探索大型预训练模型:解析人工智能的通用知识引擎
目录
- 前言
- 1 大型预训练模型的演进与重要性
-
- 1.1 Word2Vec
- 1.2 Transformer
- 1.3 GPT模型
- 2 大型预训练模型的发展趋势
-
- 2.1 参数规模与速度的飞跃提升
- 2.2 数据量的持续增长
- 2.3 知识丰富性与少样本学习的突破
- 3 大型预训练模型的核心机制
- 结语
前言
在当今迅猛发展的人工智能领域,大型预训练模型如Word2Vec、RNN、Attention Mechanism、Transformer、ELMo、BERT、GPT-3.5等逐渐成为人工智能领域的焦点,这些模型以其庞大的参数规模和通用知识的储备,在解决复杂问题和推动技术前沿方面展现出前所未有的能力。在本文中,我们将探讨这些模型的演进趋势,深入分析其重要性,以及它们背后的核心机理。我们将着眼于其参数规模的飞跃提升、数据量的持续增长以及知识丰富性与少样本学习的突破,揭示这些趋势如何塑造着未来人工智能的面貌,并为解决复杂现实问题提供新的可能性。
1 大型预训练模型的演进与重要性
随着深度学习技术的迅猛发展,大型预训练模型的出现彻底改变了人工智能的面貌。从早期的Word2Vec、RNN到后来的Attention Mechanism、Transformer、ELMo、BERT,再到最新的GPT-3.5等模型,它们的崛起标志着人工智能领域正迈向一个全新的高度。这些模型之所以备受关注,主要归功于它们庞大的参数规模和所具备的通用知识,这些因素共同为人工智能开启了崭新的纪元。
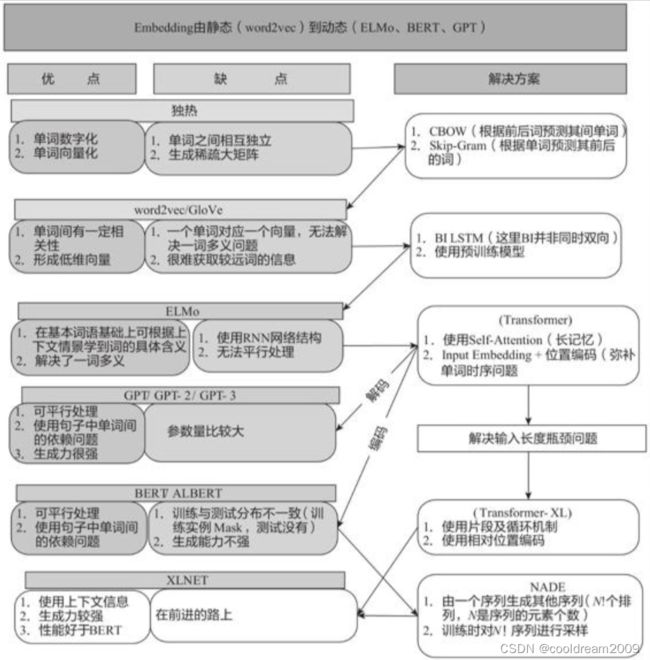
在探究大型预训练模型的机制和重要性时,我们不得不深入了解这些模型是如何成为解决复杂问题的智能引擎的。它们的崛起不仅仅是因为其巨大的规模和潜在的知识库,更因为它们为解决各种复杂问题提供了一种全新的范式。
1.1 Word2Vec
Word2Vec作为早期的预训练模型,主要用于将单词嵌入到低维空间中,以便计算机能够更好地理解语义和语境。RNN(循环神经网络)通过其循环结构在序列数据上展现出优异的性能,为自然语言处理和时间序列数据的处理提供了重要工具。Attention Mechanism则强调模型在处理长距离依赖性时的灵活性和有效性,为处理长文本提供了更好的解决方案。

1.2 Transformer
而Transformer模型的出现进一步改变了预训练模型的面貌,其自注意力机制使得模型能够更好地捕捉序列中的信息。ELMo模型则首次将上下文相关性引入了预训练模型,使得模型对于语境更加敏感,BERT则在此基础上进一步拓展了上下文敏感性,并通过Masked Language Model任务和Next Sentence Prediction任务进行预训练,极大地提高了模型的性能和通用性。
1.3 GPT模型
最新的GPT-3.5模型不仅拥有庞大的参数规模,更蕴含了丰富的知识。它具备超过1750亿的参数量,展现出了惊人的通用性能力,不仅能够精准地理解和生成文本,还能在多种任务中展现出超乎想象的智能表现。

这些模型的重要性不仅在于其性能,更在于它们为解决现实中的复杂问题提供了一种全新的方式。预训练模型的普适性使其可以应用于多种领域,如自然语言处理、计算机视觉、推荐系统等。它们的出现为我们带来了一个全新的时代,人工智能正以前所未有的速度和精度解决着人类面临的各种挑战。
2 大型预训练模型的发展趋势
在深度学习的历程中,预训练模型的崛起彻底改变了人工智能的面貌。这些模型通过吸收大规模数据并从中提取通用知识,以一种自监督的方式进行训练。其性能提升巨大,甚至在某些任务上超越了人类表现。从2018年开始,我们见证了这些模型的三大趋势。

2.1 参数规模与速度的飞跃提升
随着时间的推移,预训练模型的参数规模不断扩大,同时其运行速度也迅猛增长。例如,GPT-3模型拥有高达1750亿个参数,这种规模的增加使得模型能够更全面地学习和理解数据,从而在多个领域展现出卓越性能。模型的速度提升也是另一个值得关注的方面,这使得这些大型模型在实际应用中能够更高效地处理复杂任务。
2.2 数据量的持续增长
预训练模型的性能与其训练数据的量级密切相关。随着数据量的持续增加,模型能够更准确地把握和模拟现实世界的复杂性。这种数据量的增长不仅仅是数量级的提升,更是对模型训练的全面性和多样性的要求。大量的数据让模型能够更好地理解语言、视觉、甚至是跨学科领域的知识。
2.3 知识丰富性与少样本学习的突破
最新的预训练模型不仅拥有广泛的认知能力,还展现出强大的少样本学习能力。这种零样本或少样本学习方式的引入,使得模型在面对新任务时无需大量标注数据,依然能够快速学习和适应。模型不仅能够从海量数据中获得通用知识,还能通过少量示例快速掌握新任务的本质,这一特性在实际应用中具有重要意义。
这三大趋势的出现标志着大型预训练模型的持续演进和发展。参数规模与速度的提升、数据量的增长以及知识的丰富性与少样本学习的突破,共同推动着人工智能领域的前沿进展。这些趋势不仅仅为模型性能的提升注入了强大动力,也为人工智能技术在解决现实世界问题中发挥更广泛和更深远的作用铺平了道路。
3 大型预训练模型的核心机制
大型预训练模型的核心机制主要体现在其预训练阶段。它们利用庞大的未标记数据集,通过自监督学习的方式从中抽取通用知识。这一过程类似于模型在大规模数据中自主发现并学习规律,从而使得模型在各个领域都能获得广泛的知识基础。
在预训练完成后,当引入特定任务的相关数据时,这些模型通过微调和适应,快速而灵活地解决新问题。这种方式类似于人类学习的方式,将之前掌握的通用知识应用于新任务,并根据新数据的特征进行调整和适应。这样的学习模式使得模型能够高效地迁移和应用先前学到的知识,为解决各种任务提供了便利。
这种基于通用知识的预训练和灵活适应特定任务的能力,使得大型预训练模型能够在各种领域中展现出惊人的适应性和智能性。通过这一机制,它们仿佛拥有一个通用的智慧引擎,可以根据需要快速学习和适应不同的任务和情境。
大型预训练模型之所以备受瞩目,不仅在于其参数规模和性能的提升,更在于其独特的学习方式,通过大规模的无标注数据进行预训练,再根据特定任务的数据进行微调,从而迅速解决各种复杂问题。这一机制的应用使得模型在处理现实世界的复杂任务时具备了前所未有的灵活性和效率。
结语
大型预训练模型如同人工智能的通用知识引擎,其强大的数据驱动和通用性使其成为当今解决复杂问题的有力工具。随着技术不断演进,这些模型将继续在各个领域发挥重要作用,为人类带来更广阔的智能边界。本文简要介绍了大型预训练模型的基本概念和演进趋势,但这只是这一领域的冰山一角。预训练模型的研究与应用前景仍然充满了无限可能性,我们对此充满期待。