C++11中的实用语法
文章目录
- 一、C++11简介
- 二、列表初始化
- 三、变量类型推导
-
- 1 为什么需要类型推导
- 2 decltype类型推导
- 四、STL中的一些变化
-
- 1 array
- 2 forward_list
- 3 cbegin和cend
- 五、右值引用
-
- 1 左值和右值
- 2 左值引用的使用场景
- 3 右值引用在传值返回的作用—移动构造函数
- 4 移动赋值函数
- 5 容器插入接口的右值引用
- 6 完美转发
- 六、lambda表达式
-
- 1 引出的例子
- 2 捕捉列表详解
- 3 lambda表达式的原理
- 七、C++11中类的新功能
-
- 1 类中提供了新的一些关键字
-
- I default
- 2 delete
- 2 新增的默认类成员函数—移动构造和移动赋值
- 八、可变参数模板
-
- 1 语法含义
- 2 递归展开参数包
- 3 利用数组展开参数包
- 4 emplace系列函数解释
- 九、函数包装器
-
- 1 std::function
- 2 bind
- 十、STL线程库
-
- 1 组件
- 2 thread
- 3 mutex
- 4 atomic—原子操作
- 5 一些注意点
- 6 lock_guard和unique_lock
- 7 条件变量
一、C++11简介
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了C++98称为 C++11之前的最新C++标准名称。不过由于TC1主要是对C++98标准中的漏洞进行修复,语言的核心部分则没 有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。从C++0x到C++11,C++标准10年磨一剑, 第二个真正意义上的标准珊珊来迟。相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140 个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率。
二、列表初始化
C语言支持用{}给 struct进行初始化,C++98兼容这个C语言特性,在C++11中,扩大了列表初始化的范围。
int main()
{
// 容器
vector<int> b{ 1, 3, 4, 5 };// 等号可以省略掉
// 数组
int a[]{ 1, 2, 3, 4, 5 };
int* a1 = new int[5]{ 1, 3, 4, 2, 4 };
// 内置变量
int x{ 3 };
int y{ 3 + 4 };
}
注意 struct数组初始化需要给 struct提供一个构造函数,没有构造函数时它会去使用C语言的那个{}的特性去初始化。
可以认为C++11的列表初始化{}在某种程度上是支持了多参数的隐式类型转换,之前我们学习过,单个参数的类可以进行单参数隐式类型转换,如:
class A
{
public;
A(int a) : _a(a) {}
private:
int _a;
};
A aa = 1;
struct Point
{
int _x, _y;
Point(int x, int y) : _x(x), _y(y) {}
};
Point pp{1, 2};
Point p1 = {1, 3};
这个特性对像string这样的特别好用,可以从 const char*的常量强转为 string,禁用这个特性加上 explicit可以。
同样的,对一个自定义类型通过一个花括号括起来就能依次初始化各个特性,如果想禁止这个特性,也可以加上 explicit。
但是这样无法解释为啥vector可以使用{}初始化,因为它的元素个数多少不确定啊,上面的Point的初始化我们明确的知道它的参数个数是两个,但是vector可不是这样啊,vector的元素类型是不知道的。
通过查文档,知道C++11的vector为了支持这个特性,增加了一个构造函数:

initializer_list可以认为是一个C++11原生支持的容器,你默认写一个{}它的类型就推导为这个容器:

可以认为它就是一个有begin和end和size的迭代器。

所以对于这种元素个数不知道的容器类型,它们通过{}构造的原理就是先构造一个 initializer_list,然后把这个 initializer_list作为参数构造这个容器。
// 这样也是支持的
map<int, int> mp{ make_pair(1, 2), {3, 2} };
我们给自己写的list增加一个 initializer_list初始化:


还可以通过去复用迭代器区间的现代写法:

同理,我们还可以以{}去给容器赋值,同样的,也是支持一个参数为 initilizer_list的 operator=:


三、变量类型推导
1 为什么需要类型推导
在定义变量时,必须先给出变量的实际类型,编译器才允许定义,但有些情况下可能不知道需要实际类型怎 么给,或者类型写起来特别复杂,比如指定迭代器:
std::map<std::string, std::string>::iterator it = mp.begin();
auto it = mp.begin();
这种时候我们使用 auto关键字就会爽很多。
2 decltype类型推导
之前我们学习过,在C++98中,可以通过 typeid(对象).name()可以获得一个 const char*,其内容是对象的类型。
那如果我还想定义一个这个类型的其他对象呢,就可以用 decltype(对象) x = ...,它可以得到类型。


decltype使用场景:拷贝一个auto类型(类型名太长)的变量,虽然这样auto也可以做到,但是在模板类型参数就不能用auto,如

四、STL中的一些变化
- 新增了一些容器,如
std::array和std::forward_list。 - 已有容器增加了一些新的接口以提升效率和使用便捷程度,如利用右值引用。
1 array
固定大小的数组

它支持迭代器,和普通数组基本一致,那这个容器到底有什么意义嘞,普通数组不初始化,你也不初始化,对象在哪数组里头的东西就去存哪,你array也一样的噻。

事实就是这个容器就是“鸡肋”,食之无味弃之可惜,C++11中也有很多特性是这样的,没什么diao用,所以我们只找了一些有用的特性来看看。
array的“可惜“体现在:
- 支持迭代器,更好的兼容STL,不过数组也支持范围for啊
- 和C数组不同,array对越界有检查.


它是通过 array.operator[](size_t i)中取 assert(i < size)来实现的。
2 forward_list
它是一个单链表

它为了效率,提供的接口就很诡异:

只支持头插、头删、在某个迭代器后面插入或删除某个迭代器后面的元素。
迭代器:

C++11提供的真正有意义的新容器还得是 unordered系列的容器。
3 cbegin和cend
因为认为begin和end既返回普通迭代器,也返回const迭代器,不规范,所以每个容器都提供了cbegin和cend迭代器表示其为const迭代器。
C++11中对于STL接口最有用的方面是提供了一些能够提升效率的接口:移动构造、移动赋值、右值引用版本的插入接口。



五、右值引用
从语法意义上来说,左值引用就是给左值取别名,右值引用就就是给右值取别名。
1 左值和右值
左值是一个表示数据的表达式,如变量名或解引用的指针,我们可以获取它的地址并且可以对它赋值,左值可以出现在赋值操作的左边也可以出现在赋值符号的右边,右值不能出现在赋值符号的左边。
定义时 const修饰后的左值,如 const int b = 1;,我们也认为它是左值,只不过是不能对它赋值,但是可以给他取地址,它也可以用左值引用去引用:const int& a = b;
综合而言,可以取地址的对象都是左值。
右值也是一种表示数据的表达式,常见的右值有:字面常量、表达式返回值、传值返回的函数的返回值,右值可以出现在赋值操作的右边,不能出现在赋值符号的左边,不能对右值取地址,想要引用右值就需要用右值引用。

左值和右值的最大区别就是左值可以取地址,右值不能。
那么就有一个问题:左值引用能否引用右值?右值引用能否引用左值?
左值引用显然是不能引用右值的,我们前面就学过了,它不能直接引用很多常量:

但是加了 const以后,const左值引用就可以引用右值了,这也是为了在C++11出现以前那些STL的接口可以传右值:

那么右值引用能否引用左值:

同样也是不能直接引用,但是右值引用可以引用std::move以后的左值。

需要注意的是右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可以取到该特定位置的地址,也就是说右值引用变成了一个左值,例如:不能取字面量10的地址,但是一个右值引用rr引用了10后,就可以取它的地址,还能修改rr,如果想禁止rr被修改,可以用 const int&& rr去引用。

2 左值引用的使用场景
左值引用的使用场景1:传值传参效率太低,会调用拷贝构造,有的会是深拷贝,代价过高,所以把参数类型设置为 const T&,减少拷贝,并且右值和左值都可以传过来,很完美。
左值引用的使用场景2:做返回值,它非常不完美,只能解决部分问题。
如string中的 operator+=,它返回时就可以返回 string&,因为出了这个函数,这个对象仍然在,所以可以用 string&返回,这里就解决了问题。
但string中的 operator+,它返回的是一个临时在这个函数中创建的左值对象,语义上可以用左值引用返回,但是离开作用域这个对象就被销毁了,你就返回了一个出了问题的对象了,左值引用对于这个场景就无能为力了。
3 右值引用在传值返回的作用—移动构造函数
C++11使用右值引用解决了这个问题,它首先会提供一个移动构造函数:
string(string&& s)
: _str(nullptr), _size(0), _capacity(0)
{
this->swap(s);// 换个东西给你咯
}
为了理解移动构造的含义,我们需要了解C++11中把右值分为的类型:
- 纯右值(普通类型的右值对象)
- 将亡值(自定义类型的右值对象),即将死亡的值,如自定义类型函数的返回值,自定义类型的匿名对象等。
你都要“死亡了”,资源析构掉多不好啊,不如把资源移动给我。
这里的逻辑就是你返回的是一个右值,所以(无优化时)会先拷贝构造返回的临时对象,然后以返回值获得新对象时,会走我的参数为右值的移动构造函数(const左值引用和右值引用这里编译器会严格卡类型),析构原栈帧中的临时对象,然后会把这个返回的临时对象的资源移动给构造的新对象,而不会去直接析构这个返回临时对象,对比没有移动语义时,过程就是先走拷贝构造函数去深拷贝生成返回值的临时对象,然后析构原函数中的资源,然后再拷贝构造新的对象,然后再析构这个临时对象,有了移动语义生成的临时对象析构这件没有意义的事情。
string to_string(int val)
{
//...
return ret;
}
string s = to_string(1234);
所以无优化时,只有拷贝构造时:拷贝构造返回对象、再拷贝构造拿返回的对象构造新对象;
无优化时,有了移动构造后:拷贝构造返回对象、然后移动构造去把返回的对象的资源给新对象;
在没有移动构造时,编译器会优化为:它看你这个第一次拷贝构造的临时对象也没人用啊,所以它使得在 to_string的栈帧销毁前,用返回值的 ret去拷贝构造新的对象。
在有移动构造时,编译器会优化为:把返回值 ret直接识别为右值,调用移动构造把资源转移到新对象上去。


所以左值走拷贝构造,右值(将亡值)走移动构造,它可以把即将析构的右值的资源转移掉,转移了资源的所有权。
string s("hello world");
string s1 = s;// 拷贝构造
string s2 = s1 + s;//走移动构造
string s3 = std::move(s);// 是右值 就会走移动构造
std::move的作用是把左值变成右值,然后构造时就可以走移动构造了:


所以增加了移动构造函数以后,如 operator+的返回值等不能以左值引用返回的情况,直接以值返回就可以调用移动构造函数把函数栈帧内的资源转移给要构造的的新对象 string s = s1 + s2;
所以有了这个移动构造的概念后,同样的代码效率差距是巨大的:
vector<vector<int>> f(int v)
{
vector<vector<int>> ret;
//...
return ret;
}
auto p = f(1);
// C++98中 编译器优化后会以ret拷贝构造p 然后析构ret
// C++11中 直接把ret的资源移动给p 资源得到了延续 而没有这次析构
4 移动赋值函数

使用场景:
String To_String(String& s)
{
String ret = s;
return ret;
}
int main()
{
String bit;
String a("hlllo");
bit = To_String(a);
}
过程就是让 ret通过移动构造函数把资源给临时对象,这里以 To_String(a)代表,然后它是一个右值,走移动赋值语义把资源给 bit。




因为bit这里已经构造了,没法直接优化成一次移动构造给 bit了。
5 容器插入接口的右值引用
既然我们前面说到了有很多STL容器接口都提供了右值引用类型的参数,那么这有什么不同呢?
int main()
{
list<String> l1;
String s("hello");
l1.push_back(s);
cout << endl;
l1.push_back("2222222222");
cout << endl;
l1.push_back(To_String(s));
cout << endl;
}
无移动构造:

第一个传的是左值,只能拷贝构造去构造list中的节点;
第二个也同理,因为此时没有移动构造,只要拷贝构造list中的节点;
第三个第一次是在To_String中构造返回值调用拷贝构造,然后拷贝构造返回来的临时对象,然后再拷贝构造构建节点。
有移动构造:

第一个同上;
第二个走移动构造去构造list中的节点;
第三个第一个拷贝构造是To_String中构造返回值,然后移动构造把资源交给返回的临时对象,然后右值的临时对象再移动构造 list中的结点。
如果你想让左值去调用右值引用版本的函数,用 std::move即可,不过你要注意,这样就把你原本的资源搞没了,有这种需求时可以这样做。
6 完美转发
如果出现在模板中提供T&&或使用 auto&&时,它提供了新的语法,传过来的是左值,以左值引用接受,如果传过来的是右值,以右值引用接收。
template <class T>
void func(T&& t)// 万能引用
{
//...
}


不过要注意的是,我们前面讲过,右值引用后,它就变成了左值,万能引用接下参数后这里也是同理,所以这里会有一个问题:不管是左值右值,万能引用接过来都变成左值了,不相当于丢失了右值的属性了吗,咋办捏?
C++11中解决这个问题的方法是提供了一种称为完美转发的机制:万能引用接收原值后,往下面一层传参时,传这样的参数:std::forward。
有什么作用呢,一个比较常见的情况,比如我们实现容器时,push_back复用 insert,那如果没有完美转发,都是左值引用了,就没有啥右值引用带来的效率的提升了,所以这里实现完美转发,push_back复用 insert时提供完美转发,即在 push_back中使用 insert(std::forward。这样就能匹配到正确版本的insert。然后后续再构造结点时,再次完美转发确定去调用到正确的构造函数(左值去拷贝构造、深拷贝赋值,右值去移动构造、移动赋值)。
六、lambda表达式
1 引出的例子
很多场景中,我们需要增加一个叫做可调用对象的东西,去给一些STL中的算法作为参数,我们以前学习过的可调用对象有:
- 函数指针
- 仿函数
C++11觉得仿函数也多少有点麻烦,仿函数的写法太复杂了,并且可能存在每次都要自己定一个类型,名字也比较麻烦,这时,就可以使用 lambda表达式。
它的格式如下:[capture-list] (parameters) mutable -> return-type { statement }
[capture-list]: 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来 的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
一个两个东西相加的lambda表达式:
int main()
{
[](int a, int b)->int { return a + b; };
}
它的类型无法显示写出,我们一般用 auto 变量名 = lambda表达式获得这个lambda表达式对应的对象,调用的方法和仿函数一样。

注意: 在lambda函数定义中,参数列表和返回值类型都是可选部分,尤其是返回值,没返回值时可以直接省略,有返回值时可以让编译器自己推导。而捕捉列表和函数体可以为空。 因此C++11中最简单的lambda函数为:[]{}; 该lambda函数不能做任何事情。

捕捉列表可以通过指定变量名字决定要捕捉那些变量,加&符号可以表示我们想以引用方式捕捉。
默认捕捉时,且不以引用方式捕捉时,都是以 const方式捕捉的,如果加上 mutable,则可以表示传过来的值是可以修改的,这时,参数列表即使为空也不可省略。
2 捕捉列表详解
- [var]:表示值传递方式捕捉变量var
- [=]:表示值传递方式捕获所有父作用域中的变量(包括this)
- [&var]:表示引用传递捕捉变量var
- [&]:表示引用传递捕捉所有父作用域中的变量(包括this)
- [this]:表示值传递方式捕捉当前的this指针
捕捉不可重复,不可以[a, a]。
如果想其他变量以值捕捉,a以引用捕捉,可以这样写:[=, &a]。
注意:
a. 父作用域指包含lambda函数的语句块
b. 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。 比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量 [&,a, this]:值 传递方式捕捉变量a和this,引用方式捕捉其他变量
c. 捕捉列表不允许变量重复传递,否则就会导致编 译错误。 比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
d. 在块作用域以外的lambda函数捕捉列表必须为空,全局的lambda表达式不可捕捉变量,即使是全局变量,只可用参数列表
e. 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
f. lambda表达式之间不能相互赋值,即使看起来类型相同
所以如果某个STL函数参数需要传一个可调用对象,可以直接在参数处写一个lambda表达式:
sort(arr.begin(), arr.end(), [](const Good& a, const Good& b) { return a._price < b._price; });
3 lambda表达式的原理
我们之前用 typeid(p).name()得到过我们写的一个lambda的名称:

它还是一个类就表示lambda表达式的本质是一个仿函数,那个函数名是给编译器用的,它的底层实现其实是处理成一个类名为 lambda_uuid的仿函数类。
七、C++11中类的新功能
1 类中提供了新的一些关键字
继承和多态中提供了 final和 override关键字(C++11),它们都可以是类中发挥作用。加了 final关键字后,类就不能被继承了,或者对一个虚函数加 final关键字,那样虚函数就不能被再重写了。override关键字修饰虚函数可以表明我这个是要重写的虚函数,可以检查出我的虚函数重写的语法错误。
下面我们看看一些别的有意义的关键字。
I default
我们知道,在类中,如果我们不提供构造函数时,编译器会默认生成一个构造函数,它对默认类型没有处理,对自定义类型会调用其构造函数,但是我们提供了构造函数这个东西就会消失,有时候会引起不方便,比如我提供了一个含参的构造函数,或者提供了一个拷贝构造函数,但是我的无参的构造函数都想用原本编译器默认生成的呢?比如下面的例子:


在C++11前,如果我们想用那个默认生成的,还得自己写一个一样的,C++11中,我们可以用 default关键字,它的作用就是告诉编译器这个类函数使用默认生成的即可。

defalut可以针对类的所有函数起作用。
2 delete
假如我们想实现单例模式,这个类只能有一个对象,它不能被拷贝,不允许赋值,如果没有C++11的情况下,我们怎样操作呢?可以把拷贝构造函数和赋值函数给放到 private中。

但是这样仍然可以在类中调用拷贝构造函数,并没有达到我们的要求。

一个更决绝的方法是不实现拷贝构造函数:

这样编译都会因为链接时找不到拷贝构造函数而失败,这就是C++98的语法支持下防止拷贝构造的方法:只声明不实现,并且要把声明弄成私有。
如果只声明不实现,不弄成私有,这样的话有可能会被他人在类外补上定义后,由于不是private,就可以被访问了,这样就出问题了,所以还是要放成私有。
但是这样还是有缺陷,如果他人在类外补上定义后,在类里面就可以使用拷贝构造函数了,所以C++98的单例模式做的并不不决绝,所以C++11补了一个补丁,增加了一个关键字delete,它的语义就是删除这个默认类成员函数,
调用已经删除的函数会语法报错。

2 新增的默认类成员函数—移动构造和移动赋值
C++11中因为有了右值引用,有了移动构造和移动赋值,它俩也被列为了默认类成员函数,我们不写时,编译器会自动生成,算上C++98中的六个,一共有8个默认成员函数。
那么默认生成的肯定有一系列的规则,我们来看看:
- 如果你没有自己实现移动构造函数,且没有实现析构函数、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自己生成一个默认移动构造,默认实现的移动构造,对内置类型会按字节拷贝,对于自定义类型,如果该类型没有实现移动构造,那么就会调用该类型的拷贝构造,如果实现了移动构造,就会调用对应的移动构造函数。
- 如果你没有自己实现移动赋值函数,且没有实现析构函数、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自己生成一个默认移动构造,默认实现的移动赋值,对内置类型会按字节拷贝,对于自定义类型,如果该类型没有实现移动赋值,那么就会调用该类型的赋值重载,如果实现了移动赋值,就会调用对应的移动赋值函数,这点与移动构造类似。
- 为什么条件这么设计我也不知道= =。
八、可变参数模板
1 语法含义
C语言中就有可变参数函数,如printf函数:

因为我们不知道在格式化字符串里头要指定多少个参数,所以用了可变参数函数。
在C++的模板中,可以给出不确定模板参数个数并且不确定模板的参数类型的模板(C++11),但是它比较晦涩。
语法如下:
template <class ...Args>
void show(Args... args)
{}
// Args是一个模板参数包
// args是用模板参数包Args定义出的函数参数包

上面的args是一个被模板参数包定义出函数参数包,我们无法直接获得模板参数包中的每个参数,只能通过一些方式展开参数包来获得每个参数,这是模板参数包这个语法最晦涩的地方,下面我们介绍两种方式来展开参数包。
2 递归展开参数包

编译是可以通过,那么怎么解析呢?
首先,通过语法 sizeof...(Args)或sizeof...(args)可以算出参数包的参数个数:

既然可以获得参数包的参数个数,那么我们是否可以通过那种类似数组的方式 args[i]得到每个参数呢,遗憾的是,C++不支持这样的语法:

递归的解决方法是去增加一个模板参数:
// 递归解析它
// 要求 打印参数类型以及参数的值
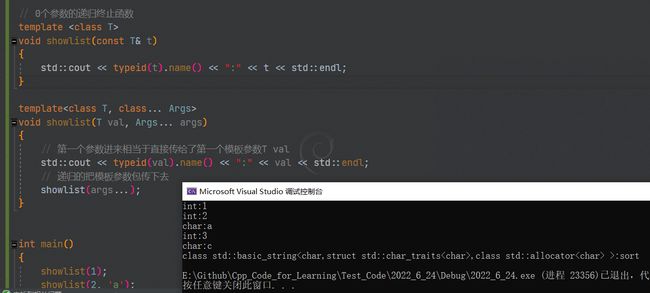
// 1个参数的递归终止函数 当下面的模板函数解析到参数包只有一个参数,就会来走上面的函数了。
template <class T>
void showlist(const T& t)
{
std::cout << typeid(t).name() << ":" << t << std::endl;
}
template<class T, class... Args>
void showlist(T val, Args... args)
{
// 第一个参数进来相当于直接传给了第一个模板参数T val
std::cout << typeid(val).name() << ":" << val << std::endl;
// 递归的把模板参数包传下去
showlist(args...);
}
int main()
{
showlist(1);
showlist(2, 'a');
showlist(3, 'c', std::string("sort"));
}
3 利用数组展开参数包
首先我们提供一个函数模板,然后用一种极其诡异的语法:
template <class T>
void PrintArgs(const T& t)
{
std::cout << typeid(t).name() << ":" << t << std::endl;
}
// 展开函数
template <class... Args>
void showlist(Args... args)
{
int arr[] = { (PrintArgs(args), 0)... };
// 含义是先把参数包的第一个参数传给上面的PrintArgs函数
// 然后...按前面写的方式依次展开,即(PrintArgs(args), 0), (PrintArgs(args), 0), (PrintArgs(args), 0)...
// 这里为什么是(函数, 0) 因为这个函数没有返回值,我们逗号表达式就会以后面的值为这个表达式的值
// 这样可以让数组确定要开的空间
std::cout << std::endl;
}
int main()
{
showlist(1);
showlist(2, 'a');
showlist(3, 'c', std::string("sort"));
}

这里我们可以优化我们的代码,给这个函数加个返回值即可。

看起来自然了一些。
这个地方的原理是编译器要去计算那个数组的大小,因此要把参数包给展开,确定函数要被调用多少次,然后函数就会依次被调用,达到我们的目的。
这个语法在STL库中的应用主要有 emplace系列函数、线程库、function包装器。


在STL的线程库中,可变参数模板提供的参数包可以让我们以各种各样的方式给线程函数指定参数类型和参数值。
STL的 emplace系列函数也是利用了可变模板参数,下面我们详细介绍一下。
4 emplace系列函数解释
首先,使用emplace系列函数会更灵活一些:
int main()
{
std::vector<std::pair<int, int>> vec;
// 利用make_pair
vec.push_back(std::make_pair(1, 1));
// 利用成员pair的成员初始化列表
vec.push_back({ 2, 4 });
// emplace系列也支持上面的写法
vec.emplace_back(std::make_pair(3, 5));
// 利用emplace_back 无需写上面的东西
vec.emplace_back(3, 5);
}
容器中是一个多成员变量的结构对象(如 std::pair),我们可以直接指定每个成员变量的值,无需再构造成一个结构后再插入,写起来更方便。
emplace系列函数与之前提供的那些容器插入函数还有一个区别:它的作用过程是直接在容器的空间上构造对象,而之前插入的那些对象,如果插入的是右值,那么走的流程是构造右值对象、移动构造容器上的对象,所以虽然有人说 emplace系列函数效率更高,其实效率差不多。
九、函数包装器
1 std::function
包括我们之前学过的 lambda表达式,我们一共有三种可调用对象类型:函数指针、仿函数、lambda表达式。
所以一个可调用对象有可能是函数指针、有可能是仿函数对象、有可能是 lambda表达式,C++11提供了一种新的语法,使得我们可以把这三种可调用对象包装为同一种类型。
包装器 std::function在头文件
template <class T> function;
template <class Ret, class... Args>
class function<Ret(Args...)>;
Ret 返回值类型
Args 函数参数列表
我们测试一下包装器:
int f(int a, int b)
{
return a + b;
}
struct func
{
double operator()(double a, double b) { return a + b; };
};
class sub
{
public:
static int isub(int a, int b)
{
return a - b;
}
double fsub(double a, double b)
{
return a - b;
}
};
int main()
{
// 包装函数指针
function<int(int, int)> f1 = f;
cout << f1(1, 2) << endl;
// 包装仿函数
function<double(double, double)> f2 = func();
cout << f2(3.0, 2.0) << endl;
// 包装成员函数
function<int(int, int)> f3 = &sub::isub;
cout << f3(1, 3) << endl;
function<double(sub, double, double)> f4 = &sub::fsub;
cout << f4(sub(), 9.0, 10.0) << endl;
// 包装lambda表达式
auto p = [](const int a, const int b) { return a * b; };
function<int(int, int)> f5 = p;
cout << f5(3, 2) << endl;
}

下面我们看一个包装器的应用案例:把传过来的一个字符串命令和一个动作函数(目前暂时是同参数类型同返回值的)映射起来,比如逆波兰表达式这个题:
class Solution {
public:
int evalRPN(vector<string>& tokens)
{
stack<int> st;
unordered_map<string, function<int(int, int)>> mp;
mp["+"] = [](int a, int b)->int { return a + b; };
mp["-"] = [](int a, int b)->int { return a - b; };
mp["*"] = [](int a, int b)->int { return a * b; };
mp["/"] = [](int a, int b)->int { return a / b; };
for (const auto& str : tokens)
{
if (mp.count(str) != 0)
{
char ch = str[0];
int op2 = st.top();
st.pop();
int op1 = st.top();
st.pop();
st.push(mp[str](op1, op2));
}
else st.push(stoi(str));
}
return st.top();
}
};
在网络服务器编程和游戏编程中,这样的操作其实挺方便的,如果未来要补充新的操作动作,直接修改映射关系即可。
2 bind

std::bind俗称绑定,也是在
通过绑定调整sub的参数顺序:
// 利用bind转变a和b的参数顺序
int sub(int a, int b)
{
return a - b;
}
class A
{
public:
int sub(int a, int b)
{
return a - b;
}
};
int main()
{
// 先绑定第二个参数 再绑定第一个参数 从而调换了sub的两个参数顺序
function<int(int, int)> f1 = bind(sub, placeholders::_2, placeholders::_1);
cout << f1(1, 2) << endl;
cout << sub(1, 2) << endl;
}

绑定非静态的成员函数,使得我们可以不显示指定 this指针就可以调用成员函数
int sub(int a, int b)
{
return a - b;
}
class A
{
public:
int sub(int a, int b)
{
return a - b;
}
};
int main()
{
// 先绑定第二个参数 再绑定第一个参数 从而调换了sub的两个参数顺序
function<int(int, int)> f1 = bind(sub, placeholders::_2, placeholders::_1);
cout << f1(1, 2) << endl;
cout << sub(1, 2) << endl;
// 第一个参数直接绑死 这样就把它适配为了一个function的包装器
function<int(int, int)> f2 = bind(&A::sub, A(), placeholders::_1, placeholders::_2);
cout << f2(3, 5) << endl;
}

十、STL线程库
1 组件

我们主要关注
C++11提供的线程库可以跨平台,这样不必非得区分Linux下的线程库和windows下的线程库的不同。
2 thread
thread是一个类,它的接口与pthread库类似,不过这套是面向对象的:

默认构造的线程不会跑起来,赋给了要跑的函数才会让线程动起来。
join、joinable和detach作用和我们Linux里头的pthread库中的对应函数作用一样。
它这里的构造函数就利用了我们的可变模板参数来指定给要执行的函数的参数:

一个测试:

我们可以先开一个vector存着一些还未运行的线程,任务来了以后去叫它干活:
int main()
{
vector<thread> vthds;
int n = 10;
vthds.resize(n);
for (auto& t : vthds)
{
t = thread(Print, 10, 3);
// 线程不可拷贝 这里是移动赋值
}
for (auto& t : vthds)
{
t.join();
}
}
它的operator=删除了拷贝赋值,只有移动赋值,线程也不可拷贝,只可移动构造。


下面写一个简单的程序,两个线程对同一个变量x++。
如何在线程函数中获得线程id?使用 std::this_thread命名空间中的静态成员函数 getid():

出现了线程安全问题,因此我们考虑加锁保护邻接资源 x:

3 mutex

这里的加锁最好放在for循环的外面,因为++x速度很快,而循环次数很大,会反复申请释放锁,导致用户态往内核态,内核态往用户态频繁的切换,效率反而会比较低:
void Func(int n)
{
// 2
for (int i = 0; i < n; ++i)
{
// 1
++x;
}
}
int main()
{
thread t1(Func, 100000);
thread t2(Func, 200000);
t1.join();
t2.join();
cout << x << endl;
}
加锁加在2的位置,这就不是一个多线程程序了,成了一个串行程序,但是它这样并没有错误。
加锁加在1的位置,这样是一个并行程序,但是++x太快了,会导致t1和t2线程频繁的切换上下文(因为要申请锁释放锁陷入内核态),比如t1竞争到了锁,然后t2没抢到,去休眠,需要保存上下文,保存t2执行到什么位置了,但是++太快了啊,t1在t2还没保存完就弄完了,t2还是得把它的动作做完,从而就会刚切出去就得切回来,频繁进行这一操作,效率问题就很大)。
这里可以用自旋锁,防止线程去挂起,而是循环等待,自旋锁在这种每个锁中的内容执行的很快的情况,也就是加在1位置,用自旋锁很好,但是C++11的库中没有自旋锁= =,如果要实现自旋锁需要自己用这个库里的设备实现或者用第三方库。
4 atomic—原子操作
针对速度很快的这些运算,但是却不是原子性的(因为要读数据、运算、放回),C++11的

它是一个模板类,我们可以自己指定类型:

换成原子操作以后就保证了线程安全,效率可能也会稍微高一些:

用lambda表达式,写的现代一些:
int main()
{
int N = 1000000;
atomic<int> x = 0;
int begin1 = clock();
thread t1([&] {
for (int i = 0; i < N; ++i, ++x);
});
int begin2 = clock();
thread t2([&] {
for (int i = 0; i < N; ++i, ++x);
});
t1.join();
int end1 = clock();
t2.join();
int end2 = clock();
cout << end1 - begin1 << "ms" << endl;
cout << end2 - begin2 << "ms" << endl;
cout << end2 - begin1 << "ms" << endl;
}
原子操作的速度:
int main()
{
int N = 1000000;
atomic<int> x = 0;
mutex mtx;
// int x = 0;
// int begin1 = clock();
atomic<int> time1 = 0;
atomic<int> time2 = 0;
int begin1, end1, begin2, end2;
thread t1([&] {
//mtx.lock();
begin1 = clock();
for (int i = 0; i < N; ++i)
{
// mtx.lock();
++x;
// mtx.unlock();
}
end1 = clock();
// mtx.unlock();
});
//int begin2 = clock();
thread t2([&] {
// mtx.lock();
begin2 = clock();
for (int i = 0; i < N; ++i)
{
// mtx.lock();
++x;
// mtx.unlock();
}
end2 = clock();
// mtx.unlock();
});
t1.join();
// int end1 = clock();
t2.join();
// int end2 = clock();
cout << end1 - begin1 << "ms" << endl;
cout << end2 - begin2 << "ms" << endl;
cout << end2 - begin1 << "ms" << endl;
}

锁外面:
int main()
{
int N = 1000000;
// atomic x = 0;
mutex mtx;
int x = 0;
// int begin1 = clock();
atomic<int> time1 = 0;
atomic<int> time2 = 0;
int begin1, end1, begin2, end2;
thread t1([&] {
mtx.lock();
begin1 = clock();
for (int i = 0; i < N; ++i)
{
// mtx.lock();
++x;
// mtx.unlock();
}
end1 = clock();
mtx.unlock();
});
//int begin2 = clock();
thread t2([&] {
mtx.lock();
begin2 = clock();
for (int i = 0; i < N; ++i)
{
// mtx.lock();
++x;
// mtx.unlock();
}
end2 = clock();
mtx.unlock();
});
t1.join();
// int end1 = clock();
t2.join();
// int end2 = clock();
cout << end1 - begin1 << "ms" << endl;
cout << end2 - begin2 << "ms" << endl;
cout << end2 - begin1 << "ms" << endl;
}

锁里面:
int main()
{
int N = 1000000;
// atomic x = 0;
mutex mtx;
int x = 0;
// int begin1 = clock();
atomic<int> time1 = 0;
atomic<int> time2 = 0;
int begin1, end1, begin2, end2;
thread t1([&] {
// mtx.lock();
begin1 = clock();
for (int i = 0; i < N; ++i)
{
mtx.lock();
++x;
mtx.unlock();
}
end1 = clock();
// mtx.unlock();
});
//int begin2 = clock();
thread t2([&] {
// mtx.lock();
begin2 = clock();
for (int i = 0; i < N; ++i)
{
mtx.lock();
++x;
mtx.unlock();
}
end2 = clock();
// mtx.unlock();
});
t1.join();
// int end1 = clock();
t2.join();
// int end2 = clock();
cout << end1 - begin1 << "ms" << endl;
cout << end2 - begin2 << "ms" << endl;
cout << end2 - begin1 << "ms" << endl;
}

N个线程处理M个加操作并且打印:
| 函数名 | 功能 |
|---|---|
| thread() | 构造一个线程对象,没有关联任何线程函数,即没有启动任何线程 |
| thread(fn, args1, args2, …) | 构造一个线程对象,并关联线程函数fn,args1,args2,…为线程函数的参数 |
| this_thread::get_id() | 获取线程id |
| joinable() | 线程是否还在执行,joinable代表的是一个正在执行中的线程。 |
| join() | 该函数调用后会阻塞住线程,当该线程结束后,主线程继续执行 |
| detach() | 在创建线程对象后马上调用,用于把被创建线程与线程对象分离开,分离的线程变为后台线程,创建的线程的"死活"就与主线程无关 |

这是一个时间锁,锁这些时间,如果这些时间后还没解锁,就会自动解锁。
5 一些注意点
严格来说,STL的线程库的接口的函数参数是不能传左值引用的,不然会编译报错,这可能是因为底层实现时使用了pthread的库,所以它的接口参数类型是指针型而非这种左值引用型:
指针型:

左值引用型:

void func1(int* x)
{
*x += 10;
}
void func2(int& x)
{
x += 10;
}
int main()
{
int n1 = 0, n2 = 0;
// thread t1(func1, &n1);
thread t2(func2, n2);
// t1.join();
t2.join();
cout << n1 << ',' << n2 << endl;
return 0;
}
但是奇怪的是,用 lambda表达式的引用方式捕捉变量却可以正常:
int main()
{
int x = 0;
thread t1([&] {
++x;
});
t1.join();
cout << x << endl;
}

这里可以用 std::ref去传那个引用参数,也可以解决问题:

void func1(int* x)
{
*x += 10;
}
void func2(int& x)
{
x += 10;
}
int main()
{
int n1 = 0, n2 = 0;
thread t1(func1, &n1);
thread t2(func2, std::ref(n2));
t1.join();
t2.join();
cout << n1 << ',' << n2 << endl;
return 0;
}
这个原因和STL一些底层实现有关系。
CAS(compare and swap)是原子类和自旋锁的实现机制。
6 lock_guard和unique_lock
在我们以前学习过的多线程程序中,可能因为后续我们将学习异常出现死锁的问题:
void func(vector<int>& v, int n, int base, mutex& mtx)
{
try
{
for (int i = 0; i < n; ++i)
{
mtx.lock();
// push_back失败了会抛异常
v.push_back(i + base);
if (base == 1000 && i == 88)
throw bad_alloc();
mtx.unlock();
}
}
catch (const exception& e)
{
cout << e.what() << endl;
}
}
int main()
{
thread t1, t2;
mutex mtx;
vector<int> v;
t1 = thread(func, std::ref(v), 100, 1000, std::ref(mtx));
t2 = thread(func, std::ref(v), 100, 2000, std::ref(mtx));
t1.join();
t2.join();
}
乍一看好像没有什么问题,但实际上因为 push_back失败时,会直接跳到捕获异常那里,那么此时这个锁还没还呢,并且永远不会还锁了,就形成了死锁,这就是一种异常安全问题,我们模拟运行一下:

一直在这个地方不动弹了,说明在这里死锁掉了。
那么怎么解决这个问题呢?既然只有抛异常才会进下面的 catch中,那么我们在其中解一下锁就好:

但是这样的代码其实感觉挺挫的,如果锁的情况很复杂的时候,我们直接手动单独解锁会很容易出错,有人提出我们可以写一个类 lockgurad来帮解决这个问题。
template <class Lock>
class LockGuard
{
public:
LockGuard(Lock& lock) : _lock(lock)
{
_lock.lock();
}
~LockGuard()
{
_lock.unlock();
}
private:
// 由于互斥锁不支持拷贝 这里我们加一个&
Lock& _lock;
};
void func(vector<int>& v, int n, int base, mutex& mtx)
{
try
{
for (int i = 0; i < n; ++i)
{
LockGuard<mutex> lg(mtx);
// 一个叫锁守卫的类帮我们管理锁
// 在作用域内 构造函数时自动加锁
// 不论是结束这轮循环还是因为异常离开作用域 都会调用析构函数自动解锁
// 巧妙地利用了RAII机制
// push_back失败了会抛异常
v.push_back(i + base);
if (base == 1000 && i == 88)
throw bad_alloc();
// mtx.unlock();
}
}
catch (const exception& e)
{
// mtx.unlock();
cout << e.what() << endl;
}
}
int main()
{
thread t1, t2;
mutex mtx;
vector<int> v;
t1 = thread(func, std::ref(v), 100, 1000, std::ref(mtx));
t2 = thread(func, std::ref(v), 100, 2000, std::ref(mtx));
t1.join();
t2.join();
}

包括我们后续会讲解的智能指针,如果出现内存申请new后的异常问题,如果你用普通指针管理还得在异常那里很难受的去delete一下(还要判断是谁给的异常,很难受),用智能指针管理内存资源,因为异常离开作用域直接调析构函数释放资源。
那我们是每个锁都要这样写吗,并不用,C++11的 lock_gurad和 unique_lock这两个锁:

lock_guard:这个和我们刚刚写的是完全一样。

unique_lock:除了有我们的原本的RAII机制,它还提供了 lock的其他的函数:


7 条件变量
两个线程交替打印,一个线程打印奇数,一个变量打印偶数,我们通过这个例子来练习条件变量的使用。
如果单纯用一个互斥锁加锁,那么就有可能某一个线程多次抢到锁,打印多次。
C++11封装了了条件变量来给我们使用,但是它不是线程安全的,需要配合互斥锁使用。

这里我们看一下wait的第二个接口:

第二个参数是一个可调用对象,当这个条件为真时,就不会阻塞;当它为假时,就会一直阻塞,类似:while (!pred()) wait(lck);,所以我们可以利用一个布尔变量,让两个线程相互协作:
int main()
{
int i = 0;
int n = 100;
bool flag = false;
// 这里的flag 同时控制了能让t1先打印(因为一开始flag是false t2过不去会一直在flag下wait)
// 而且保证了t1打印完后一定是t2打印 因为此时flag等于true了 t2从flag出来了 wait也被唤醒了
// 只有它打印完把wait改回false t1才能打印
mutex mtx;
condition_variable cv;
thread t1([&]() {
while (i < n)
{
unique_lock<mutex> ulk(mtx);
cv.wait(ulk, [&flag] { return !flag; });
++i;
cout << this_thread::get_id() << ":->" << i << endl;
flag = true;
cv.notify_one();
}
});
thread t2([&] {
while (i < n)
{
unique_lock<mutex> ulk(mtx);
cv.wait(ulk, [&flag] { return flag; });
++i;
cout << this_thread::get_id() << ">-" << i << endl;
flag = false;
cv.notify_one();
}
});
t1.join();
t2.join();
return 0;
}
这里可以从任何一个线程阻塞在锁上、阻塞在 cv.wait上,或者是单纯的休眠,这三种状态下都不会发生连续运行 。
- 如果你在锁上阻塞,就算我再次抢到了锁,进入cv.wait()我就会因为flag解锁,让你运行;
- 如果你在cv.wait阻塞,因为上一轮我给你了一个notify_one(),而且你的flag是满足条件的,一定会运行;
- 如果你时间片用完了单纯休眠,我会在锁上或者flag那里等着。