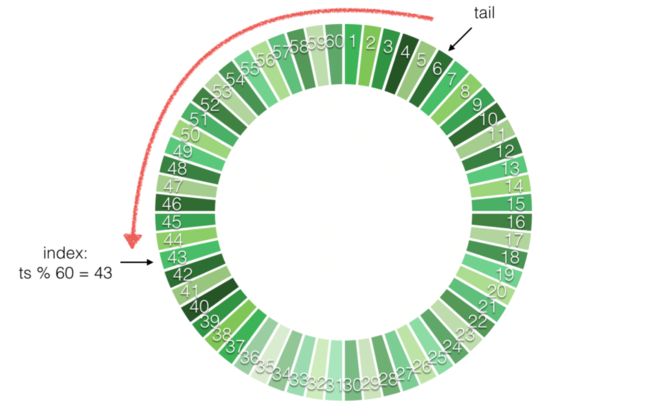
为了数据拉取方便,我们将数据按照时间进行分片,将时间作为数据切割的单位,按照时间存储、拉取、缓存数据(RingBuffer),简化了数据处理流程。
与传统的Ring Buffer不一样的是,我们只保留了尾指针,
它随着时间向前移动,每⼀秒向前移动一格,把时间戳和对应弹幕列表并写到一个区块当中,因此最多保留60秒的数据。
同时,如果此时来了一个读请求,那么缓冲环会根据客户端传入的时间戳计算出指针的索引位置,并从尾指针的副本区域往回遍历直至跟索引重叠,收集到一定数量的弹幕列表返回,
这种机制保证了缓冲区的区块是整体有序的,因此在读取的时候只需要简单地遍历一遍即可,加上使用的是数组作为存储结构,带来的读效率是相当高的。
再来考虑可能出现数据竞争的情况。
先来说写操作,由于在这个场景下,写操作是单线程的,因此⼤可不必关心并发写带来的数据一致性问题。
再来说读操作,由图可知写的方向是从尾指针以顺时针⽅向移动,而读方向是从尾指针以逆时针方向移动,
⽽决定读和写的位置是否出现重叠取决于index的位置,
由于我们保证了读操作最多只能读到30秒内的数据,因此缓冲环完全可以做到无锁读写
通过短轮训实现弹幕促达
Long Polling和Websockets都不适用弱环境,
所以我们最终采取了「短轮训」的方案来实现弹幕促达
弹幕卡顿、丢失分析
在开发弹幕系统的的时候,最常见的问题是该怎么选择促达机制,
-
推送 vs 拉取 ?
-
长轮询 vs 短 轮询
基于AJAX的长轮询方案 (Long Polling via AJAX)
客户端打开一个到服务器端的 AJAX 请求,然后等待响应,
服务器端需要一些特定的功能来允许请求被挂起,只要一有事件发生,服务器端就会在挂起的请求中送回响应。
如果打开Http的Keepalived开关,还可以节约握手的时间。
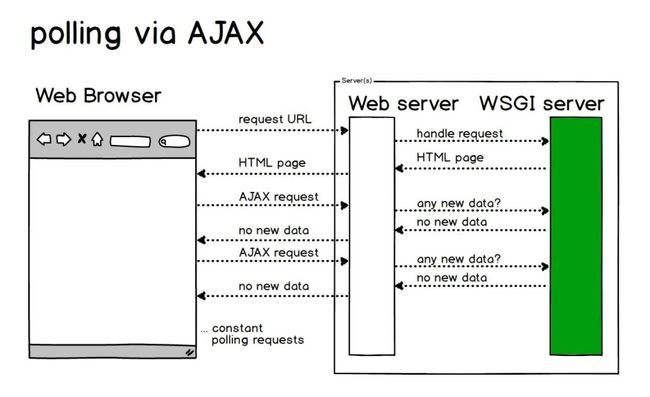
「优点:」
减少轮询次数,低延迟,浏览器兼容性较好。
「缺点:」
服务器需要保持大量连接。
基于WebSockets 的双向通讯方案
长轮询虽然省去了大量无效请求,减少了服务器压力和一定的网络带宽的占用,但是还是需要保持大量的连接。
那么人们就在考虑了,有没有这样一个完美的方案,即能双向通信,又可以节约请求的 header 网络开销,并且有更强的扩展性,最好还可以支持二进制帧,压缩等特性呢?
于是人们就发明了这样一个目前看似“完美”的解决方案 —— WebSocket。
「它的最大特点就是:」
服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息,是真正的双向平等对话。
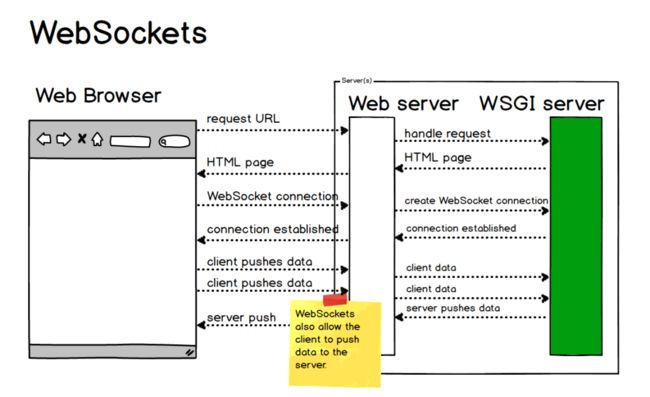
「优点1:较少的控制开销,」
较少的控制开销:在连接创建后, WS用于协议控制的数据包头部相对较小。
在不包含扩展的情况下,服务端到客户端WS 头部大小只有2至10字节(和数据包长度有关);
对于客户端到服务器的内容,此头部还需要加上额外的4字节的掩码。
但是,与 HTTP 头部比,此项开销显著减少了。
「优点2:更强的实时性,」
WEBSocket由于协议是全双工的,服务器可以随时推数据。
WEBSocket延迟明显更少;
「优点3:长连接,保持连接状态」。
Long Polling vs Websockets
无论是以上哪种方式,都使用到TCP长连接,那么TCP的长连接是如何发现连接已经断开了呢?
TCP Keepalived会进行连接状态探测,探测间隔主要由三个配置控制。
❝keepalive_probes:探测次数(默认:7次)
keepalive_time 探测的超时(默认:2小时)
keepalive_intvl 探测间隔(默认:75s)
❞
但是由于在东南亚的弱网情况下,TCP长连接会经常性的断开:
❝Long Polling 能发现连接异常的最短间隔为:min(keepalive_intvl, polling_interval)
Websockets能发现连接异常的最短间隔为:Websockets: min(keepalive_intvl, client_sending_interval)
❞
如果下次发送数据包的时候可能连接已经断开了,所以使用TCP长连接对于两者均意义不大。
并且弱网情况下, Websockets其实已经不能作为一个候选项了
-
即使Websockets服务端已经发现连接断开,仍然没有办法推送数据,只能被动等待客户端重新建立好连接才能推送,在此之前数据将可能会被采取丢弃的措施处理掉。
-
在每次断开后均需要再次发送应用层的协议进行连接建立。
根据了解, 腾讯云的弹幕系统:
-
在300人以下使用的是推送模式,
-
300人以上则是采用的轮训模式。
但是考虑到资源消耗情况,他们可能使用的是Websocket来实现的弹幕系统,
也就是 300人以上轮训模式, 腾讯云也是基于Websocket 来实现的,不太可能基于 AJAX来实现,
正式因为基于Websocket ,在弱网环境下,所以才会出现弹幕卡顿、丢失的情况。
综上所述,Long Polling和Websockets都不适用我们面临的环境,
所以我们最终采取了「短轮训」的方案来实现弹幕促达
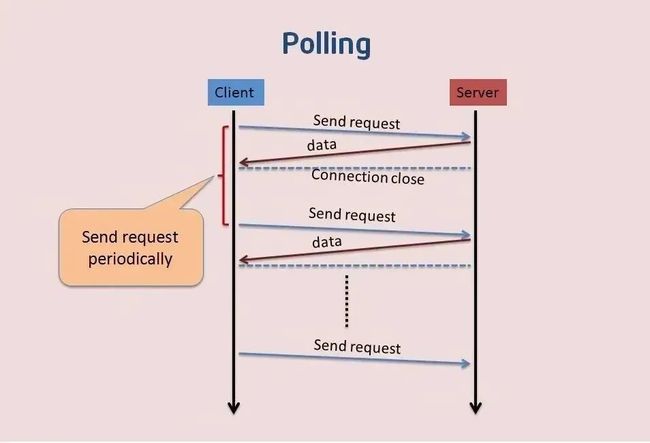
传输优化、节约带宽
为了降低带宽压力,我们主要采用了以下方案:
启用Http压缩
❝通过查阅资料,http gzip压缩比率可以达到40%以上(gzip比deflate要高出4%~5%)。
❞
Response结构简化

内容排列顺序优化
❝根据gzip的压缩的压缩原理可以知道,重复度越高,压缩比越高,
因此 : 可以将字符串和数字内容放在一起摆放
❞
频率控制
❝
通过请求频率调整带宽:通过添加请求间隔参数,实现客户端的请求频率服务端可控。间隔时间太长,在突发流量的时候, 可能会出现有损服务,对于弹幕来说,是可以容忍的。
❞
延长请求频率,可以避免无效请求:在弹幕稀疏和空洞的时间段,通过控制下次请求时间,避免客户端的无效请求。
总结
最终该服务在双十二活动中,在Redis出现短暂故障的背景下,
高效且稳定的支撑了单房间100w用户在线,成功完成了既定的100w用户的目标